MySQL(字段约束条件)
今日内容概要
字段约束条件
- 无符号、零填充
- 非空
- 默认值
- 唯一值
- 主键
- 自增
- 外键
🐳 无符号、零填充
unsined
id int unsigned
zerofill
id int (5) zerofill
🐳 非空
create table t1(
id int,
name varchar(16));
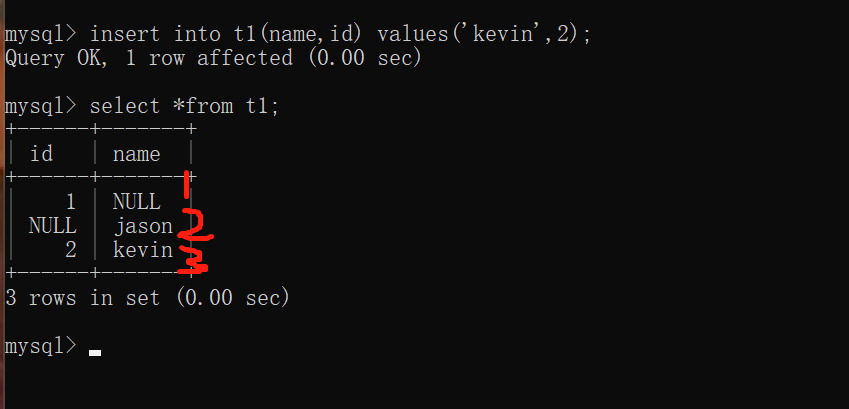
1.insert into t1(id) values(1);
2.insert into t1(name) values('jason');
3.insert into t1(name,id) values('kevin',2);
PS:所有字段类型不加约束条件的情况下默认都可以为空
create table t2(
id int,
name varchar(16) not null
);
insert into t2(id) values(1);
结果:ERROR 1364 (HY000): Field 'name' doesn't have a default value
insert into t2((name) values('jason');
结果:报错
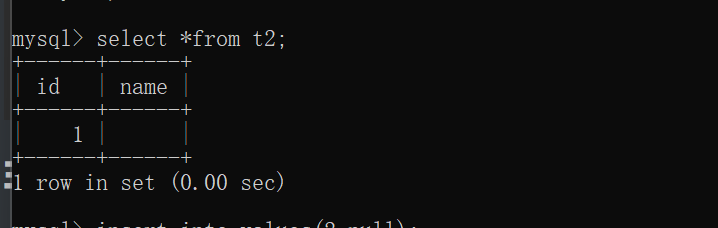
insert into t2 values(1,'');
结果:下图
insert into values(2,null);
结果:报错
🐳 默认值
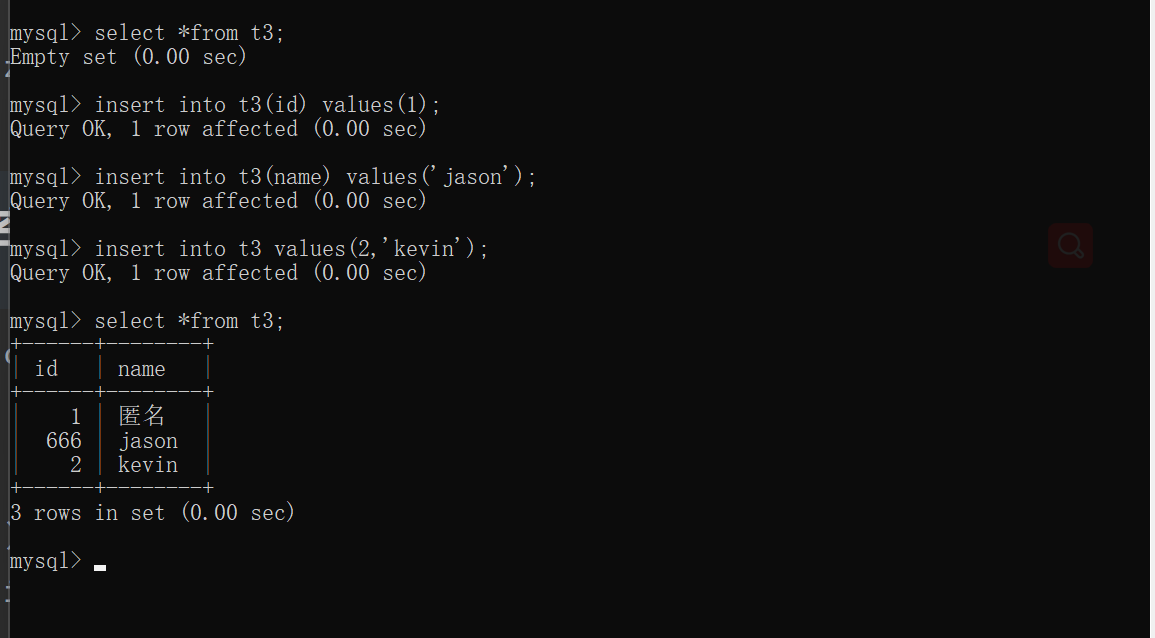
create table t3(
id int default 666,
name varchar(16) default '匿名'
);
insert into t3(id) values(1);
insert into t3(name) values('jason');
insert into t3 values(2,'kevin');
🐳唯一值
"""单例唯一"""
