ElasticSearch --- 概述
1. 数据分类
- 结构化数据
- 非结构化数据
- 半结构化数据
2. ES和Solr的对比
- 单纯的对已有数据进行搜索时,
Solr更快 - 当实时建立索引时,
Solr会产生IO阻塞,查询性能较差,ES具有更明显的优势 - 随着数据量的增加,
Solr的搜索效率会变得更低,而ES不会有明显变化 - ES开箱即用(解压就可以用),非常简单,而
Solr会复杂一些 Solr利用Zookeeper进行分布式管理,而ES自带分布式协调管理功能Solr支持多格式数据:json,xml,csv,而ES仅支持json文件格式Solr官方提供的功能更多,而ES更注重本身的核心功能,高级功能会有很多第三方插件提供,例如图形化界面需要Kibana,IK分词器Solr查询快,但是更新索引时慢(插入删除),用于电商等查询多的应用,ES建立索引快(即查询慢),但实时性查询快Solr比较成熟,ES更新太快,学习成本高
3. 基本架构
3.1 ES结构
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档
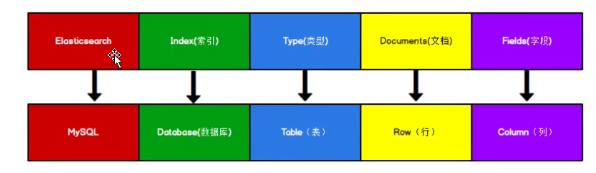
ES 里的Index 可以看做是一个库,而Types相当于表,Documents则相当于表的行
这里Types的概念已经被逐渐弱化,ES6.x中,一个index下已经只能包含一个type,Es7.x中,Type的概念已经被删除了
# ES是面向文档的,关系型数据库和ES的对比:
库 索引
表 types(#8.0已被弃用)
行 documents(最小单位)
字段 fields
3.2 物理设计
ES在后台把每个索引划分成多个分片,每个分片可以在集群中的不同服务器间迁移
3.3 底层分析
1. 节点和分片
一个集群至少有一个节点,而一个节点就是一个ES进程,节点可以有多个ES索引,如果创建ES索引,ES索引将有5个分片(Lucene索引)构成,主分片有一个副本,对于多节点的集群创建ES索引时,主分片和对应的复制分片不会在同一个节点内,这样当某一节点挂了,数据不会丢失实际上一个分片就是一个Lucene索引,一个包含倒排索引的文件目录
2. 倒排索引
通过关键字锁定主键索引,从而到处该数据
ES使用的是倒排索引结构,采用lucene倒排索引为底层,这种结构适用于快速的全文搜索,不扫描全部文档就可以搜索到对应内容,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表,如文档1中的内容是1,2,3 文档2的内容是2,3,5,为了创建索引,会将每个文档拆分成独立的词(词条),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档,如1在文档1中出现,文档2没有,2两个文档都有,3也是两个文档都有,5在文档1中没有,文档2中有,假如搜索1和2的时候,只需要查看每个词条的文档,如1在文档1中有,文档2中没有,2在文档1和文档2中都有,那么说明文档1的score更高,匹配程度更高,如果没有别的条件,这两个包含关键字的文档都将返回
也就是对文档的内容进行分词拆分,列出包含分词的文档ID,当查询的时候,直接查包含分词的文档ID就可以了,根本不会产生无用搜索
3. 正排(正向)索引
musql中通过主键,锁定对应数据
4. 应用场景
海量日志分析
商品价格监控网站
如果价格低于50会自动通知到用户
数据分析
python防脱发技巧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号