XML文件的读取
1 认识XML文件
表现:以“.xml”为文件扩展名的文件
存储:树形结构
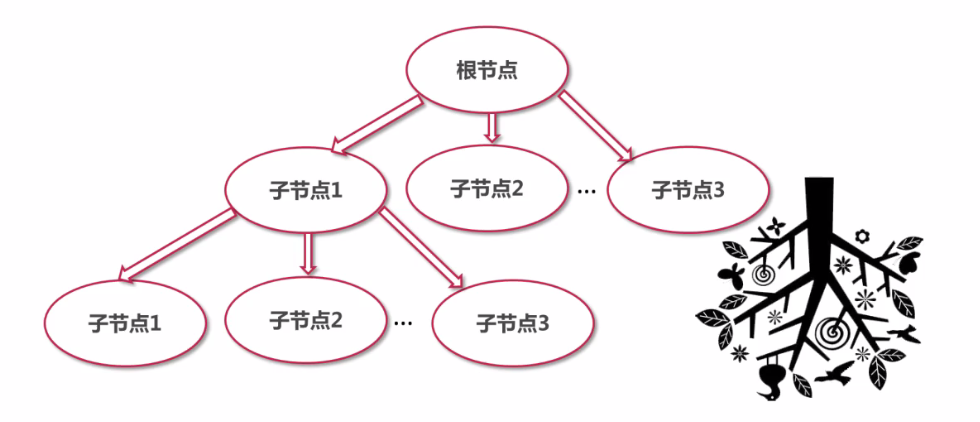
一个完整的XML文件格式如下所示:
1 <?xml version="1.0 encoding="UTF-8"?> 2 <根节点> 3 <节点1.1> 4 <节点1.1.1>对应值1.1.1</节点1.1.1> 5 <节点1.1.2>对应值1.1.2</节点1.1.2> 6 <节点1.1.3>对应值1.1.3</节点1.1.3> 7 <节点1.1.4>对应值1.1.4</节点1.1.4> 8 </节点1.1> 9 <节点1.2> 10 <节点1.2.1>对应值1.2.1</节点1.2.1> 11 <节点1.2.2>对应值1.2.2</节点1.2.2> 12 <节点1.2.3>对应值1.2.3</节点1.2.3> 13 <节点1.2.4>对应值1.2.4</节点1.2.4> 14 </节点1.2> 15 </根节点>
注:如果有中文汉字,请设置为GBK编码方式,否则报错。
为什么使用XML?
- 不同应用程序之间的通信
- 不同平台之间的通信
- 不同平台之间数据的共享
2 解析XML文件
四种解析方式:
- DOM(Java官方提供)
- SAX(Java官方提供)
- DOM4J(第三方jar)
- JDOM(第三方jar)
2.1 DOM解析方式
2.1.1 准备工作
- 创建一个DocumentBuilderFactory对象
- 创建一个DocumentBuilder对象
- 通过DocumentBuilder对象的parse(String fileName)方法解析XML文件
2.1.2 使用DOM解析文件的属性名和属性值
包括:
- 解析文件的属性名和属性值
- 解析文件的节点名和节点值
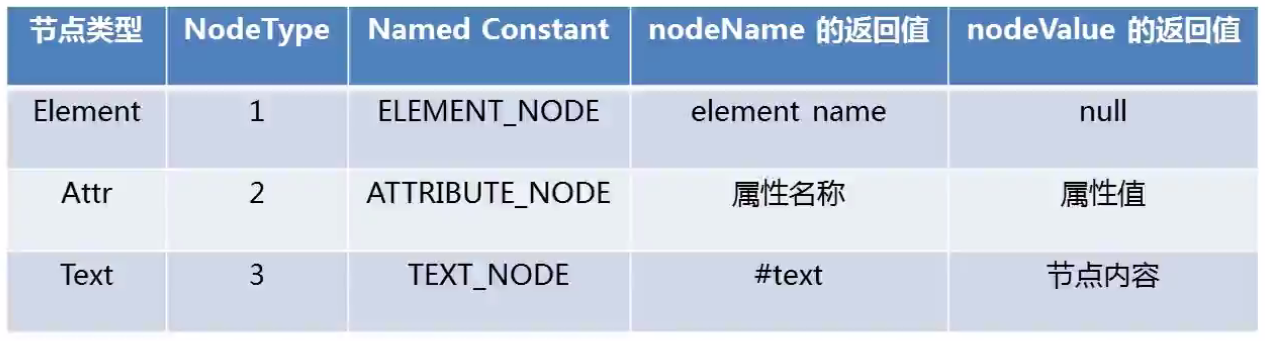
注:根节点不需要解析
2.1.3 实例
如下所述XML文件:
1 <?xml version="1.0" encoding="GBK"?> 2 <bookstore> 3 <book id="1"> 4 <name>冰与火之歌</name> 5 <author>乔治马丁</author> 6 <year>2014</year> 7 <price>89</price> 8 </book> 9 <book id="2"> 10 <name>安徒生童话</name> 11 <year>2004</year> 12 <price>77</price> 13 <language>English</language> 14 </book> 15 </bookstore>
DOM解析程序:
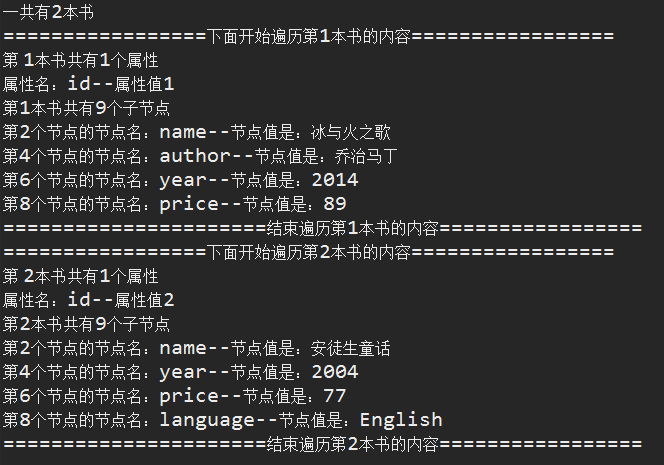
1 package com.dom.test; 2 3 import java.io.IOException; 4 5 import javax.xml.parsers.DocumentBuilder; 6 import javax.xml.parsers.DocumentBuilderFactory; 7 import javax.xml.parsers.ParserConfigurationException; 8 9 import org.w3c.dom.Document; 10 import org.w3c.dom.NamedNodeMap; 11 import org.w3c.dom.Node; 12 import org.w3c.dom.NodeList; 13 import org.xml.sax.SAXException; 14 15 public class DOMTest { 16 17 public static void main(String[] args) { 18 //创建一个DocumentBuilderFactory的对象 19 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); 20 //创建一个DocumentBuilder的对象 21 try { 22 //创建DocumentBuilder对象 23 DocumentBuilder db = dbf.newDocumentBuilder(); 24 //通过DocumentBuilder对象的parser方法加载books.xml文件到当前项目下 25 