create table t4(
id int unique,
name varchar(32) unique
);
insert into t4 values(1,'jason'),(2,'jason');
结果:报错
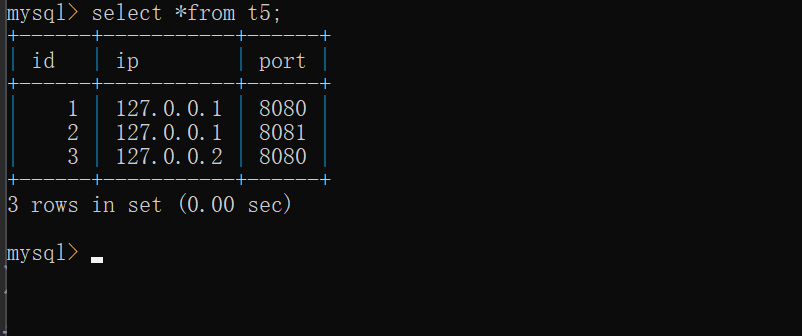
"""联合唯一"""
create table t5(
id int,
ip varchar(32),
port int,
unique(ip,port)
);
insert into t5 values(1,'127.0.0.1',8080),
(2,'127.0.0.1',8081),(3,'127.0.0.2',8080);
insert into t5 values(4,'127.0.0.1',8080);
结果:报错
🐳主键
主键:primary key,主要的键,一张表只能有个字段可以使用对应的键,用来唯一的约束该字段里面的数据,不能重复;这种之为主键。
一张表只能有最多一个主键;主键请尽量使用整数类型而不是字符串类型
方案1:字创建表的时候,直接在字段之后,跟primary key关键字(主键本身不允许为空)
优点:非常直接 缺点:只能使用一个字段为主键
方案2:在创建表的时候,在所有的字段之后,使用primary key (主键字段列表)来创建主键(如果有多个字段作为主键,可以是复合主键)
方案三:当表已经创建好之后,额外追加主键;可以通过修改表字段属性,也可以直接追加 Alter table 表名 add primary key (字段列表)
前提:表中字段对应的数据本身是独立的(不重复)
1.单从约束面上而言主键相当于 not null + unique(非空且唯一)
create table t6(
id int primary key,
name varchar (32)
);
insert into t6 (name) values('jason');
结果:报错
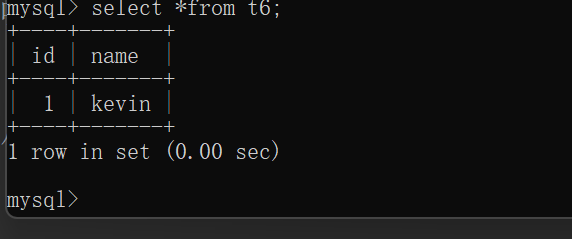
