
关于哈希
数据依赖的哈希比数据独立的哈希表现的更好,但是依然存在几个问题:
第一,大多数存在的哈希算法是批处理模式的,对于流数据的训练无效。第二,处理大数据问题时,内存消耗和计算代价都非常大。第三,无标签数据要求模型表现的提高。文章利用OSH(online Sketch Hashing)提出了FROSH(Faster online sketch Hashing)算法来sktch数据,并提出了理论保证,证明在相同内存代价下,FROSH训练时间更少。最后,将分布式加入FROSH中,进一步提高了实验的表现。
Online Sketching Hashing
给定n个数据点(n*d),OSH的目的是通过在sketch得到的小矩阵B(l*d)上构建SVD得到小的投影矩阵W(r*d)r是hash code 的比特位数,l是sketch大小。
OSH的关键是通过(FD)构建B

先来说一下FFD中使用的SRHT:
RHT类似于Fourier Transformer,将数据进行投影转化,目的是用频域变化使数据均匀化,这样遗漏部分数据就不会对参数估计造成很大影响。在此基础上采样就是SPHT的基本思想。
SHD中,D是元素为拉德马赫随机变量的对角矩阵,H是Hadamard矩阵,S是随机采样矩阵,SHDF将F压缩成了一个规模很小的矩阵。
得到B之后,通过步骤10、11,在B上SVD分解,将B中的原始信息压缩到前l/2行这样就能在下次迭代中,允许将新信息放到后l/2行

再来说FROSH算法
分批计算,每一块的行均指向量
计算B的前r个右奇异向量作为W
——————————————————————————————————————————
SRHT用在岭回归上已经在13年的nips上就有做过
FFD侧重解决在线问题
---恢复内容结束---
数据依赖的哈希比数据独立的哈希表现的更好,但是依然存在几个问题:
第一,大多数存在的哈希算法是批处理模式的,对于流数据的训练无效。第二,处理大数据问题时,内存消耗和计算代价都非常大。第三,无标签数据要求模型表现的提高。文章利用OSH(online Sketch Hashing)提出了FROSH(Faster online sketch Hashing)算法来sktch数据,并提出了理论保证,证明在相同内存代价下,FROSH训练时间更少。最后,将分布式加入FROSH中,进一步提高了实验的表现。
Online Sketching Hashing
给定n个数据点(n*d),OSH的目的是通过在sketch得到的小矩阵B(l*d)上构建SVD得到小的投影矩阵W(r*d)r是hash code 的比特位数,l是sketch大小。
OSH的关键是通过(FD)构建B
先来说一下FFD中使用的SRHT:
RHT类似于Fourier Transformer,将数据进行投影转化,目的是用频域变化使数据均匀化,这样遗漏部分数据就不会对参数估计造成很大影响。在此基础上采样就是SPHT的基本思想。
SHD中,D是元素为拉德马赫随机变量的对角矩阵,H是Hadamard矩阵,S是随机采样矩阵,SHDF将F压缩成了一个规模很小的矩阵。
得到B之后,通过步骤10、11,在B上SVD分解,将B中的原始信息压缩到前l/2行这样就能在下次迭代中,允许将新信息放到后l/2行
再来说FROSH算法
分批计算,每一块的行均指向量
计算B的前r个右奇异向量作为W
——————————————————————————————————————————
SRHT用在岭回归上已经在13年的nips上就有做过
FFD侧重解决在线问题
- 哈希可分为数据无关的哈希以及数据依赖的哈希
数据无关的哈希不训练数据,代表的有局部敏感哈希(LSH)。数据无关的哈希有很多局限性:比如学习效率低,需要很长的哈希码才能保证精度。
- 数据依赖的哈希又可以分为有监督的哈希和无监督的哈希
- 现有常用的无监督哈希:
频谱哈希(PH)——利用频谱分区解释哈希码学习,使用可以有效解决的谱方法来解决原始问题。
锚图哈希(AGH)——通过构造anchor graph来近似数据结构。
迭代量化(ITQ)——通过找到最小化误差的正交旋转矩阵,根据给定的训练样本通过迭代投影和阈值化来优化投影矩阵
可伸缩图哈希(SGH)、DPLM、LSMH、Deepbit.