Document document = db.parse("books.xml"); 26 //获取所有book节点的集合 27 NodeList bookList = document.getElementsByTagName("book"); 28 //通过nodelist的getLength()方法可以获取bookList的长度 29 System.out.println("一共有" + bookList.getLength() + "本书"); 30 //遍历每一个book节点 31 for (int i = 0; i < bookList.getLength(); i++) { 32 System.out.println("=================下面开始遍历第" + (i + 1) + "本书的内容================="); 33 //通过 item(i)方法 获取一个book节点,nodelist的索引值从0开始 34 Node book = bookList.item(i); 35 // 获取book节点的所有属性集合 36 NamedNodeMap attrs = book.getAttributes(); 37 System.out.println("第 " + (i + 1) + "本书共有" + attrs.getLength() + "个属性"); 38 // 遍历book的属性 39 for (int j = 0; j < attrs.getLength(); j++) { 40 //通过item(index)方法获取book节点的某一个属性 41 Node attr = attrs.item(j); 42 //获取属性名 43 System.out.print("属性名:" + attr.getNodeName()); 44 //获取属性值 45 System.out.println("--属性值" + attr.getNodeValue()); 46 } 47 // //前提:已经知道book节点有且只能有1个id属性 48 // //将book节点进行强制类型转换,转换成Element类型 49 // Element book = (Element) bookList.item(i); 50 // //通过getAttribute("id")方法获取属性值 51 // String attrValue = book.getAttribute("id"); 52 // System.out.println("id属性的属性值为" + attrValue); 53 //解析book节点的子节点 54 NodeList childNodes = book.getChildNodes(); 55 //遍历childNodes获取每个节点的节点名和节点值 56 System.out.println("第" + (i+1) + "本书共有" + 57 childNodes.getLength() + "个子节点"); 58 for (int k = 0; k < childNodes.getLength(); k++) { 59 //区分出text类型的node以及element类型的node 60 if (childNodes.item(k).getNodeType() == Node.ELEMENT_NODE) { 61 //获取了element类型节点的节点名 62 System.out.print("第" + (k + 1) + "个节点的节点名:" 63 + childNodes.item(k).getNodeName()); 64 // 获取了element类型节点的节点值//再获取第一个子节点,再取值 65 System.out.println("--节点值是:" + childNodes.item(k).getFirstChild().getNodeValue()); 66 // //或直接获取值(但是若该节点下还有节点,获取的就不是正常值了) 67 // System.out.println("--节点值是:" + childNodes.item(k).getTextContent()); 68 } 69 } 70 System.out.println("======================结束遍历第" + (i + 1) + "本书的内容================="); 71 } 72 } catch (ParserConfigurationException e) { 73 e.printStackTrace(); 74 } catch (SAXException e) { 75 e.printStackTrace(); 76 } catch (IOException e) { 77 e.printStackTrace(); 78 } 79 } 80 }
