
Ceph集群的使用和操作记录
这里我们还是基于之前ceph-deploy部署的环境进行测试。直接的部署参考链接:https://www.cnblogs.com/qingbaizhinian/p/14011475.html#_label1_3
之前机器环境参考下面的截图

1.存储池的介绍
之前在介绍ceph资源划分和存储过程描述的时候,没有介绍存储池的概念,这边我们来介绍一下:
关于存储池的详细知识点,可以多多参考中文社区文档:http://docs.ceph.org.cn/rados/operations/pools/#set-pool-values
1.关于存储池的概念
Ceph 存储系统支持“池”概念,存储池是Ceph中一些对象的逻辑分组。它不是一个连续的分区,而是一个逻辑概念,类似LVM中的卷组(Volume Group)。
Ceph 客户端从监视器获取一张集群运行图(集群内的所有监视器、 OSD 、和元数据服务器节点分布情况),并把对象写入存储池poll。存储池的 size 或副本数、 CRUSH 规则集和归置组数量决定着 Ceph 如何放置数据。
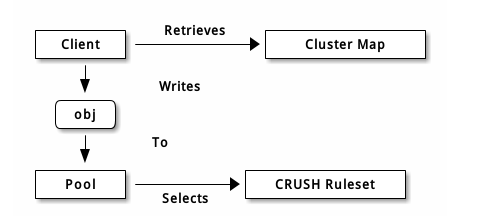
存储池至少可设置以下参数:
- 对象的所有权/访问权限;
- 归置组数量;以及,
- 使用的 CRUSH 规则集。
如果你开始部署集群时没有创建存储池, Ceph 会用默认存储池存数据。存储池提供的功能:
- 自恢复力: 你可以设置在不丢数据的前提下允许多少 OSD 失效,对多副本存储池来说,此值是一对象应达到的副本数。典型配置存储一个对象和它的一个副本(即 size = 2 ),但你可以更改副本数;对纠删编码的存储池来说,此值是编码块数(即纠删码配置里的 m=2 )。
- 归置组: 你可以设置一个存储池的归置组数量。典型配置给每个 OSD 分配大约 100 个归置组,这样,不用过多计算资源就能得到较优的均衡。配置了多个存储池时,要考虑到这些存储池和整个集群的归置组数量要合理。
- CRUSH 规则: 当你在存储池里存数据的时候,与此存储池相关联的 CRUSH 规则集可控制 CRUSH 算法,并以此操纵集群内对象及其副本的复制(或纠删码编码的存储池里的数据块)。你可以自定义存储池的 CRUSH 规则。
- 快照: 用 ceph osd pool mksnap 创建快照的时候,实际上创建了某一特定存储池的快照。
- 设置所有者: 你可以设置一个用户 ID 为一个存储池的所有者。
要把数据组织到存储池里,你可以列出、创建、删除存储池,也可以查看每个存储池的利用率。
2.存储池存储数据过程和建议
PG 映射到 OSD
每个存储池都有很多归置组, CRUSH 动态的把它们映射到 OSD 。 Ceph 客户端要存对象时, CRUSH 将把各对象映射到某个归置组。
把对象映射到归置组在 OSD 和客户端间创建了一个间接层。由于 Ceph 集群必须能增大或缩小、并动态地重均衡。如果让客户端“知道”哪个 OSD 有哪个对象,就会导致客户端和 OSD 紧耦合;相反, CRUSH 算法把对象映射到归置组、然后再把各归置组映射到一或多个 OSD ,这一间接层可以让 Ceph 在 OSD 守护进程和底层设备上线时动态地重均衡。下列图表描述了 CRUSH 如何将对象映射到归置组、再把归置组映射到 OSD 。
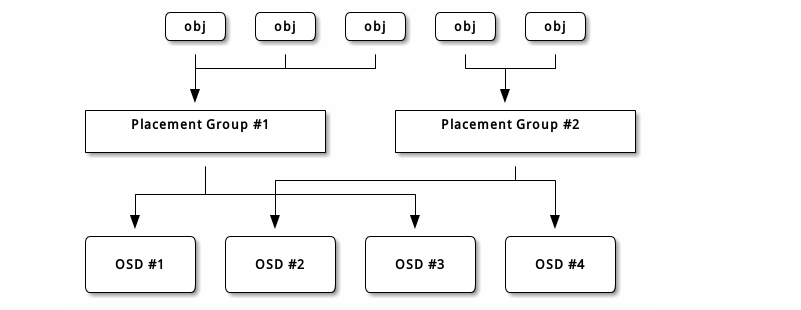
有了集群运行图副本和 CRUSH 算法,客户端就能精确地计算出到哪个 OSD 读、写某特定对象。
在生产中,一个Pool里设置的PG数量是预先设置的,PG的数量不是随意设置,需要根据OSD的个数及副本策略来确定,线上尽量不要更改PG的数量,PG的数量的变更将导致整个集群动起来(各个OSD之间copy数据),大量数据均衡期间读写性能下降严重;
预先规划Pool的规模,设置PG数量;一旦设置之后就不再变更;后续需要扩容就以 Pool 为维度为扩容,通过新增Pool来实现(Pool通过 crushmap实现故障域隔离);
3.存储池相关命令介绍
#列出集群中的存储池,在新安装好的集群上,只有一个 rbd 存储池。但是ceph-deploy安装的没有创建创建存储池 [root@ceph-deploy ~]# ceph osd lspools
#在ceph集群中创建一个pool,下面的test-pool是你自己定义的存储池名称,第一个128是指PG,第二个128是指PGP,
具体两者的区别可以参考下面的我后面的解释
[root@ceph-deploy ~]# ceph osd pool create test-pool 128 128
pool 'test-pool' created
#设置存储池配额,存储池配额可设置最大字节数、和/或每存储池最大对象数。要取消配额,设置为 0 。
[root@ceph-deploy ~]# ceph osd pool set-quota test-pool max_objects 10000 #这里是设置最大对象数为10000
