

参考学习:常用 backbone 之 HGNetv2_哔哩哔哩_bilibili
本文用于记录解析HGNetv2网络结构,加强学习记忆。
网络结构分析
从class HG_Block(nn.Module)这个类中前向传播函数可以看见主要运用的就是两个大的组件:
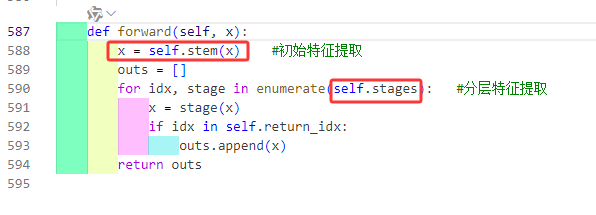
再查找这两大个组件:
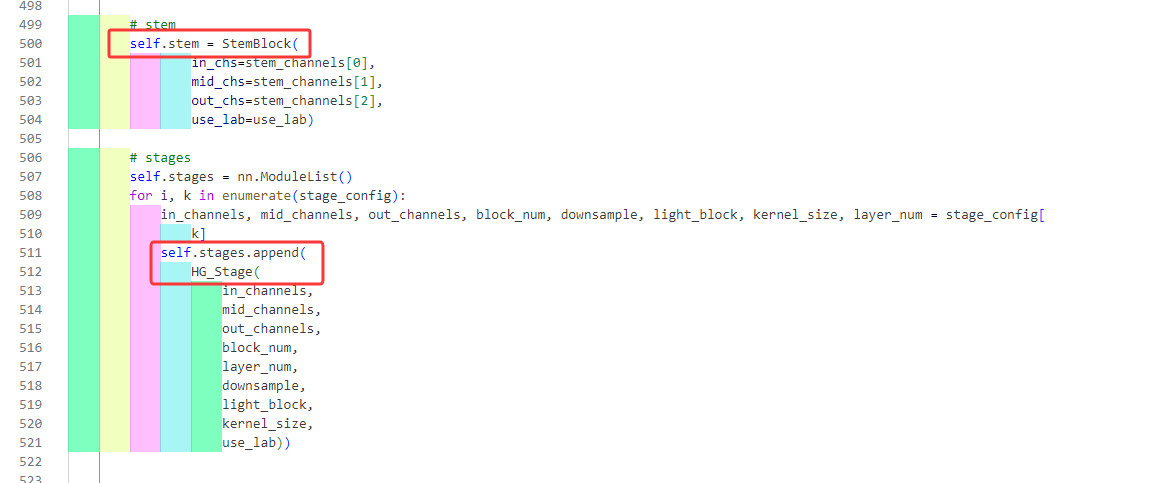
StemBlock:
也要从其前向传播函数入手分析

主要使用的是自定义的stemx这个东西,直接看这个东西就行了。
下面可以看见这个东西定义是依据ConvBNAct这个东西的。
那么接下来寻找解析ConvBNAct,这个类是一个基础组件,简单来讲就是一个非常常见的卷积组合,就是卷积,归一,激活。
ConvBNAct
class ConvBNAct(nn.Module):
def __init__(
self,
in_chs, # 输入通道数
out_chs, # 输出通道数
kernel_size, # 卷积核大小
stride=1, # 步长,默认为1
groups=1, # 分组卷积的组数,默认为1(标准卷积)
padding='', # 填充方式,支持'same'或自动计算
use_act=True, # 是否使用激活函数,默认为True
use_lab=False # 是否使用可学习仿射变换,默认为False
):
super().__init__()
self.use_act = use_act
self.use_lab = use_lab
"""
'same' 填充:通过ZeroPad2d在右侧和下侧各填充 1 个像素,确保输入和输出特征图尺寸相同(适用于奇数核)。
自动填充:根据卷积核大小自动计算填充量(kernel_size - 1) // 2,常用于保持特征图尺寸。
无偏置:bias=False,因为批归一化会消除偏置的影响。
"""
if padding == 'same':
self.conv = nn.Sequential(
nn.ZeroPad2d([0, 1, 0, 1]), # 右和下各填充1个像素
nn.Conv2d(
in_chs,
out_chs,
kernel_size,
stride,
groups=groups,
bias=False
)
)
else:
self.conv = nn.Conv2d(
in_chs,
out_chs,
kernel_size,
stride,
padding=(kernel_size - 1) // 2, # 自动计算填充,保持尺寸不变
groups=groups,
bias=False
)
#对卷积输出进行批归一化,加速训练并提高稳定性。