insert into t6 values(1,'kevin');
结果:以下
insert into t6 values(1,'jerry');
结果:报错
2.InnoDB存储引擎规定了所有的表都必须有且只有一个主键(主键是组织数据的重要条件并且主键可以加快数据的查询速度)
1.当表中没有主键也没有其他非空且唯一的字段的情况下
InnoDB会采用一个隐藏的字段作为表的主键,隐藏意味着无法使用,基于该表的数据查询只能一行行查找,速度很慢
2.当表中没有主键但是由其他非空且唯一的字段,那么会从上往下将第一个该字段自动升级为主键
create table t7(
id int,
age int not null unique,
phone bigint not null unique,
birth int not null unique,
height int not null unique
);
"""
我们在创建表的时候应该有一个字段用来标识数据的唯一性,并且该字段通常情况下就是‘id’(编号)字段
id nid sid pid gid uid
create table userinfo(
uid int primary key,
);
"""
🐳自增
自增长:当对应的字段,不给值,或者说给默认值,或者给NULL的时候,会自动的被系统触发,系统会从当前字段中已有的最大值再进行+1操作,得到一个新的在不同的字段。
自增长的字段必须定义为主题,默认起初始值是1而不是0
自增长的特点:
任何一个字段要做自增长必须前提是本身是一个索引(key 一栏值),auto_increment表示自动编号
自增长字段必须是数字(整型)
一张表最多只能有一个增长
该约束条件不能单独出现,并且一张表中能出现一次,主要就是配合主键一起用
create table t8(
id int primary key,
name varchar(32)
);
create table t9(
id int primary key auto_increment,
name varchar(32)
);
"""
自增
自增不会因为数据的删除而回退,永远自增往前
