原文地址:YOLOv8中间特征层可视化_yolov8特征图可视化-CSDN博客
防止某些平台不当人,恰烂米,先搞过来
一、优势和作用
在 YOLOv8 或类似深度学习目标检测模型中使用中间特征层进行可视化有以下优点:
1. 理解网络的学习过程
中间特征层可视化可以帮助我们深入了解模型在各个阶段如何提取和处理特征:
低层特征层: 通常捕获边缘、纹理、颜色等基本特征。
中层特征层: 逐渐开始学习更加复杂的模式,比如形状和局部结构。
高层特征层: 专注于语义信息,能够识别完整目标或其上下文。
通过观察这些特征,可以清楚地看到模型如何逐步将输入图像转化为有意义的表示。
2. 调试和改进网络结构
发现问题: 可视化中间特征层可以帮助识别模型中可能存在的问题,例如:
特定通道的激活值过低(信息丢失)。
特征图尺寸缩小过快(过度下采样)。
某些通道在高层依然保留低层特征(特征冗余)。
优化设计: 通过可视化结果,可以调整网络结构,例如:
增加或减少卷积层。
修改特征融合方式(如 FPN、PAN 等)。
改善注意力机制或特征选择模块。
3. 检测模型的注意力区域
通过中间层的特征图,我们可以观察模型对图像中不同区域的关注程度:
是否关注到目标的关键区域(如物体边缘、轮廓)。
是否忽略了背景干扰或非相关信息。
这对改进模型性能和理解检测误差来源非常重要。
4. 验证特定模块的有效性
注意力机制: 如果模型中使用了模块(如 Squeeze-and-Excitation、CBAM、OmniAttention),中间层可视化可以帮助验证这些模块是否在正确的位置起作用。
频率选择模块: 可视化能显示不同通道是否成功分离低频和高频信息。
上下文特征融合: 通过特征图观察不同尺度的融合是否完整。
5. 探索通道的重要性
通过中间层的每个通道特征图,可以:
评估各通道的激活强度。
找出对最终目标检测任务贡献较大的通道。
根据这些信息,调整通道数量或设计通道选择机制。
6. 检测小目标的特征
小目标检测: 中间特征层通常包含更细粒度的信息,有助于观察小目标是否被网络正确捕获。
如果小目标在低层次特征中就未被充分关注,可能需要调整感受野或特征融合模块。
。。。。。
二 、在YOLOv8中间层可视化的实现(分通道)
1. 必须要有个训练完的模型
2. 通过detect进行中间层可视化
这是我的detect.py脚本,重点要将 visualize=True设为True
1 import warnings 2 warnings.filterwarnings('ignore') 3 from ultralytics import YOLO 4 5 6 7 if __name__ == '__main__': 8 model = YOLO('runs/train/yolov8/weights/best.pt') # select your model.pt path 9 model.predict(source='trash/test1', 10 imgsz=640, 11 project='runs/detect/feature', 12 name='yolov8', 13 save=True, 14 # conf=0.2, 15 # iou=0.7, 16 # agnostic_nms=True, 17 visualize=True, # visualize model features maps 18 # line_width=2, # line width of the bounding boxes 19 # show_conf=False, # do not show prediction confidence 20 # show_labels=False, # do not show prediction labels 21 # save_txt=True, # save results as .txt file 22 # save_crop=True, # save cropped images with results 23 )
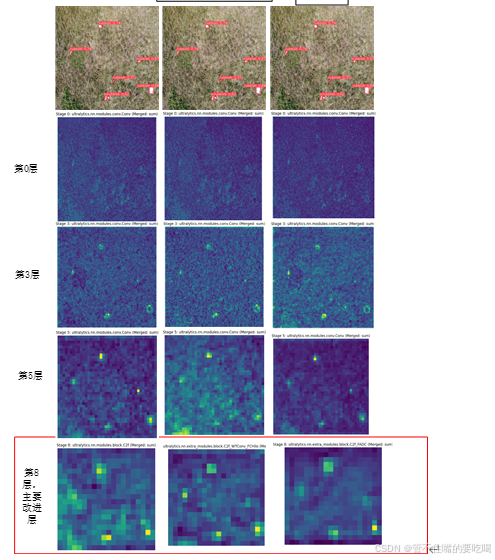
3. 接下来运行(以一张侧视图展示为例)
这张为原始图像:

