TDengine --- 基础
0. 概念
1. 介绍
TDengine 是一款开源、高性能、云原生的时序数据库(Time Series Database, TSDB), 它专为物联网、车联网、工业互联网、金融、IT 运维等场景优化设计。同时它还带有内建的缓存、流式计算、数据订阅等系统功能,能大幅减少系统设计的复杂度,降低研发和运营成本,是一款极简的时序数据处理平台。本文档是 TDengine 的用户手册,主要是介绍 TDengine 的基本概念、安装、使用、功能、开发接口、运营维护、TDengine 内核设计等等,它主要是面向架构师、开发工程师与系统管理员的。
TDengine 充分利用了时序数据的特点,提出了“一个数据采集点一张表”与“超级表”的概念,设计了创新的存储引擎,让数据的写入、查询和存储效率都得到极大的提升。
2. 特点
- 高性能:TDengine 是唯一一个解决了时序数据存储的高基数难题的时序数据库,支持上亿数据采集点,并在数据插入、查询和数据压缩上远胜其它时序数据库。
- 极简时序数据平台:TDengine 内建缓存、流式计算和数据订阅等功能,为时序数据的处理提供了极简的解决方案,从而大幅降低了业务系统的设计复杂度和运维成本。
- 云原生:通过原生的分布式设计、数据分片和分区、存算分离、RAFT 协议、Kubernetes 部署和完整的可观测性,TDengine 是一款云原生时序数据库并且能够部署在公有云、私有云和混合云上。
- 简单易用:对系统管理员来说,TDengine 大幅降低了管理和维护的代价。对开发者来说, TDengine 提供了简单的接口、极简的解决方案和与第三方工具的无缝集成。对数据分析专家来说,TDengine 提供了便捷的数据访问能力。
- 分析能力:通过超级表、存储计算分离、分区分片、预计算和其它技术,TDengine 能够高效地浏览、格式化和访问数据。
- 核心开源:TDengine 的核心代码包括集群功能全部在开源协议下公开。全球超过 140k 个运行实例,GitHub Star 20k,且拥有一个活跃的开发者社区。
采用 TDengine,可将典型的物联网、车联网、工业互联网大数据平台的总拥有成本大幅降低。表现在几个方面:
- 由于其超强性能,它能将系统所需的计算资源和存储资源大幅降低
- 因为支持 SQL,能与众多第三方软件无缝集成,学习迁移成本大幅下降
- 因为是一款极简的时序数据平台,系统复杂度、研发和运营成本大幅降低
3. 组成
为了便于解释基本概念,便于撰写示例程序,整个 TDengine 文档以智能电表作为典型时序数据场景。假设每个智能电表采集电流、电压、相位三个量,有多个智能电表,每个电表有位置 Location 和分组 Group ID 的静态属性. 其采集的数据类似如下的表格, 智能电表数据示例:
| Device ID | Timestamp | Collected Metrics | Tags | |||
|---|---|---|---|---|---|---|
| current | voltage | phase | location | groupid | ||
| d1001 | 1538548685000 | 10.3 | 219 | 0.31 | California.SanFrancisco | 2 |
| d1002 | 1538548684000 | 10.2 | 220 | 0.23 | California.SanFrancisco | 3 |
| d1003 | 1538548686500 | 11.5 | 221 | 0.35 | California.LosAngeles | 3 |
| d1004 | 1538548685500 | 13.4 | 223 | 0.29 | California.LosAngeles | 2 |
| d1001 | 1538548695000 | 12.6 | 218 | 0.33 | California.SanFrancisco | 2 |
| d1004 | 1538548696600 | 11.8 | 221 | 0.28 | California.LosAngeles | 2 |
| d1002 | 1538548696650 | 10.3 | 218 | 0.25 | California.SanFrancisco | 3 |
| d1001 | 1538548696800 | 12.3 | 221 | 0.31 | California.SanFrancisco | 2 |
每一条记录都有设备 ID、时间戳、采集的物理量(如上表中的 current、voltage 和 phase)以及每个设备相关的静态标签(location 和 groupid)。每个设备是受外界的触发,或按照设定的周期采集数据。采集的数据点是时序的,是一个数据流。
1. 采集量(Metric)
采集量是指传感器、设备或其他类型采集点采集的物理量,比如电流、电压、温度、压力、GPS 位置等,是随时间变化的,数据类型可以是整型、浮点型、布尔型,也可是字符串。随着时间的推移,存储的采集量的数据量越来越大。智能电表示例中的电流、电压、相位就是采集量。
2. 标签(Label/Tag)
标签是指传感器、设备或其他类型采集点的静态属性,不是随时间变化的,比如设备型号、颜色、设备的所在地等,数据类型可以是任何类型。虽然是静态的,但 TDengine 容许用户修改、删除或增加标签值。与采集量不一样的是,随时间的推移,存储的标签的数据量不会有什么变化。智能电表示例中的 location 与 groupid 就是标签。
3. 数据采集点(Data Collection Point)
数据采集点是指按照预设时间周期或受事件触发采集物理量的硬件或软件。一个数据采集点可以采集一个或多个采集量,但这些采集量都是同一时刻采集的,具有相同的时间戳。对于复杂的设备,往往有多个数据采集点,每个数据采集点采集的周期都可能不一样,而且完全独立,不同步。比如对于一台汽车,有数据采集点专门采集 GPS 位置,有数据采集点专门采集发动机状态,有数据采集点专门采集车内的环境,这样一台汽车就有三个数据采集点。智能电表示例中的 d1001、d1002、d1003、d1004 等就是数据采集点。
因为采集量一般是结构化数据,同时为降低学习门槛,TDengine 采用传统的关系型数据库模型管理数据。用户需要先创建库,然后创建表,之后才能插入或查询数据。
为充分利用其数据的时序性和其他数据特点,TDengine 采取一个数据采集点一张表的策略,要求对每个数据采集点单独建表(比如有一千万个智能电表,就需创建一千万张表,上述表格中的 d1001,d1002,d1003,d1004 都需单独建表),用来存储这个数据采集点所采集的时序数据。这种设计有几大优点:
- 由于不同数据采集点产生数据的过程完全独立,每个数据采集点的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升。
- 对于一个数据采集点而言,其产生的数据是按照时间排序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。
- 一个数据采集点的数据是以块为单位连续存储的。如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度。
- 一个数据块内部,采用列式存储,对于不同数据类型,采用不同压缩算法,而且由于一个数据采集点的采集量的变化是缓慢的,压缩率更高。
如果采用传统的方式,将多个数据采集点的数据写入一张表,由于网络延时不可控,不同数据采集点的数据到达服务器的时序是无法保证的,写入操作是要有锁保护的,而且一个数据采集点的数据是难以保证连续存储在一起的。采用一个数据采集点一张表的方式,能最大程度的保证单个数据采集点的插入和查询的性能是最优的。
TDengine 建议用数据采集点的名字(如上表中的 d1001)来做表名。每个数据采集点可能同时采集多个采集量(如上表中的 current、voltage 和 phase),每个采集量对应一张表中的一列,数据类型可以是整型、浮点型、字符串等。除此之外,表的第一列必须是时间戳,即数据类型为 Timestamp。对采集量,TDengine 将自动按照时间戳建立索引,但对采集量本身不建任何索引。数据用列式存储方式保存。
对于复杂的设备,比如汽车,它有多个数据采集点,那么就需要为一辆汽车建立多张表。
4. 表(Table)
因为采集量一般是结构化数据,同时为降低学习门槛,TDengine 采用传统的关系型数据库模型管理数据。用户需要先创建库,然后创建表,之后才能插入或查询数据。
为充分利用其数据的时序性和其他数据特点,TDengine 采取一个数据采集点一张表的策略,要求对每个数据采集点单独建表(比如有一千万个智能电表,就需创建一千万张表,上述表格中的 d1001,d1002,d1003,d1004 都需单独建表),用来存储这个数据采集点所采集的时序数据。这种设计有几大优点:
- 由于不同数据采集点产生数据的过程完全独立,每个数据采集点的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升。
- 对于一个数据采集点而言,其产生的数据是按照时间排序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。
- 一个数据采集点的数据是以块为单位连续存储的。如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度。
- 一个数据块内部,采用列式存储,对于不同数据类型,采用不同压缩算法,而且由于一个数据采集点的采集量的变化是缓慢的,压缩率更高。
如果采用传统的方式,将多个数据采集点的数据写入一张表,由于网络延时不可控,不同数据采集点的数据到达服务器的时序是无法保证的,写入操作是要有锁保护的,而且一个数据采集点的数据是难以保证连续存储在一起的。采用一个数据采集点一张表的方式,能最大程度的保证单个数据采集点的插入和查询的性能是最优的。
TDengine 建议用数据采集点的名字(如上表中的 d1001)来做表名。每个数据采集点可能同时采集多个采集量(如上表中的 current、voltage 和 phase),每个采集量对应一张表中的一列,数据类型可以是整型、浮点型、字符串等。除此之外,表的第一列必须是时间戳,即数据类型为 Timestamp。对采集量,TDengine 将自动按照时间戳建立索引,但对采集量本身不建任何索引。数据用列式存储方式保存。
对于复杂的设备,比如汽车,它有多个数据采集点,那么就需要为一辆汽车建立多张表。
5. 超级表(STable)
由于一个数据采集点一张表,导致表的数量巨增,难以管理,而且应用经常需要做采集点之间的聚合操作,聚合的操作也变得复杂起来。为解决这个问题,TDengine 引入超级表(Super Table,简称为 STable)的概念。
超级表是指某一特定类型的数据采集点的集合。同一类型的数据采集点,其表的结构是完全一样的,但每个表(数据采集点)的静态属性(标签)是不一样的。描述一个超级表(某一特定类型的数据采集点的集合),除需要定义采集量的表结构之外,还需要定义其标签的 Schema,标签的数据类型可以是整数、浮点数、字符串、JSON,标签可以有多个,可以事后增加、删除或修改。如果整个系统有 N 个不同类型的数据采集点,就需要建立 N 个超级表。
在 TDengine 的设计里,表用来代表一个具体的数据采集点,超级表用来代表一组相同类型的数据采集点集合。智能电表示例中,我们可以创建一个超级表 meters.
