会员
周边
新闻
博问
闪存
众包
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
那人,那事,那代码
走走停停,终该是留点什么
博客园
首页
新随笔
联系
管理
订阅
上一页
1
···
25
26
27
28
29
30
31
32
33
···
46
下一页
2020年7月14日
redmine 自定义问题列表显示字段
摘要: 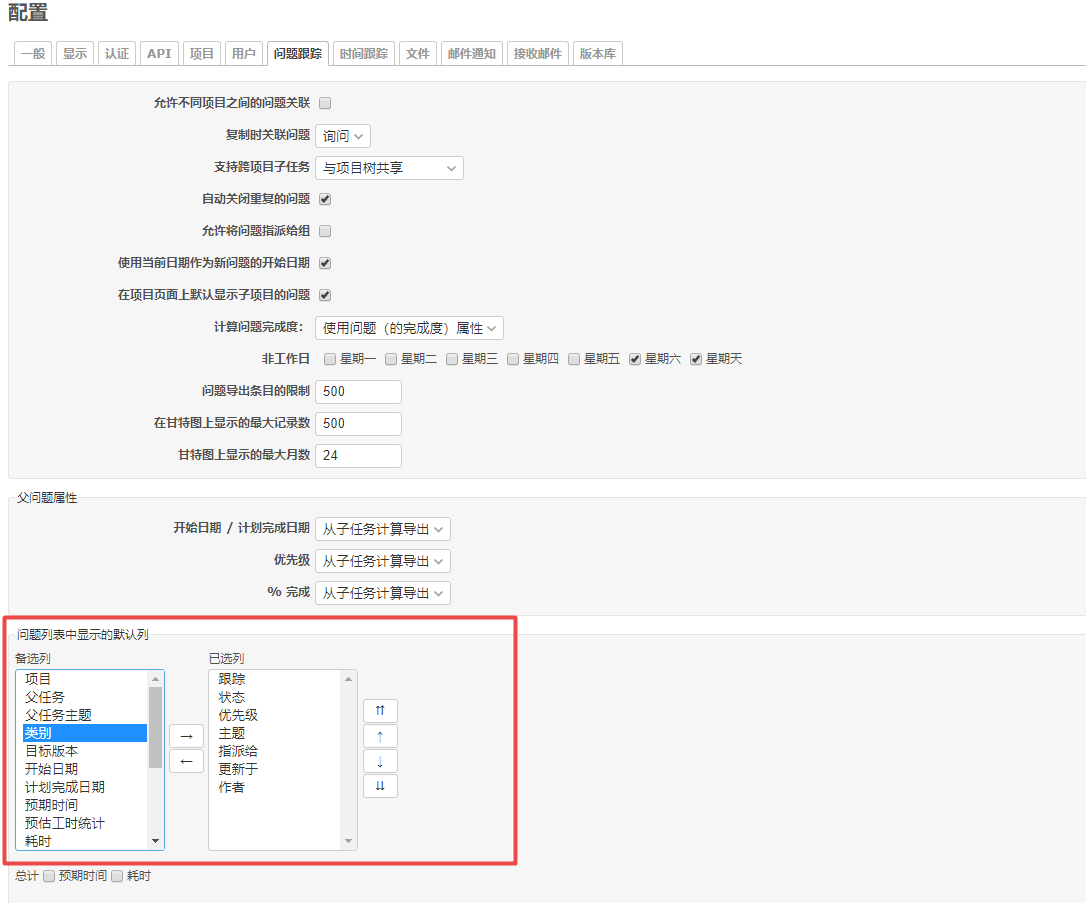
阅读全文
posted @ 2020-07-14 15:12 那时一个人
阅读(761)
评论(0)
推荐(0)
2020年7月13日
odoo 模块安装不报错,升级会报错,KeyError:
摘要: 错误原因: 没有添加模块依赖,
阅读全文
posted @ 2020-07-13 17:56 那时一个人
阅读(561)
评论(0)
推荐(0)
2020年7月11日
powerBI 连接报表服务器提示 发生意外错误
摘要: https://blog.csdn.net/guozhiwu_sz/article/details/104537333 解决办法: 打开windows设置,搜索“凭据”,定位到“管理Windows凭据”,点击“添加Windows凭据”,输入报表服务器IP地址、用户名和密码(必须是服务器的超级管理员账
阅读全文
posted @ 2020-07-11 17:41 那时一个人
阅读(1288)
评论(0)
推荐(0)
2020年7月10日
python 正则匹配替换,在匹配的字符后方添加新的字符
摘要: python 的替换 re.sub(r'(\d)',r'\1,','ab1c1de2f') 'ab1,c1,de2,f' 匹配换行符: re.findall(parttern,string,re.S) postgres 的替换: select regexp_replace('AAAAAAAAAAAA
阅读全文
posted @ 2020-07-10 10:08 那时一个人
阅读(1702)
评论(0)
推荐(0)
2020年7月8日
odoo default_get 方法和onchange装饰器造成冲突,
摘要: 在模型中如果使用default_get 方法创建明细行,同时模型中又有一个装饰器onchange,在onchange中会重新加载明细行, * 那么在执行default_get 方法后会重新调用onchange方法,将之前defalt_get 方法创建的明细行删除.
