


scrapy 教程笔记
Scrapy 框架学习笔记及截图
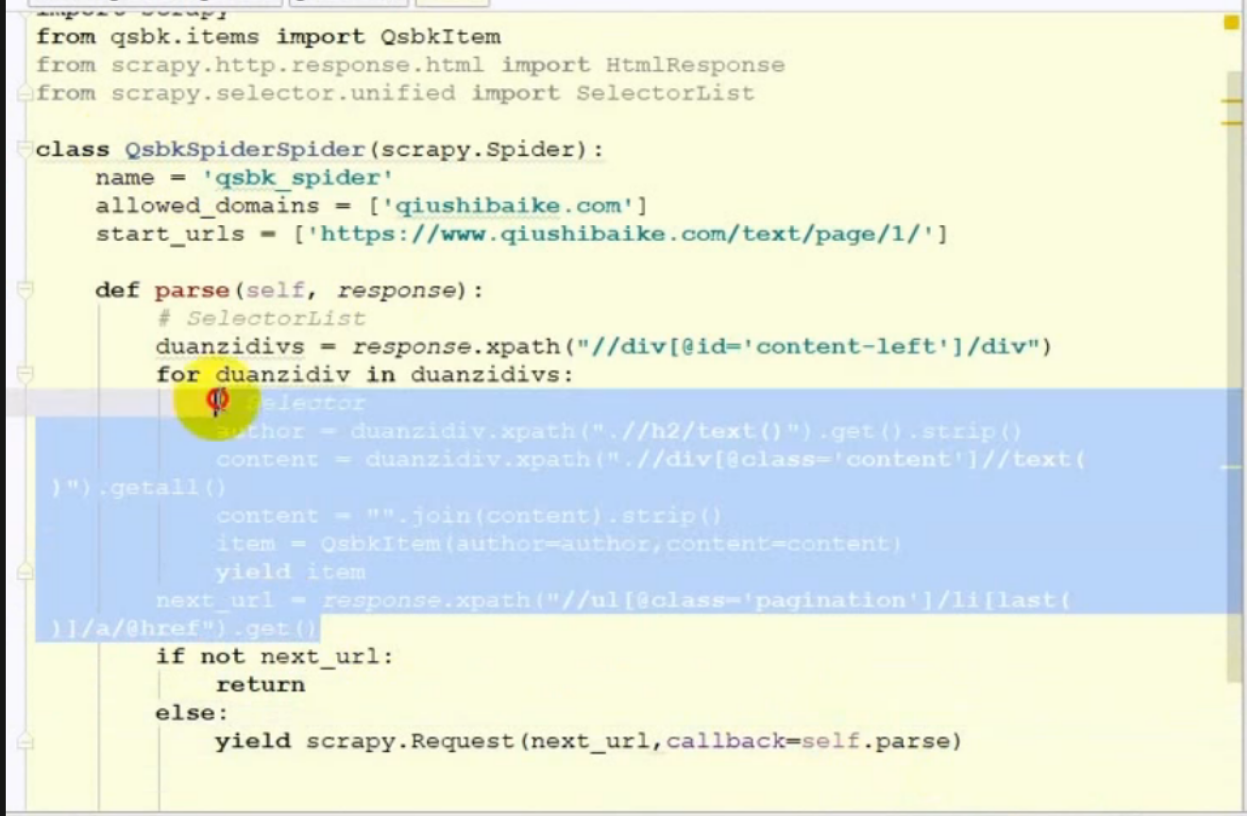
多个页面的请求之下一个页面
● 获取当前链接内容及下一个链接的内容方式:
○ 使用yield 返回当前页面的数据,当前页面的数据返回完成后(for 循环完成后) 再处理下一个链接的地址,使用 yield 返回下一个链接的请求结果.