self.bn = nn.BatchNorm2d(out_chs)
if self.use_act:
self.act = nn.ReLU()
else:
self.act = nn.Identity() # 空操作,保持接口一致性
if self.use_act and self.use_lab: #LearnableAffineBlock是一个可学习的仿射变换层,仅当同时启用use_act和use_lab时才会添加。
self.lab = LearnableAffineBlock()
else:
self.lab = nn.Identity() # 空操作,保持接口一致性
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
x = self.lab(x)
return x
这个看一下前向传播函数就知道了,就是一个cver都熟知的简单组合,注意的一点就是还添加了一个可学习的仿射变换层(LearnableAffineBlock),下面看一下这个仿射变换层。
LearnableAffineBlock
#仿射变换相当于使用 y = ax + b (a = scale_value, b = bias_value)
class LearnableAffineBlock(nn.Module):
def __init__(
self,
scale_value=1.0,
bias_value=0.0
):
super().__init__()
self.scale = nn.Parameter(torch.tensor([scale_value]), requires_grad=True)
self.bias = nn.Parameter(torch.tensor([bias_value]), requires_grad=True)
def forward(self, x):
return self.scale * x + self.bias
感觉这玩意也有点像归一化的感觉,就是把值进行偏移,但是又是动态的,会对系数进行更新好像。
现在讲解了StemBlock中最基础的组件ConvBNAct,再回来剖析这个StemBlock这个类,先放出这个类的代码及其注释
class StemBlock(nn.Module):
# for HGNetv2
def __init__(self, in_chs, mid_chs, out_chs, use_lab=False):
super().__init__()
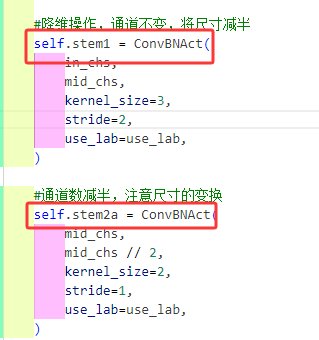
#降维操作,将尺寸减半
self.stem1 = ConvBNAct(
in_chs,
mid_chs,
kernel_size=3,
