

参考学习:从零开始实现C++ TinyWebServer 全过程记录_tinywebserver要做多久-CSDN博客
从零开始实现 C++ TinyWebServer 缓冲区 Buffer类详解_webserver缓冲区-CSDN博客
muduo学习笔记:net部分之实现TCP网络编程库-Buffer_muduo::net::buffer-CSDN博客
本文用于加强理解书写记录。
这是接触的第一个从零开始自己搭建项目,用于记录一些关键点。
Buffer类的设计
刚接触这个项目,只看了这个buffer部分,这个项目好像就是做一个信息交互的作用,网络通信,接收、传输信息之类的,也就和网络协议相关,那么我接收信息就需要缓冲,这个机制要想怎么处理。
看他们对于这个Buffer的设计是基于陈硕士muduo库的buffer(具体是什么我也没看过不知道,我只是新手想做做开源项目积累开发经验)
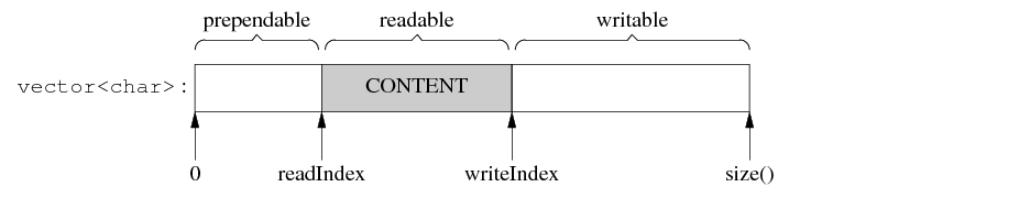
private: //获取可写区域的起始地址 char* BeginPtr_(); const char* BeginPtr_() const; //调整内部存储以容纳更多数据 void MakeSpace_(size_t len); //实际存储数据的容器,使用vector实现动态增长 std::vector<char> buffer_; //表示当前读取位置的指针,使用std::atomic确保线程安全 std::atomic<std::size_t> readPos_; //表示当前写入位置的执政,使用std::atomic确保线程安全 std::atomic<std::size_t> writePos_;
这里的类私有成员定义如上图;
-
BeginPtr_();用于获取可写区域的起始地址
这里需要考验对于c++的理解,当时学也没学太认真,所以打算从项目入手再理解一下。
对于普通的实例化对象,调用BeginPtr_()返回的指针就是正常功能的指针,没有什么限制。
但是如果说实例化对象是const的,那么调用的就是const char* BeginPtr_() const 返回的指针,解析一下这两个const的作用,在前的一个const是设置指针指向的内容不能发生修改但是其地址是可以发生变化的,在后的一个const表示的是这个函数是const的私有成员函数,在对象也是const的时候可以调用使用。
这里再辨别一下第一个const放置的作用:
const char* ptr = "hello"; *ptr = 'H'; // 编译错误,因为 ptr 指向的内容是 const 的,不能修改。
当const在前面就是让内容不能通过指针进行修改,但是你可以修改指针的地址进行可读访问。
char* const ptr = new char('a'); ptr = new char('b'); // 编译错误,因为 ptr 本身的地址是 const 的,不能修改。
当const被数据类型包括在内,就表示这个指针的地址是静态的,指针的地址不能改变,但是其内容可以进行改变。
-
MakeSpace_(size_t len);
这个函数就是用于调整buffer内部的空间大小,动态扩充容量,至于为什么能扩充是基于后面的私有成员变量使用的是vector;先理解意思再说,后续再详细剖析函数代码
-
std::vector<char> buffer_;
通常刚开始学c++第一个接触的就是c++的定义格式,都是教学使用iostream头文件再附带个using namespace std;这里的using namespace std的意思是将std命名空间的内容导入到当前的作用域当中,在开发过程中尽量不使用using namespace std这种方式导入,这种方式容易混淆一些方法是使用当前作用域定义的方法还是标准库(std)中的方法。这里选择使用vector容器进行存储让空间可以动态调整。
给个直观的栗子:
下面看成两个头文件,以及命名空间的定义方式。
// 文件 A.h namespace MyLib { int add(int a, int b) { return a + b; } } // 文件 B.h namespace YourLib { int add(int a, int b) { return a - b; } // 同名函数 }
对这两个命名空间的调用,如果你调用了这两个库,但是再叠加了命名空间进行导入就可能产生混淆,到底是调用哪个。
#include "A.h" #include "B.h" int main() { int result1 = MyLib::add(3, 2); // 调用 MyLib 的 add 函数 int result2 = YourLib::add(3, 2); // 调用 YourLib 的 add 函数 std::cout << result1 << ", " << result2 << std::endl; // 输出 5, 1 }
所以在开发过程中避免直接使用using namespace std去调用。
-
std::atomic<std::size_t> readPos_;
表示当前可读位置的指针,使用atomic保证线程安全,这个atomic不太好解释,就是说在线程调用共享的变量的时候,只有一个线程能使用,在使用完之前其他线程都不能使用这个变量,这样保证了线程的安全性,不会发生线程冲突。
-
std::atomic<std::size_t> writePos_;
表示当前写入的位置的指针,也是使用atomic保证线程安全。
