Docker --- 常用服务 -- 集群部署 -- 生产环境
1. Mysql 主从复制
1. 主服务容器 3307端口
1. 搜索 mysql
docker search mysql
2. 拉取镜像
docker pull mysql:5.7
3. 查看是否拉取成功
docker images
4. 查看 3307 端口是否被占用
ps aux|grep 3307
5. 启动 mysql-master 实例,加数据卷映射,生成目录和映射关系
docker run -d -p 3307:3306 --privileged=true -v /app/mysql/mysql-master/log:/var/log/mysql -v /app/mysql/mysql-master/data:/var/lib/mysql -v /app/mysql/mysql-master/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=flzx3000c --name mysql5.7-master mysql:5.7
6. 查看 mysql-master 实例 是否成功启动
docker ps
7. 修改配置
# 修改配置文件,指定字符集
cd /app/mysql/mysql-master
vim my.cnf
配置文件内容
[mysqld]
# 设置字符编码集
collation_server=utf8_general_ci
haracter_set_server=utf8
## 设置 server_id, 同一局域网中需要唯一
server_id=101
## 制定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日期过期清理时间,默认值为0:表示不清理
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制终端
## 如: 1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
8. 重启 mysql-master 实例
docker restart mysql5.7-master
9. 查看容器是否重启成功
docker ps
**10. 进入mysql-master **
docker exec -it mysql5.7-master /bin/bash
mysql -uroot -p
# 输入密码
14yhl9t
11. mysql-master 实例 内创建数据同步用户
-- 需要自行修改密码
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO 'slave'@'%';
2. 从服务器容器 3308端口
1. 启动 mysql-slave 实例,加数据卷映射,生成目录和映射关系
docker run -d -p 3308:3306 --privileged=true -v /app/mysql/mysql-slave/log:/var/log/mysql -v /app/mysql/mysql-slave/data:/var/lib/mysql -v /app/mysql/mysql-slave/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=14yhl9t --name mysql5.7-slave mysql:5.7
2. 查看 mysql-slave 实例 是否成功启动
docker ps
3. 修改配置
# 修改配置文件,指定字符集
cd /app/mysql/mysql-slave
vim my.cnf
配置文件内容
[mysqld]
# 设置字符编码集
collation_server=utf8_general_ci
haracter_set_server=utf8
## 设置 server_id, 同一局域网中需要唯一
server_id=102
## 制定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能,以备slave作为其他数据库实例的master时使用
log-bin=mall-mysql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日期过期清理时间,默认值为0:表示不清理
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制终端
## 如: 1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log 配置中继日志
relay_log=mall-mysql-relay-bin
## log_slave_updates 表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
## slave设置为只读(具有super权限的用户除外)
read_only=1
4. 重启 mysql-slave 实例
docker restart mysql5.7-slave
5. 查看容器是否重启成功
docker ps
6. 在主数据库中查看主从同步状态
docker exec -it mysql5.7-master /bin/bash
mysql -uroot -p
# 输入密码
flzx3000c
查看主从同步状态,slave实例需要填写下面对应参数
show master status;