6. 子表(Subtable)
当为某个具体数据采集点创建表时,用户可以使用超级表的定义做模板,同时指定该具体采集点(表)的具体标签值来创建该表。通过超级表创建的表称之为子表。正常的表与子表的差异在于:
- 子表就是表,因此所有正常表的 SQL 操作都可以在子表上执行。
- 子表在正常表的基础上有扩展,它是带有静态标签的,而且这些标签可以事后增加、删除、修改,而正常的表没有。
- 子表一定属于一张超级表,但普通表不属于任何超级表
- 普通表无法转为子表,子表也无法转为普通表。
超级表与基于超级表建立的子表之间的关系表现在:
- 一张超级表包含有多张子表,这些子表具有相同的采集量 Schema,但带有不同的标签值。
- 不能通过子表调整数据或标签的模式,对于超级表的数据模式修改立即对所有的子表生效。
- 超级表只定义一个模板,自身不存储任何数据或标签信息。因此,不能向一个超级表写入数据,只能将数据写入子表中。
查询既可以在表上进行,也可以在超级表上进行。针对超级表的查询,TDengine 将把所有子表中的数据视为一个整体数据集进行处理,会先把满足标签过滤条件的表从超级表中找出来,然后再扫描这些表的时序数据,进行聚合操作,这样需要扫描的数据集会大幅减少,从而显著提高查询的性能。本质上,TDengine 通过对超级表查询的支持,实现了多个同类数据采集点的高效聚合。
TDengine 系统建议给一个数据采集点建表,需要通过超级表建表,而不是建普通表。在智能电表的示例中,我们可以通过超级表 meters 创建子表 d1001、d1002、d1003、d1004 等。
为了更好地理解采集量、标签、超级与子表的关系,可以参考下面关于智能电表数据模型的示意图。
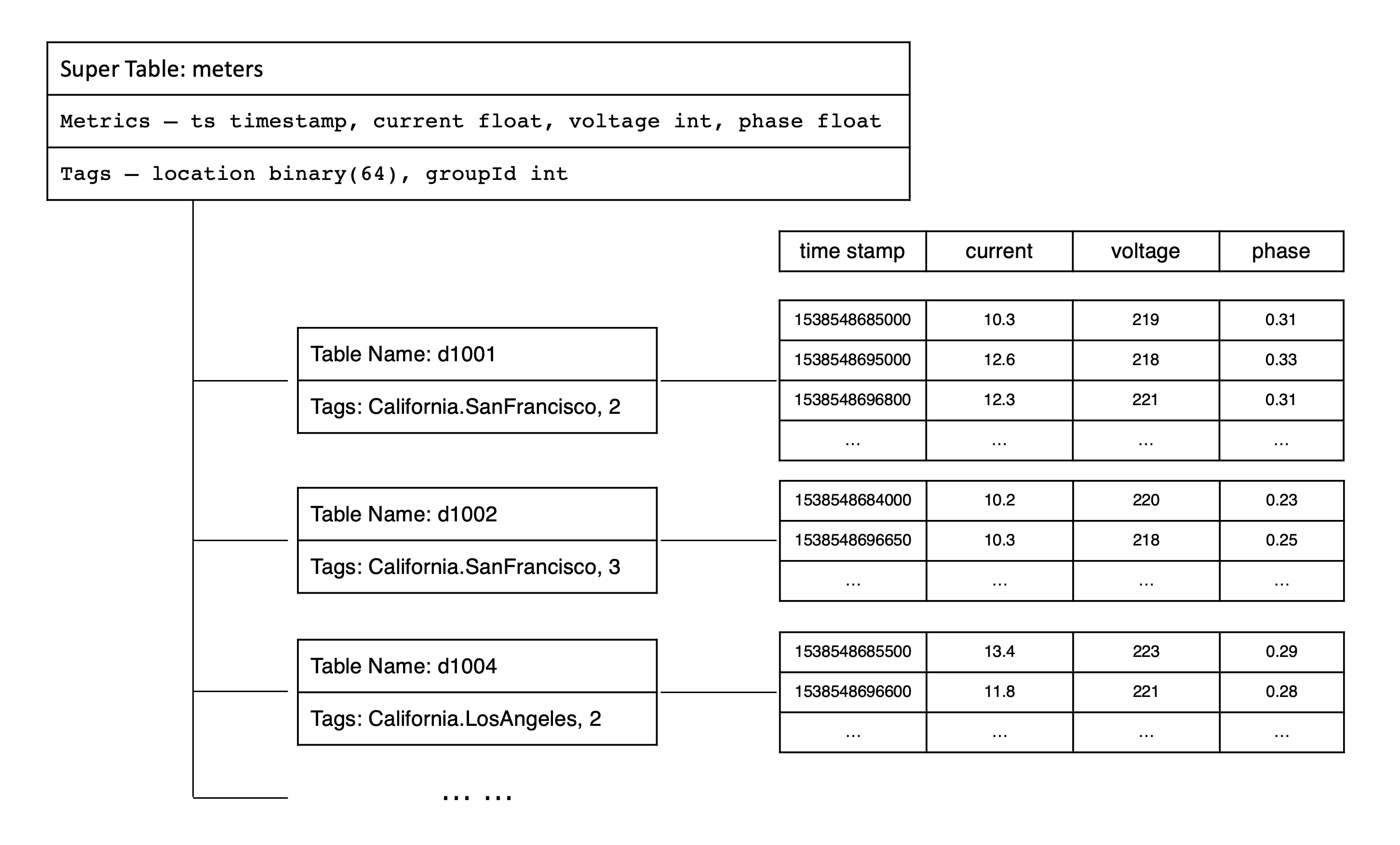
7. 库(Database)
库是指一组表的集合。TDengine 容许一个运行实例有多个库,而且每个库可以配置不同的存储策略。不同类型的数据采集点往往具有不同的数据特征,包括数据采集频率的高低,数据保留时间的长短,副本的数目,数据块的大小,是否允许更新数据等等。为了在各种场景下 TDengine 都能最大效率的工作,TDengine 建议将不同数据特征的超级表创建在不同的库里。
一个库里,可以有一到多个超级表,但一个超级表只属于一个库。一个超级表所拥有的子表全部存在一个库里。
8. FQDN & Endpoint
FQDN(Fully Qualified Domain Name,完全限定域名)是 Internet 上特定计算机或主机的完整域名。FQDN 由两部分组成:主机名和域名。例如,假设邮件服务器的 FQDN 可能是 mail.tdengine.com。主机名是 mail,主机位于域名 tdengine.com 中。DNS(Domain Name System),负责将 FQDN 翻译成 IP,是互联网应用的寻址方式。对于没有 DNS 的系统,可以通过配置 hosts 文件来解决。
TDengine 集群的每个节点是由 Endpoint 来唯一标识的,Endpoint 是由 FQDN 外加 Port 组成,比如 h1.tdengine.com:6030。这样当 IP 发生变化的时候,我们依然可以使用 FQDN 来动态找到节点,不需要更改集群的任何配置。而且采用 FQDN,便于内网和外网对同一个集群的统一访问。
TDengine 不建议采用直接的 IP 地址访问集群,不利于管理。不了解 FQDN 概念,请看博文《一篇文章说清楚 TDengine 的 FQDN》。
4. 典型应用场景
作为一个高性能、分布式、支持 SQL 的时序数据库(Time-series Database),TDengine 的典型适用场景包括但不限于 IoT、工业互联网、车联网、IT 运维、能源、金融证券等领域。需要指出的是,TDengine 是针对时序数据场景设计的专用数据库和专用大数据处理工具,因其充分利用了时序大数据的特点,它无法用来处理网络爬虫、微博、微信、电商、ERP、CRM 等通用型数据。下面本文将对适用场景做更多详细的分析。
5. 主要功能
1. 写入数据,支持多种模式和多工具无缝集成
# SQL 写入
无模式(Schemaless)写入,支持多种标准写入协议
InfluxDB Line 协议
OpenTSDB Telnet 协议
OpenTSDB JSON 协议
# 与多种第三方工具的无缝集成,它们都可以仅通过配置而无需任何代码即可将数据写入 TDengine
Telegraf
Prometheus
StatsD
collectd
Icinga2
TCollector
EMQX
HiveMQ
2. 查询数据,支持
标准 SQL,含嵌套查询
时序数据特色函数
时序数据特色查询,例如降采样、插值、累加和、时间加权平均、状态窗口、会话窗口等
用户自定义函数(UDF)
3. 缓存,将每张表的最后一条记录缓存起来,这样无需 Redis 就能对时序数据进行高效处理
4. 流式计算(Stream Processing),TDengine 不仅支持连续查询,还支持事件驱动的流式计算,这样在处理时序数据时就无需 Flink 或 Spark 这样流式计算组件
5. 数据订阅,应用程序可以订阅一张表或一组表的数据,提供与 Kafka 相同的 API,而且可以指定过滤条件
6. 可视化
支持与 Grafana 的无缝集成
支持与 Google Data Studio 的无缝集成
7. 集群
集群部署,可以通过增加节点进行水平扩展以提升处理能力
可以通过 Kubernetes 部署 TDengine
通过多副本提供高可用能力
8. 管理
监控运行中的 TDengine 实例
多种数据导入方式
多种数据导出方式
9. 工具
提供交互式命令行程序(CLI),便于管理集群,检查系统状态,做即席查询
提供压力测试工具 taosBenchmark,用于测试 TDengine 的性能
10. 编程
提供各种语言的连接器(Connector): 如 C/C++、Java、Go、Node.js、Rust、Python、C# 等
支持 REST 接口
6. 竞争优势
由于 TDengine 充分利用了时序数据特点,比如结构化、无需事务、很少删除或更新、写多读少等等,因此与其他时序数据库相比,TDengine 有以下特点:
1. 高性能:TDengine 是唯一一个解决了时序数据存储的高基数难题的时序数据库,支持上亿数据采集点,并在数据插入、查询和数据压缩上远胜其它时序数据库。
2. 极简时序数据平台:TDengine 内建缓存、流式计算和数据订阅等功能,为时序数据的处理提供了极简的解决方案,从而大幅降低了业务系统的设计复杂度和运维成本。
3. 云原生:通过原生的分布式设计、数据分片和分区、存算分离、RAFT 协议、Kubernetes 部署和完整的可观测性,TDengine 是一款云原生时序数据库并且能够部署在公有云、私有云和混合云上。
4. 简单易用:对系统管理员来说,TDengine 大幅降低了管理和维护的代价。对开发者来说, TDengine 提供了简单的接口、极简的解决方案和与第三方工具的无缝集成。对数据分析专家来说,TDengine 提供了便捷的数据访问能力。
5. 分析能力:通过超级表、存储计算分离、分区分片、预计算和其它技术,TDengine 能够高效地浏览、格式化和访问数据。
6. 核心开源:TDengine 的核心代码包括集群功能全部在开源协议下公开。全球超过 140k 个运行实例,GitHub Star 20k,且拥有一个活跃的开发者社区。
7. 采用 TDengine,可将典型的物联网、车联网、工业互联网大数据平台的总拥有成本大幅降低。表现在几个方面:
由于其超强性能,它能将系统所需的计算资源和存储资源大幅降低
因为支持 SQL,能与众多第三方软件无缝集成,学习迁移成本大幅下降
因为是一款极简的时序数据平台,系统复杂度、研发和运营成本大幅降低
1. 建立连接
1. 原生连接
1. 必须先下载客户端安装包
https://docs.taosdata.com/connector/#%E5%AE%89%E8%A3%85%E6%AD%A5%E9%AA%A4
2. 模块下载
pip install taospy
3. 建立连接
在前端可视化网站的编程菜单找到对应的代码
import taos
conn = None
try:
conn = taos.connect(
host="81.70.168.242",
user="root",
password="taosdata",
database="log",
port=6030,
config="/etc/taos", # for windows the default value is C:\TDengine\cfg
timezone="Asia/Shanghai",
)
print(conn.server_info)
except taos.Error as e:
print(e)
print("exception class: ", e.__class__.__name__)