如果自己设置了更大的数,则之后按照更大的往前自增
如果想重置某张表的主键值 可以使用
truncate t9 清空表数据并重置主键
"""
🐳外键
外键:foreign key ,外面的键(键不在自己表中);如果一张张表中有一个字段(非主键)指向另外一张表的键,那么将该字段称之为外键。
举个例子:
如果我们需要一个员工信息表格
编号 名字 年龄 部门 部门职责
1.如果全部混在一起的话就会语义不明确,(到底是员工还是部门) 可以不在意
2.存取数据过于冗余(浪费存储空间)
3.数据的扩展性极差 这点不能被忽视
解决思路:
可以将上述的的表一份为二
编号 名字 年龄
编号 部门 部门职责
上述的三个问题都解决了,但是员工和部门之间就没有关系了,这时候就引出了外键字段。
外键字段:用于表示数据与数据之间的字段关系
关系的判断:
表关系。数据关系其实是一样的,只不过是说法上不同而已。
关系一共有四种:
一对多的关系
多对多的关系
一对一的关系
没有任何关系
温馨小提示:
关系的判断可以采用“换位思考”的 原则
一对多关系
还是以员工和部门表为例
1.站在员工的角度
问:一个员工是否能对应多个部门
答:不可以
2.站在部门的角度
问:一个部门是否能对应多名员工
答:可以
所以得出结论:一个可以一个不可以,那么关系就是'一对多'
针对‘一对多’的关系呢,外键的关键字就在'多’的一方
一对多外键字段的建立:
温馨小提示:可以先定义含有普通字段的表,之后在考虑外键字段的添加
create table emp(
id int primary key auto_increment,
name varchar(32),
age int,
dep_id int,
foreign key(dep_id) references dep(id)
); /*这一句是添加外键的*/
create table dep(
id int primary key auto_increment,
dep_name varchar(32),
dep_desc varchar(64)
);
1.创建表的时候一定要先创建被关联的表
