Elasticsearch --- 环境搭建
1. ES 安装
1. 官方地址
# 下载版本: 7.8.0
https://www.elastic.co/cn/
# 下载地址
https://www.elastic.co/cn/downloads/?elektra=home&storm=hero
2. 目录结构
|--- bin # 启动文件
|--- config # 配置文件
|--- log4j2 # 日志配置文件
|--- jvm.options # jvm配置文件 ,修改该配置文件中的对于内存的配置:Xms256m和Xmx256m
|--- es.yml # es的配置文件 ,默认端口为9200,跨域问题
|--- lib # 相关jar包
|--- models # 功能模块
|--- plugins # 插件
3. 启动
# 启动文件
elasticsearch.bat
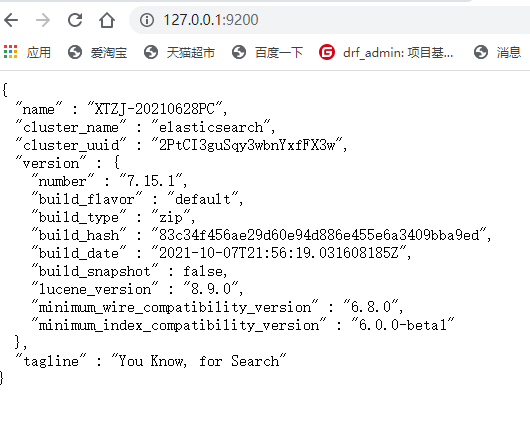
启动结果
{
"name":"" # 主机名
"cluster_name": # 集群名,默认集群开启,一个es也是一个集群
"cluster_uuid": # 在集群中的唯一标识
"version":{
"number":
"build_flavor":
"build_type":
"build_hash":
"build_date":
"build_snapshot":
"lucene_version":
"mininum_wire_compatibility_version":
"mininum_index_compatibility_version"
}
"tagline":"You Know, fro Search"
}
4. 运行端口
注意: 9300端口为ES 集群间组件的通信端口,9200端口为浏览器访问的http协议Restful端口
3.2 可视化插件安装
1. 环境下载
1. cnpm下载
http://npm.taobao.org;
2. cnpm安装
# 安装cnpm
npm install -g cnpm --registry=https://registry.npm.taobao.org
# 创建配置文件
cnpm init -y
# 查看帮助文档
cnpm help package.json
2. 可视化插件下载
https://github.com/mobz/elasticsearch-head
# 官网有下载步骤,默认端口9100
3. 解决跨域问题
elasticsearch.yml
http.cors.enabled:true
http.cors.allow-origin:"*"
重启es服务,并再次连接
3. Kibana可视化平台安装
# kibana版本要和ES版本一致
https://www.elastic.co/cn/downloads/?elektra=home&storm=hero
1. 解压
2. 启动
# 启动文件,默认端口5601
kibana.bat
3. 开发者工具
左边图标有一个扳手的图标
4. 汉化
kibana.yml
i18n.locale:"zh-CN"
重启kibana
4. IK分词器插件安装
分词:就是将一段中文或英文分成一个个的关键字,在搜索的时候会把自己的信息进行分词,会将索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每一个中文作为一个词,这显然不合逻辑,所以需要安装中文分词器IK来解决这个问题
IK提供了两个分词算法:ik_samrt和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分
1. 下载
# 下载完毕,键文件夹,放到ES的plugins文件夹中
https://github.com/medcl/elasticsearch-analysis-ik/releases
2. 重启ES
3. 查看是否安装成功
ES的启动界面会有加载IK的日志
# 命令行
elasticsearch-plugin
5. Kibana交互ES
# 可以使用kibana的开发者工具,和ES交互
# 选择分词算法
GET _analyze # get请求
{
"analyzer":"ik_smart", # 选择分词算法
"text": "美特斯邦威"
}
GET _analyze # get请求
{
"analyzer":"ik_max_word", # 选择分词算法
"text": "美特斯邦威"
}
# 可能ik分词器的字典中不存在我想要的分词,这样就需要自己手动添加了
6. IK分词器自定义分词
# ES的plugin下的ik分词器中的config目录中新建一个自定义分词字典(xxx.dic)
# ES的plugin下的ik分词器中的config目录中的IKAnalyzer.ofg.xml文件导入该dic
<entry key="ext_dict">xxx.dic</entry>
重启ES
7. 安装中的问题及解决方式
1. 打不开?
ElasticSearch 是使用java开发的,且7.8版本的ES 需要JDK 版本1.8以上,默认安装包带有jdk环境,如果系统配置JAVA_HOME,name使用
默认的JDK,如果没有配置使用自带的JDK,一般建议使用系统配置的JDK
2. 双击启动窗口闪退?
通过路径追踪错误,如果是"空间不足",请修改
config/jvm.options配置文件
# 设置JVM 初始内存为1G,此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存
# 设置JVM最大可用内存为1G
-Xmslg
-Xmxlg
python防脱发技巧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号