这张为detect后的图像:

接下来以YOLOv8的原始网络为例
1 # Ultralytics YOLO 🚀, AGPL-3.0 license 2 # YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect 3 4 # Parameters 5 nc: 80 # number of classes 6 scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n' 7 # [depth, width, max_channels] 8 n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs 9 s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs 10 m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs 11 l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs 12 x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs 13 14 # YOLOv8.0n backbone 15 backbone: 16 # [from, repeats, module, args] 17 - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 这就是可视化中间层的stage0 18 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 这就是可视化中间层的stage1 19 - [-1, 3, C2f, [128, True]] # 这就是可视化中间层的stage2 20 - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 这就是可视化中间层的stage3,后面以此类推 21 - [-1, 6, C2f, [256, True]] 22 - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 23 - [-1, 6, C2f, [512, True]] 24 - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 25 - [-1, 3, C2f, [1024, True]] 26 - [-1, 1, SPPF, [1024, 5]] # 9 27 28 # YOLOv8.0n head 29 head: 30 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] 31 - [[-1, 6], 1, Concat, [1]] # cat backbone P4 32 - [-1, 3, C2f, [512]] # 12 33 34 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] 35 - [[-1, 4], 1, Concat, [1]] # cat backbone P3 36 - [-1, 3, C2f, [256]] # 15 (P3/8-small) 37 38 - [-1, 1, Conv, [256, 3, 2]] 39 - [[-1, 12], 1, Concat, [1]] # cat head P4 40 - [-1, 3, C2f, [512]] # 18 (P4/16-medium) 41 42 - [-1, 1, Conv, [512, 3, 2]] 43 - [[-1, 9], 1, Concat, [1]] # cat head P5 44 - [-1, 3, C2f, [1024]] # 21 (P5/32-large) 45 46 - [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
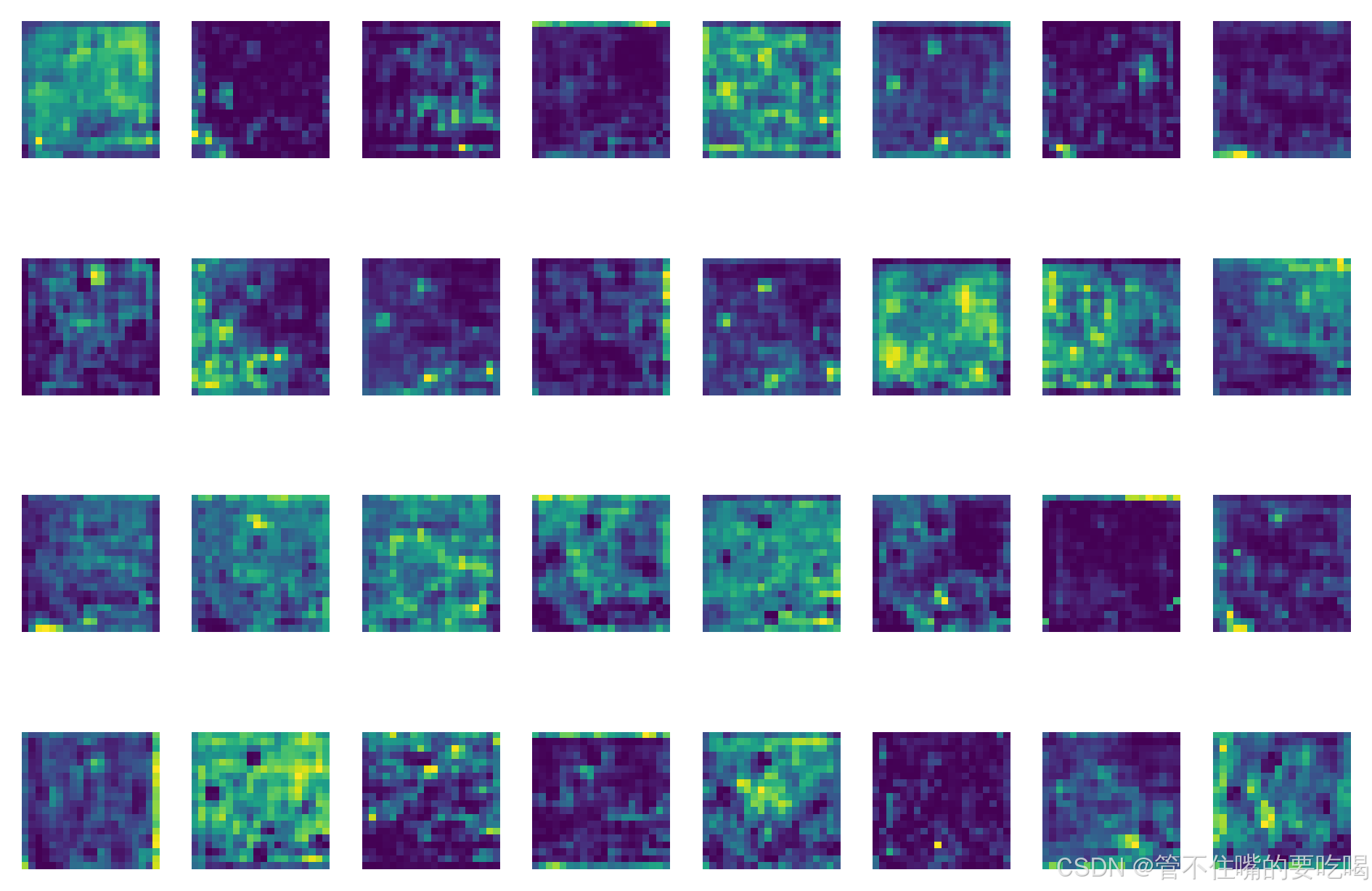
4. 以浅层也就是前几层为例(在这里,每一层特征图有多少通道数就会生成多少张特征图)
第0层(16个通道数,所以生成了16张图)