运行结果:
2.2 DOM4J解析方式
DOM4J:一个第三方jar包。
DOM4J解析程序:
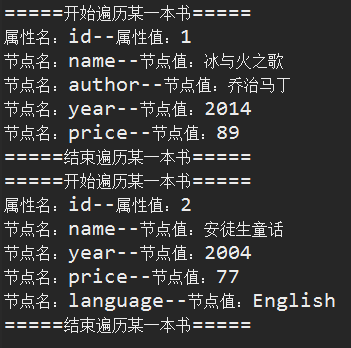
1 package com.dom4j.test; 2 3 import java.io.File; 4 import java.util.ArrayList; 5 import java.util.Iterator; 6 import java.util.List; 7 8 import org.dom4j.Attribute; 9 import org.dom4j.Document; 10 import org.dom4j.DocumentException; 11 import org.dom4j.Element; 12 import org.dom4j.io.SAXReader; 13 14 import com.dom4j.entity.Book; 15 16 public class DOM4JTest { 17 private static ArrayList<Book> bookList = new ArrayList<Book>(); 18 /** 19 * @param args 20 */ 21 public static void main(String[] args) { 22 // 解析books.xml文件 23 // 创建SAXReader的对象reader 24 SAXReader reader = new SAXReader(); 25 try { 26 // 通过reader对象的read方法加载books.xml文件,获取docuemnt对象。 27 Document document = reader.read(new File("src/res/books.xml")); 28 // 通过document对象获取根节点bookstore 29 Element bookStore = document.getRootElement(); 30 // 通过element对象的elementIterator方法获取迭代器 31 Iterator it = bookStore.elementIterator(); 32 // 遍历迭代器,获取根节点中的信息(书籍) 33 while (it.hasNext()) { 34 System.out.println("=====开始遍历某一本书====="); 35 Element book = (Element) it.next(); 36 // 获取book的属性名以及 属性值 37 List<Attribute> bookAttrs = book.attributes(); 38 for (Attribute attr : bookAttrs) { 39 System.out.println("属性名:" + attr.getName() + "--属性值:" 40 + attr.getValue()); 41 } 42 // 获取book的节点名和节点值 43 Iterator itt = book.elementIterator(); 44 while (itt.hasNext()) { 45 Element bookChild = (Element) itt.next(); 46 System.out.println("节点名:" + bookChild.getName() + "--节点值:" 47 + bookChild.getStringValue()); 48 } 49 System.out.println("=====结束遍历某一本书====="); 50 } 51 } catch (DocumentException e) { 52 // TODO Auto-generated catch block 53 e.printStackTrace(); 54 } 55 } 56 }
运行结果:
作者:祁俊辉
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号