Python解析库lxml
使用XPath
XPath即XML路径语言,它是一门在XML文档中查找信息的语言。它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。
在做爬虫时,完全可以使用XPath来做相应的信息抽取。
1、Xpath概述
Xpath的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。另外,还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等。几乎所有我们想要定位的节点,都可以用XPath来选择。
2、Xpath常用规则
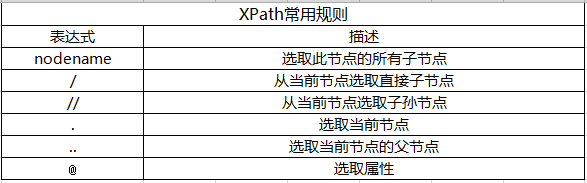
XPath的常用匹配规则:
//title[@lang='eng'] 这就是一个XPath规则,表示选择所有名称为title,同时属性lang的值为eng的节点。
使用Python的lxml库进行HTML解析
安装:pip install lxml
实例引入
from lxml import etree #导入etree
html_text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a> </li>
<li class="item-0"><a href="link2.html">second item</a> </li>
<li class="item-2"><a href="link3.html">third item</a> </li>
<li class="item-3"><a href="link4.html">fourth item</a> </li>
<li class="item-4"><a href="link5.html">fifth item</a> </li>
</ul>
</div>'''
html = etree.HTML(html_text)
获取所有节点
print(html.xpath("//*")) #*代表匹配所有节点,也就是整个HTML文本中的所有节点都会被获取。
输出:[<Element html at 0x26b9348>, <Element body at 0x26b92c8>, ]
#获取所有li节点
print(html.xpath("//li")) #使用//,然后直接加上节点名称即可。
输出:[<Element li at 0x26a92c8>, <Element li at 0x26a9288>, <Element li at 0x26a9388>, <Element li at 0x26a93c8>, <Element li at 0x26a9448>]
子节点 :通过/或//即可查找元素的子节点或子孙节点。例如:选择li节点的所有直接a子节点
#子节点和子孙节点
print(html.xpath("//li/a")) #获取所有li节点的所有直接a子节点。
输出:[<Element a at 0x26a92c8>, <Element a at 0x26a9288>, <Element a at 0x26a9388>, <Element a at 0x26a93c8>, <Element a at 0x26a9448>]
print(html.xpath("//ul//a"))#获取所有ul节点下面所有子孙节点
输出:[<Element a at 0x26a9488>, <Element a at 0x26a92c8>, <Element a at 0x26a9288>, <Element a at 0x26a9388>, <Element a at 0x26a93c8>]
父节点
print(html.xpath("//a[@href='link5.html']/../@class")) #获取父节点
输出:['item-4']
属性匹配
print(html.xpath("//li[@class='item-0']")) #可以用@符合进行属性过滤
输出:[<Element li at 0x26d9448>, <Element li at 0x26d92c8>]
文本获取
用Xpath中的text()方法获取节点中的文本。
print(html.xpath("//li[@class='item-0']/text()")) #text()前面是/,而此处/的含义是选取直接子节点,li的直接子节点都是a
输出:['\n ']
print(html.xpath("//li[@class='item-0']/a/text()"))#方法1:获取li节点内部的文本
print(html.xpath("//li[@class='item-0']//text()"))#方法2://选取li节点下的所有子孙
['first item', 'second item']
[first item', ' ', 'second item', ' ']
属性获取
print(html.xpath("//li/a/@href")) #获取所有li节点下所有a节点的href属性
输出:['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
属性多值匹配
多属性值时使用contains()方法,第一个参数传入属性名称,第二个参数传入属性值,只要此属性包含所传入的属性值,就可以完成匹配;
text1 = '''
<li class="li li-first"><a href="link.html">fifth item</a> </li>
'''
html2 = etree.HTML(text1)
print(html2.xpath("//li[contains(@class,'li')]/a/text()"))
多属性匹配
根据多个属性确定一个节点,这时就需要同时匹配多个属性。此时可以使用运算符and来连接:
text1 = '''
<li class="li li-first" name="item"><a href="link.html">fifth item</a> </li>
'''
html2 = etree.HTML(text1)
print(html2.xpath("//li[contains(@class,'li') and @name='item']/a/text()"))
查询更多XPath的用法:http://www.w3school.com.cn/xpath/index.asp


 浙公网安备 33010602011771号
浙公网安备 33010602011771号