7. 进入mysql-slave
docker exec -it mysql5.7-slave /bin/bash
mysql -uroot -p
# 输入密码
14yhl9t
8. mysql-slave 实例 配置主从复制
注意和master 的 show master status 命令执行结果对照
change master to master_host='宿主机IP',master_user='slave',master_password='123456',master_port=3307,master_log_file='mall-mysql-bin.000001',masterlog_pos=617,master_connect_retry=30;
参数说明
master_host # 主数据库的IP地址
master_user # 主数据库的运行端口
master_password # 在主数据库创建的用于同步数据的用户账号
master_port # 在主数据库创建的用于同步数据的用户密码
master_log_file # 指定从数据库要复制数据的日志文件,通过查看主数据库的状态中的File参数
masterlog_pos # 指定从数据库从哪个位置开始复制数据,通过查看主数据库的状态中的Position参数
master_connect_retry # 连接失败重试的时间间隔,单位为妙
9. mysql-slave 查看主从同步状态
show slave status \G;
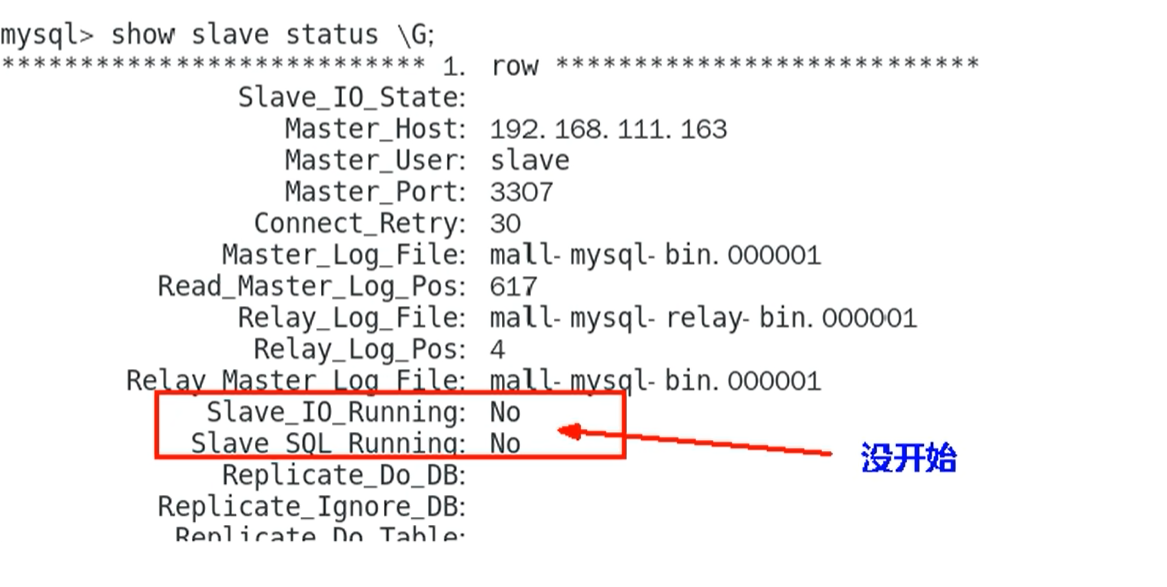
10. mysql-slave 实例 开启主从复制
start slave;
11. mysql-slave 查看主从同步状态是否开始同步
show slave status \G;

12. 自行测试
2. Redis 集群 (分布式存储)
2.1 亿级数据存储解决方案
单机单台100%不可能,肯定是分布式存储,一般业界有 3 种解决方案
1. 哈希取余分区 (小厂)
1. 实现思想
2亿条记录就是2亿个k,v 单机肯定不可能实现,必须要分布式多机存储,假设有3台机器构成一个集群,用户的每次读写操作都是根据公式 hash(key) % 机器台数,计算出哈希值,用来决定数据映射到哪个节点上