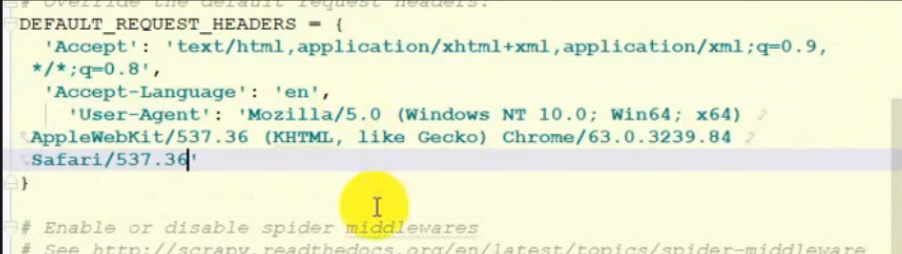
● 设置请求头:
○ 
● 设置管道操作:
ITEM_PIPELINES = {
'scrapy_rere.pipelines.ScrapyRerePipeline': 300,
}
● 管道的使用:
class ScrapyRerePipeline(object):
def __init__(self):
pass
def process_item(self, item, spider):
return item
def open_spider(self, spider):
pass
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
pass
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
crawlspider的使用
- crawlspider 创建方式:
![]()
● 比spider要高级,可以定义规则自动爬取页面中的链接
● 规则为链接的正则表达式
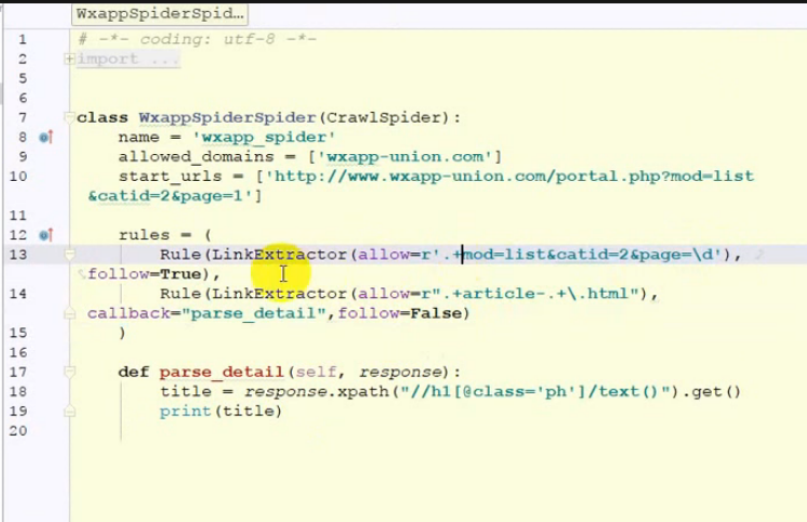
代码分析:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy.http.response.html import HtmlResponse
from scrapy.selector.unified import SelectorList
class RereCrawlSpider(CrawlSpider):
name = 'rere_crawl'
allowed_domains = ['rereapi.com']
start_urls = ['https://api.rereapi.com/?m=vod-index-pg-1.html']
rules = (
Rule(LinkExtractor(allow=r'.+m=vod-index-pg-\d+\.html'), callback='parse_item', follow=True),
Rule(LinkExtractor(allow=r'.+m=vod-detail-id-\d+\.html'), callback='parse_item1', follow=False),
)
def parse_item(self, response):
# response HtmlResponse 对象
# res 是SelectorList
if isinstance(response,HtmlResponse):
res = response.css('.xing_vb4>a::attr(href)')
print(res.extract())
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
def parse_item1(self,response):
if isinstance(response,HtmlResponse):
res = response.css('div.vodh>h2::text')
print(res.extract())
return {}
- css 选择器怎样定位到元素的属性值:
答案:
例如res = response.css('.xing_vb4>a::attr(href)') - css 选择器怎样获取元素中的文本值:
答案:
例子:res = response.css('div.vodh>h2::text')
scrapy shell 命令可以再任意位置执行
- 执行命令:
scrapy shell 'http://www.baidu.com/'
-
如果要要读取项目中的配置文件,则需要在项目文件夹中执行该命令.