print("error number:", e.errno)
print("error message:", e.msg)
except BaseException as other:
print("exception occur")
print(other)
finally:
if conn:
conn.close()
2. WebSocket 连接
0. 版本要求
- 要求
python版本在3.7+
1. 模块下载
# 单独安装 taos-ws
pip install taos-ws-py
2. 建立连接
import taosws
dsn = "taosws://root:taosdata@81.70.168.242:6041"
conn = taosws.connect(dsn)
print(conn)
3. 关闭连接
conn.close()
2. 建库
0. 建库策略
1. 如何判断数据库的cachesize够用
查看cachesize
select * from information_schema.ins_databases;
查看cacheload
show <db_name>.vgroups;
判断 cachesize 是否够用
如果 cacheload 非常接近 cachesize,则 cachesize 可能过小。 如果 cacheload 明显小于 cachesize 则 cachesize 是够用的。可以根据这个原则判断是否需要修改 cachesize 。具体修改值可以根据系统可用内存情况来决定是加倍或者是提高几倍。
1. 常用参数
1. BUFFER
一个 VNODE 写入内存池大小,单位为 MB,默认为 256,最小为 3,最大为 16384。
2. CACHEMODEL
表示是否在内存中缓存子表的最近数据。默认为 none。
- none:表示不缓存。
- last_row:表示缓存子表最近一行数据。这将显著改善 LAST_ROW 函数的性能表现。
- last_value:表示缓存子表每一列的最近的非 NULL 值。这将显著改善无特殊影响(WHERE、ORDER BY、GROUP BY、INTERVAL)下的 LAST 函数的性能表现。
- both:表示同时打开缓存最近行和列功能。 Note:CacheModel 值来回切换有可能导致 last/last_row 的查询结果不准确,请谨慎操作。推荐保持打开。
3. CACHESIZE
表示每个 vnode 中用于缓存子表最近数据的内存大小。默认为 1 ,范围是[1, 65536],单位是 MB。
4. COMP
表示数据库文件压缩标志位,缺省值为 2,取值范围为 [0, 2]。
- 0:表示不压缩。
- 1:表示一阶段压缩。
- 2:表示两阶段压缩。
5. DURATION
数据文件存储数据的时间跨度。可以使用加单位的表示形式,如 DURATION 100h、DURATION 10d 等,支持 m(分钟)、h(小时)和 d(天)三个单位。不加时间单位时默认单位为天,如 DURATION 50 表示 50 天。
6. WAL_FSYNC_PERIOD
当 WAL_LEVEL 参数设置为 2 时,用于设置落盘的周期。默认为 3000,单位毫秒。最小为 0,表示每次写入立即落盘;最大为 180000,即三分钟。
7. MAXROWS
文件块中记录的最大条数,默认为 4096 条。
8. MINROWS
文件块中记录的最小条数,默认为 100 条。
9. KEEP
表示数据文件保存的天数,缺省值为 3650,取值范围 [1, 365000],且必须大于或等于3倍的 DURATION 参数值。数据库会自动删除保存时间超过 KEEP 值的数据。KEEP 可以使用加单位的表示形式,如 KEEP 100h、KEEP 10d 等,支持 m(分钟)、h(小时)和 d(天)三个单位。也可以不写单位,如 KEEP 50,此时默认单位为天。企业版支持多级存储功能, 因此, 可以设置多个保存时间(多个以英文逗号分隔,最多 3 个,满足 keep 0 <= keep 1 <= keep 2,如 KEEP 100h,100d,3650d); 社区版不支持多级存储功能(即使配置了多个保存时间, 也不会生效, KEEP 会取最大的保存时间)。
10. PAGES
一个 VNODE 中元数据存储引擎的缓存页个数,默认为 256,最小 64。一个 VNODE 元数据存储占用 PAGESIZE * PAGES,默认情况下为 1MB 内存。
11. PAGESIZE
一个 VNODE 中元数据存储引擎的页大小,单位为 KB,默认为 4 KB。范围为 1 到 16384,即 1 KB 到 16 MB。
12. PRECISION
数据库的时间戳精度。ms 表示毫秒,us 表示微秒,ns 表示纳秒,默认 ms 毫秒。
13. REPLICA
表示数据库副本数,取值为 1、2 或 3,默认为 1; 2 仅在企业版 3.3.0.0 及以后版本中可用。在集群中使用,副本数必须小于或等于 DNODE 的数目。
14. WAL_LEVEL
WAL(Write Ahead Log),是 TDengine 的一个重要的功能模块,它可以实现数据的容错能力,保证数据的高可用,默认为 1。
- 1:写 WAL,但不执行 fsync。
- 2:写 WAL,而且执行 fsync。
翻译一下是“预写日志”,含义就是:在数据写入存储之前,先按照时间顺序在日志中做一下记录,这样就可以确保应用能够通过这个日志将数据库恢复到任意的某个状态,即使数据库因为断电等意外事故宕机,也能避免数据的丢失。目前,TDengine社区版尚不支持将数据回滚到指定时间。TDengine 中的 WAL 实现机制稍有特殊。它把 WAL 分为两部分,一种是 管理节点(mnode) 目录下的 WAL,一种是 虚拟数据节点(vnode) 目录下的 WAL。在 TDengine 的数据文件路径下(默认为/var/lib/taos),就可以看到上述目录结构。
对于关系型数据库的使用者来说,它大概就相当于 Oracle 中的 redolog ,MySQL 中的 binlog 和 redolog,里面记录的是一切关于数据库的更新修改操作。
mnode 的 WAL 内容是持久化在硬盘上的,作为最重要的管理节点,它的 WAL 记录着所有关于数据库的 DDL 操作(比如创建删除操作:create dnode,create account,create mnode,create user,create table, drop dnode ,drop table等,或者修改操作:alter database,alter table ,alter user等)
而 vnode 目录下的 WAL 则主要负责记录着写入数据的操作,与此同时也记录着对表的 DDL 操作,在触发落盘后会清零。之后,写入 vnode 的时序数据会落盘到数据文件目录 /vnode/vnodeX/tsdb/data 下面。而对于表的 DDL 操作(也就是表的元数据)则会落盘到数据文件目录/vnode/vnodeX/tsdb/meta文件中,
上面的第二张图是 vnode 的工作流程,从这里我们可以更清楚地看到时序数据和元数据是如何在写满三分之一的 buffer pool 后落地到磁盘的(一个 meta 文件,一个数据文件组:.data、.head、.last文件)。
总结而言,mnode 通过 WAL 记录了集群、用户、数据库以及表的元数据等信息。而 vnode 通过 WAL 记录了数据和表的元数据,并且会在落盘触发后清零,而其记录的表的元数据会被写入到 meta 文件,时序数据会被写入到 data 目录。
在了解了 WAL 的作用后,接下来会衍生出细节的场景:
首先,WAL 是将数据库数据更新操作按照时间顺序追加更新的日志文件。数据库进程 taosd 在启动的时候会逐行读取 mnode 下的 WAL 文件并操作,直到最后一行,才能顺利启动服务。
这样的构造下,可能会导致这个问题出现:
1.当累计的 DDL 操作过多时,TDengine 的启动会变慢——那么要如何避免这种情况的发生呢?
首先,当子表数量绝对大的时候,这个情况是没法避免的。但是这是一个很大的数量级,对于绝大多数用户都是达不到的。
更容易出现的是这种情况:这个环境表数量并不是很多,但是却充满了频繁的删库删表重建表等操作。比如,创建一个十万子表的超级表后删掉,然后再重建这个超级表。等到数据库启动加载WAL的时候,即便前面的 create table 和 drop table 都是无效的操作,但是还会被操作一遍,而且删表操作本身在加载的时候也会更慢一些,从而大幅拖慢 TDengine 的启动速度。
因此,为了避免这种情况,生产环境上一定要慎重。尤其是要尽量杜绝删库、删除超级表这些重大操作,如果是为了调试,反复重建的测试操作一定要在测试环境进行,生产环境不可延用测试环境直接建库建表投入使用,除非该服务器的 TDengine 已经卸载干净。
2.那如果是使用时间太久,或者各种更改表结构的操作无可避免,导致 mnode 下的 WAL 过大,是不是无解了呢?