2. 优点
简单粗暴,直接有效,只需要预估好数据,规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑,使用 Hash 算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用
3. 缺点
原来规划好的节点,进行扩容或者缩容就比较麻烦了,不管扩容还是缩容,每次数据变动导致节点有变动,映射关系需要重新进行运算,在服务器个数固定不变时没有问题,但如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化: Hash(key) / 3 会变成 Hash(key) / ?
此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控
某个Redis机器宕机了,由于台数数量变化,会导致 Hash 取余全部数据重新洗牌
2. 一致性哈希算法分区 (中厂)
1. 实现思想
1. 解决了哪些问题
为了解决哈希取余分区的变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数就不正确了
一致性哈希算法的解决方案目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系
2. 实现步骤
1. 用算法构建一致性哈希环
# 什么是一致性哈希环
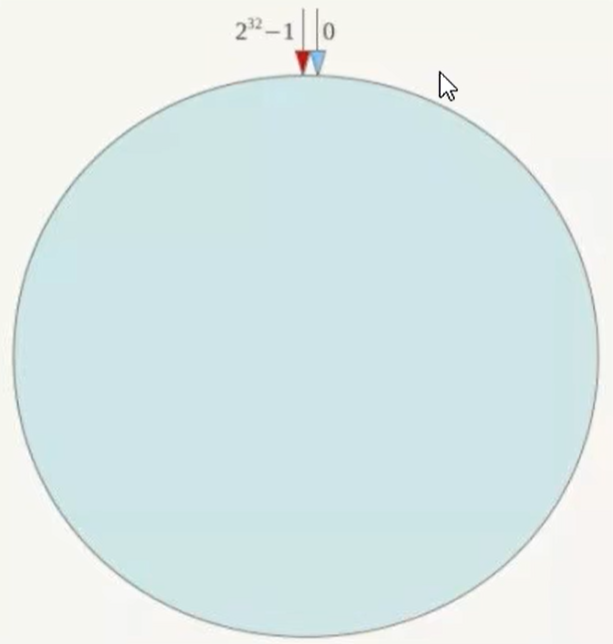
一致性哈希算法必然有个 Hash 函数并按照算法产生 Hash 值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个Hash 空间[0,2^32-1],这个是以个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0=2^32),这样让它在逻辑上形成了一个环形空间.
它也是按照使用取模的方法,上面的节点取模法是对节点(服务器)的数量进行取模.而一致性Hash算法是对2^32取模,简单来说,一致性哈希算法将整个哈希值空间组织成一个虚拟的圆环,
如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整型),整个哈希环如下图: 整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推知道2^32-1,也就是说0点左侧的第一个点代表2^32-1.0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环
2. 服务器IP 节点映射
将集群中各个IP节点映射到环上的某一个位置.
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置.
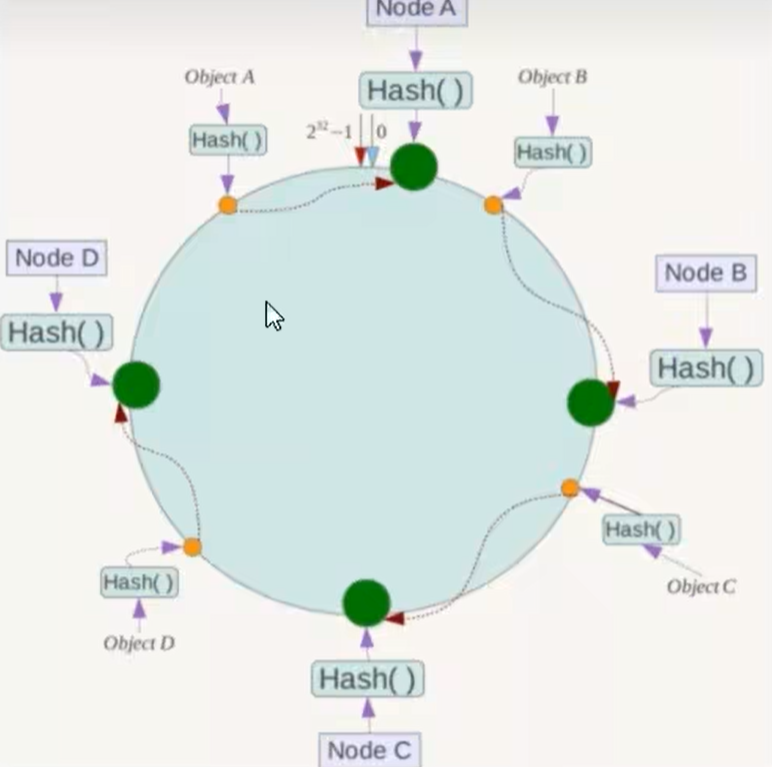
假如有4个节点:NodeA B C D ,通过IP地址的哈希函数计算(Hash(ip)),使用IP地址哈希后在环空间的位置如下