阅读全文
posted @ 2020-07-08 17:17 那时一个人
阅读(637)
评论(0)
推荐(0)
redmine 如何启用用户图标
摘要: 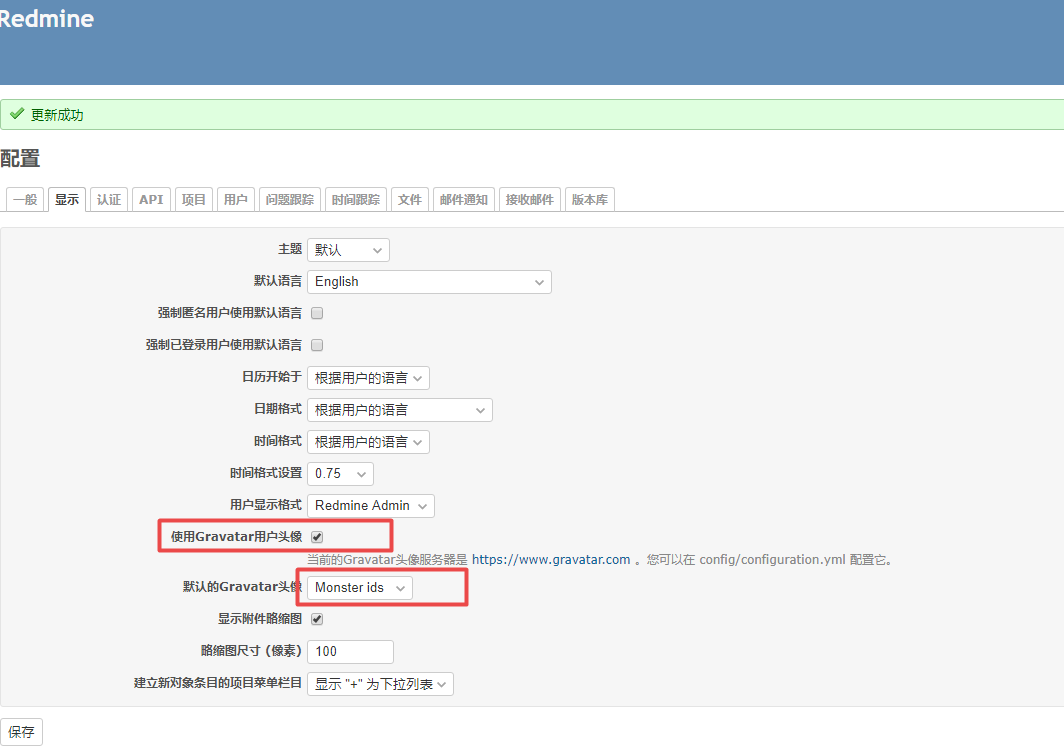
阅读全文
posted @ 2020-07-08 14:55 那时一个人
阅读(220)
评论(0)
推荐(0)
2020年7月7日
odoo 打印执行的sql语句
摘要: 设置配置文件: level = debug_sql https://blog.csdn.net/M0relia/article/details/39484491?locationNum=5
阅读全文
posted @ 2020-07-07 12:25 那时一个人
阅读(891)
评论(0)
推荐(0)
2020年7月5日
scrapy 管理部署的爬虫项目的python类
摘要: 这个类可以比较方便的去管理你的爬虫服务 # 测试浏览器弹窗的验证: import requests from urllib import parse import logging logging.basicConfig(level=logging.INFO) class ScrapyManager(
阅读全文
posted @ 2020-07-05 18:43 那时一个人
阅读(181)
评论(0)
推荐(0)
docker 部署爬虫服务的命令
摘要: docker run -p 6800:6800 --name scrapy -e USERNAME=admin -e PASSWORD=admin cdrx/scrapyd-authenticated 命令中USERNAME=admin -e PASSWORD=admin 指定nginx服务的访问账
阅读全文
posted @ 2020-07-05 17:32 那时一个人
阅读(221)
评论(0)
推荐(0)
scrapy 部署的项目带有验证,怎样启动项目
摘要: import requests session = requests.session() url = 'http://IP:6800/schedule.json' data = dict( project='scrapy_rere', spider='rere', ) # 需要加上你的爬虫服务账密:
阅读全文
posted @ 2020-07-05 17:03 那时一个人
阅读(117)
评论(0)
推荐(0)
上一页
1
···
25
26
27
28
29
30
31
32
33
···
46
下一页
公告



 浙公网安备 33010602011771号
浙公网安备 33010602011771号