

参考学习:
从零开始实现C++ TinyWebServer 全过程记录_tinywebserver要做多久-CSDN博客
从零开始实现C++ TinyWebServer(二)---- 勿在浮沙筑高台,项目地基需打稳_tinywebserver陈硕-CSDN博客
从零开始实现 C++ TinyWebServer 缓冲区 Buffer类详解_webserver缓冲区-CSDN博客
上一章剖析了Buffer的头文件内容,这里再剖析Buffer的源文件内容。
先放个整体代码:
#include "buffer.h" //读写下标初始化,vector<char>初始化 Buffer::Buffer(int initBuffSize) : buffer_(initBuffSize), readPos_(0), writePos_(0){} //可写的数量: buffer大小 - 写下标 size_t Buffer::WritableBytes() const{ return buffer_.size() - writePos_; } //可读的数量: 写下标 - 读下标 size_t Buffer::ReadableBytes() const{ return writePos_ - readPos_; } //可预留空间:已经读过的就没用了,等于读下标 size_t Buffer::PrependableBytes() const{ return readPos_; } //获取可读数据的起始地址,只用于查询指针,不会对其进行修改 const char* Buffer::Peek() const{ return &buffer_[readPos_]; } //确保可写的长度 void Buffer::EnsureWriteable(size_t len){ if(len > WritableBytes()){ MakeSpace_(len); } assert(len <= WritableBytes()); } //移动写下标,在Append中使用 void Buffer::HasWritten(size_t len){ writePos_ += len; } // 读取len长度,移动读下标 void Buffer::Retrieve(size_t len){ readPos_ += len; } //读出所有数据,buffer归零,读写下标归零,在别的函数中会用到 void Buffer::RetrieveAll(){ bzero(&buffer_[0], buffer_.size()); readPos_ = writePos_ = 0; } //取出剩余可读的str std::string Buffer::RetrieveAllToStr(){ std::string str(Peek(),ReadableBytes())//这里的作用应该是读取可读指针位置,和可读字符长度赋值给str RetrieveAll(); return str; } //写指针的位置 const char* Buffer::BeginWriteConst() const{ return &buffer_[writePos_]; } char* Buffer::BeginWrite(){ return &buffer_[writePos_]; } //添加str到缓冲区 void Buffer::Append(const char* str, size_t len){ assert(str); EnsureWriteable(len); //确保可写的长度 std::copy(str, str + len, BeginWrite()); //将str放到写下标开始的地方 HasWritten(len);//移动写下标 } void Buffer::Append(const std::string& str){ Append(str.c_str(),str.size()); } void Buffer::Append(cosnt void* data, size_t len){ Append(static_cast<const char*>(data), len); } //将buffer中的读下标的地方放到该buffer中的写下标的位置 void Buffer::Append(const Buffer& buff){ Append(buff.Peek(),buff.ReadableBytes()); } //将fd的内容读到缓冲区,即writeable的位置 ssize_t Buffer::ReadFd(int fd, int* Errno) { char buff[65535]; //栈区 struct iovec iov[2]; size_t writeable = WritableBytes(); //先记录能写多少 //分散读,保证数据全部读完 iov[0].iov_base = BeginWrite(); iov[0].iov_len = writeable; iov[1].iov_base = buff; iov[1].iov_len = sizeof(buff); ssize_t len = readv(fd, iov, 2) if(len < 0){ *Errno = errno; } else if(static_cast<size_t>(len) <= writeable){//若len小于writable writePos_ += len;//直接移动写下标 } else { writePos_ = buffer_.size(); //写区写满了,下标移动到最后 Append(buff, static_cast<size_t>(len - writeable));//剩余的长度 } return len; } //将buffer中可读的区域写入fd中 ssize_t Buffer::WriteFd(int fd,int* Errno){ ssize_t len = write(fd, Peek(), ReadableBytes()); if(len < 0){ *Errno = errno; return len; } Retrieve(len); return len; } char* Buffer::BeginPtr_(){ return &buffer_[0]; } const char* Buffer::BeginPtr_() const{ return &buffer_[0]; } //扩展空间 void Buffer::MakeSpace_(size_t len){ if(WritableBytes() + PrependableBytes() < len){ buffer_.resize(writePos_ + len + 1); } else { size_t readable = ReadableBytes(); std::copy(BeginPtr_() + readPos_, BeginPtr_() + writePos_, BeginPtr_()); readPos_ = 0; writePos_ = readable; assert(readable == ReadableBytes()); } }
再把buffer的结构设计图放出来好对比代码
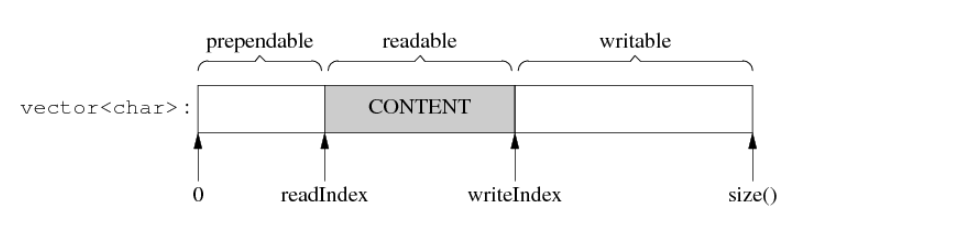
构造函数
作用:读写下标初始化,vector<char>初始化
Buffer::Buffer(int initBuffSize) : buffer_(initBuffSize), readPos_(0), writePos_(0){}
查询缓冲区状态
- 计算可写字节大小,很简单,就直接返回buffer的空间大小减去可写指针下标就行
//可写的数量: buffer大小 - 写下标 size_t Buffer::WritableBytes() const{ return buffer_.size() - writePos_; }
- 计算可读的字节数量,将可写的下标减去可读的下标就是可读的字节数量
//可读的数量: 写下标 - 读下标 size_t Buffer::ReadableBytes() const{ return writePos_ - readPos_; }
- 可预留空间,具体干嘛用的还不清楚,好像是可以优化性能节省空间大小
//可预留空间:已经读过的就没用了,等于读下标 size_t Buffer::PrependableBytes() const{ return readPos_; }
const char* Buffer::Peek() const;
只是用于获取可读数据的起始地址,只读权限。
/获取可读数据的起始地址,只用于查询指针,不会对其进行修改 const char* Buffer::Peek() const{ return &buffer_[readPos_]; }
void Buffer::EnsureWriteable(size_t len);
这个代码是嵌套调用的主要不是他,他可以看作一个判断语句罢了,主要的扩展代码得看MakeSpace_();
void Buffer::EnsureWriteable(size_t len){ if(len > WritableBytes()){ MakeSpace_(len); } assert(len <= WritableBytes()); }
void Buffer::HasWritten(size_t len);
这个作用就是用于移动写下标使用,感觉像个组件。
//移动写下标,在Append中使用 void Buffer::HasWritten(size_t len){ writePos_ += len; }
void Buffer::Retrieve(size_t len);
移动读下标
// 读取len长度,移动读下标 void Buffer::Retrieve(size_t len){ readPos_ += len; }
void Buffer::RetrieveAll();
读出所有数据,buffer归零,读写下标归零,感觉也像个组件,先将空间清空,再将读写下标设为0;
//读出所有数据,buffer归零,读写下标归零,在别的函数中会用到 void Buffer::RetrieveAll(){ bzero(&buffer_[0], buffer_.size()); readPos_ = writePos_ = 0; }
bzero是一个标准的C库函数,用于将一块内存区域的内容设为0;