-
在爬取数据是需要登陆了的情况下需要先重写
start_request方法,并且回调callback指定的函数,调用其他的请求方法
模拟登录请求可以使用引入类formrequest可以方便提交
图片和文件的爬虫:

-
修改setting 中的
ITEM_PIPLINE,设置完成后将不会执行原有的pipline 中的方法.
![]()
-
设置图片存储路径:
![]()
-
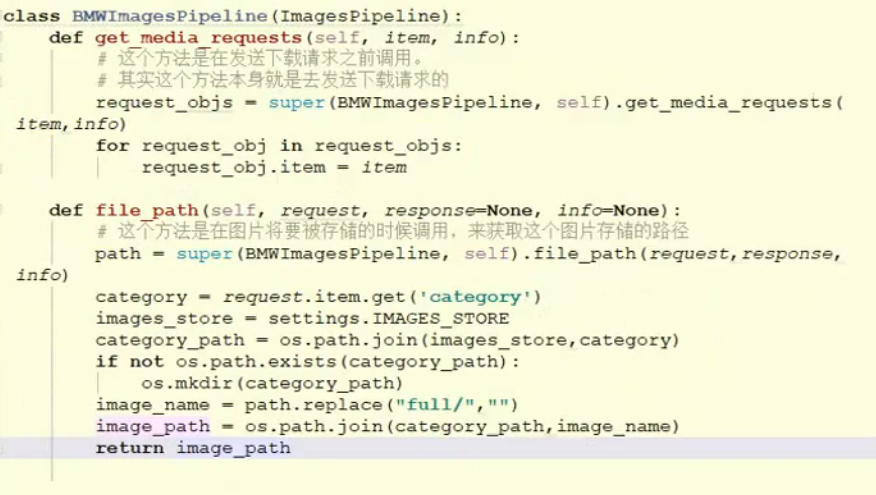
pipline 图片下载方法重写,假如要更该图片存储结构:
导入类:
![]()
-
重写方法,重点是获取item 中的数据的方式:
![]()
-
在settting 中声明要调用的类:
![]()




*自动添加https:

中间件:
-
流程图:
![]()
-