3. Key落到服务器的落键规则
当我们需要存储一个K,V 键值对时,首先计算Key的Hash 值(Hash(Key)),将这个Key使用相同的函数 Hash 计算出哈希值并确定此数据在换上的位置,从此为止沿环顺时针"游走",第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上
如: 我们有ObjectA、ObjectB、ObjectC、ObjectD四个数据对象,经过哈希计算后,在环空间上的位置如下图: 根据一致性Hash 算法,数据A会被定位到Node A 上, 数据B被定位到Node B上,数据C被定位到Node C上,数据D被定位到Node D上
2. 优点
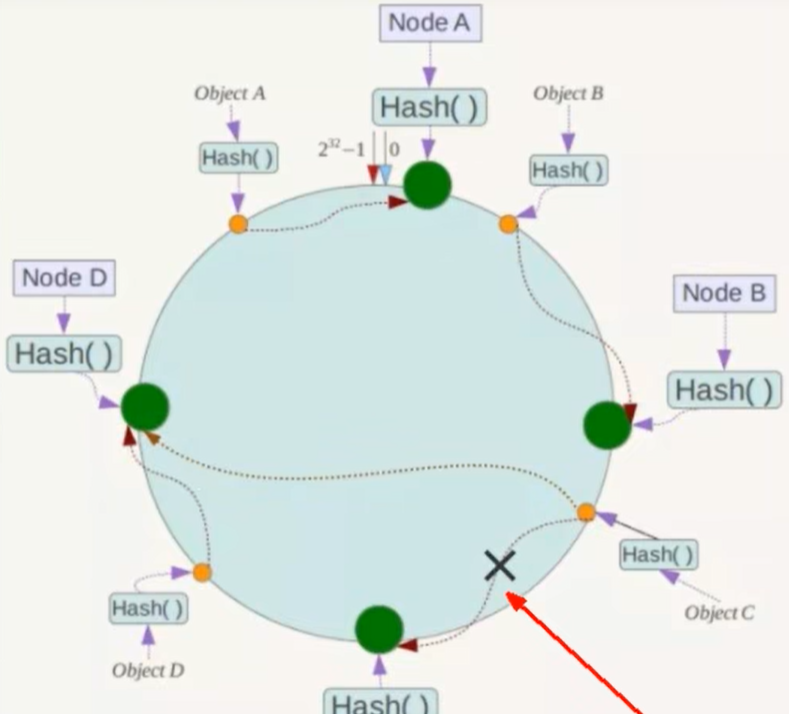
1. 一致性哈希算法的容错性
假设Node C宕机了,可以看到此时对象A、B、C不会受到影响,只有C对象被重定位到Node D,一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿环逆时针方向行走遇到的第一台服务器)之间的数据,其他不会受到影响
简单说:就是C挂了,受到影响的只是B,C之间的数据,并且这些数据会转移到D进行存储
2. 一致性哈希算法的扩展性
数据量增加了,需要增加一台节点Node X,X的位置在A,B之间,那受到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,不会导致Hash取余全部数据重新洗牌
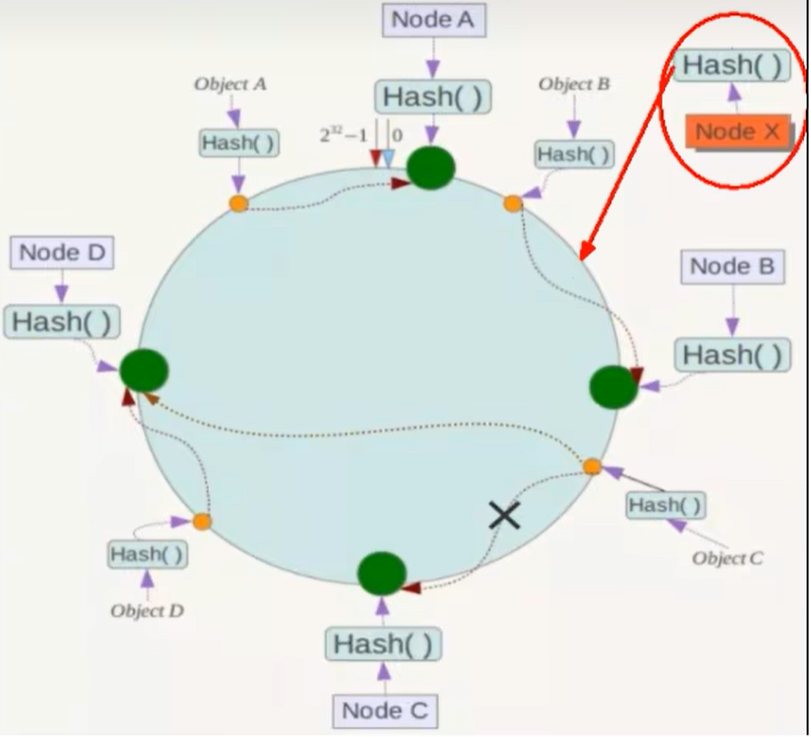
3. 缺点
1. 一致性哈希算法的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)的问题,如下:只有两台服务器

3. 哈希槽分区 (大厂)
1. 为什么会出现
哈希槽实质就是一个数组,数组[0,2^14-1]形成 hash slot空间
2. 能干什么
解决均匀分配的问题,在数据和节点之间又加入一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于几点上方的是槽,槽里放的是数据

槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动
哈希解决的是映射问题,使用Key的哈希值来计算存在的槽,便于数据分配
3. 多少个hash槽及方案实现流程
一个集群只能有16384个槽,编号0-16383(0-2^14-1),这些槽会分配给集群中的所有主节点,分配策略没有要求.可以指定哪些编号的槽分配给哪个主节点,集群会记录节点和槽的对应关系.解决了节点和槽的关系,就需要对Key求Hash值,然后对16384取余,余数是几,key就落入对应的槽里.
slot = CRC16(key)%16384 以槽为单位移动数据,因为槽的数目是固定的处理起来比较容易,这样数据移动问题就解决了
4. 为什么Redis 的最大槽数是16384个
1. CRC16算法产生的Hash值有16bit,该算法可以产生2^16=65536个值,换句话说值是分布在0-65535之间,那作者在做mod运算的时候,为什么不mod65536,而选择mod16384呢?
# 1. 保证心跳方便
正常的心跳数据包带有节点的完整配置,可以用幂等方式用旧的节点替换旧的节点,以便更新旧的配置
这意味着它们包含原始节点的插槽配置,该节点使用2k的空间和16k的插槽,但是会使用8k的空间(使用65k的插槽).
同时,由于其他设计折中,Redis集群不太可能扩展到1000个以上的主节点
因此16k处于正确的范围内,以确保每个主机具有足够的插槽,最多容纳1000个矩阵,但数量足够少,可以轻松的将插槽配置作为原始位图传播,请注意,在小型集群中,位图很难压缩,因为当N较小时,位图将设置的slot/N位占设置为的很大百分比
# 如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大.
在消息头中最占空间的是 myslots[CLUSTER_SLOTS/8]. 当槽位为65536是,这块的大小是:65536/8/1024=8kb
因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为65536,这个ping消息的消息头太大了,浪费带宽
# Redis的集群主节点数量不可能超过1000个
集群节点越多,心跳包的消息体内携带的数据越多.如果节点超过1000个,也会导致网络拥堵,因此redis作者不建议redis cluster节点数量超过1000个,那么对于节点数在1000以内的redis cluster集群,16384个槽位够用了,没必要拓展到65536个
# 2. 保证数据的传输最大化
# 槽位越小,节点少的情况下,压缩比高,容易传输
Redis主节点的配置信息中,它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中会对bitmap进行压缩,但是如果bitmap的填充率slots/N很高的话(N表示节点数),bitmap的压缩率就很低,如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低
5. 哈希槽计算
Redis集群中内置了16384个哈希槽,redis会根据节点数量大致均等的将哈希槽映射到不同的节点,当需要再Redis集群中放置一个key-value时,redis先对key使用CRC16算法计算出一个结果,然后把结果对16384取余数,这样每个Key都会对应一个编号在0-16384之间的哈希槽,也就是映射到某个节点上,如下代码,key值A,B落在Node2,key值C落在Node3上

2.2 集群搭建(3主3从)

1. 启动6个 Redis 实例
# --cluster-enabled 是否开启集群 --appendonly 是否开启持久化
docker run -d --name reids6.0.8-node-1 --net host --privileged=true -v /data/redis/share/redis6.0.8-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name reids6.0.8-node-2 --net host --privileged=true -v /data/redis/share/redis6.0.8-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name reids6.0.8-node-3 --net host --privileged=true -v /data/redis/share/redis6.0.8-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name reids6.0.8-node-4 --net host --privileged=true -v /data/redis/share/redis6.0.8-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name reids6.0.8-node-5 --net host --privileged=true -v /data/redis/share/redis6.0.8-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name reids6.0.8-node-6 --net host --privileged=true -v /data/redis/share/redis6.0.8-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386
2. 进入 redis6.0.8-node-1 并为6台机器构建集群关系
docker exec -it redis6.0.8-node-1 /bin/bash
# --cluster-replicas 表示为每个master创建一个slave节点
redis-cli --cluster create 192.168.0.11:6381 192.168.0.11:6382 192.168.0.11:6383 192.168.0.11:6384 192.168.0.11:6385 192.168.0.11:6386 --cluster-replicas 1