对于这种情况,在 2.1.5 版本之后,我们提供了离线压缩 Mnode WAL 的方案来解决:
1)单机:
- systemctl stop taosd。
- taosd --compact-mnode-wal,如果执行正常的话,会在数据文件目录下生成 mnode_bak 目录,用于保存原数据。
- systemctl start taosd,这样 TDengine 就会使用压缩过的 wal 日志来启动数据库服务进程。
2)集群:
- show mnodes ,确认 mnode 节点所在的服务器,并且区分 mnode 的 master 和 slave。
- systemctl stop taosd,停止集群所有节点。
- 【可选】移出所有mnode 节点上的 mnode_bak目录。
- 在 mnode master 服务器上,以 root 权限执行 taosd --compact-mnode-wal 。
- 将 mnode master 压缩后的 mnode/wal/* 文件复制到其他 slave 节点对应目录。
- 重启集群。
值得注意的是,taosd --compact-mnode-wal 命令第一次的运行时间与压缩前集群启动时间基本相同,要等到下次再启动的时候速度才会变快。
此外,在未来的 TDengine 3.0 版本中,这也会是我们的重大的优化项。由于 WAL 也会变成分布式的存储,届时,即使是在亿级别表数量的情况下,TDengine 的启停速度也都不再会是问题。而且这项优化不过是 3.0 版本诸多特性的冰山一角。这项调整的背后代表着 TDengine 对于很多重要模块的优化重构,稳定性和性能都会大幅提高,多项重磅功能也会上线。
15. VGROUPS
数据库中初始 vgroup 的数目。
16. SINGLE_STABLE
表示此数据库中是否只可以创建一个超级表,用于超级表列非常多的情况。
- 0:表示可以创建多张超级表。
- 1:表示只可以创建一张超级表。
17. STT_TRIGGER
表示落盘文件触发文件合并的个数。默认为 1,范围 1 到 16。对于少表高频场景,此参数建议使用默认配置,或较小的值;而对于多表低频场景,此参数建议配置较大的值。
18. TABLE_PREFIX
当其为正值时,在决定把一个表分配到哪个 vgroup 时要忽略表名中指定长度的前缀;当其为负值时,在决定把一个表分配到哪个 vgroup 时只使用表名中指定长度的前缀;例如,假定表名为 "v30001",当 TSDB_PREFIX = 2 时 使用 "0001" 来决定分配到哪个 vgroup ,当 TSDB_PREFIX = -2 时使用 "v3" 来决定分配到哪个 vgroup
19. TABLE_SUFFIX
当其为正值时,在决定把一个表分配到哪个 vgroup 时要忽略表名中指定长度的后缀;当其为负值时,在决定把一个表分配到哪个 vgroup 时只使用表名中指定长度的后缀;例如,假定表名为 "v30001",当 TSDB_SUFFIX = 2 时 使用 "v300" 来决定分配到哪个 vgroup ,当 TSDB_SUFFIX = -2 时使用 "01" 来决定分配到哪个 vgroup。
20. TSDB_PAGESIZE
一个 VNODE 中时序数据存储引擎的页大小,单位为 KB,默认为 4 KB。范围为 1 到 16384,即 1 KB到 16 MB。
21. WAL_RETENTION_PERIOD
为了数据订阅消费,需要WAL日志文件额外保留的最大时长策略。WAL日志清理,不受订阅客户端消费状态影响。单位为 s。默认为 3600,表示在 WAL 保留最近 3600 秒的数据,请根据数据订阅的需要修改这个参数为适当值。
22. WAL_RETENTION_SIZE
为了数据订阅消费,需要WAL日志文件额外保留的最大累计大小策略。单位为 KB。默认为 0,表示累计大小无上限。
2. 创建库
默认时间戳为毫秒级别
import taosws
dsn = "taosws://root:taosdata@81.70.168.242:6041"
conn = taosws.connect(dsn)
# 创建数据库
db = "power"
# 创建一个名为 power 的库
# KEEP 365 数据库会自动删除保存时间超过 KEEP 值的数据,默认为3650天, 支持 m(分钟)、h(小时)和 d(天)三个单位,
# DURATION 10 每 10 天一个数据文件
# BUFFER 1 每个 VNode 的写入内存池的大小为 16 MB,
# WAL_LEVEL 1 对该数据库入会写 WAL 但不执行 FSYNC。
# PRECISION 'us' 数据库的时间戳精度,ms 表示毫秒,us 表示微秒,ns 表示纳秒, 默认 ms 毫秒。
# CACHEMODEL both 同时缓存子表最近一行数据 和 每一列的最近的非 NULL 值
# DURATION 支持 m(分钟)、h(小时)和 d(天)三个单位, 默认为天, 酌情添加
# WAL_FSYNC_PERIOD 用于设置落盘的周期 0 - 6000 *3, 默认为 3000, 单位为毫秒, 最小为0, 表示每次写入立即落盘
# MAXROWS 文件块中记录的最大条数,默认为 4096 条
# MINROWS:文件块中记录的最小条数,默认为 100 条
# PAGES 一个 VNODE 中元数据存储引擎的页大小,单位为 KB,默认为 4 KB。范围为 1 到 16384,即 1 KB 到 16 MB
# SINGLE_STABLE 表示此数据库中是否只可以创建一个超级表,用于超级表列非常多的情况。 0:表示可以创建多张超级表。 1:表示只可以创建一张超级表。
# STT_TRIGGER:表示落盘文件触发文件合并的个数。默认为 1,范围 1 到 16。对于少表高频场景,此参数建议使用默认配置,或较小的值;而对于多表低频场景,此参数建议配置较大的值。
# WAL_RETENTION_PERIOD: 为了数据订阅消费,需要WAL日志文件额外保留的最大时长策略,单位为 s。默认为 3600,表示在 WAL 保留最近 3600 秒的数据
# WAL_RETENTION_SIZE:为了数据订阅消费,需要WAL日志文件额外保留的最大累计大小策略。单位为 KB。默认为 0,表示累计大小无上限。
conn.execute(f"CREATE DATABASE {db} KEEP 365 DURATION 10 BUFFER 16 WAL_LEVEL 1 CACHEMODEL both")
3. 使用库
# 切换库
conn.execute(f"USE {db}")
3. 建表
1. 超级表
0. 建表策略
由于一个数据采集点一张表,导致表的数量巨增,难以管理,而且应用经常需要做采集点之间的聚合操作,聚合的操作也变得复杂起来。为解决这个问题,TDengine 引入超级表(Super Table,简称为 STable)的概念。
超级表是指某一特定类型的数据采集点的集合。同一类型的数据采集点,其表的结构是完全一样的,但每个表(数据采集点)的静态属性(标签)是不一样的。描述一个超级表(某一特定类型的数据采集点的集合),除需要定义采集量的表结构之外,还需要定义其标签的 Schema,标签的数据类型可以是整数、浮点数、字符串、JSON,标签可以有多个,可以事后增加、删除或修改。如果整个系统有 N 个不同类型的数据采集点,就需要建立 N 个超级表。
在 TDengine 的设计里,表用来代表一个具体的数据采集点,超级表用来代表一组相同类型的数据采集点集合。智能电表示例中,我们可以创建一个超级表 meters.
1. 创建超级表
# 需要提供表名(示例中为 meters),表结构 Schema,即数据列的定义。第一列必须为时间戳(示例中为 ts),
# 其他列为采集的物理量(示例中为 current, voltage, phase),数据类型可以为整型、浮点型、字符串等。除此之外,
# 还需要提供标签的 Schema (示例中为 location, groupId),标签的数据类型可以为整型、浮点型、字符串等。
# 采集点的静态属性往往可以作为标签,比如采集点的地理位置、设备型号、设备组 ID、管理员 ID 等等。标签的 Schema 可以事后增加、删除、修改。
conn.execute(
"CREATE STABLE meters (ts timestamp, current float, voltage int, phase float) TAGS (groupId int, location binary(64))"
)
2. 多列模型 和 单列模型
TDengine 支持多列模型,只要物理量是一个数据采集点同时采集的(时间戳一致),这些量就可以作为不同列放在一张超级表里。但还有一种极限的设计,单列模型,每个采集的物理量都单独建表,因此每种类型的物理量都单独建立一超级表。比如电流、电压、相位,就建三张超级表。
TDengine 建议尽可能采用多列模型,因为插入效率以及存储效率更高。但对于有些场景,一个采集点的采集量的种类经常变化,这个时候,如果采用多列模型,就需要频繁修改超级表的结构定义,让应用变的复杂,这个时候,采用单列模型会显得更简单。
2. 表
0. 建表策略
# 为充分利用其数据的时序性和其他数据特点,TDengine 采取一个数据采集点一张表的策略,要求对每个数据采集点单独建表(比如有一千万个智能电表,就需创建一千万张表,用来存储这个数据采集点所采集的时序数据。这种设计有几大优点:
1. 由于不同数据采集点产生数据的过程完全独立,每个数据采集点的数据源是唯一的,一张表也就只有一个写入者,这 样就可采用无锁方式来写,写入速度就能大幅提升。
2. 对于一个数据采集点而言,其产生的数据是按照时间排序的,因此写的操作可用追加的方式实现,进一步大幅提高数 据写入速度。
3. 一个数据采集点的数据是以块为单位连续存储的。如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量 级的提升读取和查询速度。
4. 一个数据块内部,采用列式存储,对于不同数据类型,采用不同压缩算法,而且由于一个数据采集点的采集量的变化 是缓慢的,压缩率更高。
如果采用传统的方式,将多个数据采集点的数据写入一张表,由于网络延时不可控,不同数据采集点的数据到达服务器的时序是无法保证的,写入操作是要有锁保护的,而且一个数据采集点的数据是难以保证连续存储在一起的。'''采用一个数据采集点一张表的方式,能最大程度的保证单个数据采集点的插入和查询的性能是最优的'''
Dengine 建议用数据采集点的名字(如上表中的 d1001)来做表名。每个数据采集点可能同时采集多个采集量(如上表中的 current、voltage 和 phase),每个采集量对应一张表中的一列,数据类型可以是整型、浮点型、字符串等。除此之外,表的第一列必须是时间戳,即数据类型为 Timestamp。对采集量,TDengine 将自动按照时间戳建立索引,但对采集量本身不建任何索引。数据用列式存储方式保存。
对于复杂的设备,比如汽车,它有多个数据采集点,那么就需要为一辆汽车建立多张表。
子表(Subtable)
当为某个具体数据采集点创建表时,用户可以使用超级表的定义做模板,同时指定该具体采集点(表)的具体标签值来创建该表。通过超级表创建的表称之为子表。正常的表与子表的差异在于:
- 子表就是表,因此所有正常表的 SQL 操作都可以在子表上执行。
- 子表在正常表的基础上有扩展,它是带有静态标签的,而且这些标签可以事后增加、删除、修改,而正常的表没有。
- 子表一定属于一张超级表,但普通表不属于任何超级表
- 普通表无法转为子表,子表也无法转为普通表。
超级表与基于超级表建立的子表之间的关系表现在:
- 一张超级表包含有多张子表,这些子表具有相同的采集量 Schema,但带有不同的标签值。
- 不能通过子表调整数据或标签的模式,对于超级表的数据模式修改立即对所有的子表生效。
- 超级表只定义一个模板,自身不存储任何数据或标签信息。因此,不能向一个超级表写入数据,只能将数据写入子表中。
查询既可以在表上进行,也可以在超级表上进行。针对超级表的查询,TDengine 将把所有子表中的数据视为一个整体数据集进行处理,会先把满足标签过滤条件的表从超级表中找出来,然后再扫描这些表的时序数据,进行聚合操作,这样需要扫描的数据集会大幅减少,从而显著提高查询的性能。本质上,TDengine 通过对超级表查询的支持,实现了多个同类数据采集点的高效聚合。
TDengine 系统建议给一个数据采集点建表,需要通过超级表建表,而不是建普通表。在智能电表的示例中,我们可以通过超级表 meters 创建子表 d1001、d1002、d1003、d1004 等。
为了更好地理解采集量、标签、超级与子表的关系,可以参考下面关于智能电表数据模型的示意图。
1. 创建单表
每一个设备创建一个表
-- 其中 d1001 是表名,meters 是超级表的表名,后面紧跟标签 Location 的具体标签值为 "California.SanFrancisco",标签 groupId 的具体标签值为 2
CREATE TABLE d1001 USING meters TAGS (1, 'California.SanFrancisco')
2. 创建多表
每一个设备创建一个表
CREATE TABLE
`d1001` USING `meters` TAGS(0, 'Los Angles')
`d1002` USING `meters` TAGS(0, 'Los Angles')
`d1003` USING `meters` TAGS(1, 'California.SanFrancisco')
`d1004` USING `meters` TAGS(1, 'California.SanFrancisco')
3. 自动建表
在某些特殊场景中,用户在写数据时并不确定某个数据采集点的表是否存在,此时可在写入数据时使用自动建表语法来创建不存在的表,若该表已存在则不会建立新表且后面的 USING 语句被忽略。
INSERT INTO d1001 USING meters TAGS (1, "California.SanFrancisco") VALUES (NOW, 10.2, 219, 0.32)
上述 SQL 语句将记录(NOW, 10.2, 219, 0.32)插入表 d1001。如果表 d1001 还未创建,则使用超级表 meters 做模板自动创建,同时打上标签值 2, "California.SanFrancisco"