- 现有常用的有监督哈希:
带有内核的哈希(KSH)
**************************************************************************************************************************
最新进展:
——AAAI——
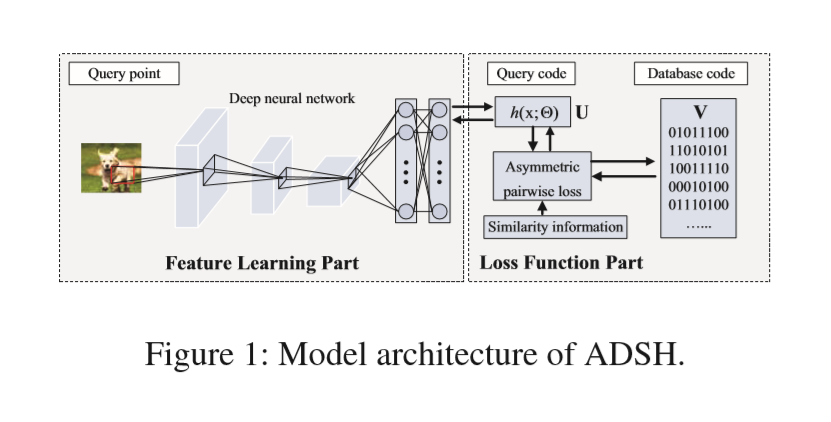
2018_Asymmetric Deep Supervised Hashing(ADSH)
非对称深度监督哈希,只为查询点学习深度哈希函数,而对数据库点则直接学习。
分为两部分
(1)Feature Learning Part——CNN-F model
5卷积层,3全连接层。为二进制哈希码提取特征表示。2016年的DPSH也使用了此模型,在 ADSH中,最后一层被全连接层代替