2.录入数据的时候一定要先录入被关联表
3.修改数据的时候外键字段无法修改和删除
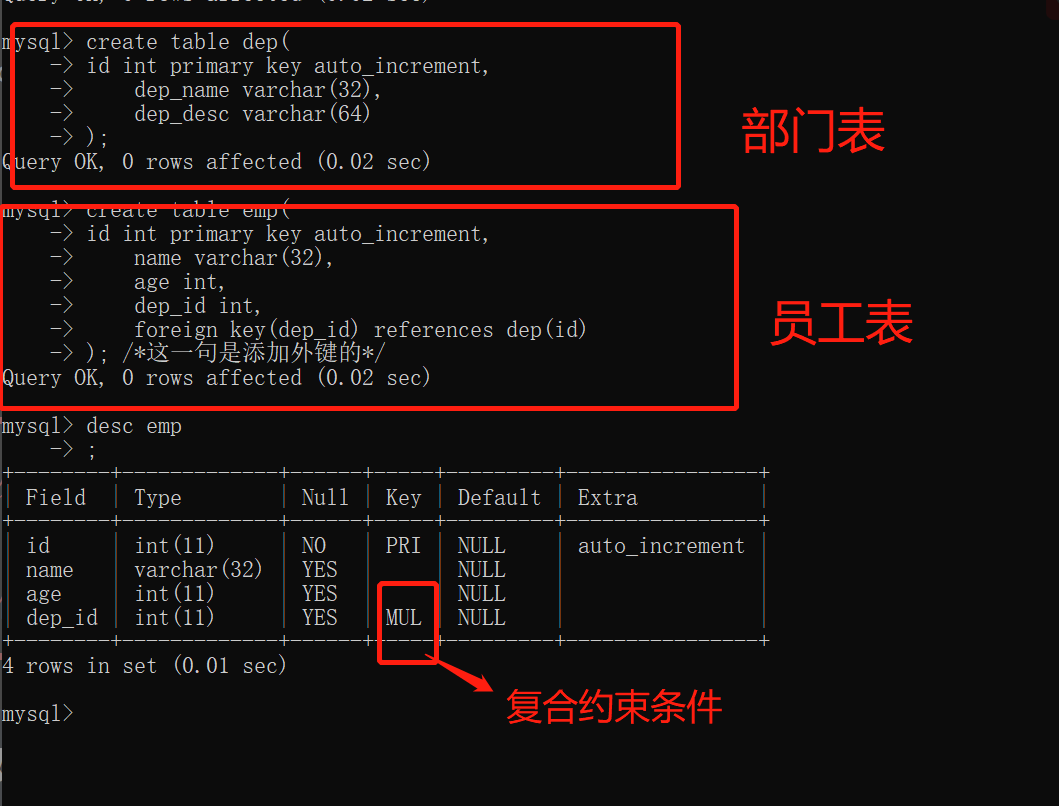
优化:
针对3有简化的措施>>>>:级联更新级联删除
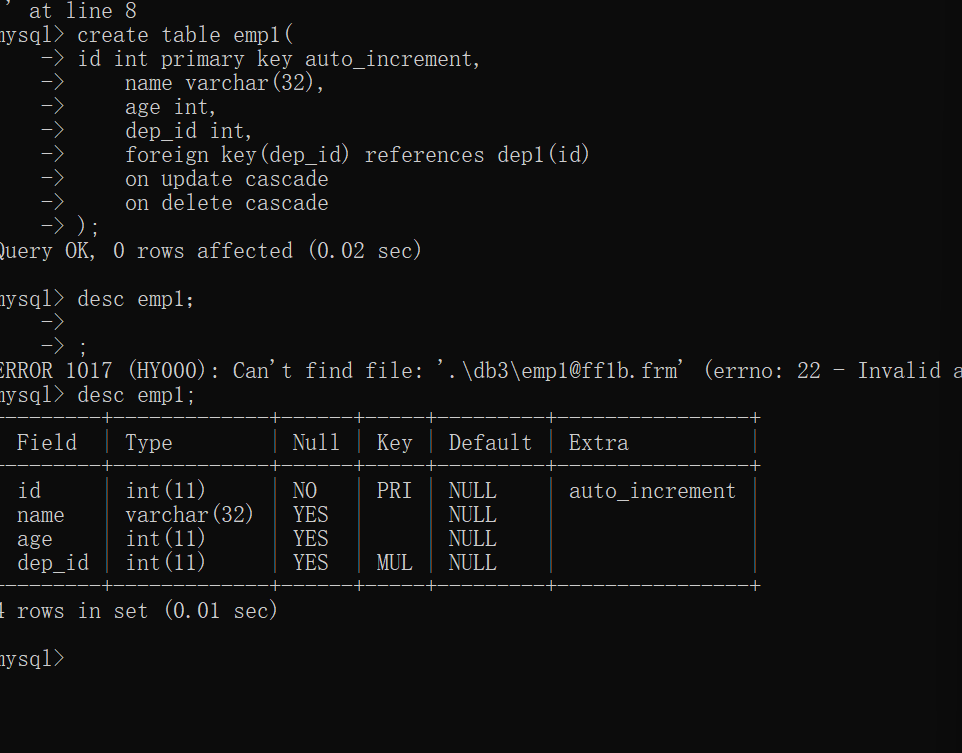
create table emp1(
id int primary key auto_increment,
name varchar(32),
age int,
dep_id int,
foreign key(dep_id) references dep1(id)
on update cascade /*关于级联更新*/
on delete cascade /*级联删除删除时级联删除依赖行可以在创建表时设置级联删除*/
);
create table dep1(
id int primary key auto_increment,
dep_name varchar(32),
dep_desc varchar(64));
"""外键其实就是强耦合,不符合结耦合的特性
所以很多低吼,实际项目中当表的的数量较多的情况,我们可能不会使用外键,而是使用代码来建立逻辑层面的关系
"""
District: 严格模式(默认的), 父表不能删除或者更新一个已经被子表数据引用的记录
Cascade: 级联模式: 父表的操作, 对应子表关联的数据也跟着被删除
Set null: 置空模式: 父表的操作之后,子表对应的数据(外键字段)被置空
通常的一个合理的做法(约束模式): 删除的时候子表置空, 更新的时候子表级联操作
多对多关系
如上:举个例子 以书籍和作者表为例
1.站在书籍表的角度
问:一本书能否对应多个作者
答:可以
2.在站在作者表的角度
问:一个作者能否对应多本书
答:可以
结论:两者都可以的话,关系就是"多对多"
针对"多对多"不能在表中直接创建,需要新建立第三张关系表
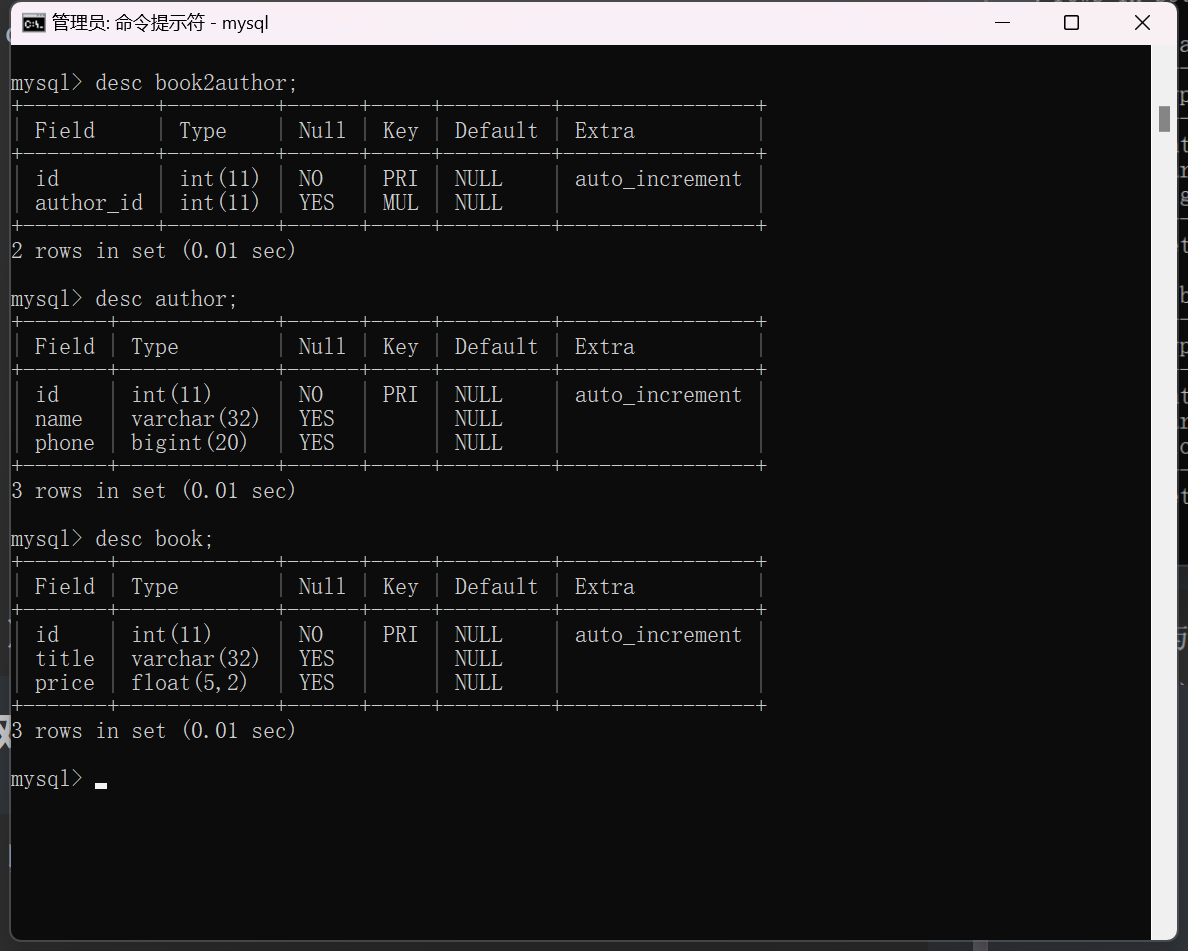
/*书籍列表*/
create table book(