4. 写入数据
1. 时间戳精度
TDengine 要求插入的数据必须要有时间戳
- 字符串格式的时间戳写法不受所在 DATABASE 的时间精度设置影响;而长整形格式的时间戳写法会受到所在 DATABASE 的时间精度设置影响
- 时间戳"2021-07-13 16:16:48"的 UNIX 秒数为 1626164208。则其在毫秒精度下需要写作 1626164208000,在微秒精度设置下就需要写为 1626164208000000,纳秒精度设置下需要写为 1626164208000000000。
- 一次插入多行数据时,不要把首列的时间戳的值都写 NOW。否则会导致语句中的多条记录使用相同的时间戳,于是就可能出现相互覆盖以致这些数据行无法全部被正确保存
- 其原因在于,NOW 函数在执行中会被解析为所在 SQL 语句的客户端执行时间,出现在同一语句中的多个 NOW 标记也就会被替换为完全相同的时间戳取值。
- 允许插入的最老记录的时间戳,是相对于当前服务器时间,减去配置的 KEEP 值(数据保留的天数, 可以在创建数据库时指定,缺省值是 3650 天)。
- 允许插入的最新记录的时间戳,取决于数据库的 PRECISION 值(时间戳精度, 可以在创建数据库时指定, ms 表示毫秒,us 表示微秒,ns 表示纳秒,默认毫秒):如果是毫秒或微秒, 取值为 1970 年 1 月 1 日 00:00:00.000 UTC 加上 1000 年, 即 2970 年 1 月 1 日 00:00:00.000 UTC; 如果是纳秒, 取值为 1970 年 1 月 1 日 00:00:00.000000000 UTC 加上 292 年, 即 2262 年 1 月 1 日 00:00:00.000000000 UTC。
**示例: **
ts1 = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
# '{ts}', 外面必须加 单引号,才表示该参数是字符串格式
conn.execute(f"INSERT INTO d1001 VALUES ('{ts1}', 10.3, 219, 0.31)")
2. 插入一条
-- NOW 指插入数据时的当前时间戳
IINSERT INTO d1001 VALUES (NOW, 10.2, 219, 0.32)
3. 插入多条
INSERT INTO d1001 VALUES
('2021-07-13 14:06:32.272', 10.2, 219, 0.32)
(1626164208000, 10.15, 217, 0.33) -- 插入时间戳时, 要注意数据库设置的时间戳精度
4. 指定列插入
向数据子表中插入记录时,无论插入一行还是多行,都可以让数据对应到指定的列。对于 SQL 语句中没有出现的列,数据库将自动填充为 NULL。主键(时间戳)不能为 NULL。
INSERT INTO d1001 (ts, current, phase) VALUES ('2021-07-13 14:06:33.196', 10.27, 0.31);
5. 向多个表插入
INSERT INTO
d1001 VALUES
('2021-07-13 14:06:34.630', 10.2, 219, 0.32)
('2021-07-13 14:06:35.779', 10.15, 217, 0.33)
d1002 (ts, current, phase) VALUES
('2021-07-13 14:06:34.255', 10.27, 0.31);
6. 插入来自文件的数据记录
除了使用 VALUES 关键字插入一行或多行数据外,也可以把要写入的数据放在 CSV 文件中(英文逗号分隔、时间戳和字符串类型的值需要用英文单引号括住)供 SQL 指令读取。其中 CSV 文件无需表头
/tmp/csvfile.csv
'2021-07-13 14:07:34.630', 10.2, 219, 0.32
'2021-07-13 14:07:35.779', 10.15, 217, 0.33
sql
INSERT INTO d1001 FILE '/tmp/csvfile.csv';
7. 通过超级表插入
表名通过tbname列指定
INSERT INTO meters(tbname, location, groupId, ts, current, voltage, phase) values
('d31001', 'California.SanFrancisco', 2, '2021-07-13 14:06:34.630', 10.2, 219, 0.32)
('d31001', 'California.SanFrancisco', 2, '2021-07-13 14:06:35.779', 10.15, 217, 0.33)
('d31002', NULL, 2, '2021-07-13 14:06:34.255', 10.15, 217, 0.33)
5. 查询
1. 查询方式
1. 原生方式
from datetime import datetime
import taos
host = "81.70.168.242"
user = "root"
password = "taosdata"
database = "test"
port = 6030
config = "/etc/taos"
timezone = "Asia/Shanghai"
class TDEngine(object):
conn = None
def __init__(self):
self.connect()
def connect(self):
try:
self.conn = taos.connect(
host=host,
user=user,
password=password,
database=database,
port=port,
config=config,
timezone=timezone,
)
except taos.Error as e:
print("连接出错", e)
print("exception class: ", e.__class__.__name__)
print("error number:", e.errno)
print("error message:", e.msg)
self.close()
except BaseException as other:
print("exception occur")
print(other)
self.close()
def query(self, sql):
result = self.conn.query(sql)
fields = result.fields
field_list = [field.get("name") for field in fields]
row_data = result.fetch_all()
data = [dict(zip(field_list, row)) for row in row_data]
return data
def close(self):
if self.conn:
self.conn.close()
td = TDEngine()
print(td.query("SELECT * from meters LIMIT 10"))
2. ws 方式
import json
import time
from datetime import datetime
import taosws
from taosws import TaosField
dsn = "taosws://root:taosdata@81.70.168.242:6041"
conn = taosws.connect(dsn)
db = "power"
# 创建库
conn.execute(f"DROP DATABASE IF EXISTS {db}")
conn.execute(f"CREATE DATABASE {db}")
# 使用库
conn.execute(f"USE {db}")
# 创建超级表
conn.execute(
"CREATE TABLE `meters` (`ts` TIMESTAMP, `current` FLOAT, `voltage` INT, `phase` FLOAT) TAGS (`groupid` INT, `location` BINARY(16))"
)
# 创建表
conn.execute("CREATE TABLE `d1001` USING `meters` TAGS(0, 'Los Angles') `d1002` USING `meters` TAGS(0, 'Los Angles') `d1003` USING `meters` TAGS(0, 'Los Angles') `d1004` USING `meters` TAGS(0, 'Los Angles')")
# 批量写入数据
# for i in range(1,11):
# time.sleep(0.5)
# time_str = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
# a = 10.40000 + i / 10
# b = 220 + i
# c = 0.4100 + i / 10
# sql = f"""
# INSERT INTO
# power.d1001 USING power.meters TAGS(1, 2) VALUES ('{time_str}', {a}, {b}, {c})"""
# inserted = conn.execute(sql)
# print(inserted)
# 查询语句
result = conn.query("SELECT ts, current, voltage, phase FROM d1001")
# result = conn.query("SELECT ts, current, voltage, phase FROM d1001 WHERE ts > '2024-08-11 15:20:39'")
field_list = ["ts", "current", "voltage", "phase"]
data = [dict(zip(field_list, row)) for row in result]
print(data)
conn.close()
2. 单表查询
TDengine 采用 SQL 作为查询语言。应用程序可以通过 REST API 或连接器发送 SQL 语句,用户还可以通过 TDengine 命令行工具 taos 手动执行 SQL 即席查询(Ad-Hoc Query)。TDengine 支持如下查询功能:
1. 单列、多列数据查询
2 标签和数值的多种过滤条件:>, <, =, <>, like 等
3. 聚合结果的分组(Group by)、排序(Order by)、约束输出(Limit/Offset)
4. 时间窗口(Interval)、会话窗口(Session)和状态窗口(State_window)等窗口切分聚合查询
5. 数值列及聚合结果的四则运算
6. 时间戳对齐的连接查询(Join Query: 隐式连接)操作
7. 多种聚合/计算函数: count, max, min,avg,sum,twa,stddev,leastsquares,top,bottom,first,last,percentile, apercentile, last_row, spread, diff 等
从表 d1001 中查询出 voltage > 215 的记录,按时间降序排列,仅仅输出 2 条。
select * from d1001 where voltage > 215 order by ts desc limit 2;
3. 函数查询
1. ABS()
指定字段的绝对值
ABS(expr)
功能说明:获得指定字段的绝对值。
返回结果类型:与指定字段的原始数据类型一致。
适用数据类型:数值类型。
嵌套子查询支持:适用于内层查询和外层查询。
适用于: 表和超级表。
使用说明:只能与普通列,选择(Selection)、投影(Projection)函数一起使用,不能与聚合(Aggregation)函数一起使用
2. ACOS()
反余弦
ACOS(expr)
功能说明:获得指定字段的反余弦结果。
返回结果类型:DOUBLE。
适用数据类型:数值类型。
嵌套子查询支持:适用于内层查询和外层查询。
适用于: 表和超级表。
使用说明:只能与普通列,选择(Selection)、投影(Projection)函数一起使用,不能与聚合(Aggregation)函数一起使用。
4. 特色查询
1. 数据切分
当需要按一定的维度对数据进行切分然后在切分出的数据空间内再进行一系列的计算时使用数据切分子句,part_list 可以是任意的标量表达式,包括列、常量、标量函数和它们的组合。
PARTITION BY part_list
**示例: **
将数据按标签 location 进行分组,取每个分组内的电压平均值:
select location, avg(voltage) from meters partition by location
2. 窗口切分
window_clause: {
SESSION(ts_col, tol_val)
| STATE_WINDOW(col)
| INTERVAL(interval_val [, interval_offset]) [SLIDING (sliding_val)] [FILL(fill_mod_and_val)]
| EVENT_WINDOW START WITH start_trigger_condition END WITH end_trigger_condition
| COUNT_WINDOW(count_val[, sliding_val])
}
interval_val 和 sliding_val 都表示时间段,interval_offset 表示窗口偏移量,interval_offset 必须小于 interval_val
- INTERVAL(1s, 500a) SLIDING(1s), 自带时间单位的形式,其中的时间单位是单字符表示, 分别为: a (毫秒), b (纳秒), d (天), h (小时), m (分钟), n (月), s (秒), u (微妙), w (周), y (年).
