Python中requests基本使用
requests模块
- 介绍
- 基于GET请求
- 基于POST请求
- 响应Response
- 高级用法
requests介绍
官方链接 ---> http://docs.python-requests.org/en/master/
HTTP协议 ---> http://www.cnblogs.com/linhaifeng/p/6266327.html
安装 : pip3 install requests
介绍:使用requests可以模拟浏览器请求
requests库发送请求将网页内容下载下来后,并不会执行js代码,需要我们自己分析目标站点然后发起新的request请求
各种请求方式:常用requests.get()和requests.post()
import requests
r = requests.get('https://api.github.com/events')
r1 = requests.get('http://httpbin.org/post',data={'key':'value'})
二、基GET请求
基本参数 :method,url , params , data , json , headers , cookies
其它参数 :files , auth , proxies...
1、基于GET请求(无参数)
import requests
response = requests.get('http://dig.chouti.com/')
print(response)
print(response.text)
print(response.url)
2、带参数的GET请求-->params
#请求头内将自己伪装成浏览器,否则百度不会正常返回页面内容
import requests
#在headers请求头中将自己伪装成浏览器,否则百度不会正常返回页面内容;
#将参数直接写到请求url的后面,只能用于英文和数字,中文或者其它特殊字符必须使用params参数带值过去;
response = requests.get('https://www.baidu.com/s?wd=python&pn=1',
headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36', })
print(response.text)
#如果出现关键词是中文或者其它特殊字符,即通过params带参数
wd = 'alck老师'
pn = 1
response_2 = requests.get('https://www.baidu.com/s', params={'wd':wd, 'pn':pn },
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36', })
print(response_2.text)
print(response_2.url)
#有参数例子
import requests
payload = {'key1':'value1','key2':'value2'}
ret = requests.get("http://www.itest.info",params=payload)
print(ret.url)
#输出:http://www.itest.info/?key2=value2&key1=value1
3、带参数的GET请求-->headers
通常在发送请求时都需要带上请求头,请求头是将自身伪装成浏览器的关键,常见的有用请求头:
Host
Referer # 大型网站通常都会根据该参数判断请求的来源
User-Agent # 客户端
Cookie # Cookie信息虽然包含在请求头里,但requests模块有单独的参数来处理它,headers={}内就不需要放它
#添加headers(浏览器会识别请求头,不加可能会被拒绝访问,例如:https://www.zhihu.com/explor)
import requests
response = requests.get('https://www.zhihu.com/explore')
print(response.status_code)
# 返回500
#自定制headers
headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',}
response = requests.get('https://www.zhihu.com/explore',headers=headers)
print(response.status_code)
#200
4、带参数的GET请求-->cookies
import requests
#登录github,然后从浏览器中获取cookies,以后就可以直接拿着cookie登录了,无需输入用户名;
Cookies = { 'user_session':'ImRJpK-svLGo2riFpzGKXHdkOCnvnkuFG7CySWGYljuGP--a',}
response = requests.get('https://github.com/settings/emails',cookies=Cookies)
print('352932341@qq.com'in response.text)#True
三、基于POST请求
1、介绍
#GET请求:
HTTP默认的请求方法就是GET,特点如下:
没有请求体 ;
数据必须在1K之内;
GET请求数据会暴露在浏览器的地址栏中;
#GET请求常用的操作:
在浏览器的地址栏中直接给出URL,那么一定就是GET请求;
点击页面上的超链接也一定是GET请求;
提交表单时,表单默认使用GET请求,但可以设置为POST;
#POST请求
数据不会出现在地址栏中;
数据的大小没有上限;
有请求体;
请求体中如果存在中文,会使用URL编码;
requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据。
2、发送post请求,模拟浏览器的登录行为
对于登录来说,应该输错用户名和密码然后分析抓包流程,因为输入正确浏览器就跳转了无法分析;
import requests
import json
#1、基本POST实例
url = 'https://api.github.com/some/endpoint'
payload = {'key1':'value1','key2':'value2'}
ret = requests.post(url=url,data = payload )
print(ret.text)
2、发送请求头和数据
payload = {'some':'data'}
headers = {'content-type':'application/json'}
r2 = requests.post( url = "http://www.oldboyedu.com',data = json.dumps(payload),headers = headers )
print(ret.text)
print(ret.cookies)
ps:请求参数中存在字典嵌套字典时用json
其它参数使用data和json都可以
其它请求
requests.get(url, params=None, **kwargs)
requests.post(url, data=None, json=None, **kwargs)
requests.put(url, data=None, **kwargs)
requests.head(url, **kwargs)
requests.delete(url, **kwargs)
requests.patch(url, data=None, **kwargs)
requests.options(url, **kwargs)
# 以上方法均是在此方法的基础上构建
requests.request(method, url, **kwargs)
更多参数
def request(method, url, **kwargs):
"""Constructs and sends a :class:`Request <Request>`.