第3层(有32个通道数,所以生成了32张特征图)

5. 但是大家会发现 ,这样生成的中间层特征图可视化,很难去看,层越深图像越来越抽象,比较难观察,比如以第8层为例
6.所以接下来我们将每一层的通道数进行通道融合,每一层生成一个特征图
三、在YOLOv8中间层可视化的实现(合并通道,分通道共同实现)
1. 添加代码(ultralytics/utils/plotting.py)
1 def feature_visualization_merged(x, module_type, stage, merge_mode="mean", save_dir=Path("runs/detect/exp")): 2 """ 3 Visualize merged feature maps of a given model module during inference. 4 Args: 5 x (torch.Tensor): Features to be visualized. 6 module_type (str): Module type. 7 stage (int): Module stage within the model. 8 merge_mode (str, optional): Mode to merge channels. Defaults to "mean". Options: "mean", "sum", "max". 9 save_dir (Path, optional): Directory to save results. Defaults to Path('runs/detect/exp'). 10 """ 11 for m in {"Detect", "Segment", "Pose", "Classify", "OBB", "RTDETRDecoder"}: # all model heads 12 if m in module_type: 13 return 14 if isinstance(x, torch.Tensor): 15 _, channels, height, width = x.shape # batch, channels, height, width 16 if height > 1 and width > 1: 17 # Save path 18 save_dir.mkdir(parents=True, exist_ok=True) 19 f = save_dir / f"stage{stage}_{module_type.split('.')[-1]}_merged_features.png" 20 21 # Merge channels 22 if merge_mode == "mean": 23 merged_feature = x[0].mean(dim=0).cpu() # Channel-wise mean 24 elif merge_mode == "sum": 25 merged_feature = x[0].sum(dim=0).cpu() # Channel-wise sum 26 elif merge_mode == "max": 27 merged_feature, _ = x[0].max(dim=0) # Channel-wise max 28 merged_feature = merged_feature.cpu() 29 else: 30 raise ValueError(f"Unsupported merge_mode: {merge_mode}. Choose from 'mean', 'sum', 'max'.") 31 32 # Visualize 33 plt.figure(figsize=(6, 6)) 34 plt.imshow(merged_feature, cmap="viridis") # Use colormap for visualization 35 plt.axis("off") 36 plt.title(f"Stage {stage}: {module_type} (Merged: {merge_mode})") 37 plt.savefig(f) 38 plt.close()
2. 继续添加代码(ultralytics/nn/tasks.py)
在tasks.py中找到
class BaseModel(nn.Module):
下面的
def predict(self, x, profile=False, visualize=False, augment=False, embed=None):
下面的这句话
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
在这个if语句里面添加如下
if visualize: feature_visualization(x, m.type, m.i, save_dir=visualize) feature_visualization_merged(x, m.type, m.i, save_dir=visualize, merge_mode="sum") # 添加的代码
最后在tasks找到from ultralytics.utils.plotting import feature_visualization,在后面引用上feature_visualization_merged
from ultralytics.utils.plotting import feature_visualization,feature_visualization_merged
3. 在这里解释一下merge_mode=""可选择的参数,分别有mean、sum、max

