
《Distributed Learning with Random Features》阅读笔记
---恢复内容开始---
- Kernel ridge regression(KRR)
期望误差:
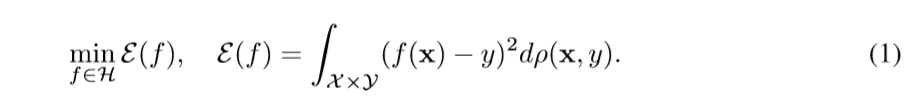
目标是最小化期望误差:

求导得到结果(?和核函数有什么关系嘞?)
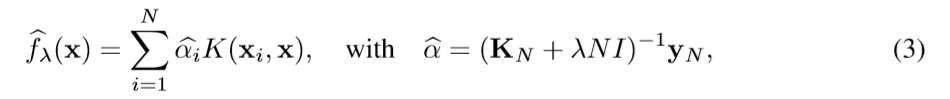 当n规模很大时,通过矩阵转置计算线性系统需要的时间和空间都会很大,因此提出了一些加速方法:
当n规模很大时,通过矩阵转置计算线性系统需要的时间和空间都会很大,因此提出了一些加速方法:
(1)divide & conquer
(2) 随机投影比如nystrom,降低数据维度
本文结合了两种方法:
KRR-DC——
在数据集的子集Dj上,估计结果:
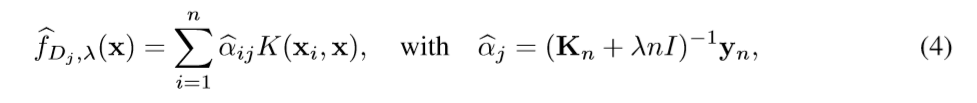
最后的结果是这些分块估计结果的平均值

KRR-DC-RF
随机特征方法的基本思想是通过显示的特征映射近似正定核。
************************随机特征************************
将数据映射到相对低维的随机特征空间,将核机器的训练和评估工作转换为线性机器的相关工作。
![]()
z(x)和不同,z(x)是低维的。
文章介绍了两种随机特征映射,第一种是随机傅里叶变换,基于z(x) = cos(ω’x + b) 。
随机映射z(x)将x映射到一个随机方向w的直线上,再转换成单位圆。

w是从正态分布中随机选取的,b是从二项分布中随机选取的,由w和b可以计算z(x),进而估计k(x,y)。
************************************************************************************
![]()
![]()
---恢复内容结束---
- Kernel ridge regression(KRR)
期望误差:
目标是最小化期望误差:
求导得到结果(?和核函数有什么关系嘞?)
当n规模很大时,通过矩阵转置计算线性系统需要的时间和空间都会很大,因此提出了一些加速方法:
(1)divide & conquer
(2) 随机投影比如nystrom,降低数据维度
本文结合了两种方法:
KRR-DC——
在数据集的子集Dj上,估计结果:
最后的结果是这些分块估计结果的平均值
KRR-DC-RF
随机特征方法的基本思想是通过显示的特征映射近似正定核。
**********************************************************随机特征*********************************************************************
将数据映射到相对低维的随机特征空间,将核机器的训练和评估工作转换为线性机器的相关工作。
![]()
z(x)和不同,z(x)是低维的。
文章介绍了两种随机特征映射,第一种是随机傅里叶变换,基于z(x) = cos(ω’x + b) 。
随机映射z(x)将x映射到一个随机方向w的直线上,再转换成单位圆。
w是从正态分布中随机选取的,b是从二项分布中随机选取的,由w和b可以计算z(x),进而估计k(x,y)。
************************************************************************************************************************************************
![]()
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号