- INTERVAL(1000, 500) SLIDING(1000), 不带时间单位的形式,将使用查询库的时间精度作为默认时间单位,当存在多个库时默认采用精度更高的库.
- INTERVAL('1s', '500a') SLIDING('1s'), 自带时间单位的字符串形式,字符串内部不能有任何空格等其它字符.
3. 时间窗口
**示例: **
SELECT * FROM temp_tb_1 INTERVAL(1m);
**注意: **
- 聚合时间段的窗口宽度由关键词 INTERVAL 指定,最短时间间隔 10 毫秒(10a);并且支持偏移 offset(偏移必须小于间隔),也即时间窗口划分与“UTC 时刻 0”相比的偏移量。SLIDING 语句用于指定聚合时间段的前向增量,也即每次窗口向前滑动的时长。
- 使用 INTERVAL 语句时,除非极特殊的情况,都要求把客户端和服务端的 taos.cfg 配置文件中的 timezone 参数配置为相同的取值,以避免时间处理函数频繁进行跨时区转换而导致的严重性能影响。
- 返回的结果中时间序列严格单调递增。
4. 状态窗口
使用整数(布尔值)或字符串来标识产生记录时候设备的状态量。产生的记录如果具有相同的状态量数值则归属于同一个状态窗口,数值改变后该窗口关闭
如下图所示,根据状态量确定的状态窗口分别是[2019-04-28 14:22:07,2019-04-28 14:22:10]和[2019-04-28 14:22:11,2019-04-28 14:22:12]两个。
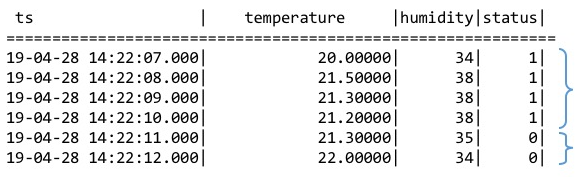
使用 STATE_WINDOW 来确定状态窗口划分的列。
SELECT COUNT(*), FIRST(ts), status FROM temp_tb_1 STATE_WINDOW(status);
仅关心 status 为 2 时的状态窗口的信息。
SELECT * FROM (SELECT COUNT(*) AS cnt, FIRST(ts) AS fst, status FROM temp_tb_1 STATE_WINDOW(status)) t WHERE status = 2;
支持将 CASE 表达式用在状态量,可以表达某个状态的开始是由满足某个条件而触发,这个状态的结束是由另外一个条件满足而触发的语义。例如,智能电表的电压正常范围是 205V 到 235V,那么可以通过监控电压来判断电路是否正常。
SELECT tbname, _wstart, CASE WHEN voltage >= 205 and voltage <= 235 THEN 1 ELSE 0 END status FROM meters PARTITION BY tbname STATE_WINDOW(CASE WHEN voltage >= 205 and voltage <= 235 THEN 1 ELSE 0 END);
5. 会话窗口
5. 多表聚合查询
物联网场景中,往往同一个类型的数据采集点有多个。TDengine 采用超级表(STable)的概念来描述某一个类型的数据采集点,一张普通的表来描述一个具体的数据采集点。同时 TDengine 使用标签来描述数据采集点的静态属性,一个具体的数据采集点有具体的标签值。通过指定标签的过滤条件,TDengine 提供了一高效的方法将超级表(某一类型的数据采集点)所属的子表进行聚合查询。对普通表的聚合函数以及绝大部分操作都适用于超级表,语法完全一样。
查找加利福尼亚州所有智能电表采集的电压平均值,并按照 location 分组。
select avg(voltage),location from meters group by location;
avg(voltage) | location |
=======================================================
208.615713702623907 | California.SantaClara |
208.599407205452763 | California.SanFrancisco |
208.613291080797495 | California.SanJose |
208.619345330739293 | California.LosAngles |
208.609964263959398 | California.SanDiego |
208.601105432595574 | California.Sunnyvale |
208.598370926829261 | California.PaloAlto |
208.613153564154800 | California.Cupertino |
208.608173223480946 | California.MountainView |
208.616491848906549 | California.Campbell |
Query OK, 10 row(s) in set (0.642952s)
在 TDengine CLI, 查找 groupId 为 2 的所有智能电表的记录条数,电流的最大值。
taos> SELECT count(*), max(current) FROM meters where groupId = 2;
cunt(*) | max(current) |
==================================
5 | 13.4 |
Query OK, 1 row(s) in set (0.002136s)
6. 降采样查询(每10s求和)
物联网场景里,经常需要通过降采样(down sampling)将采集的数据按时间段进行聚合。TDengine 提供了一个简便的关键词 interval 让按照时间窗口的查询操作变得极为简单。
将智能电表 d1001 采集的电流值每 10 秒钟求和
-- 必须为 _wstart
SELECT _wstart, sum(current) FROM d1001 INTERVAL(10s);
降采样操作也适用于超级表,比如:将加利福尼亚州所有智能电表采集的电流值每秒钟求和
SELECT _wstart, SUM(current) FROM meters where location like "California%" INTERVAL(1s);
降采样操作也支持时间偏移,比如:将所有智能电表采集的电流值每秒钟求和,但要求每个时间窗口从 500 毫秒开始
SELECT _wstart, SUM(current) FROM meters INTERVAL(1s,500a);
物联网场景里,每个数据采集点采集数据的时间是难同步的,但很多分析算法(比如 FFT)需要把采集的数据严格按照时间等间隔的对齐,在很多系统里,需要应用自己写程序来处理,但使用 TDengine 的降采样操作就轻松解决。
如果一个时间间隔里,没有采集的数据,TDengine 还提供插值计算的功能。
6. 索引
1. 创建
默认在第一列 TAG 建立索引, 并且无法修改
CREATE INDEX index_name ON tbl_name (tagColName)
2. 删除
DROP INDEX index_name
3. 查看
1. 查看系统中已经存在的索引
SELECT * FROM information_schema.INS_INDEXES
2. 查看指定表的索引
SHOW INDEXES FROM tbl_name [FROM db_name];
SHOW INDEXES FROM [db_name.]tbl_name;
4. 说明
- 索引使用得当能够提升数据过滤的效率,目前支持的过滤算子有
=,>,>=,<,<=。如果查询过滤条件中使用了这些算子,则索引能够明显提升查询效率。但如果查询过滤条件中使用的是其它算子,则索引起不到作用,查询效率没有变化。未来会逐步添加更多的算子。 - 针对一个 tag 列只能建立一个索引,如果重复创建索引则会报错。
- 每次只能针对一个 tag 列建立一个索引,不能同时对多个 tag 建立索引。
- 整个系统中不管是哪种类型的索引,其名称必须唯一。
- 对索引个数没有限制,但每增加一个索引都会导致系统中的元数据增加,过多的索引会降低元数据存取的效率从而降低整个系统的性能。所以请尽量避免添加不必要的索引。
- 不支持对普通和子表建立索引。
- 如果某个 tag 列的唯一值较少时,不建议对其建立索引,这种情况下收效甚微。
- 新建立的超级表,会给第一列tag,随机生成一个indexNewName, 生成规则是:tag0的name + 23个byte, 在系统表可以查,也可以按需要drop,行为和其他列tag 的索引一样
7. 流式计算
在时序数据的处理中,经常要对原始数据进行清洗、预处理,再使用时序数据库进行长久的储存。在传统的时序数据解决方案中,常常需要部署 Kafka、Flink 等流处理系统。而流处理系统的复杂性,带来了高昂的开发与运维成本。
TDengine 3.0 的流式计算引擎提供了实时处理写入的数据流的能力,使用 SQL 定义实时流变换,当数据被写入流的源表后,数据会被以定义的方式自动处理,并根据定义的触发模式向目的表推送结果。它提供了替代复杂流处理系统的轻量级解决方案,并能够在高吞吐的数据写入的情况下,提供毫秒级的计算结果延迟。
流式计算可以包含数据过滤,标量函数计算(含UDF),以及窗口聚合(支持滑动窗口、会话窗口与状态窗口),可以以超级表、子表、普通表为源表,写入到目的超级表。在创建流时,目的超级表将被自动创建,随后新插入的数据会被流定义的方式处理并写入其中,通过 partition by 子句,可以以表名或标签划分 partition,不同的 partition 将写入到目的超级表的不同子表。
TDengine 的流式计算能够支持分布在多个 vnode 中的超级表聚合;还能够处理乱序数据的写入:它提供了 watermark 机制以度量容忍数据乱序的程度,并提供了 ignore expired 配置项以决定乱序数据的处理策略——丢弃或者重新计算。
流式计算创建语法
CREATE STREAM [IF NOT EXISTS] stream_name [stream_options] INTO stb_name AS subquery
stream_options: {
TRIGGER [AT_ONCE | WINDOW_CLOSE | MAX_DELAY time]
WATERMARK time
IGNORE EXPIRED [0 | 1]
}
示例一
企业电表的数据经常都是成百上千亿条的,那么想要将这些分散、凌乱的数据清洗或转换都需要比较长的时间,很难做到高效性和实时性,以下例子中,通过流计算可以将电表电压大于 220V 的数据清洗掉,然后以 5 秒为窗口整合并计算出每个窗口中电流的最大值,最后将结果输出到指定的数据表中。
创建 DB 和原始数据表
DROP DATABASE IF EXISTS power;
CREATE DATABASE power;
USE power;
CREATE STABLE meters (ts timestamp, current float, voltage int, phase float) TAGS (location binary(64), groupId int);
CREATE TABLE d1001 USING meters TAGS ("California.SanFrancisco", 2);
CREATE TABLE d1002 USING meters TAGS ("California.SanFrancisco", 3);
CREATE TABLE d1003 USING meters TAGS ("California.LosAngeles", 2);
CREATE TABLE d1004 USING meters TAGS ("California.LosAngeles", 3);
创建流
create stream current_stream trigger at_once into current_stream_output_stb as select _wstart as wstart, _wend as wend, max(current) as max_current from meters where voltage <= 220 interval (5s);
写入数据
insert into d1001 values("2018-10-03 14:38:05.000", 10.30000, 219, 0.31000);
insert into d1001 values("2018-10-03 14:38:15.000", 12.60000, 218, 0.33000);
insert into d1001 values("2018-10-03 14:38:16.800", 12.30000, 221, 0.31000);
