
Elasticsearch-底层Lucene打分机制
Lucene 相似度打分
1. 文本相似度的主要影响因子
a. 词频 tf (term frequency) : 指某个词在文档中出现的次数, 其值越大, 就可以认为这篇文章描述的内容与该词越相近, 相似度得分就越高.
在 Lucene 中的计算公式为:

b. 逆文本频率 df (inverse document frequency) : 这是一个逆向的指标, 表示在整个文档集合中包含某个词的文档数量越少, 这个词越重要
idf(t) = 1+Log( docCount/(docFreq+1))
其中, docCount 表示索引中的文档总数, docFreq表示包含Term t的文档数, 分母中 docFreq + 1 是为了防止分母为0.
c. Length: 这是一个逆向的指标, 表示在同等条件下, 搜索词所在文档的长度越长, 搜索词和文档的相似度就越低; 文档的长度越短, 相似度就越高. 例如 "lucene" 出现在一篇包含 10个字的文档中和一篇包含 10000 个文字的文档中, 那么我们认为 10个字的那篇文章与 "lucene" 更相关.
2. 基于向量空间模型
向量空间模型( Vector SpaceModel, VSM) 的主要思路是把文本信息映射到空间向量中, 形成文本信息和向量数据的映射关系, 然后通过计算几个或者多个不同的向量的差异, 来计算文本的相似度.
如下图所示 有两个文本 query 和 document, 在query 中包含 2 个 term1 和 1 个 term2 , 在document 中包含 1 个 Term1 和 4 个 Term2.
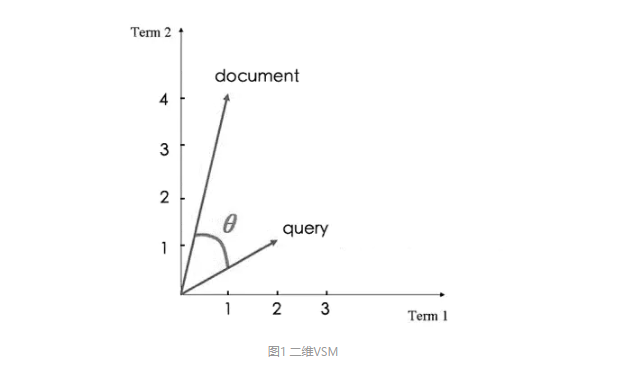
根据每个Term 在每个文本中出现的次数, 我们可以把文本信息映射到空间向量中, 形成文本信息和向量数据的映射关系, 也就是根据两个文档 query 和 document 生成的 query(以下简称q) 和 document(以下简称d) 这两个向量, 而向量 q 和向量 d 之间的夹角描述了他们之间的相似度, 夹角越小就越相似, 如果 q 和 d 完全相同, 则其夹角为 0 .
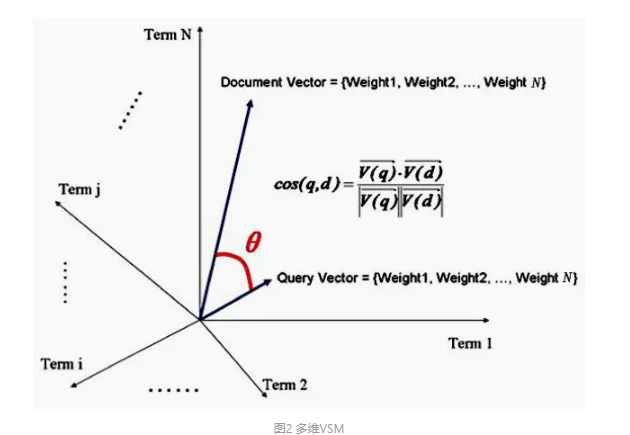
一篇文章通常是由很多 Term 组成, 所以我们把二维的情形推广到 N 维也是可行的, 两个向量之间的夹角依然可以表示两个文档的相似度, 夹角越小就越相似
3. 基于概率的模型
BM25 算法是根据 BIM(Binary independent Model, 二元独立模型) 算法改进而来的, 二元独立模型做了两个假设.
a. 二元假设, 指一个词和文档的关系只有两种: 1. 相关; 2. 不相关. 不考虑其他因素
b. 词的独立性假设, 指文档里词和词之间没有任何关联, 任意一个词在文档中的分布概率不依赖于其他单词或文档.
而BM25算法是在 BIM 算法的基础上加了词的权重和两个经验参数, 到目前为止很是优秀的排名算法. 现在 Elasticsearch 默认的打分算法已经由原来的向量空间模型变成了 BM25.

IDF(qi): 词的重要程度和其出现在文档中的数量成反比, 包含该词的文档数越多, idf值就越小.
Fi: 表示第 i 个词在文档中出现的次数, Fi 的值越大, 得分就越高
dl: 表示文档的长度, 文档越长, 得分就越低
avgdl: 表示文档的平均长度, 随着索引的增删改查, 这个值是实时变化的.
K1: 表示调节因子, 调节词频对得分的影响, K1 越大, 表示这个词频对得分的影响就越大, 在 K1 = 0 的极限情况下, 词频失效. 默认值为 1.2
b: 表示调节因子, 调节字段长度对得分的影响, b 越大, 表示对文档长度的惩罚越大, 在 K = 0 的极限情况下, 忽略文档长度的影响. 默认值为 0.75

 浙公网安备 33010602011771号
浙公网安备 33010602011771号