:param method: method for the new :class:`Request` object.
:param url: URL for the new :class:`Request` object
:param params: (optional可选的) Dictionary or bytes to be sent in the query string for the :class:`Request`.
:param data: (optional可选的) Dictionary, bytes, or file-like object to send in the body of the :class:`Request`.
:param json: (optional) json data to send in the body of the :class:`Request`.
:param headers: (optional) Dictionary of HTTP Headers to send with the :class:`Request`.
:param cookies: (optional) Dict or CookieJar object to send with the :class:`Request`.
:param files: (optional) Dictionary of ``'name': file-like-objects`` (or ``{'name': file-tuple}``) for multipart encoding upload.
``file-tuple`` can be a 2-tuple ``('filename', fileobj)``, 3-tuple ``('filename', fileobj, 'content_type')``
or a 4-tuple ``('filename', fileobj, 'content_type', custom_headers)``, where ``'content-type'`` is a string
defining the content type of the given file and ``custom_headers`` a dict-like object containing additional headers
to add for the file.
:param auth: (optional) Auth tuple to enable Basic/Digest/Custom HTTP Auth.
:param timeout: (optional) How long to wait for the server to send data
before giving up, as a float, or a :ref:`(connect timeout, read
timeout) <timeouts>` tuple.
:type timeout: float or tuple
:param allow_redirects: (optional) Boolean. Enable/disable GET/OPTIONS/POST/PUT/PATCH/DELETE/HEAD redirection. Defaults to ``True``.
:type allow_redirects: bool
:param proxies: (optional) Dictionary mapping protocol to the URL of the proxy.
:param verify: (optional) whether the SSL cert will be verified. A CA_BUNDLE path can also be provided. Defaults to ``True``.
:param stream: (optional) if ``False``, the response content will be immediately downloaded.
:param cert: (optional) if String, path to ssl client cert file (.pem). If Tuple, ('cert', 'key') pair.
:return: :class:`Response <Response>` object
:rtype: requests.Response
Usage::
>>> import requests
>>> req = requests.request('GET', 'http://httpbin.org/get')
<Response [200]>
"""
参数例子:
伪代码
import requests,json
def param_method_url():
"""下面这种写法和requests.get()和requests.post()是一样的功能"""
# response = requests.request(method='get',url='https://github.com')
# response = requests.request(method='post',url='https://github.com')
pass
def param_param():
'''参数params以及传递几种方式'''
# 字典,字符串,字节(ascii编码已内)
requests.request(method='get', url='https://github.com',params={'k1':'v1','k2':'圣剑'})
requests.request(method='get',url='https://github.com',params="k1=v1&k2=圣剑&k3=v3&k3==vv3")
requests.request(method='get', url='https://github.com', params=bytes("k1=v1&k2=k2&k3=v3&k3==vv3",encoding='utf8'))
#错误,参数为中文
requests.request(method='get',url='https://github.com',params=bytes('k1=v1&k2=屌爆了&k3=vv3',encoding='utf8'))
def param_data():
'''参数data,传递方式'''
#字典、字符串、字节、文件对象
requests.request(method='get',url = 'https://github.com',data = {'k1':'v1','k2':'交通费'})
requests.request(method='POST',url = 'https://github.com',data = "k1=v1;k2=v2;k3=v3;k3=v4")
requests.request(method ='POST',url = 'https://github.com',data = "k1=v1;k2=v2;k3=v3;k3=v4",headers = {'Content-Type':'application/x-www-form-urlencoded'})
requests.request(method ='POST',url ='https://github.com',data = open('data_file.py',mode='r',encoding='utf-8'),#文件内容是:k1=v1;k2=v2;k3=v3;k3=v4
headers ={'Content-Type':'application/x-www-form-urlencoded'})
def param_json():
