ElasticSearch_7.8.0 --- 数据类型及操作
1. 数据类型
1.1 基础数据类型
# 字符串
text # 文本,会模糊匹配,只要包含就可以匹配的到
keyword # 关键字,如果是keyword类型,被查询时会被精准匹配,不会被拆分
# 数值类型
long
integer
short
byte
double
float
half
float
scaled
# 日期类型
date
# 布尔值类型
boolean
# 二进制类型
binary
1.2 数据类型配置
# 设置数据类型,如果未设置,底层会自动匹配类型
PUT /test2 # 创建test2索引
{
"mappings":{ # 规则
"properties":{ # 属性
"name":{
"type":"text" # 设置name字段为text类型
},
"age":{
"type":"long" # 设置age字段为long类型
},
"birthday":{
"type":"date" # 设置birthday字段为date类型
}
}
}
}
# 获取索引结构
get test2
2. 数据操作
2.1 索引操作
1. 创建索引
对比关系型数据库,创建索引就等同于创建数据库,Postman中向ES 服务器发送PUT请求:http:127.0.0.1:8200/shopping 创建一个shopping的index
# 创建文档,指定文档ID
ip:9200/索引名称/文档id
{
字段:值,
...
}
# 修改文档,每修改一次,version会增加1,表示改动的次数,但是如果提交的json字段和原有的字段不是一一对应,会覆盖原数据,不建议使用这种方式修改
ip:9200/索引名称/文档id
{
字段:值,
...
}
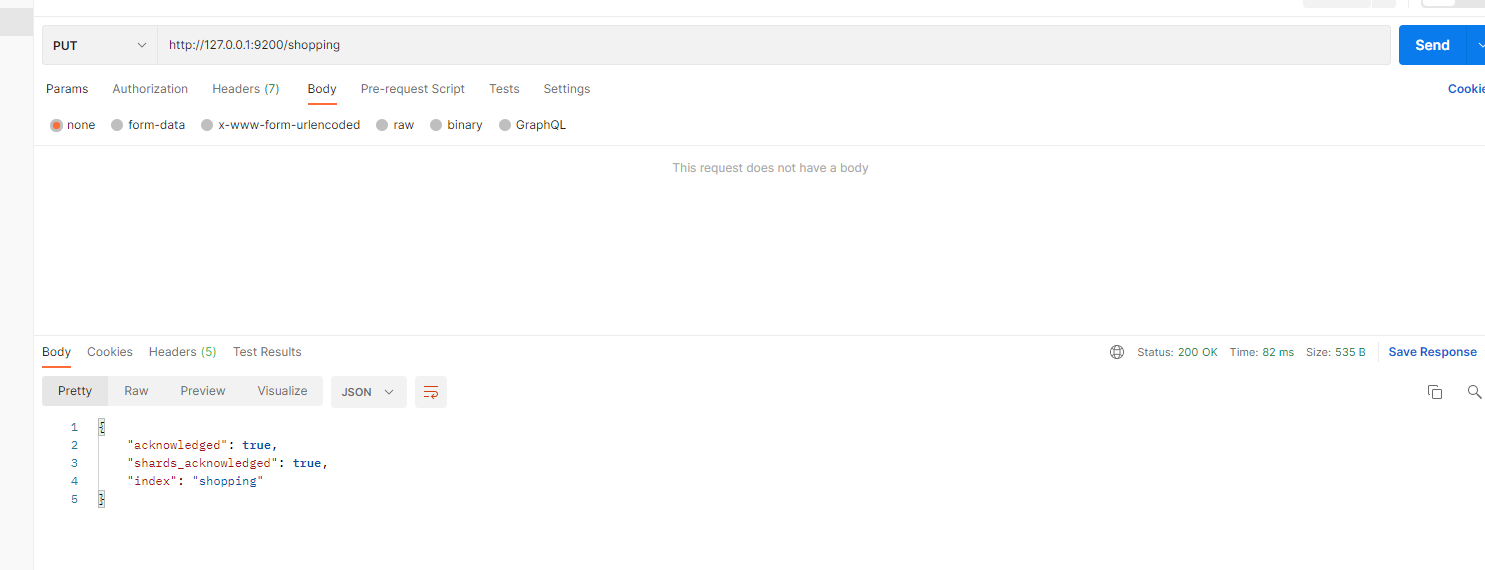
2. 获取索引
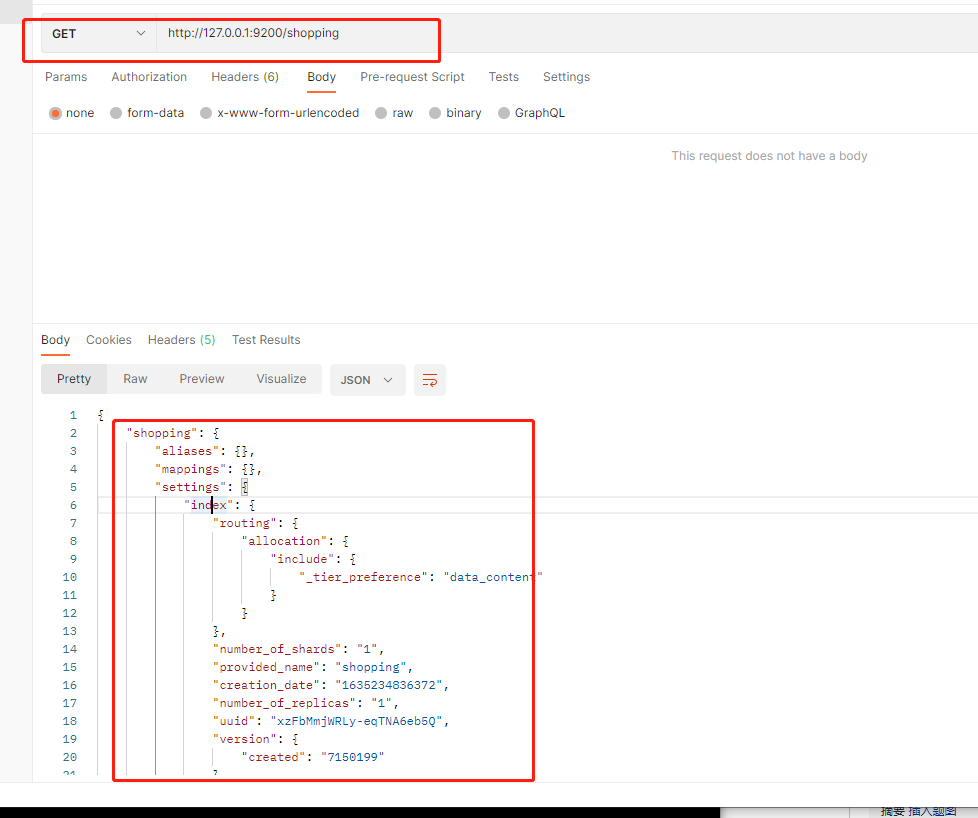
1. 获取某个索引
# 查询文档,通过文档ID
# ip:9200/索引名称/类型名称/文档id 类型名8.0已弃用
ip:9200/索引名称/文档id
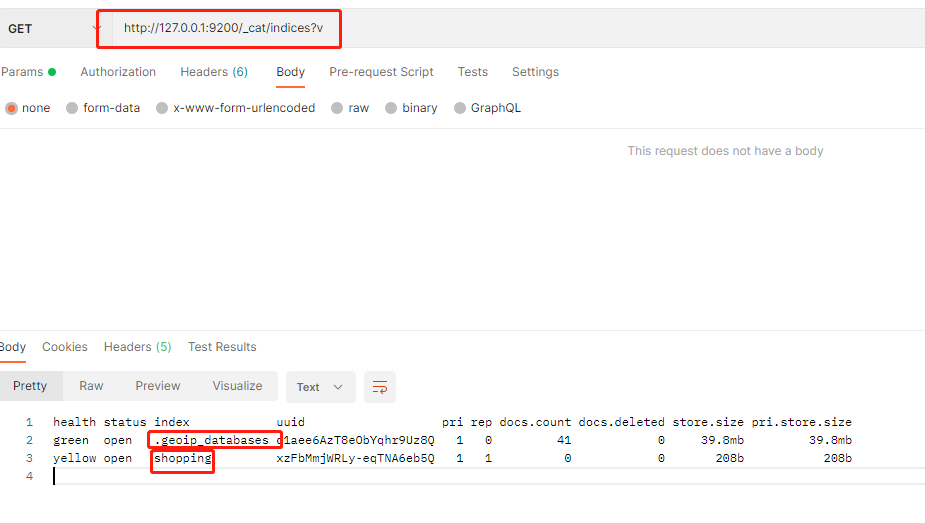
# ip:9200/_cat/health 查看健康信息
# ip:9200/_cat/indices?v 查看ES中的所有信息
2. 获取所有索引
v 表示详细信息
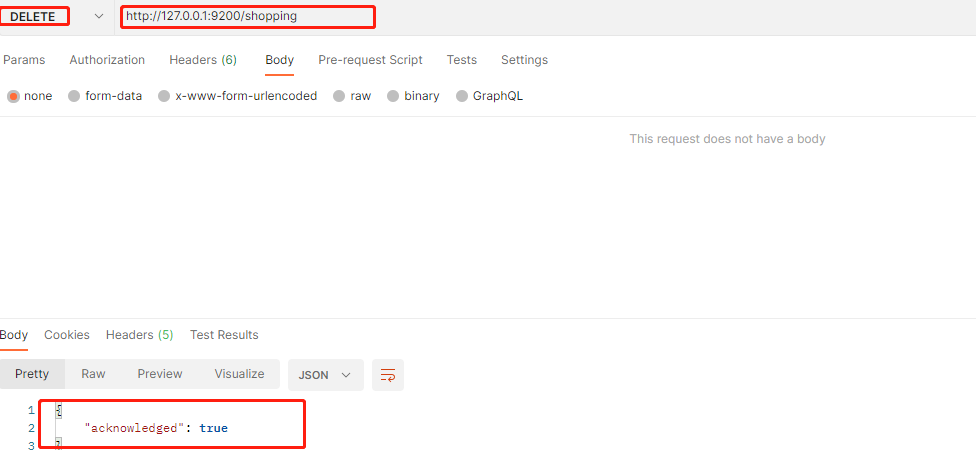
3. 删除索引
# 删除文档,指定文档ID
ip:9200/索引名称/文档id
2.2 文档操作
1. 创建文档
# 查询文档,通过文档ID
# ip:9200/索引名称/类型名称/文档id 类型名8.0已弃用
ip:9200/索引名称/文档id