id int primary key auto_increment,
title varchar(32),
price float (5,2)
);
/*作者列表*/
create table author(
id int primary key auto_increment,
name varchar(32),
phone bigint
);
/*第三方列表*/
create table book2author(
id int primary key auto_increment,
author_id int,
/*添加外键*/
foreign key(author_id) references book(id)
on update cascade
on delete cascade
);
一对一关系
以用户表与用户详细表为例
1.先站在用户表的角度
问:一个用户能否对应多个用户详细
答:不可以
2.再站在用户详细表的角度
问:一个用户详细能否对应多个用户
答:不可以
结论:两个都不可以的情况下,关系只可能是'一对一'或者没有关系
针对'一对一'外键字段键在任何一方都可以,但是推荐建在查询频率较高的表中
/*用户表*/
create table user(
id int primary key auto_increment,
name varchar(32),
detail_id int unique,
/*添加外键*/
foreign key(detail_id) references userdetail(id)
on update cascade
on delete cascade
);
/*详细地址*/
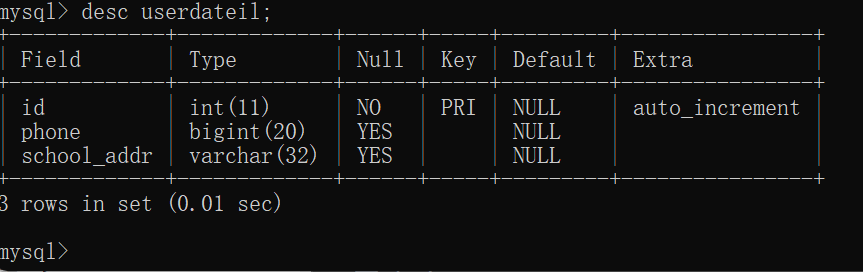
create table userdateil(
id int primary key auto_increment,
phone bigint,
school_addr varchar(32)
);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号