stride=2,
use_lab=use_lab,
)
#通道数减半,注意尺寸的变换
self.stem2a = ConvBNAct(
mid_chs,
mid_chs // 2,
kernel_size=2,
stride=1,
use_lab=use_lab,
)
#通道数增加一半,注意图像尺寸的变换
self.stem2b = ConvBNAct(
mid_chs // 2,
mid_chs,
kernel_size=2,
stride=1,
use_lab=use_lab,
)
#降维+下采样,通道数减半,尺寸减半
self.stem3 = ConvBNAct(
mid_chs * 2,
mid_chs,
kernel_size=3,
stride=2,
use_lab=use_lab,
)
#1×1卷积调整通道数
self.stem4 = ConvBNAct(
mid_chs,
out_chs,
kernel_size=1,
stride=1,
use_lab=use_lab,
)
#这玩意这样设置可以保存图像尺寸大小,使用ceil_mode进行向上取整操作,还有滑动窗口最后一点没有进行滑动保存下来了一点窗口进行相加导致图像寸尺大小不变
self.pool = nn.MaxPool2d(kernel_size=2, stride=1, ceil_mode=True)
def forward(self, x):
x = self.stem1(x)
x = F.pad(x, (0, 1, 0, 1)) #右侧下侧进行填充
#分支1,这玩意有点像瓶颈层的感觉
x2 = self.stem2a(x)
x2 = F.pad(x2, (0, 1, 0, 1))
x2 = self.stem2b(x2)
#分支2
x1 = self.pool(x)
#分支特征融合,通道拼接
x = torch.cat([x1, x2], dim=1)
#进一步降维和下采样
x = self.stem3(x)
x = self.stem4(x)
return x
这个地方主要注意图像的尺寸变化,要保持图像尺寸的适配,所以在进行卷积提取特征的同时对其特征尺寸进行了填充,F.pad,是一个双分支的结构,分支完后进行通道拼接,最后进行降维和下采样操作,返回最后提取的特征。
那么这个StemBlock大组件基本就这样了,采用双分支结构进行特征提取。
再来看看这个HG_Stage大组件
HG_Stage
也是一样从其前向传播入手,看看存在什么自定义的组件
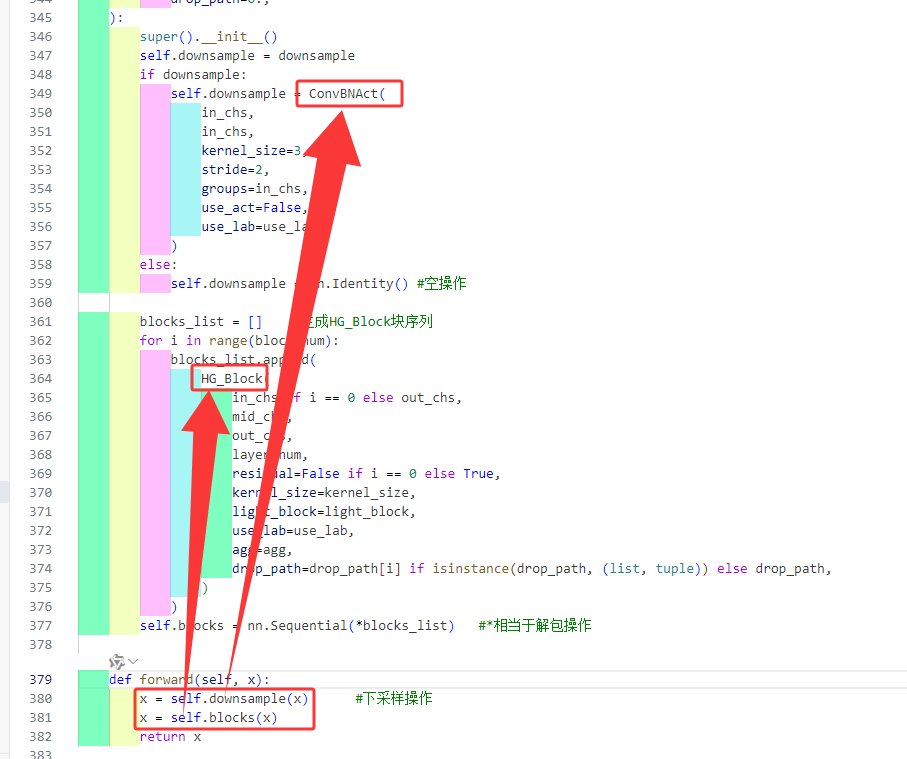
存在两个组件一个是self.downsample正常情况是由ConvBNAct基础组件组成,另外一个是由HG_Block组件序列组成,那就来看看HG_Block这个组件