insert into d1002 values("2018-10-03 14:38:16.650", 10.30000, 218, 0.25000);
insert into d1003 values("2018-10-03 14:38:05.500", 11.80000, 221, 0.28000);
insert into d1003 values("2018-10-03 14:38:16.600", 13.40000, 223, 0.29000);
insert into d1004 values("2018-10-03 14:38:05.000", 10.80000, 223, 0.29000);
insert into d1004 values("2018-10-03 14:38:06.500", 11.50000, 221, 0.35000);
查询以观察结果
select wstart, wend, max_current from current_stream_output_stb;
wstart | wend | max_current |
===========================================================================
2018-10-03 14:38:05.000 | 2018-10-03 14:38:10.000 | 10.30000 |
2018-10-03 14:38:15.000 | 2018-10-03 14:38:20.000 | 12.60000 |
Query OK, 2 rows in database (0.018762s)
示例二
依然以示例一中的数据为基础,我们已经采集到了每个智能电表的电流和电压数据,现在需要求出有功功率和无功功率,并将地域和电表名以符号 "." 拼接,然后以电表名称分组输出到新的数据表中。
创建 DB 和原始数据表
DROP DATABASE IF EXISTS power;
CREATE DATABASE power;
USE power;
CREATE STABLE meters (ts timestamp, current float, voltage int, phase float) TAGS (location binary(64), groupId int);
CREATE TABLE d1001 USING meters TAGS ("California.SanFrancisco", 2);
CREATE TABLE d1002 USING meters TAGS ("California.SanFrancisco", 3);
CREATE TABLE d1003 USING meters TAGS ("California.LosAngeles", 2);
CREATE TABLE d1004 USING meters TAGS ("California.LosAngeles", 3);
创建流
create stream power_stream trigger at_once into power_stream_output_stb as select ts, concat_ws(".", location, tbname) as meter_location, current*voltage*cos(phase) as active_power, current*voltage*sin(phase) as reactive_power from meters partition by tbname;
写入数据
insert into d1001 values("2018-10-03 14:38:05.000", 10.30000, 219, 0.31000);
insert into d1001 values("2018-10-03 14:38:15.000", 12.60000, 218, 0.33000);
insert into d1001 values("2018-10-03 14:38:16.800", 12.30000, 221, 0.31000);
insert into d1002 values("2018-10-03 14:38:16.650", 10.30000, 218, 0.25000);
insert into d1003 values("2018-10-03 14:38:05.500", 11.80000, 221, 0.28000);
insert into d1003 values("2018-10-03 14:38:16.600", 13.40000, 223, 0.29000);
insert into d1004 values("2018-10-03 14:38:05.000", 10.80000, 223, 0.29000);
insert into d1004 values("2018-10-03 14:38:06.500", 11.50000, 221, 0.35000);
查询以观察结果
select ts, meter_location, active_power, reactive_power from power_stream_output_stb;
ts | meter_location | active_power | reactive_power |
===================================================================================================================
2018-10-03 14:38:05.500 | California.LosAngeles.d1003 | 2506.240411678508281 | 720.680274962222370 |
2018-10-03 14:38:16.600 | California.LosAngeles.d1003 | 2863.424274421749033 | 854.482390838683273 |
2018-10-03 14:38:05.000 | California.SanFrancisco.d1001 | 2148.178871730459832 | 688.120784089717517 |
2018-10-03 14:38:15.000 | California.SanFrancisco.d1001 | 2598.589176205376134 | 890.081451417929088 |
2018-10-03 14:38:16.800 | California.SanFrancisco.d1001 | 2588.728381186420393 | 829.240910475176975 |
2018-10-03 14:38:16.650 | California.SanFrancisco.d1002 | 2175.595991996653993 | 555.520860397212005 |
2018-10-03 14:38:05.000 | California.LosAngeles.d1004 | 2307.834596289459569 | 688.687331847069345 |
2018-10-03 14:38:06.500 | California.LosAngeles.d1004 | 2387.415754896007911 | 871.474763417922873 |
Query OK, 8 row(s) in set (0.002986s)
8. 缓存
1. 写缓存
TDengine 采用时间驱动缓存管理策略(First-In-First-Out,FIFO),又称为写驱动的缓存管理机制。这种策略有别于读驱动的数据缓存模式(Least-Recent-Used,LRU),直接将最近写入的数据保存在系统的缓存中。当缓存达到临界值的时候,将最早的数据批量写入磁盘。一般意义上来说,对于物联网数据的使用,用户最为关心最近产生的数据,即当前状态。TDengine 充分利用了这一特性,将最近到达的(当前状态)数据保存在缓存中。
每个 vnode 的写入缓存大小在创建数据库时决定,创建数据库时的两个关键参数 vgroups 和 buffer 分别决定了该数据库中的数据由多少个 vgroup 处理,以及向其中的每个 vnode 分配多少写入缓存。buffer 的单位是MB。
create database db0 vgroups 100 buffer 16
理论上缓存越大越好,但超过一定阈值后再增加缓存对写入性能提升并无帮助,一般情况下使用默认值即可。
2. 读缓存
在创建数据库时可以选择是否缓存该数据库中每个子表的最新数据。由参数 cachemodel 设置,分为四种情况:
- none: 不缓存
- last_row: 缓存子表最近一行数据,这将显著改善 last_row 函数的性能
- last_value: 缓存子表每一列最近的非 NULL 值,这将显著改善无特殊影响(比如 WHERE, ORDER BY, GROUP BY, INTERVAL)时的 last 函数的性能
- both: 同时缓存最近的行和列,即等同于上述 cachemodel 值为 last_row 和 last_value 的行为同时生效
3. 元数据缓存
为了更高效地处理查询和写入,每个 vnode 都会缓存自己曾经获取到的元数据。元数据缓存由创建数据库时的两个参数 pages 和 pagesize 决定。pagesize 的单位是 kb。
create database db0 pages 128 pagesize 16
上述语句会为数据库 db0 的每个 vnode 创建 128 个 page,每个 page 16kb 的元数据缓存。
4. 文件系统缓存
TDengine 利用 WAL 技术来提供基本的数据可靠性。写入 WAL 本质上是以顺序追加的方式写入磁盘文件。此时文件系统缓存在写入性能中也会扮演关键角色。在创建数据库时可以利用 wal 参数来选择性能优先或者可靠性优先。
- 1: 写 WAL 但不执行 fsync ,新写入 WAL 的数据保存在文件系统缓存中但并未写入磁盘,这种方式性能优先
- 2: 写 WAL 且执行 fsync,新写入 WAL 的数据被立即同步到磁盘上,可靠性更高
5. 客户端缓存
为了进一步提升整个系统的处理效率,除了以上提到的服务端缓存技术之外,在 TDengine 的所有客户端都要调用的核心库 libtaos.so (也称为 taosc )中也充分利用了缓存技术。在 taosc 中会缓存所访问过的各个数据库、超级表以及子表的元数据,集群的拓扑结构等关键元数据。
当有多个客户端同时访问 TDengine 集群,且其中一个客户端对某些元数据进行了修改的情况下,有可能会出现其它客户端所缓存的元数据不同步或失效的情况,此时需要在客户端执行 "reset query cache" 以让整个缓存失效从而强制重新拉取最新的元数据重新建立缓存。
9. 数据订阅
为了帮助应用实时获取写入 TDengine 的数据,或者以事件到达顺序处理数据,TDengine 提供了类似消息队列产品的数据订阅、消费接口。这样在很多场景下,采用 TDengine 的时序数据处理系统不再需要集成消息队列产品,比如 kafka, 从而简化系统设计的复杂度,降低运营维护成本。
与 kafka 一样,你需要定义 topic, 但 TDengine 的 topic 是基于一个已经存在的超级表、子表或普通表的查询条件,即一个 SELECT 语句。你可以使用 SQL 对标签、表名、列、表达式等条件进行过滤,以及对数据进行标量函数与 UDF 计算(不包括数据聚合)。与其他消息队列软件相比,这是 TDengine 数据订阅功能的最大的优势,它提供了更大的灵活性,数据的颗粒度可以由应用随时调整,而且数据的过滤与预处理交给 TDengine,而不是应用完成,有效的减少传输的数据量与应用的复杂度。
消费者订阅 topic 后,可以实时获得最新的数据。多个消费者可以组成一个消费者组 (consumer group), 一个消费者组里的多个消费者共享消费进度,便于多线程、分布式地消费数据,提高消费速度。但不同消费者组中的消费者即使消费同一个 topic, 并不共享消费进度。一个消费者可以订阅多个 topic。如果订阅的是超级表,数据可能会分布在多个不同的 vnode 上,也就是多个 shard 上,这样一个消费组里有多个消费者可以提高消费效率。TDengine 的消息队列提供了消息的 ACK 机制,在宕机、重启等复杂环境下确保 at least once 消费。
为了实现上述功能,TDengine 会为 WAL (Write-Ahead-Log) 文件自动创建索引以支持快速随机访问,并提供了灵活可配置的文件切换与保留机制:用户可以按需指定 WAL 文件保留的时间以及大小(详见 create database 语句)。通过以上方式将 WAL 改造成了一个保留事件到达顺序的、可持久化的存储引擎(但由于 TSDB 具有远比 WAL 更高的压缩率,我们不推荐保留太长时间,一般来说,不超过几天)。 对于以 topic 形式创建的查询,TDengine 将对接 WAL 而不是 TSDB 作为其存储引擎。在消费时,TDengine 根据当前消费进度从 WAL 直接读取数据,并使用统一的查询引擎实现过滤、变换等操作,将数据推送给消费者。