然后输入 yes
执行成功的效果

3. 以6381为切入点,查看集群状态
# 连接6381
redic-cli -p 6381
# 查看集群信息
cluster info
# 查看集群的主从关系
cluster nodes


2.3 数据存储和主从容错
1. 数据读写存储
1. 进入 redis6.0.8-node-1
docker exec -it redis6.0.8-node-1 /bin/bash
2. 连接 6381
redis-cli -p 6381
3. 插入一条数据
set k1 v1
# 报错:因为当前环境是集群,通过对k1进行哈希槽运算后,得到结果不一定是插入到当前进入的6381中,12706为槽位
(error) MOVED 12706 192.168.0.11:6383
# 需要操作集群来插入数据
4. 集群读写
# -c 防止路由失效(优化路由),表示使用集群环境连接
redis-cli -p 6381 -c

2. 容错切换迁移
1. 检查 集群中的 key 存储情况和集群信息
redis-cli --cluster check 192.168.0.11:6381
2. 6381 宕机,看一下它的从节点是否会自动变为主节点
docker stop redis6.0.8-node-1
3. 进入 6382 查看集群信息
docker exec -it redis6.0.8-node-2
redis-cli -p 6382 -c
cluster nodes

2.4 主从扩容
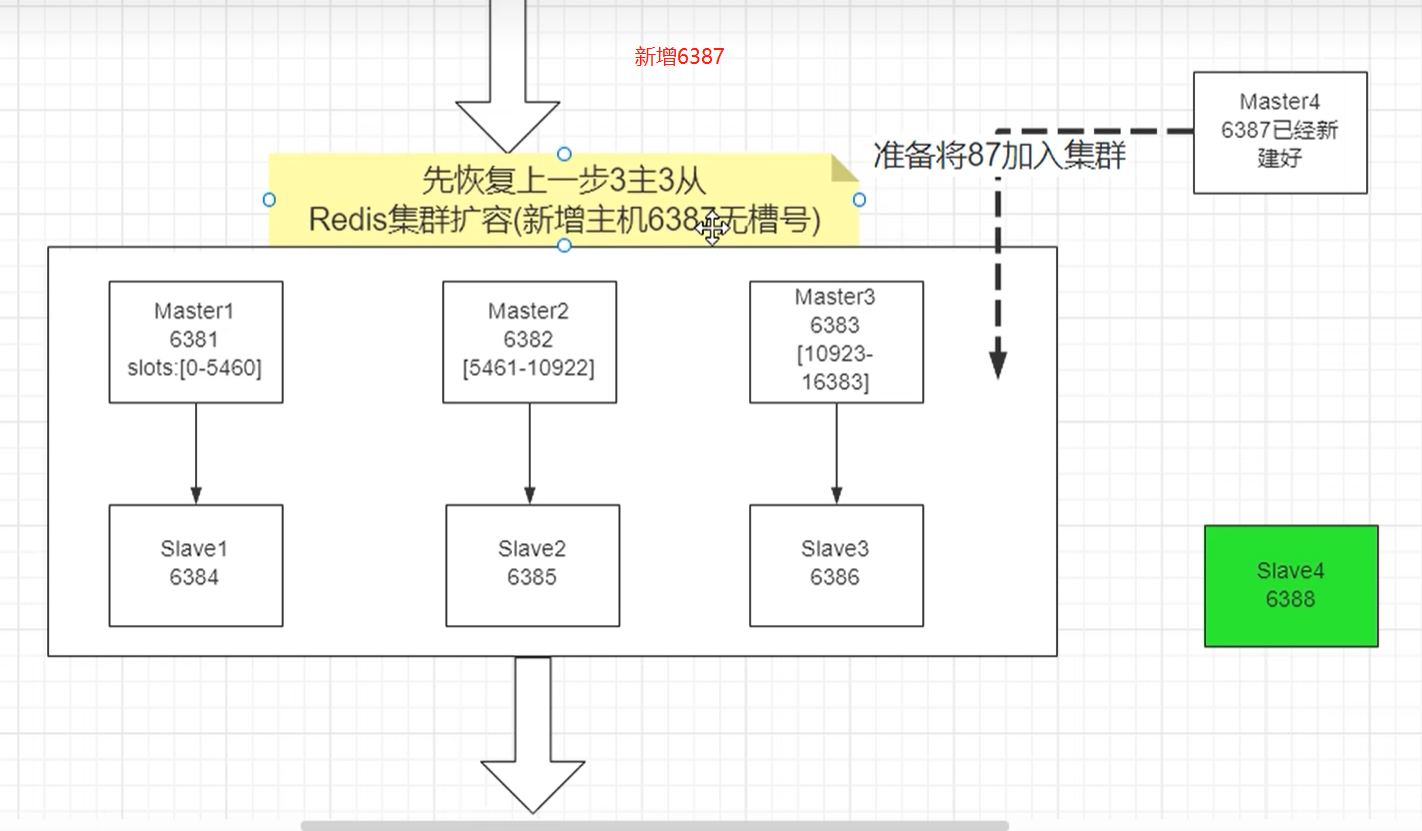

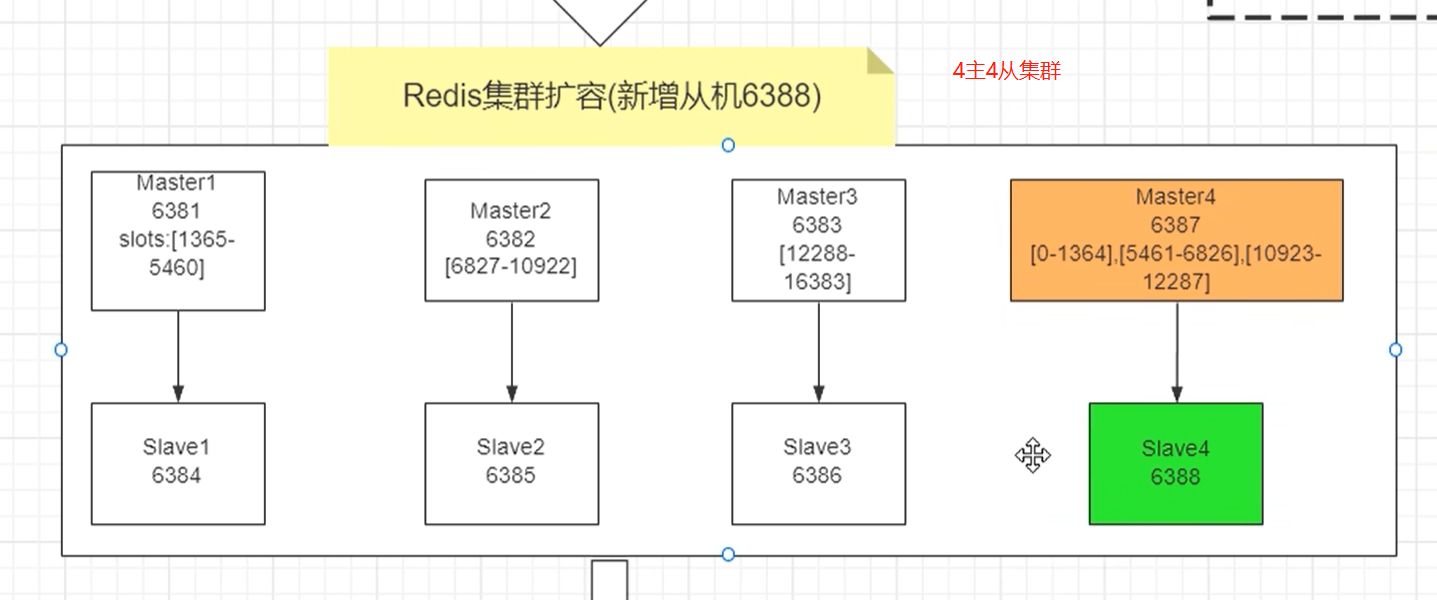
1. 新建启动 6387,6388两个节点
docker run -d --name reids6.0.8-node-7 --net host --privileged=true -v /data/redis/share/redis6.0.8-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387
docker run -d --name reids6.0.8-node-8 --net host --privileged=true -v /data/redis/share/redis6.0.8-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388
2. 查看是否启动成功
docker ps
3. 进入 redis6.0.8-node-7 容器实例
docker exec -it redis-node-7 /bin/bash
4. 将新增的6387节点,作为master 节点加入集群
# 6387 就是要新增的主节点,按照 6381的模式加入集群
redis-cli --cluster add-node 192.168.0.11:6387 192.168.0.11:6381
5. 查看集群状态
redis-cli --cluster check 192.168.0.11:6381