# 将json中对应的数据进行序列化成一个字符串,json.dumps(...)
# 然后发送到服务端的body中,并且Content-Type是{'Content-Type':'application/json'}
requests.request(method='POST',url='https://github.com', json={'k1':'v1','k2':'交通费'})
def param_headers():
#发送请求头到服务端
requests.request(method='POST',url ='https://github.com',json ={'k1':'v1','k2':'交通费'},headers={'Content-Type':'application/x-www-form-urlencoded'} )
def param_cookies():
#发送Cookie到服务端
requests.request(method='POST',url ='https://github.com',data={'k1':'v1','k2':'v2'},cookies ={'cook1':'value1'})
def param_files():
#发送文件
file_dict={'f1':open('readme','rb')}
requests.request(method='POST',url='https://github.com',files=file_dict)
#发送文件,定制文件名
file_dict_2 ={'f2':('test.txt',open('readme','rb'))}
requests.request(method='POST', url='https://github.com',files=file_dict_2)
#发送文件,定制文件名
file_dict_3 = { 'f3':('test.txt','wordcontent','application/text',{'k1':'0'}) }
requests.request(method='POST',url='https://github.com', files=file_dict_3)
def param_auth():
from requests.auth import HTTPBasicAuth,HTTPDigestAuth
ret = requests.get('https://api.github.com/usre',auth=HTTPBasicAuth('test','123456t'))
print(ret.text)
ret_one = requests.get('http://192.168.1.1', auth=HTTPBasicAuth('admin','admin'))
ret_one.encoding ='gbk'
print(ret_one.text)
ret_tow = requests.get('http://httpbin.org/digest-auth/auth/user/pass',auth=HTTPDigestAuth('user','pass'))
print(ret)
def param_timeout():
ret = requests.get('http://google.com/',timeout=1)
print(ret)
ret_1 =requests.get('http://google.com/',timeout=(5,1))
print(ret_1)
def param_allow_redirects():
'''允许重定向'''
ret = requests.get('http://127.0.0.1:8000/test',allow_redirects=False)
print(ret.text)
def param_proxies():
'''代理'''
# proxies = {
# "http":"62.172.258.98:80",
# "https":"http://61.185.219.126:3128",
# }
proxies = {'http://10.20.1.128':'http://10.10.1.10:5323'}
ret = requests.get("http://www.proxy360.cn/Proxy",proxies=proxies)
print(ret.headers)
from requests.auth import HTTPProxyAuth
proxyDict = { 'http':'77.75.105.165','https':'77.75.105.165'}
auth = HTTPProxyAuth('username','mypassword')
r = requests.get("http://www.google.com",proxies=proxyDict,auth=auth)
print(r.text)
def param_stream():
ret = requests.get('http://127.0.0.1:800/test',stream=True)
print(ret.content)
ret.close()
def requests_session():
import requests
session = requests.Session()
### 1、登录任何页面,获取cookie
i1 = session.get(url="http://dig.chouti.com/help/service")
###2、用户登录,携带上一次的cookie,后台对cookie中的gpsd进行授权
i2 = session.post(
url="http://dig.chouti.com/login",
data ={
'phone' :'86352932341@qq.com',
'password':'xxxooo',
'oneMonth':"" })
i3 = session.post( url="http://dig.chouti.com/link/vote?linksId=8589623", )
print(i3.text)
实战:
2.1、目标站点分析
浏览器输入:https://github.com/login ---->然后输入错误的账号密码分析如下:
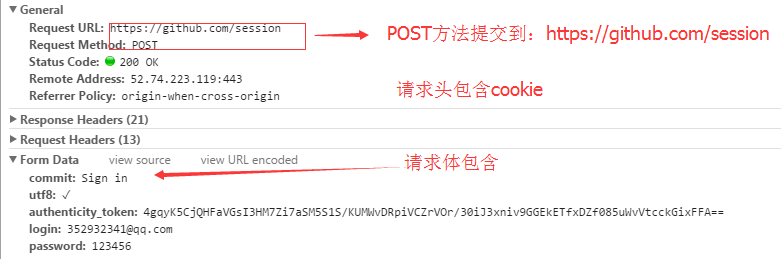
2.2、流程分析
先GET :https://github.com/login 拿到初始cookie与authenticity_token
返回POST:https://github.com/session, 带上初始cookie,带上请求体(authenticity_token,用户名,密码等);
最后拿到登录cookie
PS:如果密码时密文形式,则可以先输错账号,输对密码,然后到浏览器中拿到加密后的密码,github的密码是明文;
import requests,re
#第一次请求
r1 = requests.get('https://github.com/login')
r1_cookie = r1.cookies.get_dict()#拿到初始cookie(未被授权)]
#<input type="hidden" name="authenticity_token" value="OquWGlzANjzFvVWfygbs94KI15FeI42bfNy1eQkLBp76xpFtQ/cJEYUlQNvdT3xTCkOL1IkMDor9JjhZYV+VRg==" /> <div class="auth-form-header p-0">