void bzero(void *s, size_t n); //s指向要清零的内存区域的指针。 //n为要清零的字节数。
获取写指针位置
返回写指针位置,这个是用于提供外部接口的
//写指针的位置 const char* Buffer::BeginWriteConst() const{ return &buffer_[writePos_]; } char* Buffer::BeginWrite(){ return &buffer_[writePos_]; }
追加内容到缓冲区
- 传入可读的字符指针,还有字符串长度
void Buffer::Append(const char* str, size_t len){ assert(str); EnsureWriteable(len); //确保可写的长度 std::copy(str, str + len, BeginWrite()); //将str放到写下标开始的地方 HasWritten(len);//移动写下标 }
先调用确保满足可写空间函数;再使用copy函数将字符串从可写位置开始复制,这里记得调用的是指针,不是下标;写完后移动写下标。
- 使用string类型数据进行追加
void Buffer::Append(const std::string& str){ Append(str.c_str(),str.size()); }
套娃调用,把string类型往字符类型转,地址是连续的,只需要首地址就行,再加上string的长度,就可以套用第一个追加函数了。
- 追加任意数据类型进入缓冲区
void Buffer::Append(const void* data, size_t len){ Append(static_cast<const char*>(data), len); }
void*是通用类型指针,可以指向任意类型的数据,但是不能解引用,这里不清楚解引用是什么意思就查了一下
- 解引用:听名词很专业,引用就是把指针指向一个数据,解引用就是把指针数据赋值给变量。
int value = 10; int* ptr = &value; // ptr 指向 value // 解引用 ptr,访问 value 的值 int dereferencedValue = *ptr; // dereferencedValue 现在等于 10
void* ptr = &value; // int dereferencedValue = *ptr; // 编译错误:无法解引用 void*
- 解引用:听名词很专业,引用就是把指针指向一个数据,解引用就是把指针数据赋值给变量。
获得通用数据后再使用static_cast<cosnt char*>进行数据类型转换,再套用第一个追加方法就行。
- 追加Buffer类型数据进入缓冲区
/将buffer中的读下标的地方放到该buffer中的写下标的位置 void Buffer::Append(const Buffer& buff){ Append(buff.Peek(),buff.ReadableBytes()); }
Peek函数返回的是字符指针下标,再传入其可读长度,套娃就行了。
ssize_t Buffer::ReadFd(int fd, int* Errno);
这个好像是核心函数,将fd内容写入到缓冲区
//将fd的内容读到缓冲区,即writeable的位置 ssize_t Buffer::ReadFd(int fd, int* Errno) { char buff[65535]; //栈区 struct iovec iov[2]; size_t writeable = WritableBytes(); //先记录能写多少 //分散读,保证数据全部读完 iov[0].iov_base = BeginWrite(); iov[0].iov_len = writeable; iov[1].iov_base = buff; iov[1].iov_len = sizeof(buff); ssize_t len = readv(fd, iov, 2) if(len < 0){ *Errno = errno; } else if(static_cast<size_t>(len) <= writeable){//若len小于writable writePos_ += len;//直接移动写下标 } else { writePos_ = buffer_.size(); //写区写满了,下标移动到最后 Append(buff, static_cast<size_t>(len - writeable));//剩余的长度 } return len; }
- char buff[65535]
- 定义一个大小为65535字节的栈上缓冲区,用于存储超出当前缓冲区可写空间的数据
- struct iovec iov[2]; (这个不知道是什么鬼东西,下面看看定义)
- iovec 是Linux系统调用中用于分散/聚集I/O的结构体,定义如下:
struct iovec { void* iov_base; // 数据缓冲区的起始地址 size_t iov_len; // 缓冲区的长度 };
- ai说的是这里定义了两个iovec结构体,分别指向缓冲区的可写区域和临时缓冲区buff