如何选择聚合模式?(由于我在第8层修改了模块,想看模块对特征图的作用与修改前的哪个好,所以选择了sum)
分析整体特征:选择 mean,可以平衡所有通道的贡献。
寻找热点区域:选择 max,更容易发现显著激活的区域。
关注响应强度:选择 sum,分析特征图的总响应。
4. 话不多说展示
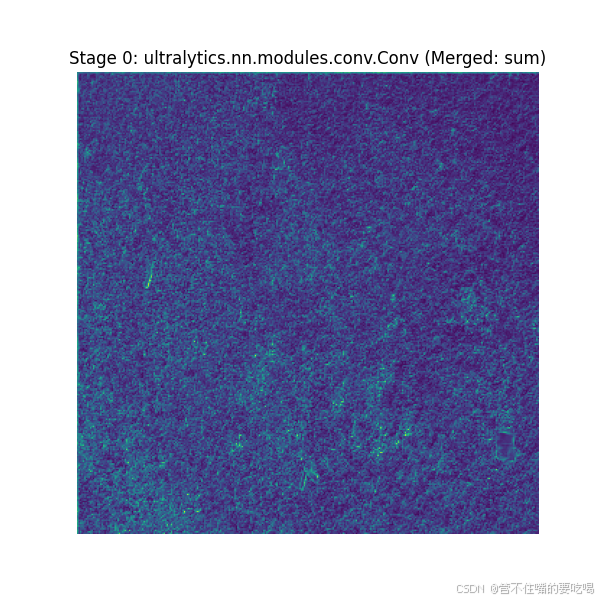
继续运行detect.py,生成如下特征图,带merged的就是融合后的
原图:

第0层
第3层

第8层:
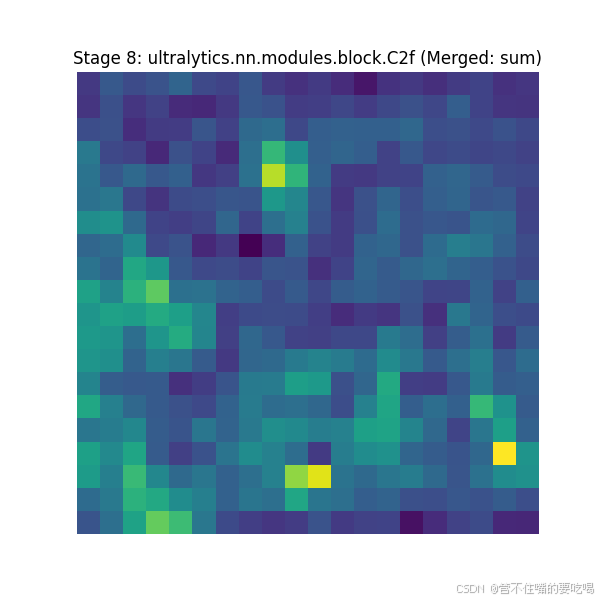
对比展示