HG_Block
也一样先看前向传播函数,主要由两个自定义组件:
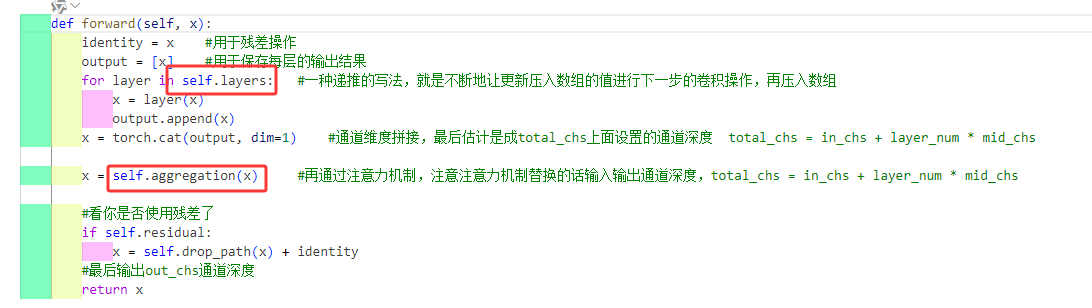
self.layers
就是由一堆基础的卷积组合块组成
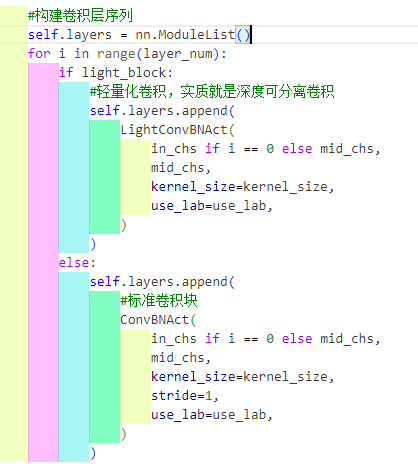
self.aggregation
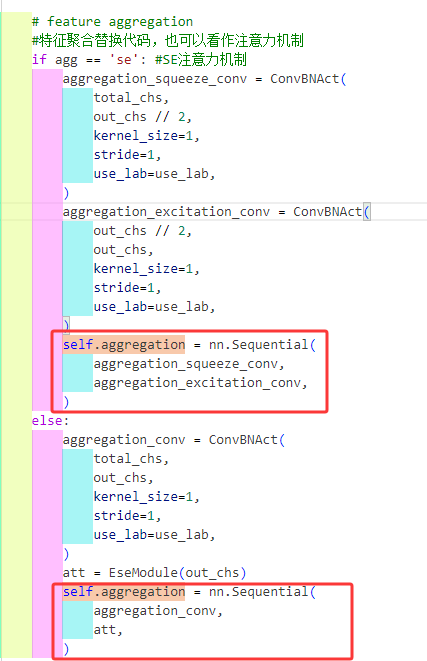
来看看这个(EseModule)组件
EseModule
class EseModule(nn.Module): #轻量化通道注意力机制
def __init__(self, chs):
super().__init__()
self.conv = nn.Conv2d(
chs,
chs,
kernel_size=1,
stride=1,
padding=0,
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
identity = x # 保存原始输入
# 1. 全局平均池化:压缩空间维度
x = x.mean((2, 3), keepdim=True) # [B,C,H,W] → [B,C,1,1]
# 2. 1×1卷积:生成通道权重
x = self.conv(x) # [B,C,1,1] → [B,C,1,1]
# 3. Sigmoid激活:将权重归一化到[0,1]
x = self.sigmoid(x) # [B,C,1,1]
return torch.mul(identity, x) # [B,C,H,W] × [B,C,1,1] → [B,C,H,W]
怎么运行的在其前向传播中注释的很清晰。
了解了上面这些基础组件再回去看HG_Block就很简单了,先通过一堆的卷积序列进行特征提取后进行通道拼接再塞入注意力机制中最后看看要不要进行残差连接返回提取的特征块就行了。

这就是HG_Block,用它来组合成HG_Stage,下面拉回来看看HG_Stage

这个大组件由self.downsample和self.blocks组成,而self.downsample看这个变量名也很清楚一个下采样的东西,从定义上看如果需要下采样的话就由ConvBNAct进行下采样,如果不想下采样就空操作就行了;self.blocks就由一堆的HG_Block组成。
至此HGNetv2的两大组件(self.stem、self.stages)就解析完了
再来复述一下
这个self.stem就是由ConvBNAct组成的双分支结构组件。
self.stages是由HG_Stage序列化块组成;单个的HG_Stage是由下采样和HG_Block序列块组成;单个HG_Block块是由卷积组合块和注意力机制组成。
