
敏捷冲刺二
敏捷冲刺二
Task1:团队TSP
| 团队任务 | 预估时间 | 实际时间 | 完成日期 |
|---|---|---|---|
| 搜索引擎相关内容了解 | 300 | 500 | 11-5 |
| 数据库表的创建 | 180 | 150 | 11-8 |
| 学院网站的爬取 | 210 | -- | -- |
| 建立数据库索引 | 190 | -- | -- |
| 代码测试 | 180 | -- | -- |
| 前端页面的设计 | 240 | -- | -- |
| 前后端的交互 | 300 | -- | -- |
| 搜索引擎测试 | 260 | -- | -- |
Task2:描述项目进展
| 成员 | 任务安排 | 预期任务量/小时 |
|---|---|---|
| 秦玉(组长) | 配置Elasticsearch-analysis-ik插件、安装ELasticSearch,配置Elasticsearch-analysis-ik插件,安装Redis 、完成第二次冲刺博客园 | 200 |
| 陈晓菲 | 配置Elasticsearch-analysis-ik插件、安装ELasticSearch,配置Elasticsearch-analysis-ik插件,安装Redis, Django、完成第二次冲刺博客园 | 200 |
| 韩烨 | 了解服务器的部署 | 140 |
| 姚雯婷 | 配置Elasticsearch-analysis-ik插件、安装ELasticSearch,配置Elasticsearch-analysis-ik插件,安装Redis | 200 |
| 罗佳 | 学习爬虫原理,并实践、初步编写代码 | 160 |
| 高天 | 学习爬虫原理,并实践、初步编写代码 | 160 |
Task3:目前面临的困难
本次整个团队重点在配置搜索引擎的运行环境,我们使用的环境如下:
- web服务器选择:Apache HTTP Server
- 前端框架 bootstrap
- python框架:Django+vue.js
在配置环境的过程中,因为在冲刺一时确定了整个框架,但是没有沟通好版本细节上,导致本次会议中有大半时间用来协调统一组内已安装的软件的版本。除此之外在配置环境上也是比较耗时间的,一旦出现报错,需要很久才可以完成。
Task4:成果及展望
目前取得的成果
1.配置完项目所需环境
- Elasticsearch
- Elasticsearch-analysis-ik插件
- Redis
- Django
2.爬虫初步实现
参考网上的资料,最后决定用Scrapy 框架:
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
- Scrapy 使用了 Twisted异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
Scrapy框架抓取的基本流程大概是这样:
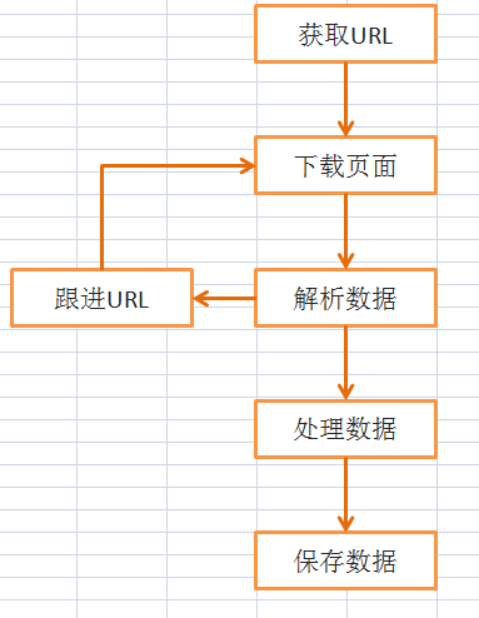
3.数据库的建立
| 字段名 | 解释 | 用途 |
|---|---|---|
| title | 文章标题 | 用来之后创建索引,拆分作为关键字 |
| create_date | 创建时间 | -- |
| url | 文章路径 | 用于传给前端查询关键字的地址 |
| url_object_id | 路径id | -- |
| front_image_url | 文章图片 | -- |
| content | 文章内容 | 可以结合文章内容进行更精确的匹配 |
| crawl_time | 爬下数据的时间 | 记录本次更新的时间 |
PS:这是我们参考了一些大型网站的爬取信息中的数据库字段的建立设计的,但是后面发现我们学校的架构跟其他网站还是差很多的,大型网站一般靠使用css选择器进行内容的获取,但是我们学校的官网几乎是纯用表格进行布局的,所以后面可能还是会根据实际情况进行二次调整
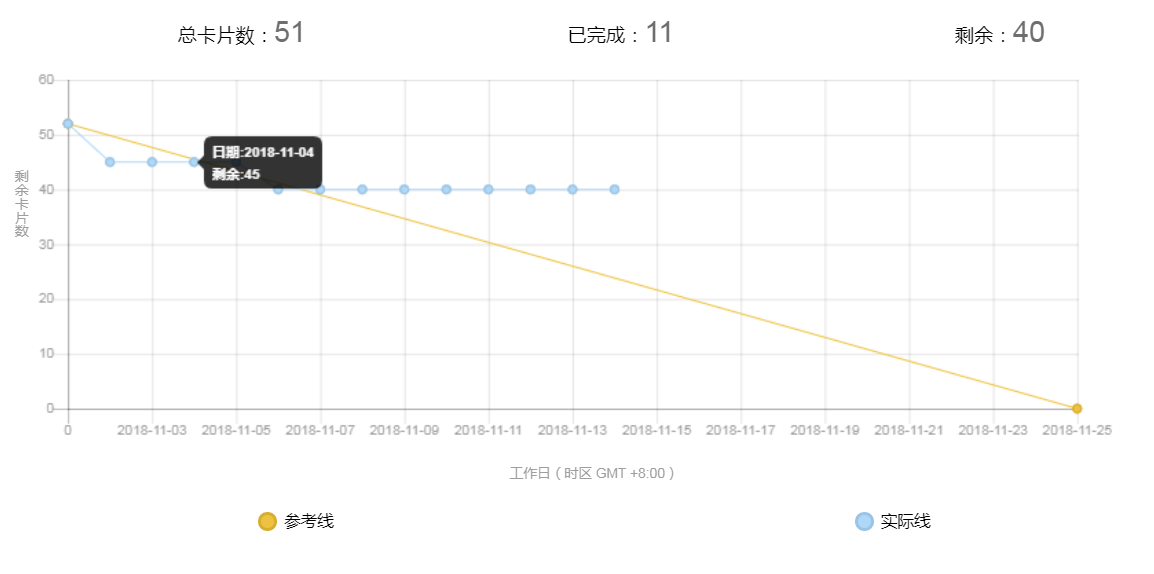
Task5:项目燃尽图
Task6:提交历史截图

Task7:站立式会议照片



 浙公网安备 33010602011771号
浙公网安备 33010602011771号