- iovec 是Linux系统调用中用于分散/聚集I/O的结构体,定义如下:
- 调用WritableBytes函数,看看还有多少空间可以记录使用
-
//分散读,保证数据全部读完 iov[0].iov_base = BeginWrite(); iov[0].iov_len = writeable; iov[1].iov_base = buff; iov[1].iov_len = sizeof(buff);
剖析一下这个分散读代码。前面定义了两块iov,从这里就可以看出,一块iov是充当当前的Buffer类进行使用,另一块iov是充当一个临时缓冲区使用
- ssize_t len = readrv(fd, iov, 2)
- readv系统调用
- readv是Linux提供的分散读取系统调用,可以从文件描述符fd中一次性读取多个不连续的缓冲区
- 参数说明:
fd: 文件描述符
iov: iovec结构体数组,表示要读取的目标缓冲区。
2: iovec数组的大小(即要读取的缓冲区域数量) - 如果函数成功读取,返回实际读取的字节数(数据类型为ssize_t);如果返回值为负数,则表示发生错误,错误码存储在errno中。
- 作用
- 尝试从fd中读取数据,先填满缓冲区的可写区域(iov[0]),如果还有剩余数据,则继续填满临时缓冲区buff(iov[1])
- readv系统调用
if(len < 0){ *Errno = errno; } else if(static_cast<size_t>(len) <= writeable){//若len小于writable writePos_ += len;//直接移动写下标 } else { writePos_ = buffer_.size(); //写区写满了,下标移动到最后 Append(buff, static_cast<size_t>(len - writeable));//剩余的长度 }
剖析一下这个判断条件
- 这里面第一个判断语句,当读取失败的时候,会返回一个负值给len,如果len是负值就会将系统最近一次调用或库函数发生错误时的错误码,赋值给指针,这个errno是系统定义的变量。
- 第二个判断语句是表示读取的数据量没有超过缓冲区的可写空间,这种情况直接更新可写下标就行。
- 第三种情况就是读取成功但是数据量超过了可写空间,这种情况下直接将可写下标移动到数组尽头进行,因为超过了可写空间在原来的Buffer内是记录满的,iov[0]充当当前Buffer使用,是已经记录满,但是下标还没有进行变化。在下标完成变化后,再对数据进行追加,追加函数内存在动态扩充空间。
ssize_t Buffer::WriteFd(int fd,int* Errno);
这也是个核心函数,作用将Buffer中可读的区域写入fd中
//将buffer中可读的区域写入fd中 ssize_t Buffer::WriteFd(int fd,int* Errno){ ssize_t len = write(fd, Peek(), ReadableBytes()); if(len < 0){ *Errno = errno; return len; } Retrieve(len); return len; }
- write函数是系统调用函数,通常在#include<unistd.h>中,将buffer可读指针和可读空间大小作为参数,写入fd文件描述符中。
- 如果未写入到信息会将系统最近一次调用或库函数发生错误时的错误码,赋值给指针,这个errno是系统定义的变量,直接返回负值。
- 如果写入成功,就移动读下标,返回读取的长度。
私有成员中获取可写区域的起始地址
私有成员变量在类中调用,不作为对外的接口使用
char* Buffer::BeginPtr_(){ return &buffer_[0]; } const char* Buffer::BeginPtr_() const{ return &buffer_[0]; }
void Buffer::MakeSpace_(size_t len);
空间不足进行扩展存储空间
//扩展空间 void Buffer::MakeSpace_(size_t len){ if(WritableBytes() + PrependableBytes() < len){ buffer_.resize(writePos_ + len + 1); } else { size_t readable = ReadableBytes(); std::copy(BeginPtr_() + readPos_, BeginPtr_() + writePos_, BeginPtr_()); readPos_ = 0; writePos_ = readable; assert(readable == ReadableBytes()); }
如果说传入的参数len(也就是新需要写入的数据长度)大于可写入空间和已经使用空间(预留空间)就会调用resize函数,这个作用是重新开辟一片空间,将原数据拷贝过去,这是在所需空间大于原空间的情况下,如果所需空间小于原空间会直接截断,这样进行扩充。如果所需写入缓冲区数据没有大于可写入空间和预留空间总和就会将可读数据拷贝到最前方,重置可读下标,将可写空间和预留空间重新作为新的可写空间去写入数据,还要重新设定可写下标位置。