本文档不对消息队列本身的基础知识做介绍,如果需要了解,请自行搜索。
说明(以c接口为例):
- 一个消费组消费同一个topic下的所有数据,不同消费组之间相互独立;
- 一个消费组消费同一个topic所有的vgroup,消费组可由多个消费者组成,但一个vgroup仅被一个消费者消费,如果消费者数量超过了vgroup数量,多余的消费者不消费数据;
- 在服务端每个vgroup仅保存一个offset,每个vgroup的offset是单调递增的,但不一定连续。各个vgroup的offset之间没有关联;
- 每次poll服务端会返回一个结果block,该block属于一个vgroup,可能包含多个wal版本的数据,可以通过 tmq_get_vgroup_offset 接口获得是该block第一条记录的offset;
- 一个消费组如果从未commit过offset,当其成员消费者重启重新拉取数据时,均从参数auto.offset.reset设定值开始消费;在一个消费者生命周期中,客户端本地记录了最近一次拉取数据的offset,不会拉取重复数据;
- 消费者如果异常终止(没有调用tmq_close),需等约12秒后触发其所属消费组rebalance,该消费者在服务端状态变为LOST,约1天后该消费者自动被删除;正常退出,退出后就会删除消费者;新增消费者,需等约2秒触发rebalance,该消费者在服务端状态变为ready;
- 消费组rebalance会对该组所有ready状态的消费者成员重新进行vgroup分配,消费者仅能对自己负责的vgroup进行assignment/seek/commit/poll操作;
- 消费者可利用 tmq_position 获得当前消费的offset,并seek到指定offset,重新消费;
- seek将position指向指定offset,不执行commit操作,一旦seek成功,可poll拉取指定offset及以后的数据;
- seek 操作之前须调用 tmq_get_topic_assignment 接口获取该consumer的vgroup ID和offset范围。seek 操作会检测vgroup ID 和 offset是否合法,如非法将报错;
- position是获取当前的消费位置,是下次要取的位置,不是当前消费到的位置
- commit是提交消费位置,不带参数的话,是提交当前消费位置(下次要取的位置,不是当前消费到的位置),带参数的话,是提交参数里的位置(也即下次退出重启后要取的位置)
- seek是设置consumer消费位置,seek到哪,position就返回哪,都是下次要取的位置
- seek不会影响commit,commit不影响seek,相互独立,两个是不同的概念
- begin接口为wal 第一条数据的offset,end 接口为wal 最后一条数据的offset + 1
- tmq_get_vgroup_offset接口获取的是记录所在结果block块里的第一条数据的offset,当seek至该offset时,将消费到这个block里的全部数据。参见第四点;
- 由于存在 WAL 过期删除机制,即使seek 操作成功,poll数据时有可能offset已失效。如果poll 的offset 小于 WAL 最小版本号,将会从WAL最小版本号消费;
- 数据订阅是从 WAL 消费数据,如果一些 WAL 文件被基于 WAL 保留策略删除,则已经删除的 WAL 文件中的数据就无法再消费到。需要根据业务需要在创建数据库时合理设置
WAL_RETENTION_PERIOD或WAL_RETENTION_SIZE,并确保应用及时消费数据,这样才不会产生数据丢失的现象。数据订阅的行为与 Kafka 等广泛使用的消息队列类产品的行为相似;
主要数据结构和 API
class Consumer:
def subscribe(self, topics):
pass
def unsubscribe(self):
pass
def poll(self, timeout: float = 1.0):
pass
def assignment(self):
pass
def seek(self, partition):
pass
def close(self):
pass
def commit(self, message):
pass
准备工作
写入数据
首先完成建库、建一张超级表和多张子表操作,然后就可以写入数据了,比如:
DROP DATABASE IF EXISTS tmqdb;
CREATE DATABASE tmqdb WAL_RETENTION_PERIOD 3600;
CREATE TABLE tmqdb.stb (ts TIMESTAMP, c1 INT, c2 FLOAT, c3 VARCHAR(16)) TAGS(t1 INT, t3 VARCHAR(16));
CREATE TABLE tmqdb.ctb0 USING tmqdb.stb TAGS(0, "subtable0");
CREATE TABLE tmqdb.ctb1 USING tmqdb.stb TAGS(1, "subtable1");
INSERT INTO tmqdb.ctb0 VALUES(now, 0, 0, 'a0')(now+1s, 0, 0, 'a00');
INSERT INTO tmqdb.ctb1 VALUES(now, 1, 1, 'a1')(now+1s, 11, 11, 'a11');
创建 topic
TDengine 使用 SQL 创建一个 topic:
CREATE TOPIC topic_name AS SELECT ts, c1, c2, c3 FROM tmqdb.stb WHERE c1 > 1;
- topic创建个数有上限,通过参数 tmqMaxTopicNum 控制,默认 20 个
TMQ 支持多种订阅类型:
列订阅
语法:
CREATE TOPIC topic_name as subquery
通过 SELECT 语句订阅(包括 SELECT *,或 SELECT ts, c1 等指定列订阅,可以带条件过滤、标量函数计算,但不支持聚合函数、不支持时间窗口聚合)。需要注意的是:
- 该类型 TOPIC 一旦创建则订阅数据的结构确定。
- 被订阅或用于计算的列或标签不可被删除(
ALTER table DROP)、修改(ALTER table MODIFY)。 - 若发生表结构变更,新增的列不出现在结果中。
超级表订阅
语法:
CREATE TOPIC topic_name [with meta] AS STABLE stb_name [where_condition]
与 SELECT * from stbName 订阅的区别是:
- 不会限制用户的表结构变更。
- 返回的是非结构化的数据:返回数据的结构会随之超级表的表结构变化而变化。
- with meta 参数可选,选择时将返回创建超级表,子表等语句,主要用于taosx做超级表迁移
- where_condition 参数可选,选择时将用来过滤符合条件的子表,订阅这些子表。where 条件里不能有普通列,只能是tag或tbname,where条件里可以用函数,用来过滤tag,但是不能是聚合函数,因为子表tag值无法做聚合。也可以是常量表达式,比如 2 > 1(订阅全部子表),或者 false(订阅0个子表)
- 返回数据不包含标签。
数据库订阅
语法:
CREATE TOPIC topic_name [with meta] AS DATABASE db_name;
通过该语句可创建一个包含数据库所有表数据的订阅
- with meta 参数可选,选择时将返回创建数据库里所有超级表,子表的语句,主要用于taosx做数据库迁移
创建消费者 consumer
消费者需要通过一系列配置选项创建,基础配置项如下表所示:
| 参数名称 | 类型 | 参数说明 | 备注 |
|---|---|---|---|
td.connect.ip |
string | 服务端的 IP 地址 | |
td.connect.user |
string | 用户名 | |
td.connect.pass |
string | 密码 | |
td.connect.port |
integer | 服务端的端口号 | |
group.id |
string | 消费组 ID,同一消费组共享消费进度 | 必填项。最大长度:192。 每个topic最多可建立100个 consumer group |
client.id |
string | 客户端 ID | 最大长度:192。 |
auto.offset.reset |
enum | 消费组订阅的初始位置 | earliest: default;从头开始订阅; latest: 仅从最新数据开始订阅; none: 没有提交的 offset 无法订阅 |
enable.auto.commit |
boolean | 是否启用消费位点自动提交,true: 自动提交,客户端应用无需commit;false:客户端应用需要自行commit | 默认值为 true |
auto.commit.interval.ms |
integer | 消费记录自动提交消费位点时间间隔,单位为毫秒 | 默认值为 5000 |
msg.with.table.name |
boolean | 是否允许从消息中解析表名, 不适用于列订阅(列订阅时可将 tbname 作为列写入 subquery 语句) | 默认关闭 |
对于不同编程语言,其设置方式如下:
Python 语言下引入 taos 库的 Consumer 类,创建一个 Consumer 示例:
from taos.tmq import Consumer
# Syntax: `consumer = Consumer(configs)`
#
# Example:
consumer = Consumer({"group.id": "local", "td.connect.ip": "127.0.0.1"})
上述配置中包括 consumer group ID,如果多个 consumer 指定的 consumer group ID 一样,则自动形成一个 consumer group,共享消费进度。
订阅 topics
一个 consumer 支持同时订阅多个 topic。
consumer.subscribe(['topic1', 'topic2'])
消费
以下代码展示了不同语言下如何对 TMQ 消息进行消费。
while True:
res = consumer.poll(100)
if not res:
continue
err = res.error()
if err is not None:
raise err
val = res.value()
for block in val:
print(block.fetchall())
结束消费
消费结束后,应当取消订阅。
# 取消订阅
consumer.unsubscribe()
# 关闭消费
consumer.close()
删除 topic
如果不再需要订阅数据,可以删除 topic,需要注意:只有当前未在订阅中的 TOPIC 才能被删除。
/* 删除 topic */
DROP TOPIC topic_name;
状态查看
1、topics:查询已经创建的 topic
SHOW TOPICS;
2、consumers:查询 consumer 的状态及其订阅的 topic
SHOW CONSUMERS;
3、subscriptions:查询 consumer 与 vgroup 之间的分配关系
SHOW SUBSCRIPTIONS;
示例代码
https://docs.taosdata.com/develop/tmq/
10. 优化建议
- 要提高写入效率,需要批量写入。一般来说一批写入的记录条数越多,插入效率就越高。但一条记录不能超过 48KB,一条 SQL 语句总长度不能超过 1MB。
- Dengine 支持多线程同时写入,要进一步提高写入速度,一个客户端需要打开多个同时写。但线程数达到一定数量后,无法再提高,甚至还会下降,因为线程频繁切换,会带来额外开销,合适的线程数量与服务端的处理能力,服务端的具体配置,数据库的参数,数据定义的 Schema,写入数据的 Batch Size 等很多因素相关。一般来说,服务端和客户端处理能力越强,所能支持的并发写入的线程可以越多;数据库配置时的 vgroups 参数值越多(但仍然要在服务端的处理能力以内)则所能支持的并发写入越多;数据定义的 Schema 越简单,所能支持的并发写入越多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号