scrapy框架
scrapy爬虫框架
简介:所谓框架其实就是一个被集成了很多功能且具有很强通用性的一个项目模板;
学习:学习框架中集成的各种功能特性;
scrapy专门用于异步爬虫的框架
高性能的数据解析、请求发送、持久化存储、全站数据爬取、中间件、分布式...
环境安装
windows安装
1、pip install wheel
2、下载twisted文件,下载地址: https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted

3、进入下载目录,执行 pip install Twisted-17.1.0-cp35-cp35m-win_amd64.whl(Twisted就是一个异步的架构,被作用到scrapy中)
安装报错:需要更换另一个版本的twisted文件进行安装即可。
4、pip install pywin32
5、pip install scrapy
安装验证:cmd中输入scrapy按回车,没有报错说明安装成功
scrapy的基本使用:
第一步:创建一个工程:scrapy startproject ProName

目录结构
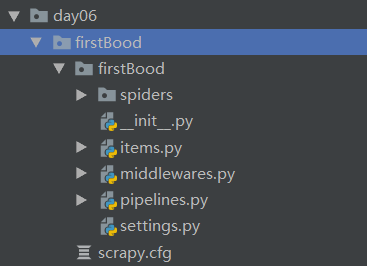
目录结构介绍
spiders : 爬虫文件夹,必须要存放一个爬虫源文件,默认是没有爬虫文件的,需要自己创建;
settings.py 工程的配置文件;
第二步:cd ProName
创建爬虫文件:scrapy genspider spiderName www.xxx.com
例如:创建名称为first的爬虫文件,只需要cd到工程目录下即可执行命令 :scrapy genspider first www.xxx.com

爬虫文件中编写对应的爬虫代码。
第三步:执行工程
scrapy crawl spiderName
执行工程后,默认会输出工程所有的日志信息。
指定类型日志的输出(只输出错误类型的日志):settings.py 中 LOG_LEVEL ="ERROR"
爬虫文件spiderName内容介绍:
import scrapy class FirstSpider(scrapy.Spider): # 爬虫文件的名称,作用当前源文件的唯一标识 name = 'first' # 允许的域名,通常注释掉:allowed_domains # allowed_domains = ['www.xxx.com'] # 起始的url列表,只可以存储url # 作用:列表中存储的url都会被进行get请求的发送 start_urls = ['https://www.baidu.com/', 'https://www.sogou.com'] # 数据解析 # parse方法调用的次数完全取决于请求的次数 # 参数response,表示服务器返回的响应对象 def parse(self, response): print("到这里啊", response)
settings.py配置
- 禁止robots
- 指定日志类型:LOG_LEVEL ="ERROR"
- UA伪装
... LOG_LEVEL = "ERROR" # 定义只输出错误的日志 # Crawl responsibly by identifying yourself (and your website) on the user-agent # UA伪装 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36' # Obey robots.txt rules # robots协议,默认True ROBOTSTXT_OBEY = False ...


 浙公网安备 33010602011771号
浙公网安备 33010602011771号