6. 重新分配槽位
# 192.168.0.11:6381,集群中有槽位的的主节点
redis-cli --cluster reshard 192.168.0.11:6381
# How many slots do you want to move(from 1 to 16384)?
# 添 16384/主节点数量,如4主4从就是 16384 / 4 = 4096
输入 4096,并回车确认
# What is the receiving node ID?
输入 新加入主节点的ID,并回车确认
# Please enter all the source node IDs.
输入 all,并回车确认
# Do you want to proceed with the proposed reshard plan(yes/no)?
输入 yes,并回车确认
7. 重新查看集群信息,并记录6387的ID
redis-cli --cluster check 192.168.0.11:6381
8. 槽位变化

9. 槽位重分配规则
# 为什么6387 是3个新的区间,以前的还是连续的?
重新分配成本太高,前三家各自匀出来一部分,从6381、6382、6383三个旧节点分别匀出大概1365个槽位凑成4096个槽位给新节点6387
10. 为主节点6387 分配从节点6388
redis-cli --cluster add-node 192.168.0.11:6388 192.168.0.11:6387 --cluster-slave --cluster-master-id 要挂载的主节点在集群中的ID
11. 查看集群状态,从节点是否挂载成功
redis-cli --cluster check 192.168.0.11:6381
2.5 主从缩容
1. 检查集群状态,记录6387和6388的ID
redis-cli --cluster check 192.168.0.11:6381
2. 先删除 6388 从节点
redis-cli --cluster del-node 192.168.0.11:6388 从节点的ID
3. 检查集群状态,查看6388是否被删除成功
redis-cli --cluster check 192.168.0.11:6381
4. 以6381为切入点重新分配槽位,这里是重新平均分配
redis-cli --cluster reshard 192.168.0.11:6381
1. 一次性分配给6381
# How many slots do you want to move(from 1 to 16384)?
# 将6387的4096个槽位重新分配回3个主节点
输入 4096,并回车确认
# What is the receiving node ID?
输入参与分配主节点的ID(6381的ID),并回车确认
# Please enter all the source node IDs.
输入6387的ID
输入 done,并回车确认
# Do you want to proceed with the proposed reshard plan(yes/no)?
输入 yes,并回车确认
2. 自行均匀分配给6381,6382,6383
redis-cli --cluster reshard 192.168.0.11:6381
# How many slots do you want to move(from 1 to 16384)?
# 将6387的4096个槽位重新分配回3个主节点
输入 1365,并回车确认
# What is the receiving node ID?
输入参与分配主节点的ID(6381的ID),并回车确认
# Please enter all the source node IDs.
输入6387的ID
输入 done,并回车确认
# Do you want to proceed with the proposed reshard plan(yes/no)?
输入 yes,并回车确认
redis-cli --cluster reshard 192.168.0.11:6381
# How many slots do you want to move(from 1 to 16384)?
# 将6387的4096个槽位重新分配回3个主节点
输入 1365,并回车确认
# What is the receiving node ID?
输入参与分配主节点的ID(6382的ID),并回车确认
# Please enter all the source node IDs.
输入6387的ID
输入 done,并回车确认
# Do you want to proceed with the proposed reshard plan(yes/no)?
输入 yes,并回车确认
redis-cli --cluster reshard 192.168.0.11:6381
# How many slots do you want to move(from 1 to 16384)?
# 将6387的4096个槽位重新分配回3个主节点
输入 1366,并回车确认
# What is the receiving node ID?
输入参与分配主节点的ID(6383的ID),并回车确认
# Please enter all the source node IDs.
输入6387的ID
输入 done,并回车确认
# Do you want to proceed with the proposed reshard plan(yes/no)?
输入 yes,并回车确认
5. 查看集群状态,确认6387的槽位被清空
redis-cli --cluster check 192.168.0.11:6381
6. 从集群中删除6387
redis-cli --cluster del-node 192.168.0.11:6387 主节点的ID
7. 查看集群状态,确认6387被删除
redis-cli --cluster check 192.168.0.11:6381

 浙公网安备 33010602011771号
浙公网安备 33010602011771号