[root@ceph-deploy ~]# ceph osd pool set-quota test-pool max_bytes 10000000000000 #这里设置最大存储空间为10T
#删除存储池,(集群名字需要重复两次),注意如果你给自建的存储池创建了定制的规则集,你不需要存储池时最好删除它。
如果你曾严格地创建了用户及其权限给一个存储池,但存储池已不存在,最好也删除那些用户。
[root@ceph-deploy ~]# ceph osd pool delete test-pool test-pool --yes-i-really-really-mean-it
#注意在执行上面命令删除存储池过程中出现下面的错误,需要到mon节点的配置文件/etc/ceph/ceph.conf里添加或修改如下一行mon allow pool delete = true
然后执行systemctl restart ceph-mon.target重启ceph-mon服务
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
#显示集群中pool的详细信息
[root@ceph-deploy ~]# rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR
test-pool 0 B 0 0 0 0 0 0 0 0 B 0 0 B
total_objects 0
total_used 3.7 GiB
total_avail 86 GiB
total_space 90 GiB
#给一个pool创建一个快照,前面test-pool是存储池名,后面test-pool-snap是你自己指定的快照名
[root@ceph-deploy ~]# ceph osd pool mksnap test-pool test-pool-snap
created pool test-pool snap test-pool-snap
#删除pool的快照
[root@ceph-deploy ~]# ceph osd pool rmsnap test-pool test-pool-snap
#查看存储池中PG的数量
[root@ceph-deploy ~]# ceph osd pool get test-pool pg_num
pg_num: 128
#设置存储池的副本数为3
[root@ceph-deploy ~]# ceph osd pool set test-pool size 3
#设置data池能接受写操作的最小副本为2
[root@ceph-deploy ~]# ceph osd pool set test-pool min_size 2
#要获取对象副本数,执行命令:
[root@ceph-deploy ~]# ceph osd dump | grep 'replicated size'
存储池中PG和PGP概念的区别和理解:
- PG是指定存储池存储对象的目录有多少个,PGP是存储池PG的OSD分布组合个数
- PG的增加会引起PG内的数据进行分裂,分裂到相同的OSD上新生成的PG当中
- PGP的增加会引起部分PG的分布进行变化,但是不会引起PG内对象的变动
简单理解就是我们把PG的值理解成一个口袋,然后口袋里面装的是对象数据,然后OSD就相当于一个箱子。对象数据装入口袋,口袋装入箱子。现在对象数据的量是固定的,如果PG设为1个,也就是对象数据都会放在一个口袋里,然后放在箱子里,如果PG数量增加了,那么其实加的是口袋的数量,也就是之前可能一个箱子内放的是一个口袋,现在放了两个口袋,但是对象数据的量是固定的啊,所以就会根据算法,把对象数据放到新的口袋,但是这种变化是在一个箱子内部的,并不是跨箱子的。然后PGP的值可以理解成口袋的分布的一个指定。这样可能不好理解,你可以这样理解,本身一共有12个口袋,然后PGP的值是6,那么这12个口袋就会均匀的分布在6个箱子里面,每个箱子两个,这个时候如果把PGP设为12个,那么就会自动的从每个箱子里拿出一共口袋,放到新的箱子里来。这种变化是跨箱子的。
确定pg_num取值是强制性的,因为不能自动计算。下面是几个常用的值:
•少于5 个OSD 时可把pg_num设置为128•OSD
数量在5 到10 个时,可把pg_num设置为512•OSD
数量在10 到50 个时,可把pg_num设置为4096•OSD
数量大于50 时,你得理解权衡方法、以及如何自己计算pg_num取值
2.块设备的快速入门
1.安装ceph客户端
Ceph块设备,以前称为RADOS块设备,为客户机提供可靠的、分布式的和高性能的块存储磁盘。RADOS块设备利用librbd库并以顺序的形式在Ceph集群中的多个osd上存储数据块。RBD是由Ceph的RADOS层支持的,因此每个块设备都分布在多个Ceph节点上,提供了高性能和优异的可靠性。RBD有Linux内核的本地支持,这意味着RBD驱动程序从过去几年就与Linux内核集成得很好。除了可靠性和性能之外,RBD还提供了企业特性,例如完整和增量快照、瘦配置、写时复制克隆、动态调整大小等等。RBD还支持内存缓存,这大大提高了其性能:

任何普通的Linux主机(RHEL或基于debian的)都可以充当Ceph客户机。客户端通过网络与Ceph存储集群交互以存储或检索用户数据。CephRBD支持已经添加到Linux主线内核中,从2.6.34和以后的版本开始
#我们之间在之前的ceph-deploy节点上演示客户端挂载块设备,如果是其他节点,执行的命令都一样,我们先安装ceph [root@ceph-deploy ~]# ceph-deploy install ceph-deploy #接下来用 ceph-deploy 把 Ceph 配置文件和 ceph.client.admin.keyring 拷贝到 ceph-deploy节点上。 [root@ceph-deploy ~]# ceph-deploy admin ceph-deploy #上面命令,ceph-deploy 工具会把密钥环复制到 /etc/ceph 目录,要确保此密钥环文件有读权限。我们可以执行下面命令 [root@ceph-deploy ~]#chmod +r /etc/ceph/ceph.client.admin.keyring
2.环境检查
#检查内核版本是否符合要求
需要注意:
1、linux内核从2.6.32版本开始支持ceph
2、建议使用2.6.34以及以上的内核版本[root@ceph-deploy ceph]# uname -r 4.4.248-1.el7.elrepo.x86_64 #检查环境是否支持RBD [root@ceph-deploy ceph]# modprobe rbd [root@ceph-deploy ceph]# echo $? 0
3.客户端创建块设备及映射和取消映射删除块设备
#默认创建块设备,会直接创建在rbd池中,但使用deploy 安装后,该rbd池并没有创建。所以我们这里创建rbd存储池,并初始化
[root@ceph-deploy ~]# ceph osd pool create rbd 128
[root@ceph-deploy ~]# rbd pool init rbd
#下面命令会创建一个名为test-rbd1,大小为10G的块设备镜像。这里--image-feature的作用是在创建块设备的时候指明需要的特性。
不然后面可能出一下报错。上面讲了默认块存储建子啊rbd池中,这里可以通过-p参数改变池 [root@ceph-deploy ~]# rbd create --size 10240 test-rbd1 --image-feature layering #列出现在集群中有哪些rbd设备镜像
[root@ceph-deploy ~]# rbd ls test-rbd1 #查看创建后的块设备的信息
[root@ceph-deploy ~]# rbd --image test-rbd1 info rbd image 'test-rbd1': size 10 GiB in 2560 objects order 22 (4 MiB objects) id: 5e7b6b8b4567 block_name_prefix: rbd_data.5e7b6b8b4567 format: 2 features: layering op_features: flags: create_timestamp: Tue Jan 12 15:35:57 2021 #通过下面命令把创建好的块设备镜像映射到本地。
[root@ceph-deploy ~]# rbd map --image test-rbd1
#映射过程中我们发现以下报错。
rbd: sysfs write failed In some cases useful info is found in syslog - try "dmesg | tail". rbd: map failed: (110) Connection timed out
#按报错提示,我们执行下面命令,发现出错的原因
[root@ceph-deploy ~]# dmesg |tail
[535525.898069] libceph: mon0 172.31.46.63:6789 feature set mismatch, my 106b84a842a42 < server's 40106b84a842a42, missing 400000000000000
[535525.898128] libceph: mon0 172.31.46.63:6789 missing required protocol features
#解决过程如下
1.修改Ceph配置文件/etc/ceph/ceph.conf(集群中每个节点都要改),在global section下,增加
rbd_default_features = 1