# 根据条件查询,如果字段类型为keyword,必须是完全相同的字符才能被匹配
ip:9200/索引名称/类型名称/_search?q=字段名:值&字段名2:值2
# 修改请求体,达到复杂查询的目的
ip:9200/索引名称/类型名称/_search
{
"query":{
"match":{
"字段名":"值"
}
}
"_source":["name","field"] # 字段过滤
"sort":[ # 排序,根据字段排序
{
"字段":{
"order":"desc"
}
}
]
"from":0 # 分页,起始值
"size":1 # 分页,一页几条数据
}
# 查询结果结构
hit:索引和文档的信息,如果有多个匹配项是个列表
score:分数,可以判断谁的权重更高,用来排序
# must,类似and,查询结果必须包含must字段中指定的的值
{
"query":{
"bool":{
"must":[
"match":{
"字段名":"值"
},
"match":{
"字段名":"值"
}
]
}
}
}
# should,类似or
{
"query":{
"bool":{
"should":[
"match":{
"字段名":"值"
},
"match":{
"字段名":"值"
}
]
}
}
}
# must_not 类似(not)
{
"query":{
"bool":{
"must_not":[
"match":{
"字段名":"值"
},
"match":{
"字段名":"值"
}
]
}
}
}
# 过滤器(filter)
{
"query":{
"bool":{
"must":[
"match":{
"字段名":"值"
},
]
"filter":{
"range":{
"字段":{
"gt"
"lt"
"gte":
"lte":
}
}
}
}
}
}
# 多条件查询,可以制定score来进一步过滤
{
"query":{
"match":{
"字段":"值1 值2" # 多条件空格分隔
}
}
}
# term:直接通过倒排索引指定的词条进行精确查找
{
"query":{
"term":{
"字段":"值1 值2" # 多条件空格分隔
}
}
}
# 高亮查询,指定的高亮字段,会自动加<em>搜索结果<em>
{
"query":{
"match":{
"字段":"值1 值2" # 多条件空格分隔
}
}
"highlight":{ # 高亮功能
"pre_tags":"<p class='key' style='color:red'>", # 自定义高亮的标签格式开头
"post_tags":"</p>", # 指定高亮的标签格式闭合标签
"fields":{ # 设置高亮字段
"字段":{} #空字典就可以了
}
}
}
查询总结
# 关于分词
term:倒排索引精确查找
match:会使用分词器解析,先分析文档,再进行查询