authenticity_token = re.findall(r'name="authenticity_token".*?value="(.*?)"',r1.text)[0] #正则匹配上面的返回的input标签,获取csrf的value值
#获取到csrf token
#第二次请求:带着初始cookie和token发送POST请求给登录页面,带上账号密码
data = {
'commit':'Sign in',
'utf8':'✓',
'authenticity_token':authenticity_token,
'login':'352932341@qq.com',
'password':'xxoooaooa' #密码是错误,需输入自己密码
}
r2 = requests.post('https://github.com/session',data=data,cookies = r1_cookie)
login_cookie = r2.cookies.get_dict()
#第三次请求:以后登录,拿着login_cookie访问一些个人配置:emails
r3 = requests.get('https://github.com/settings/emails',cookies=login_cookie)
print('352932341@qq.com' in r3.text)
#True
requests.session()自动保存cookie信息
import requests,re
#第一次请求
session = requests.session() #session会自动帮我们保存cookie信息
r1 = session.get('https://github.com/login')
authenticity_token = re.findall(r'name="authenticity_token".*?value="(.*?)"',r1.text)[0]
#从页面中拿到CSRF TOKEN
#第二次请求:带着初始cookie和token发送POST请求给登录页面,带上账号密码
data = {
'commit':'Sign in',
'utf8':'✓',
'authenticity_token':authenticity_token,
'login':'352932341@qq.com',
'password':'123456tian'
}
r2 = session.post('https://github.com/session', data=data,)
#第三次请求:以后登录,拿着login_cookie访问一些个人配置:emails
r3 = session.get('https://github.com/settings/emails')
print('352932341@qq.com' in r3.text)
#True
补充
requests.post(url='xxxxxxxx',data={'xxx':'yyy'}) #没有指定请求头,#默认的请求头:application/x-www-form-urlencoed
#如果我们自定义请求头是application/json,并且用data传值, 则服务端取不到值
requests.post(url='',data={'':1,},headers={'content-type':'application/json' })
requests.post(url='', json={'':1,}, ) #默认的请求头:application/json
抽屉首页全部点赞
import requests
from lxml import etree
header ={ "user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",}
r1 = requests.get("https://dig.chouti.com/",headers=header)
payload = { "phone" :"8613580423620","password":"123456tian","oneMonth":"1",}
r2 = requests.post("https://dig.chouti.com/login",headers=header,cookies=r1.cookies.get_dict(),data=payload)
gpsd = r1.cookies.get_dict()['gpsd']
print(r2.text)
html = etree.HTML(r1.text)
tages = html.xpath(".//div[@id='content-list']/div/div[2]/img/@lang")
print(tages)
print(len(tages))
for i in tages:
url = "https://dig.chouti.com/link/vote?linksId={0}".format(i)
r3 = requests.post(url=url,headers=header,cookies={'gpsd':gpsd})
汽车之家保存首页标题中图片保存到本地
import requests
from uuid import uuid4
from lxml import etree
header ={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",}
r1 = requests.get("https://www.autohome.com.cn/news/",headers=header)
print(r1)
r1.encoding = 'gbk'
html = etree.HTML(r1.text)
tages = html.xpath(".//div[@id='auto-channel-lazyload-article']/ul/li/a/div[1]/img/@src")
for i in tages:
img_url = "http:{0}".format(i)
res_jpg = requests.get(img_url,headers=header)
file_name = str(uuid4())+".jpg"
with open(file_name,'wb') as wr:
wr.write(res_jpg.content)
Response
3.1、response属性
import requests
response = requests.get('http://www.jianshu.com') #默认返回响应码
#response属性
print(response.text) #str类型打印请求响应体
print(response.content) #字节方式显示请求响应体
print(response.status_code) #获取返回状态码
print(response.headers)
print(response.cookies) #获取所有的cookies 返回字典类型
print(response.cookies.get_dict()) #获取指定的cookies
print(response.cookies.items())
response.encoding = "gbk" #
#第二种方法,解决编码不一致问题
print(response.url) print(response.history) print(response.encoding)
3.2、编码问题
import requests