2.然后重启ceph守护进程(每个节点都做) systemctl stop ceph.target systemctl start ceph.target 3.关闭不需要的特性
[root@ceph-deploy ~]# ceph osd crush tunables hammer adjusted tunables profile to hammer #然后重新执行映射
[root@ceph-deploy ~]# rbd map --image test-rbd1 /dev/rbd0 #查看块设备的映射信息
[root@ceph-deploy ~]# rbd showmapped id pool image snap device 0 rbd test-rbd1 - /dev/rbd0 #接下来我们就可以按正常硬盘来进行格式化使用了
[root@ceph-deploy ~]# fdisk -l [root@ceph-deploy ~]# mkfs.ext4 /dev/rbd0 [root@ceph-deploy ~]# mkdir /test-rbd [root@ceph-deploy ~]# mount /dev/rbd0 /test-rbd/
#如果想把块设备进行扩容,可以执行下面的命令,下面的命令表示把test-rbd1这个块设备扩容到20G
[root@ceph-deploy ~]# rbd resize --size 20480 test-rbd1
#扩容完块设备后,还需要执行下面命令,对块设备磁盘进行文件系统在线扩容
[root@ceph-deploy ~]# resize2fs /dev/rbd0
#通过下面的几条命令取消映射块设备,和删除块设备
[root@ceph-deploy ~]# umount /test-rbd/ #取消映射
[root@ceph-deploy ~]# rbd unmap /dev/rbd/rbd/test-rbd1#查看是否取消成功,如没有任何输出则表示取消映射成功
[root@ceph-deploy ~]# rbd showmapped
#删除块设备并检查 [root@ceph-deploy ~]# rbd rm test-rbd1 Removing image: 100% complete...done. [root@ceph-deploy ~]# rbd ls
3.文件系统的快速入门
这里我们还是ceph的部署管理节点演示如何使用的ceph的文件存储。
#CephFs需要用到MDS服务,所以我们这里需要在集群中部署mds服务,我们这里选择部署在node1节点上
[manager@ceph-deploy my-cluster]$ ceph-deploy mds create node1 #一个 Ceph 文件系统需要至少两个 RADOS 存储池,一个用于数据、一个用于元数据。配置这些存储池时需考虑:
- 为元数据存储池设置较高的副本水平,因为此存储池丢失任何数据都会导致整个文件系统失效。
- 为元数据存储池分配低延时存储器(像 SSD ),因为它会直接影响到客户端的操作延时。
#创建数据pool,名字叫cephfs_data
[manager@ceph-deploy my-cluster]$ ceph osd pool create cephfs_data 64
#创建元数据池,名字叫cephfs_metadata [manager@ceph-deploy my-cluster]$ ceph osd pool create cephfs_metadata 64 #创建好存储池后,你就可以用 fs new 命令创建文件系统了(如下)
ceph fs new cephfs cephfs_metadata cephfs_data #通过下面几条命令,查看mds,存储池pool,CephFS
[manager@ceph-deploy my-cluster]$ ceph mds stat cephfs-1/1/1 up {0=node1=up:active} [manager@ceph-deploy my-cluster]$ ceph osd pool ls cephfs_data cephfs_metadata [manager@ceph-deploy my-cluster]$ ceph fs ls name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ] [manager@ceph-deploy my-cluster]$ ceph -s cluster: id: a3da0081-4306-4b89-b1aa-45db06909d43 health: HEALTH_OK services: mon: 1 daemons, quorum node1 mgr: node1(active), standbys: node3, node2 mds: cephfs-1/1/1 up {0=node1=up:active} osd: 3 osds: 3 up, 3 in data: pools: 2 pools, 128 pgs objects: 22 objects, 2.2 KiB usage: 3.0 GiB used, 87 GiB / 90 GiB avail pgs: 128 active+clean #创建用户名为cephfs的用户,并为mon,mds,osd分配权限,并指定pool(可选,因为部署时已经生成了一个admin的key,这里我们新建一个)
