敏捷冲刺五
Task1:团队TSP
| 团队任务 |
预估时间 |
实际时间 |
完成日期 |
| 搜索引擎相关内容了解 |
300 |
500 |
11-5 |
| 数据库表的创建 |
180 |
150 |
11-5 |
| 学院网站的爬取 |
210 |
460 |
11-10 |
| 建立数据库索引 |
190 |
230 |
11-12 |
| 代码测试 |
180 |
-- |
-- |
| 前端页面的设计 |
240 |
-- |
-- |
| 前后端的交互 |
300 |
-- |
-- |
| 搜索引擎测试 |
260 |
-- |
-- |
Task2:描述项目进展
| 成员 |
任务安排 |
预期任务量/小时 |
| 秦玉(组长) |
与队员一起继续编写代码突破难关,补全之前的博客欠缺的地方 |
180 |
| 陈晓菲 |
与队员一起继续编写代码突破难关,补全之前的博客欠缺的地方 |
180 |
| 韩烨 |
前端模板的设计,补全之前的博客欠缺的地方 |
180 |
| 姚雯婷 |
分析学院页面结构,并且编写爬虫代码,能爬取页面后开始写分词器 |
180 |
| 罗佳 |
完成团队TSP表格,完成第五次冲刺博客园,配置完环境跟上进度 |
180 |
| 高天 |
完成需要在课堂上展示的ppt,继续编写代码突破难关 |
180 |
Task3:目前面临的困难
- 最开始爬取到的页面只有十几条,肯定不对啊,然后仔细检查代码,查看学院网页的头,发现其实学院网页的头不是每个都是/info开头的,有些是content,所以我们删去了/info
if url.startswith("http://cec.jmu.edu.cn/info"):
yield Request(url,callback=self.parse_content)
- 仔细比对学院网站源码后发现,只能爬取红色标题网页的原因是学院网站网页格式不统一,在解析网页时需要在多加一些或判断。我们打开学校网站的链接,一个一个的看标题,发现红字的是加了span标签的内容,取掉span之后就能爬取黑色标题的内容,但是红色标题的网页名会是空
#item_loader.add_xpath("title", "//td[@class='titlestyle124904']/span/text()")
- 当我们同时用这两句抓取的时候就可以同时抓到红黑两种,但是我们觉得抓取还是一次就好,不然强行增加运行时间,所以我们查了下xpath的语法,发现用 | 就可以同时爬取红黑标题的内容了,最后发现其实我们学院只有43条页面,其他的都连接到教务处或者科研中心,网页的格式就不一样了。
- 利用elassticsearch搭建搜索引擎,目前还在编写中。IKanalyzer、ansj_seg、jcseg三种中文分词器,了解了各种分词器的功能,最终我们选择了标准分词器 IKanalyzer,发现如果直接使用elassticsearch在处理中文内容的搜索时遇到很尴尬的问题——中文词语被分成了一个一个的汉字,发现原来这是因为使用了Elasticsearch中默认的标准分词器,这个分词器在处理中文的时候会把中文单词切分成一个一个的汉字,因此引入es之中文的分词器插件es-ik就能解决这个问题。
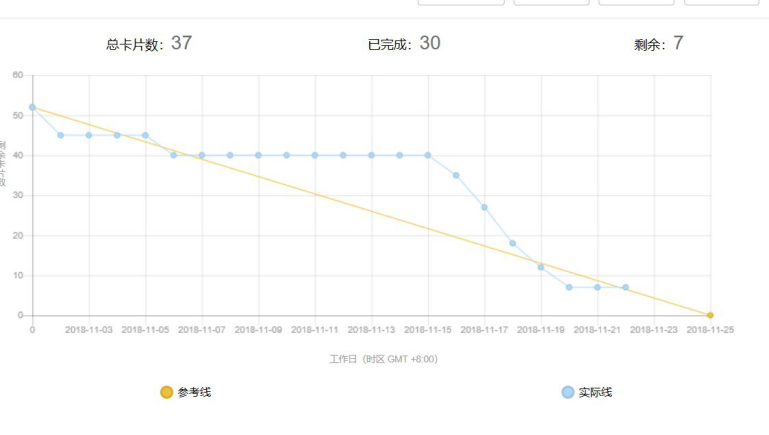
Task4:项目燃尽图
![]()
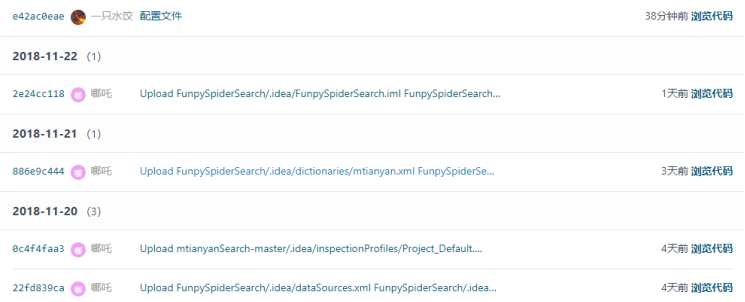
Task5:提交历史截图
![]()
Task6:站立式会议照片
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号