



处理梨视频|Python笔记
分析
1)目标网站
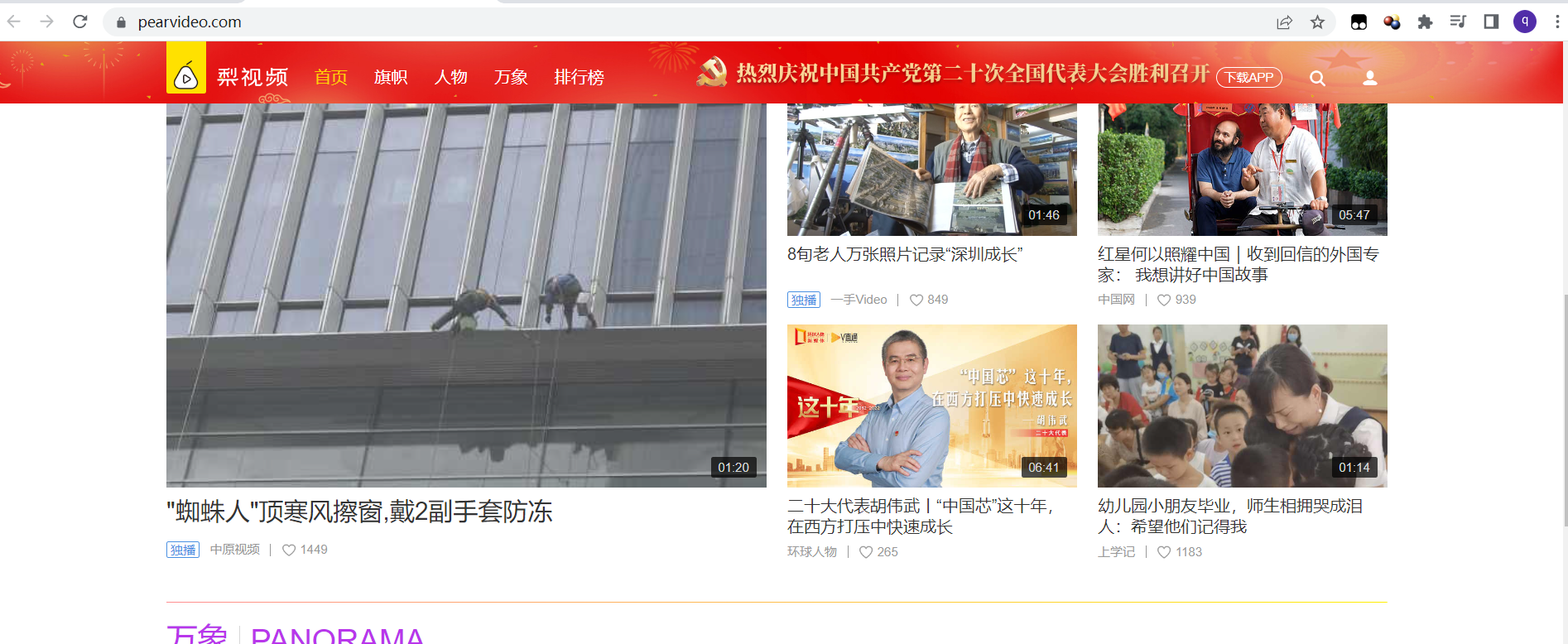
要抓取页面中的视频首先要确认视频是否在页面源代码中。
2)打开检查,找到视频的位置,发现视频放在video标签里,但是拿到“
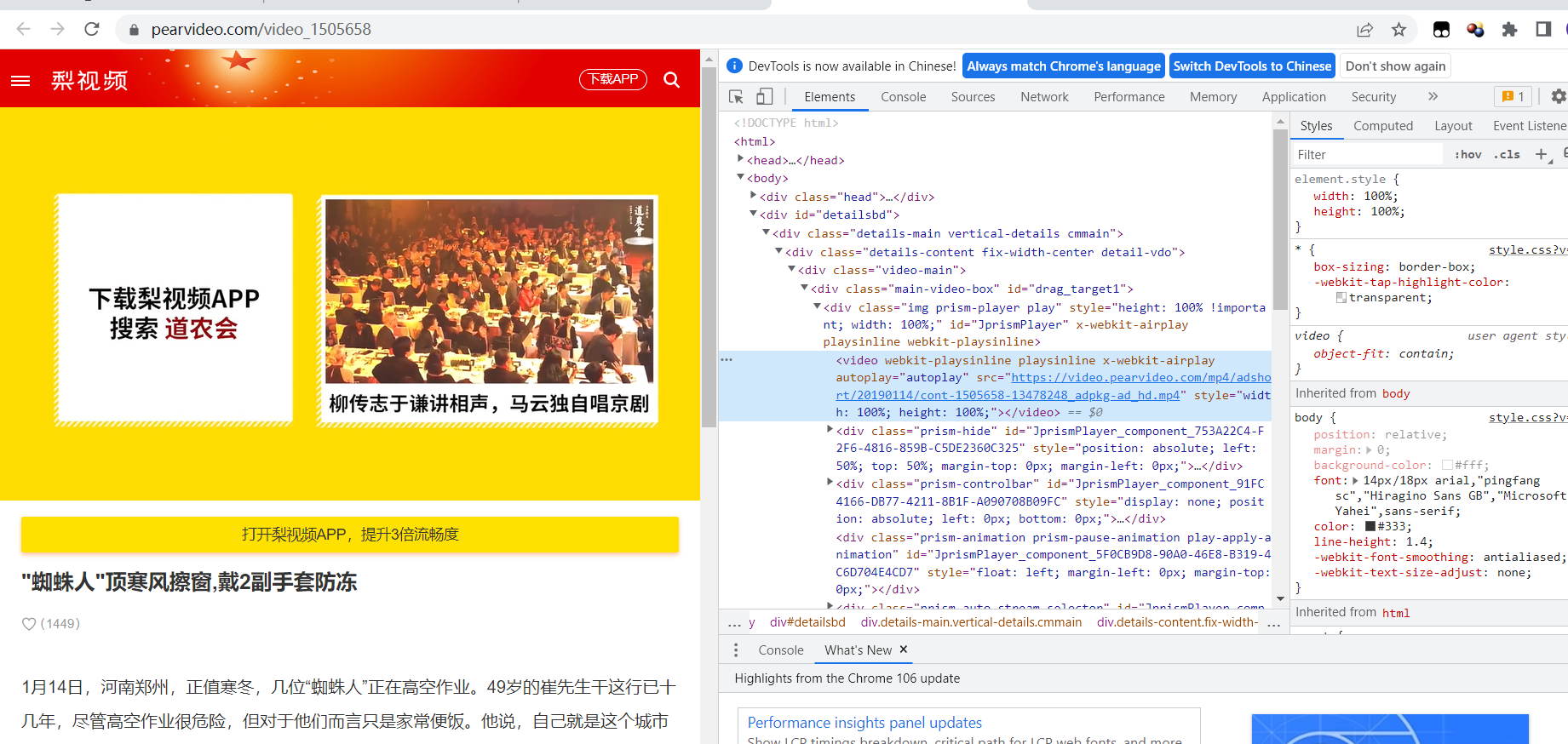
3)选择XHR,筛选出js包
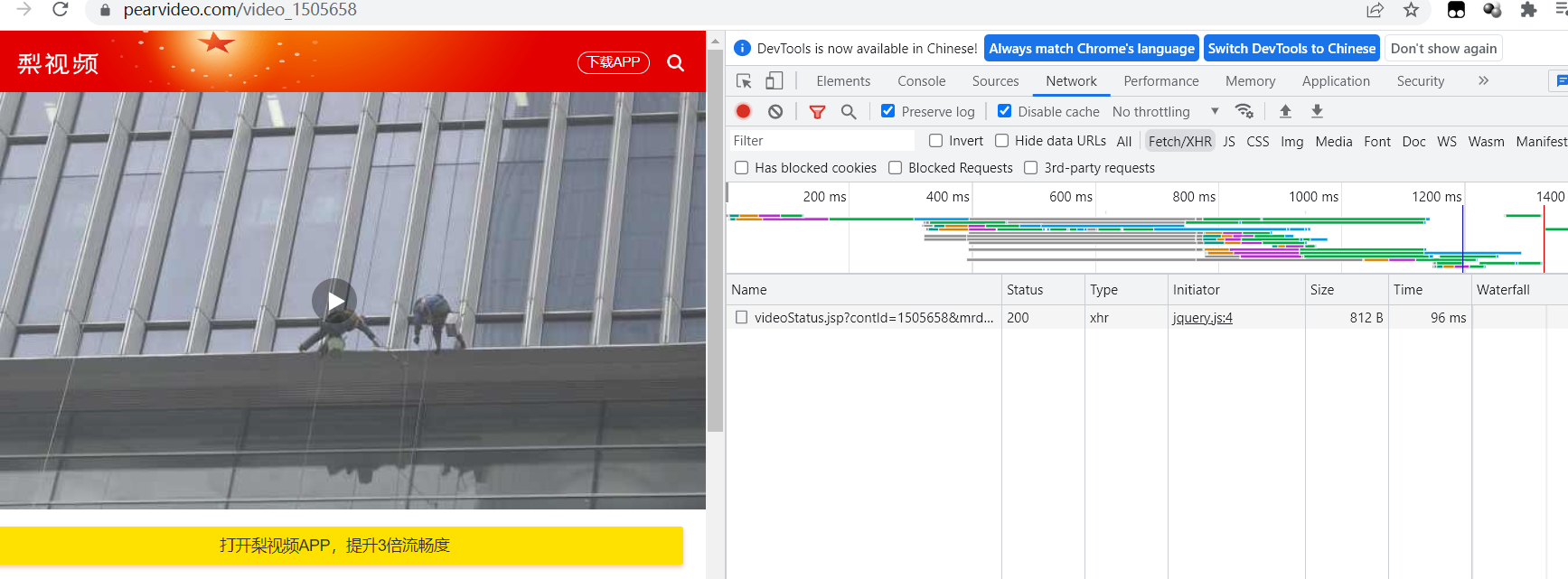
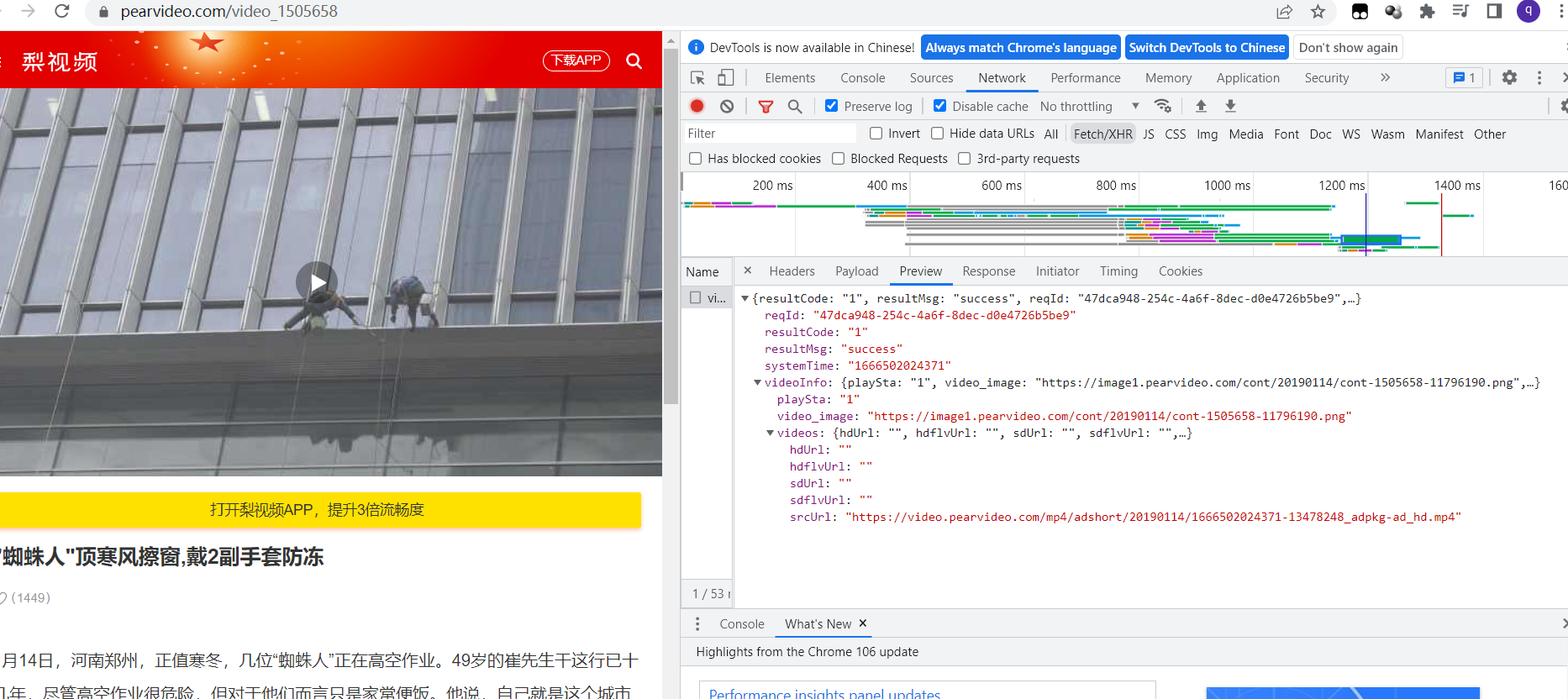
找到.mp4的url,对比该连接与真正视频连接:
真正url:
https://video.pearvideo.com/mp4/adshort/20190114/cont-1505658-13478248_adpkg-ad_hd.mp4
包里的url:
https://video.pearvideo.com/mp4/adshort/20190114/1666502024371-13478248_adpkg-ad_hd.mp4
说明包里的url又进行了加工,寻找规律。
2)编写爬虫
- 拿到contId
- 拿到videoStatus返回的json——>srcURL