(2)Loss Function Part——
最小化查询与数据库点的二进制码之间的L2 loss。

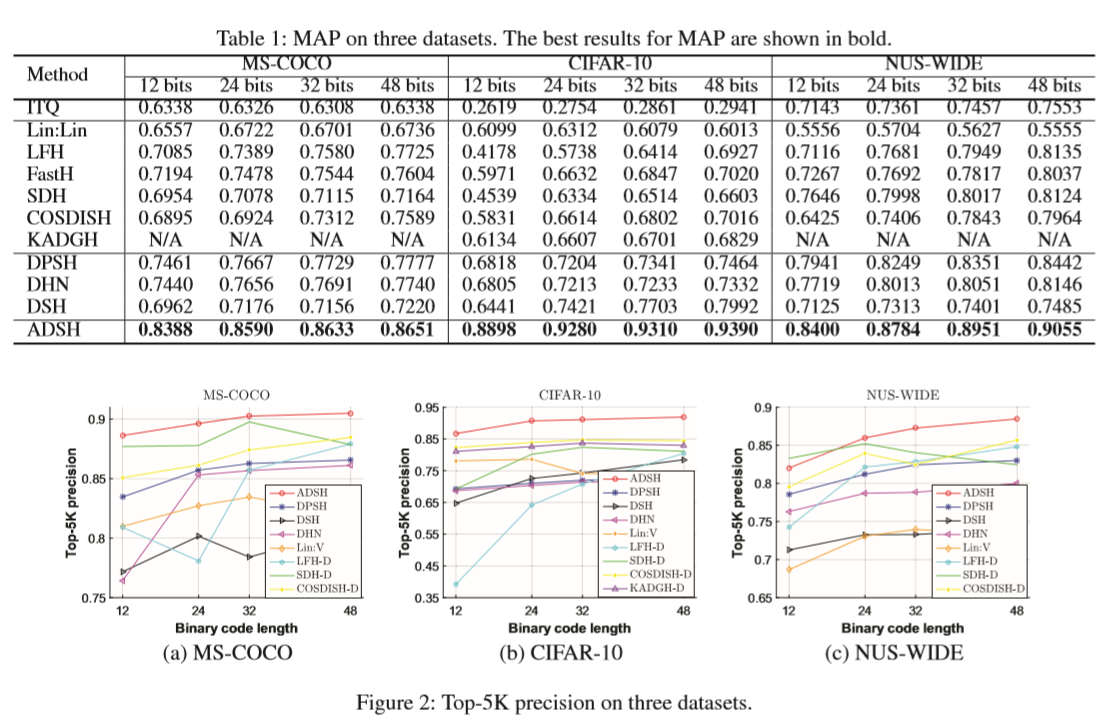
训练时间
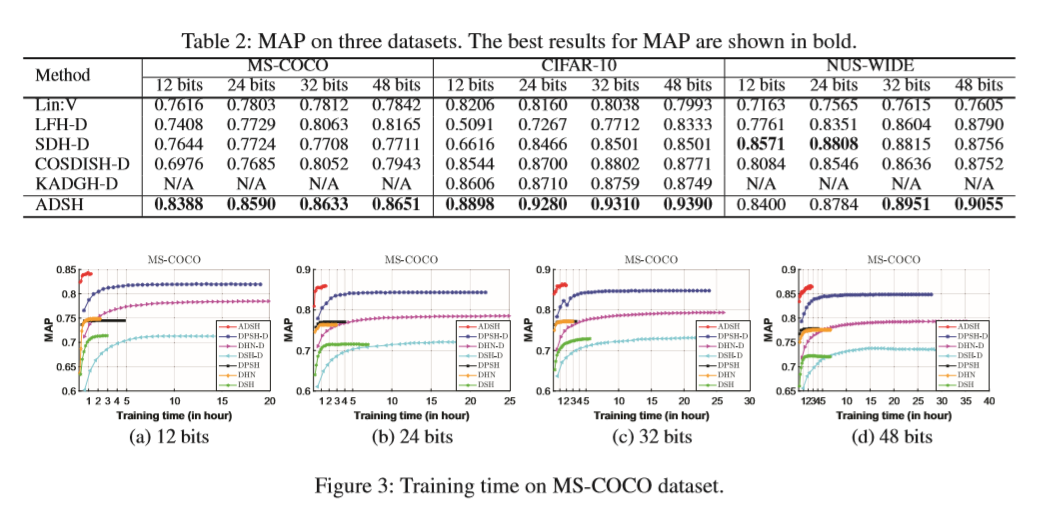
——NIPS——
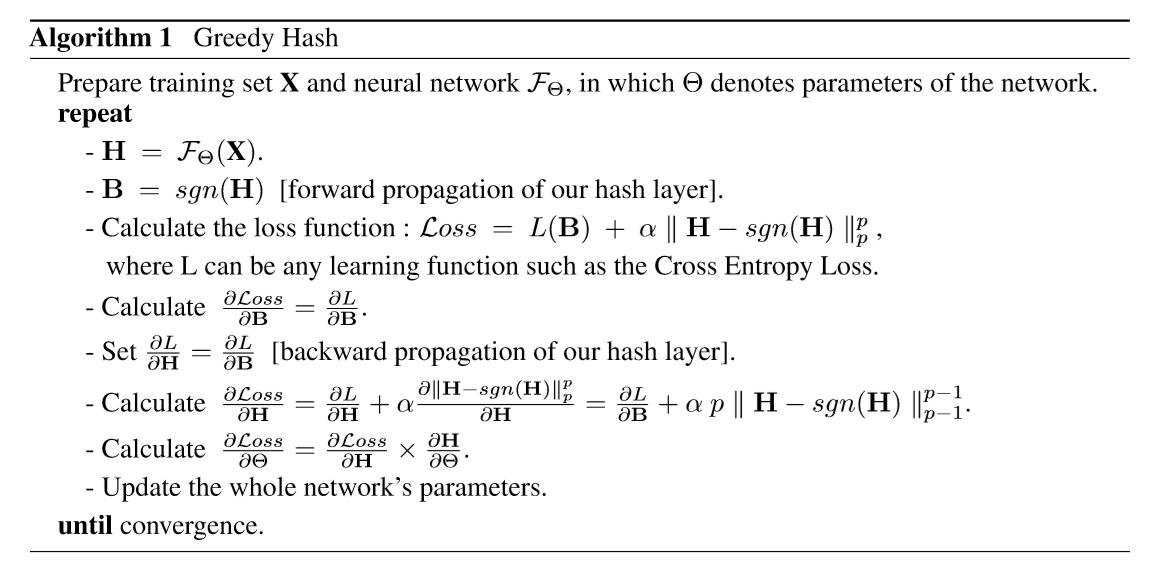
2018_Greedy Hash
目的:解决由于对输出施加离散约束而使得优化变为 NP难的问题。
将贪婪思想用于卷积神经网络,前向传播时使用符号函数,反向传播将梯度完整地传递到前层,避免梯度消失。
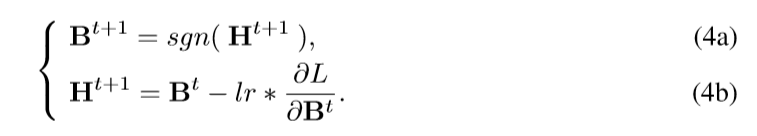
在最后一层隐藏层后边加入新的哈希层,在新的哈希层的前向传播中使用符号函数。
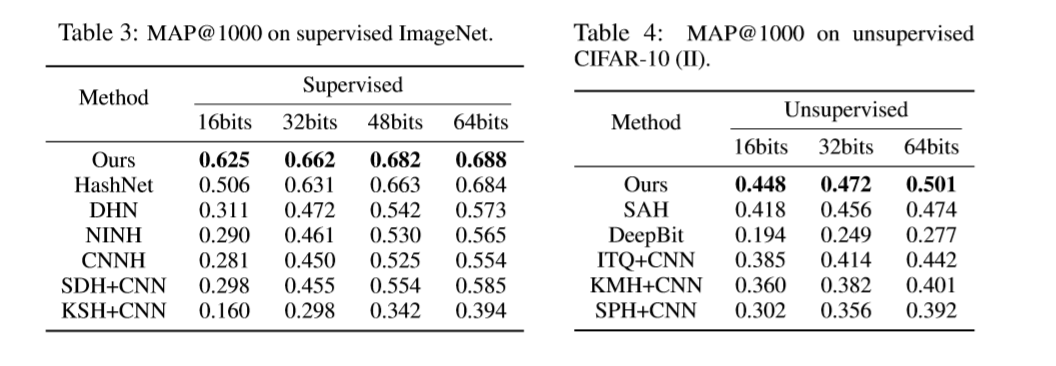