# 关于类型
keyword # keyword类型是关键字,会把整个keyword当做一个整体精确查询,
text # text类型会模糊查询
在Postman中 向ES 服务器发送POST请求,http://127.0.0.1:9200/shopping/_doc _doc表示索引中添加文档
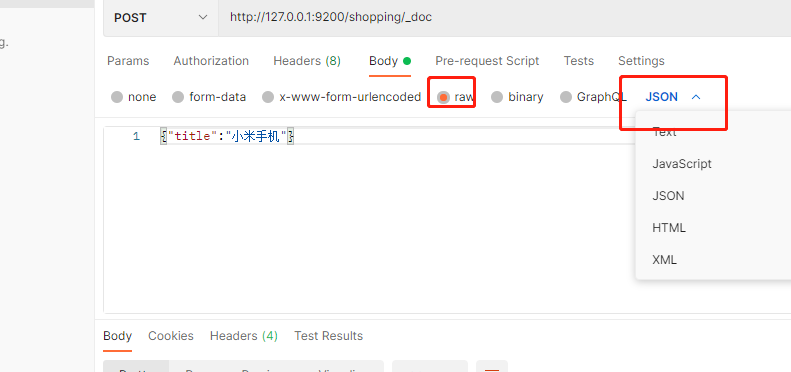
成功后的返回值

_id :数据的随机唯一标识,类似于主键,每次添加都不一样,当然也可以通过这个标识进行查询,但是这个_id并不好记,可以自定制
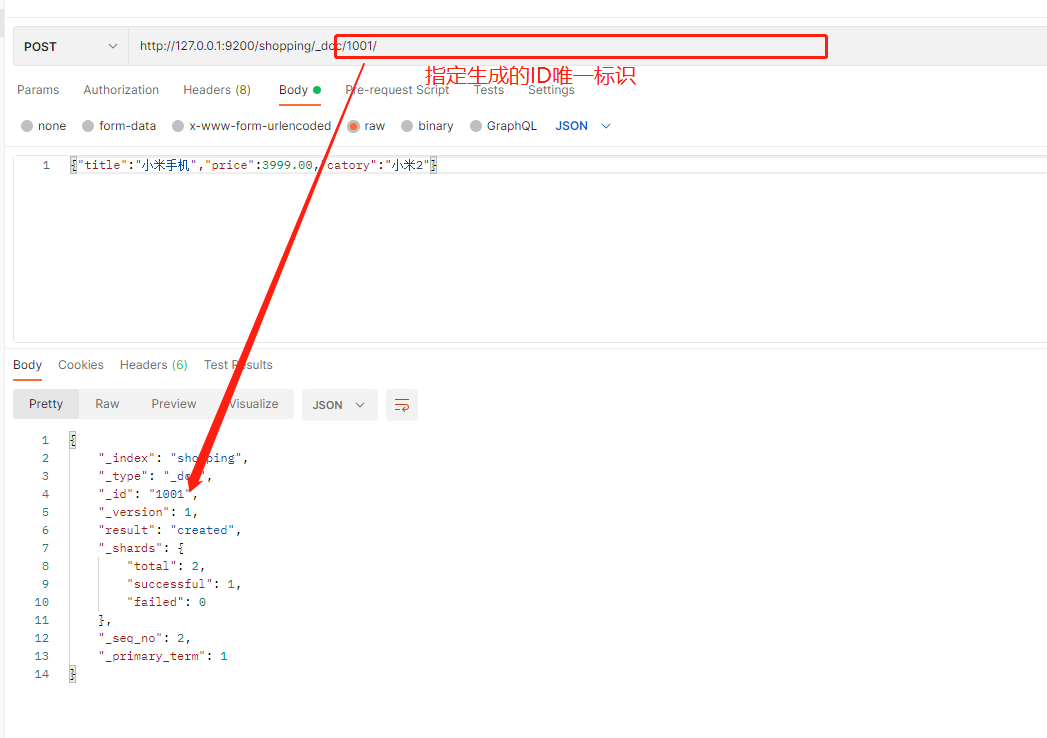
查询刚刚添加的单条文档数据
_doc/文档标识ID
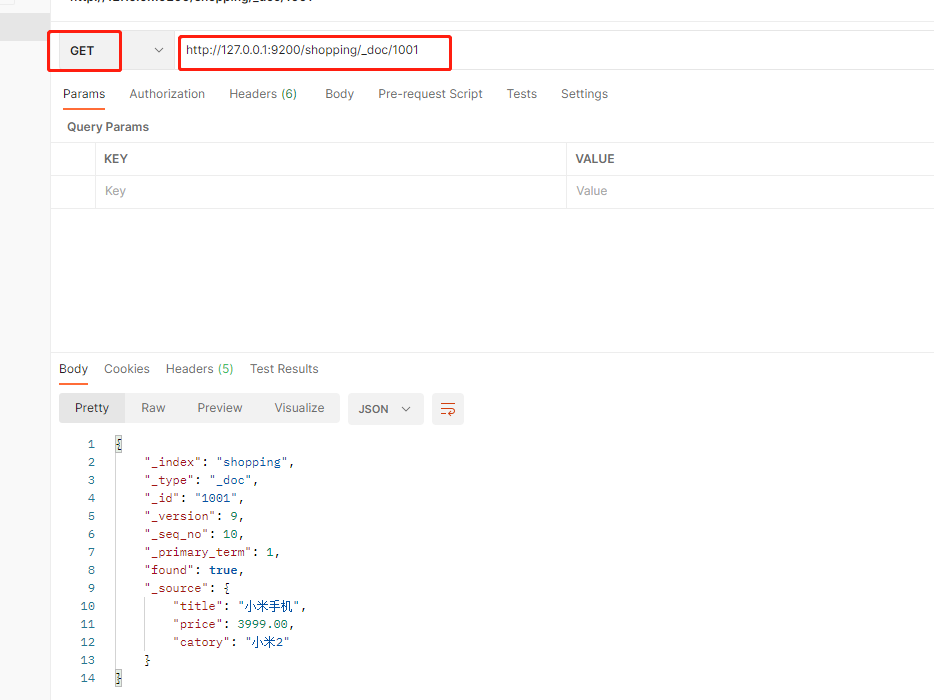
查询本索引下的所有的文档数据
_search
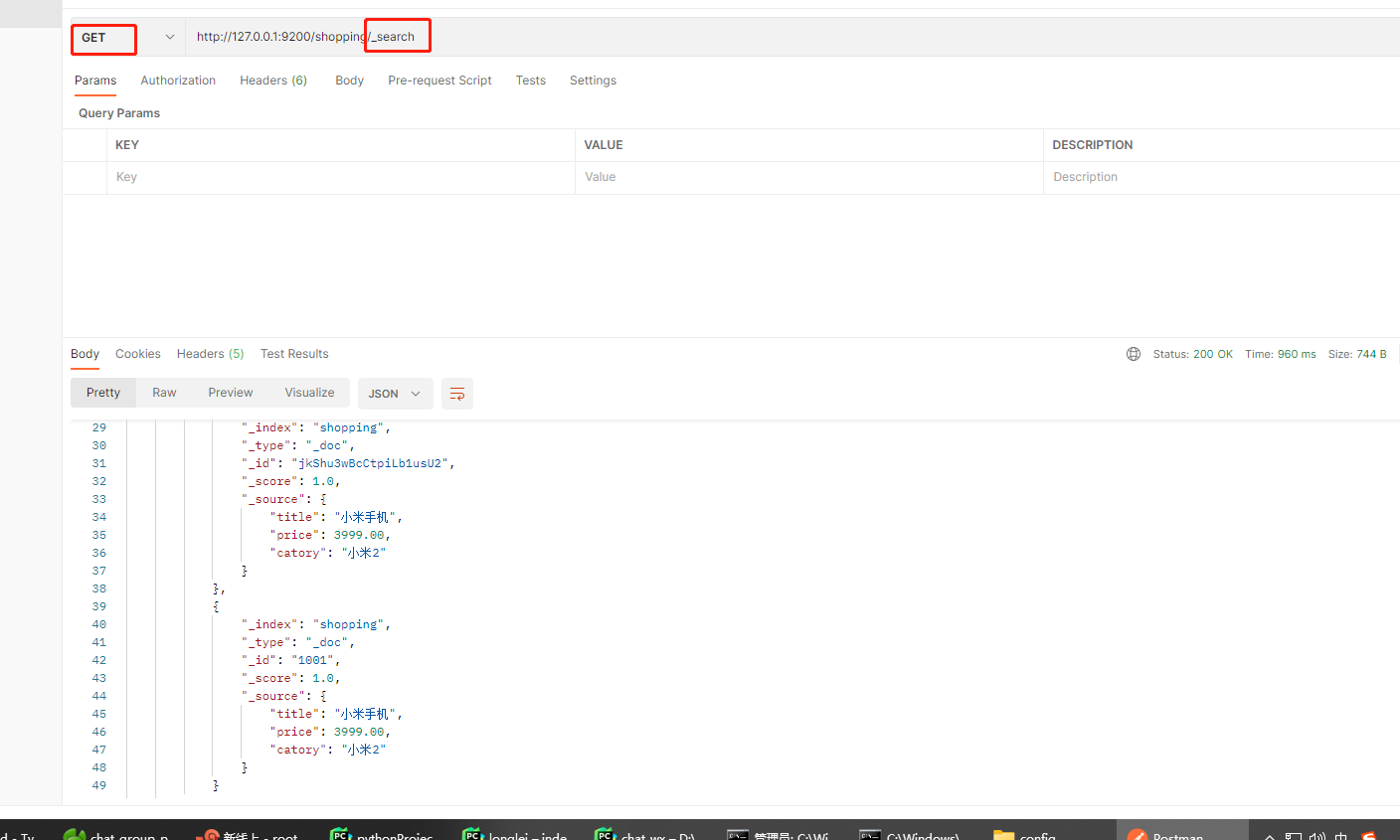
修改
完全覆盖之前的文档数据
PUT : http://127.0.0.1:9200/shopping/_doc/1001/
需要覆盖的内容
{"title":"华为手机","price":3999.00,"cateory":"华为"}
局部字段更新
POST http://127.0.0.1:9200/shopping/_doc/1001/
需要更新的字段
{
"doc":{ // doc表示明确指定更新
"title":"华为手机",
"price":399.00
}
}
3. 条件查询
指定字段查询
http://127.0.0.1:9200/shopping/_search?q=title:小米
由于url中携带中文容易出现乱码的情况,所以改成通过请求体来发送查询参数
http://127.0.0.1:9200/shopping/_search
{
"query":{ // query 表示本操作为查询
"match":{ // match 表示匹配查询
"title":"小米"
}
}
}
全量查询 + 分页
{
"query":{ // query 表示本操作为查询
"match_all":{ // match_all表示全量查询,配合分页查询
}
},
"from" : 0, // 表示第一页的起始位置 第二页为(页码-1)*每页数据条数 (2-1) * 10
"size" : 10, // 每一页多少条数据
"_source" : ["title"], // 只显示title字段
"sort" : {
"price":{ // 指定字段进行排序
"order":"desc" // 降序排列
}
}
}
python防脱发技巧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号