- srcURL里面的内容进行修整
- 下载视频
import requests
url = "https://www.pearvideo.com/video_1505658"
contId = url.split("_")[1]
videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.6525775882820379"
resp = requests.get(videoStatusUrl)
print(resp.text)

代码逻辑没问题,那么爬取不到首先考虑UA,但发现加入UA后仍然无法爬取,那么就引出Refer。
3)处理Refer
Refer就是防盗链,即当前请求会进行溯源,也就是在哪个页面发起请求的,A——>B——>C。
import requests
url = "https://www.pearvideo.com/video_1505658"
contId = url.split("_")[1]
videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.6525775882820379"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
"Referer": "https://www.pearvideo.com/video_1505658"
}
resp = requests.get(videoStatusUrl,headers=headers)
print(resp.text)
4)resp.json()拿到字典,拿到视频连接
import requests
url = "https://www.pearvideo.com/video_1505658"
contId = url.split("_")[1]
videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.6525775882820379"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
"Referer": "https://www.pearvideo.com/video_1505658"
}
resp = requests.get(videoStatusUrl,headers=headers)
dic = resp.json()
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime,f"cont-{contId}")
print(srcUrl)
5)下载视频
import requests
url = "https://www.pearvideo.com/video_1505658"
contId = url.split("_")[1]
videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.6525775882820379"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
"Referer": "https://www.pearvideo.com/video_1505658"
}
resp = requests.get(videoStatusUrl,headers=headers)
dic = resp.json()
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime,f"cont-{contId}")
with open("a.mp4",mode="wb") as f:
f.write(requests.get(srcUrl).content)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号