效果 :

——CVPR——
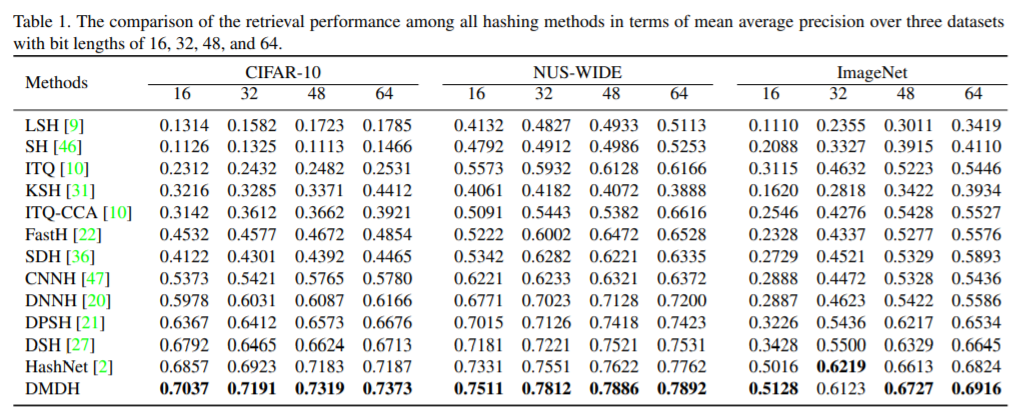
Deep Hashing via Discrepancy Minimization(DMDH)
也是为了解决NP难的哈希离散优化问题。
效果:
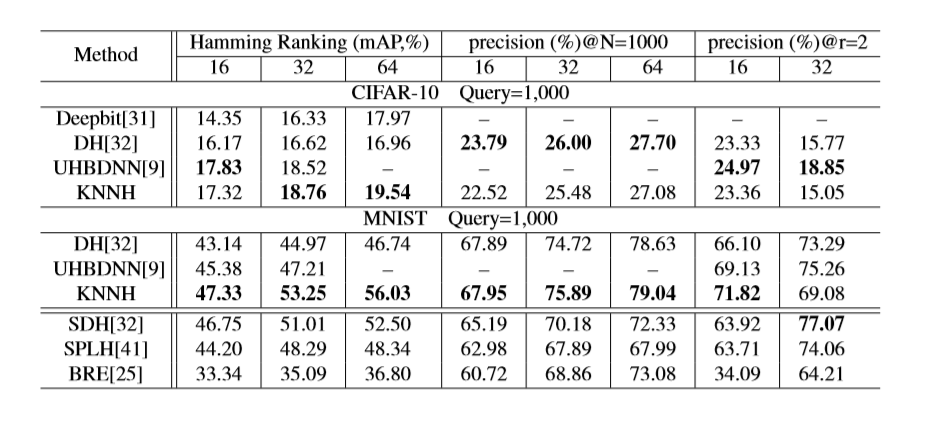
K-Nearest Neighbors Hashing(KNNH)

效果:
在MNIST和CIFAR10数据集上进行实验,KNNH几乎在每个标准上都优于其他代表性的无监督散列方法。

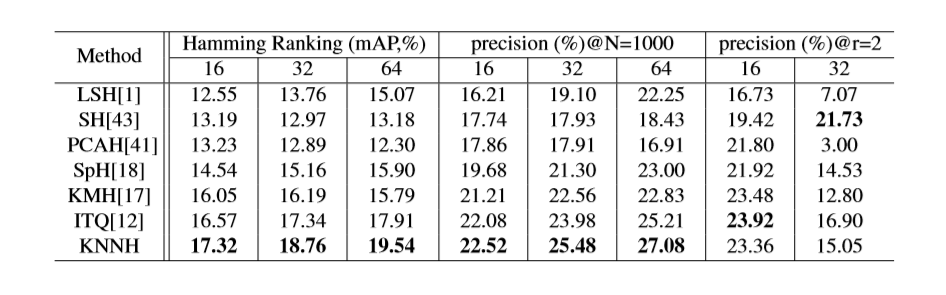
和深度无监督方法相比也有一定的竞争力,甚至 在MNIST数据集上超过了一些深度有监督方法。
DistillHash
一种深度无监督的哈希
——ICIP——
PDH:PROBABILISTIC DEEP HASHING BASED ON MAP ESTIMATIONOF HAMMING DISTANCE
通过图像的概率分布产生不带超参的损失函数,通过生成使此损失函数最小化的哈希码,执行图像检索。
——ECCV——
ForestHash: Semantic Hashing With Shallow Random Forests and Tiny Convolutional Networks
将微小随机网络嵌入到随机森林中,为同一语义的数据类提供一致的哈希码。
使用矩阵核范数学习子空间的线性变换。聚合过程以贪婪的方式执行。
——IJCAI——
18_SSDH(Semantic Structurebased unsupervised Deep Hashing)基于语义结构的无监督深度哈希
网络结构:VGG-F

 浙公网安备 33010602011771号
浙公网安备 33010602011771号