response = requests.get('http://www.autohome.com/news')
response.encoding ='gbk' #汽车之家返回页面内容为gb2312,而requests的默认编码为ISO-8859-1,如果不设置中文就是乱码
print(response.text)
3.3 获取二进制数据
需求:请求图片ulr,保存到本地
import requests
response = requests.get('https://timgsa.baidu.com/timg?image&quality=80
&size=b9999_10000&sec=1509868306530&di=712e4ef3ab258b36e9f4b48e85a81c9d&
imgtype=0&src=http%3A%2F%2Fc.hiphotos.baidu.com%
2Fimage%2Fpic%2Fitem%2F11385343fbf2b211e1fb58a1c08065380dd78e0c.jpg')
with open('a.jpg','wb') as f:
f.write(response.content)
需求:stream参数:一点一点获取,
例如:下载视频,50G,用response.content然后一下子写到文件中是不合理
import requests
response = requests.get('https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo-transcode/1767502_56ec685f9c7ec542eeaf6eac93a65dc7_6fe25cd1347c_3.mp4',
stream=True) #stream参数:一点一点取
with open('b.mp4','wb') as f:
for line in response.iter_content():
f.write(line)
3.4、解析json
import requests
response = requests.get('http://httpbin.org/get').json()#获取json数据
print(response)
五、Redirection(重定向) and History(历史)
import requests
import re
#第一次请求
r1 = requests.get('https://github.com/login')
r1_cookies = r1.cookies.get_dict()#获取初始cookie(未被授权)
authenticity_token = re.findall(r'name="authenticity_token".*?value="(.*?)"',r1.text)[0]
#从页面中拿到CSRF TOKEN
#第二次请求:带着初始cookie和token发送POST请求给登录页面,带上账号密码
data = {
'commit':'Sign in',
'utf8':'✓',
'authenticity_token':authenticity_token,
'login':'352932341@qq.com',
'password':'123456tian'
}
#没有指定allow_redirects=False,响应头中出现Location就跳转到新页面,r2表示新页面的response
r2 = requests.post('https://github.com/session',data=data,cookies = r1_cookies)
print(r2.status_code)#200
print(r2.url) #查看跳转后的url即登录成功后的url
print(r2.history)#查看跳转前的response
print(r2.history[0].text)#查看跳转前的response.text
# 指定allow_redirects=False,则响应头中即出现Location也不会跳转到新页面,r3代理老页面
r3 = requests.post('https://github.com/session',data=data,cookies=r1_cookies,allow_redirects=False)
print("我是r3",r3.status_code)#302
print("我是r3",r3.url) #查看跳转前的url
print("我是r3",r3.history)#[]
六、高级用法
1、SSL 证书验证
import requests,re
#证书验证(大部分网站都是https)
response = requests.get('https://www.12306.cn')
print(response)
#改进1:去掉报错,但会报警告
response_1 = requests.get('https://www.12306.cn',verify=False)#不验证证书,报警告返回200
print(response_1.status_code)
#改进2:去掉报错,并且去掉警报信息
import requests
from requests.packages import urllib3
urllib3.disable_warnings() #关闭警告
respone = requests.get('https://www.12306.cn',verify=False)
print(respone.status_code)
#改进3:加上证书
#很多网站都是https,但是不用证书也可以访问,大多数情况都是可以携带也可以不携带证书
#知乎\百度等都是可带可不带
#有硬性要求的,则必须带,比如对于定向的用户,拿到证书后才有权限访问某个特定网站
import requests
respone = requests.get('https://www.12306.cn',cert=('/path/server.crt','/path/key'))
print(respone.status_code)
2、超时设置
#超时设置
#两种超时:float 或 tuple元组
#timeout = 0.1 接收数据超时时间
#timeout =(0.1,0.2) 0.1代表链接超时,0.2代表接收数据超时
import requests
response = requests.get('https://www.baidu.com',timeout=0.0001)
3、异常处理
import requests
from requests.exceptions import * #可以查看requests.exceptions获取异常类型
try:
r = requests.get('http://www.baidu.com',timeout=10)
except ReadTimeout:
print('=====')
# except ConnectionError:#网络不通
# print('=====')
# except Timeout:
# print('aaaaa')
except RequestException: #返回异常
print('Error')
4、上传文件
import requests
files={'file':open('a.jpg','rb')}
respone=requests.post('http://httpbin.org/post',files=files)
print(respone.status_code)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号