注意上面两个指针是间接的指向,这里面记录的数据类型是size_t也可以认为是int类型,也就是说其实其记录的是下标,是vector的下标,充当指针的效果使用。
下面看看buffer中的公共成员
public: Buffer(int initBuffSize = 1024) ~Buffer() = default; //查询缓冲区状态 //计算可写空间 size_t WritableBytes() const; //计算可读空间 size_t ReadableBytes() const; //计算可预分配空间 size_t PrependableBytes() const; //获取可读数据的起始地址 const char* Peek() const; //确保有足够的可写空间,如果缓冲区的可写空间不足,则调整内部存储以容纳更多数据 void EnsureWriteable(size_t len); //标记已写入的字节数 void HasWritten(size_t len); //移除指定长度的数据 void Retrieve(size_t len); //移除直到指定位置的数据 void RetrieveUntil(const char* end); //清空整个缓冲区 void RetrieveAll(); //将缓冲区中的所有数据转换为字符串并清空缓冲区 std::string RetrieveAllToStr(); //获取可写区域的起始地址 const char* BeginWriteConst() const; char* BeginWrite(); //数据追加,支持多种数据类型 void Append(const std::string& str); void Append(const char* str, size_t len); void Append(const void* data, size_t len); void Append(const Buffer& buff); //从文件描述符中读取数据到缓冲区 ssize_t ReadFd(int fd,int* Errno); //将缓冲区中的数据写入文件描述符中 ssize_t WriteFd(int fd,int* Errno);
-
Buffer(int initBuffSize = 1024); ~Buffer() = default;
一个构造函数,一个析构函数,很明显了,这个构造函数就是直接初始化容器空间大小用的,设置最初Buffer可容纳数据的大小
-
状态查询
-
size_t WritableBytes() const;
计算可写空间大小 -
size_t ReadableBytes() const;
计算可读空间大小 -
size_t PrependableBytes() const;
计算可预分配空间大小
-
这里状态查询使用的都是const类型的,只作为查询的作用,避免了对内部数据的修改,正常的实例化对象可以调用const的函数,但是如果是const的实例化对象就只能调用const函数。
-
数据追加,支持多种数据类型
-
void Append(const std::string& str);
-
void Append(const char* str, size_t len);
-
void Append(const void* data, size_t len);
- void Append(const Buffer& buff);
-
这个不太想解释,到时候看源码就行了,这个有点像套娃,数据转化套进去。
-
const char* Peek() const;
获取可读数据的起始地址,就是获取可读指针的地址位置。使用const防止内容被进行修改
-
void EnsureWriteable(size_t len);
这个函数好像有点复杂的,作用就是确保有足够的可写空间,如果缓冲区的可写空间不足,则调整内部存储以容纳更多数据。
-
void HasWritten(size_t len);
标记已写入的字节数,这个方法好像就是个组件,后续看看实际的代码调用
-
void Retrieve(size_t len);
移除指定长度的数据,这个东西好像也是个组件,后续看看实际的代码调用
-
void RetrieveUntil(const char* end);
移除直到指定位置的数据,这几个移除方法好像存在套娃操作,作为组件,后续看看实际的代码调用
-
void RetrieveAll();
清空整个缓冲区
-
std::string RetrieveAllToStr();
将缓冲区中的所有数据转换为字符串并清空缓冲区
-
获取可写区域的起始地址
-
const char* BeginWriteConst() const;
只读属性,不能修改指针指向内容,可修改指针指向地址,只有可读权限。 -
char* BeginWrite();
返回指针,拥有全部的权限。
-
这里有点疑惑,在私有成员中已经存在了相同功能的两个函数,都是返回可写区域的起始地址的方法,ai给的解释是使用的场景不同,我的理解就是在私有成员中书写的方法是给类内部自己使用的,在公共成员中书写的方法是提供给外部的接口。
-
ssize_t ReadFd(int fd,int* Errno);
这个函数代码挺复杂的,是个核心函数,后续详细解析,这里先解释一下作用,从文件描述符中读取数据到缓冲区
-
ssize_t WriteFd(int fd,int* Errno);
这也是个核心函数,将缓冲区的数据写入文件描述符中。