[manager@ceph-deploy my-cluster]$ ceph auth get-or-create client.cephfs mon 'allow r' mds 'allow r, allow rw path=/' osd 'allow rw pool=cephfs_data' -o ceph.client.cephfs.keyring #查看生成的密钥
[manager@ceph-deploy my-cluster]$ cat ceph.client.cephfs.keyring [client.cephfs] key = AQCSZv5fynH1AhAAMF7BYivQwGTOdUZDihuNYg== #因为我们这里就是在部署管理节点上进行文件存储挂载的演示,如果是其他节点进行挂载的,还需要执行下面的命令把密钥文件拷贝到对应节点(可以不拷贝到客户机上,客户机挂载时只需使用上面key里面的内容即可),
记住客户机上一定需要部署ceph(部署过程就不演示了,可以参考上面块存储一开始安装ceph的步骤)
scp ceph.client.cephfs.keyring root@234.234.234.234:/etc/ceph
#一般Ceph我们都启用了Ceph 认证所有挂载的时候需要name 和secret ceph.client.cephfs.keyring文件信息,可通过下面的命令检查是否开启的验证,cephx表示开启
了验证
[manager@ceph-deploy my-cluster]$ cat /etc/ceph/ceph.conf | grep auth | grep required auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx #通过下面命令把key保存在文件里,用于下面的内核驱动形式挂载。
[root@ceph-deploy ceph]# echo AQCSZv5fynH1AhAAMF7BYivQwGTOdUZDihuNYg== > /etc/ceph/cephfskey #ceph文件存储挂载分为通过内核驱动挂载和FUSE客户端两种方式挂载。
#下面我们命令我们演示的是有认证情况下,通过内核驱动是如何挂载的,如果没有认证,就不用指定-o以及后面的参数,这里node1为mds的主节点。
[root@ceph-deploy ceph]# mount -t ceph node1:6789:/ /cephfs/ -o name=cephfs,secretfile=/etc/ceph/cephfskey
#如果想要开机挂载,执行下面命令就行了。
[root@node2 ~]# echo "node1:6789:/ /cephfs ceph name=cephfs,secretfile=/etc/ceph/cephfskey,_netdev,noatime 0 0" >> /etc/fstab
#fuse客户端挂载,这种适用于内核低于2.6.34的,或者您有任何应用程序依赖项,
#首先我们配置好ceph的yum源,这里不演示了,然后执行下面命令安装fuse客户端
[root@ceph-deploy ~]# yum install ceph-fuse -y
#把ceph 服务器上生成的cephfskey复制到客户端,因为我就是在部署管理节点进行演示的,所以不用复制,然后通过下面的命令指定key进行fuse客户端挂载。
不指定key文件挂载(默认回去/etc/ceph/目录下找 对应的用户名key文件)[root@ceph-deploy ~]# ceph-fuse --keyring /home/manager/my-cluster/ceph.client.cephfs.keyring --name client.cephfs -m 172.31.46.63:6789 /cephfs2
#fuse客户端开机挂载,可以执行下面命令,因为 keyring文件包含了用户名,所以fstab不需要指定用了
[root@ceph-deploy ~]# echo "id=cephfs,keyring=/home/manager/my-cluster/ceph.client.cephfs.keyring /cephfs2 fuse.ceph defaults 0 0 _netdev" >> /etc/fstab

 浙公网安备 33010602011771号
浙公网安备 33010602011771号