process_request 的处理逻辑:
在未接收到response 之前不会返回engine
![]()
-
process_response 处理逻辑:
![]()


随机请求头中间件:
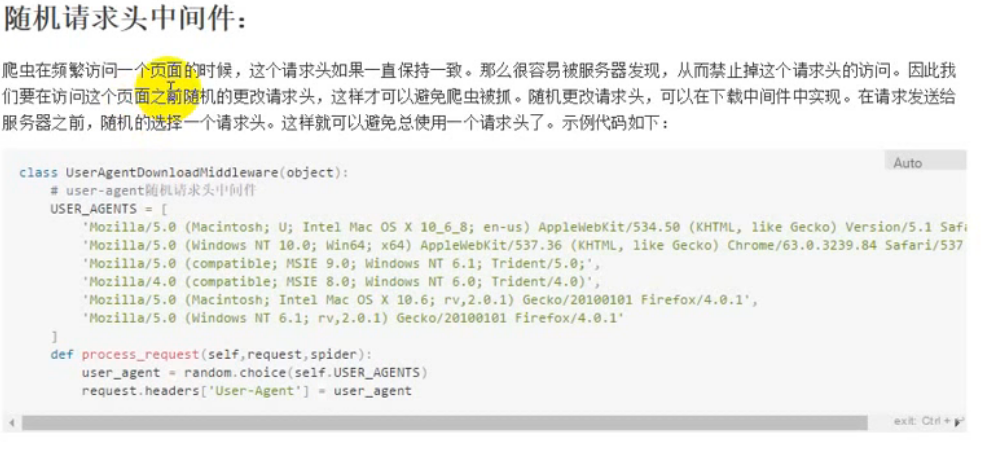
-
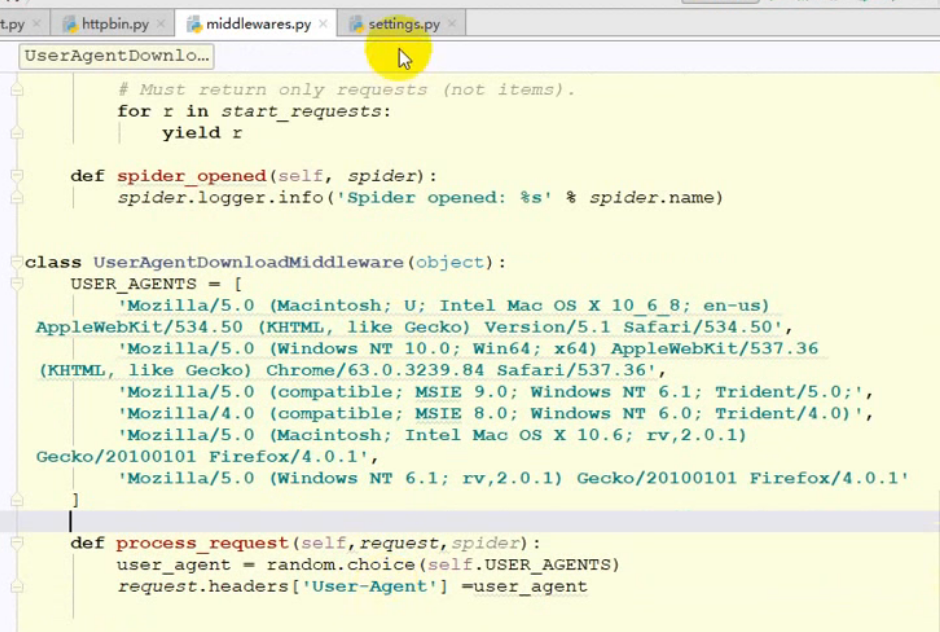
随机请求头设置位置:
![]()
-
随机请求头需要在settting中声明:
![]()
-
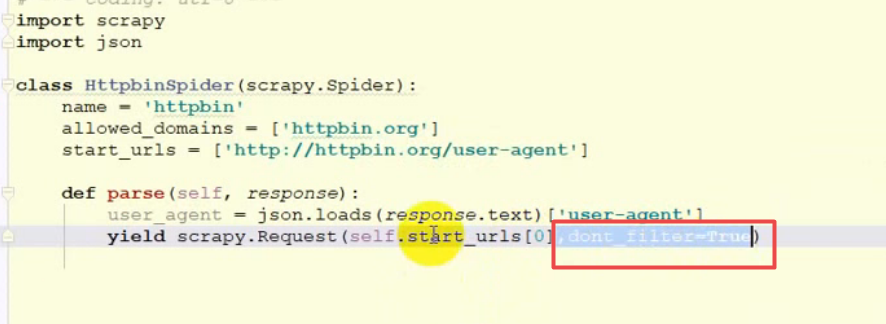
dont_filter去重复的功能:
如果要重复发送某一个请求的话,需要在请求时设置为False,
![]()
但是如果设置为False 之后就会一直请求不会停下来. -
IP代理的设置:
![]()
-
IP 代理传递账户密码:
![]()



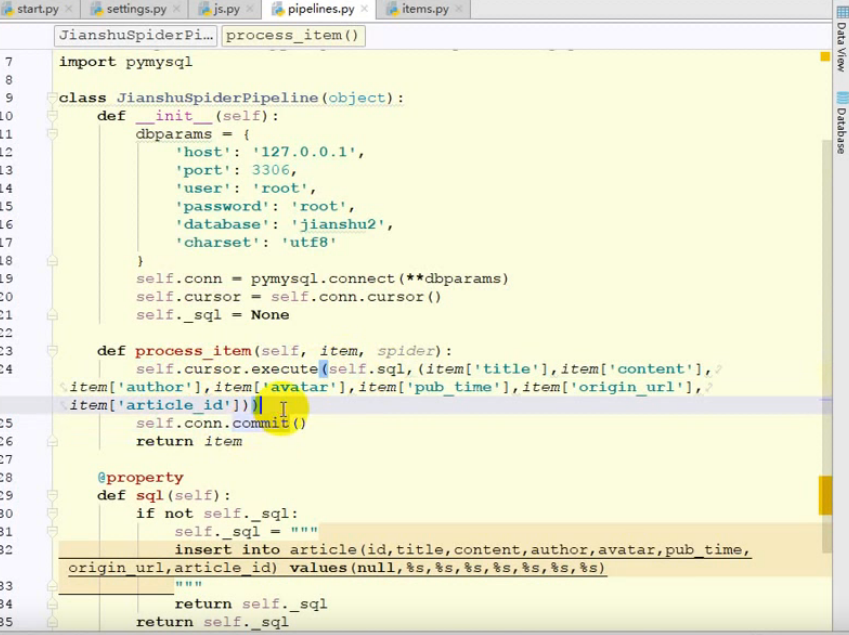
将数据写入到数据库:
-
非异步方式写入到数据库中:
![]()
-
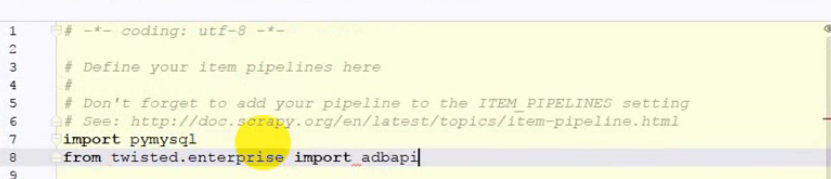
异步写入到数据库中:Twisted
![]()
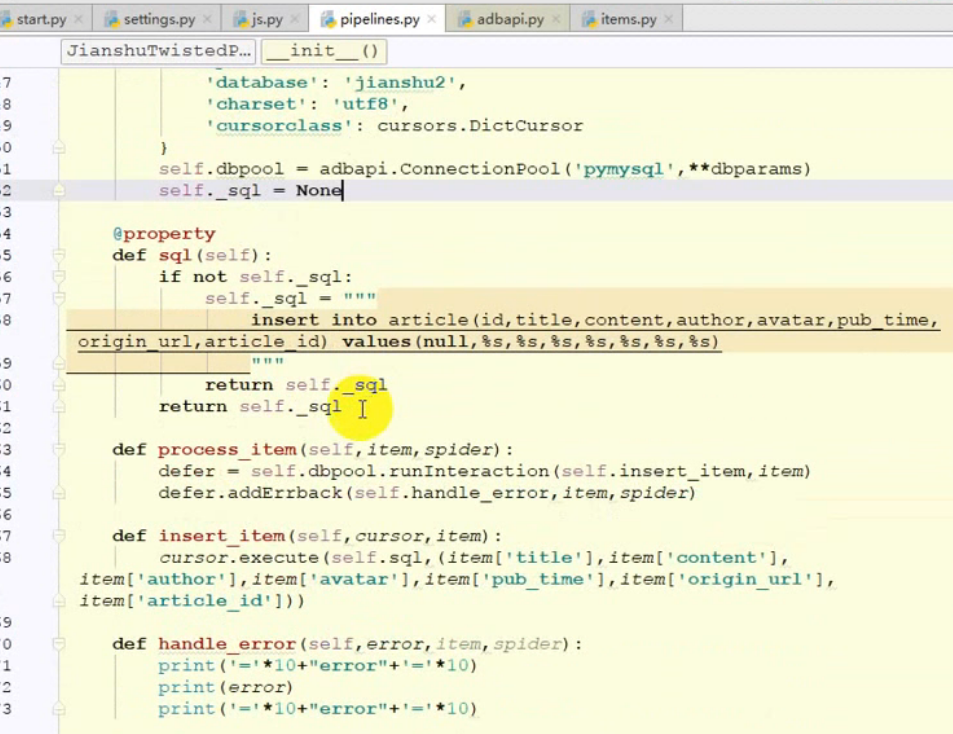
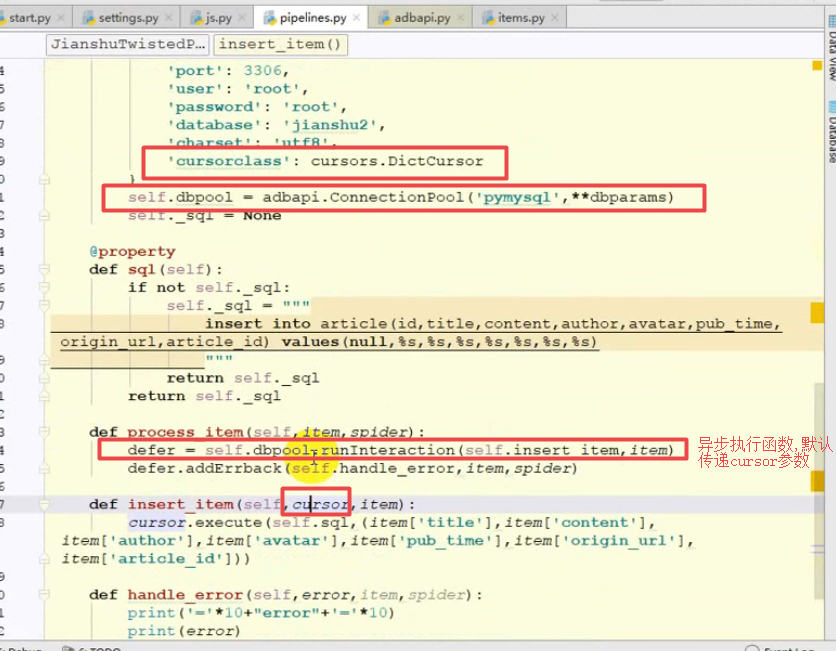
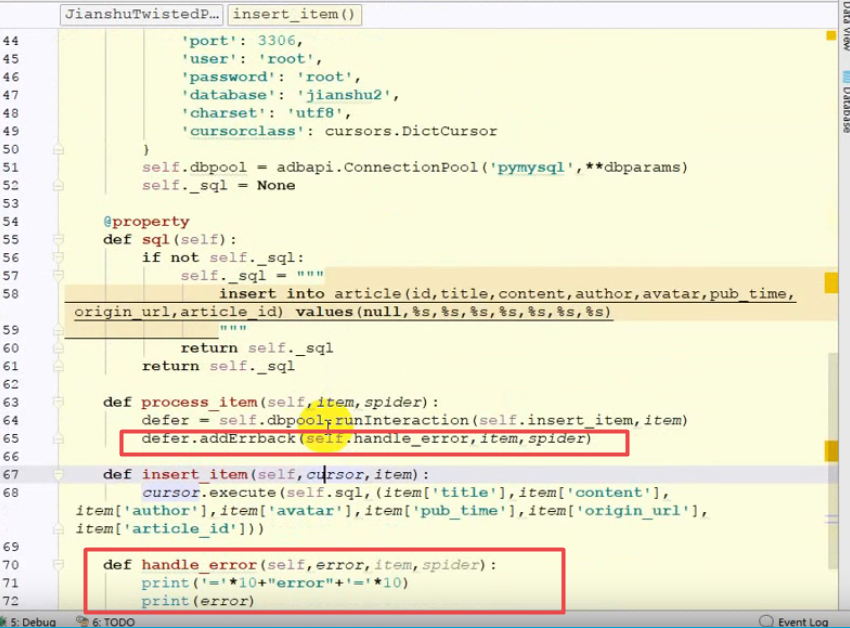
- 发生错误时函数处理:
![]()
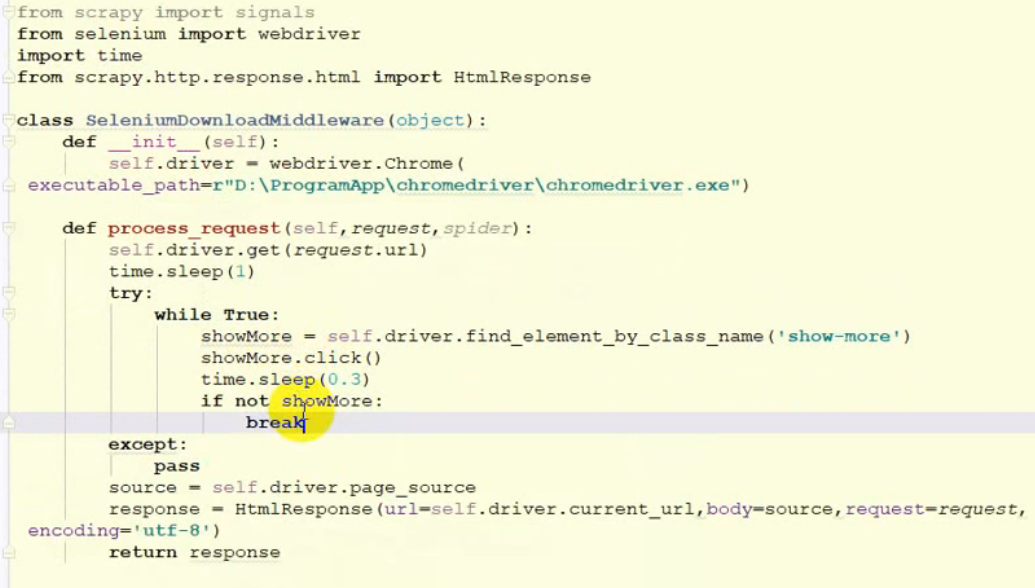
获取ajax 请求的数据:
- 使用selenium 模拟浏览器请求数据,在数据请求过程中,会将浏览器打开,并可视化操作,selenium 在中间件中操作.
![]()
- 利用selenium 请求数据可以忽略Ajax请求,因为Ajax请求直接使用浏览器请求完成了.
- selenium 在调用浏览器的时候,谷歌浏览器打开后没有反应,网上说是没有安装驱动之类的,后来更换了火狐,就可以使用,
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.expected_conditions import presence_of_element_located
# # This example requires Selenium WebDriver 3.13 or newer
def func():
with webdriver.Firefox as driver:
wait = WebDriverWait(driver, 10)
driver.get("https://www.baidu.com/")
driver.find_element(By.ID, "").send_keys("cheese" + Keys.RETURN)
first_result = wait.until(presence_of_element_located(By.CSS_SELECTOR, "body"))
print(first_result.get_attribute("textContent"))
https://github.com/SeleniumHQ/selenium/wiki/InternetExplorerDriver
- selenium 提高爬取效率:
可以将浏览器设置为无图模式,例如火狐的无图模式设置:
1、在地址栏输入about:config,打开设置。
2、将permissions.default.image项设置为2。
分布式爬虫:
scrapy-redis
-
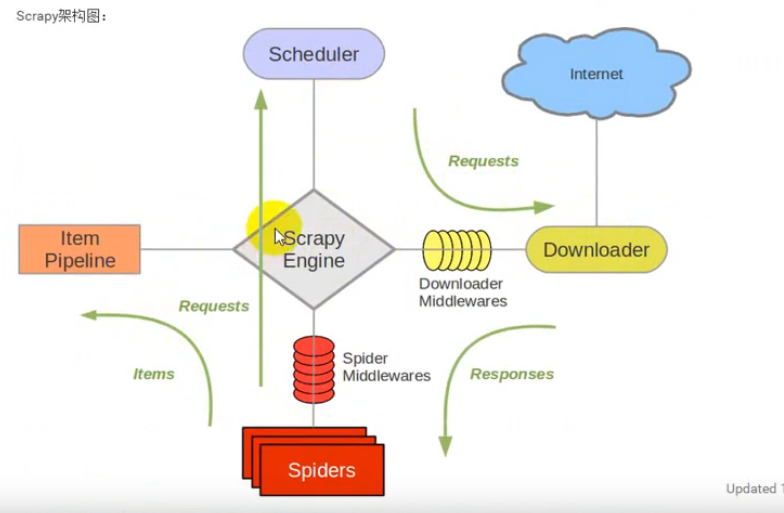
scrapy 架构图:
![]()
-
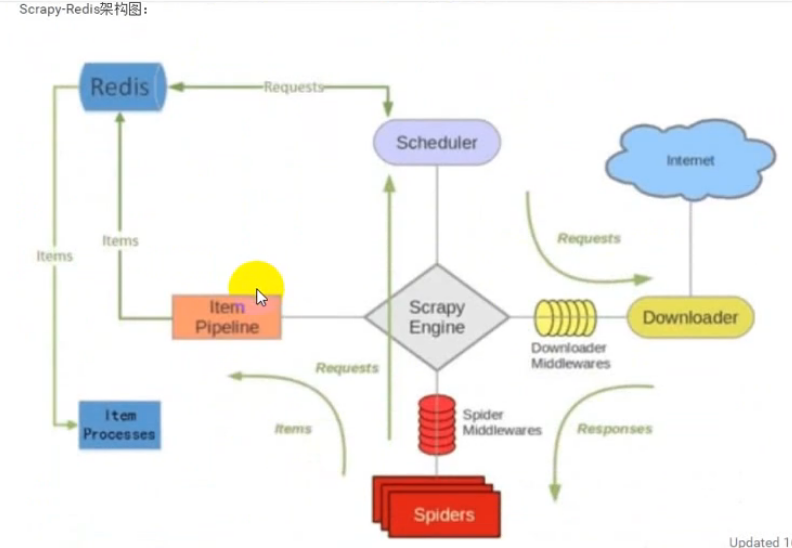
scrapy-redis架构图:
![]()
-
scrapy-redis 服务器:
![]()
-
房天下爬虫的获取到城市的地址后处理,调用其他函数,并传值,通过
meta传值:
![]()


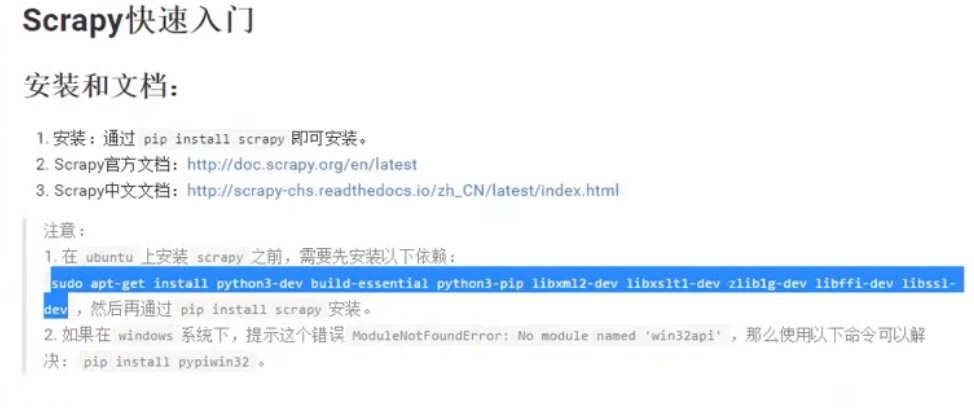
scrapy 安装:
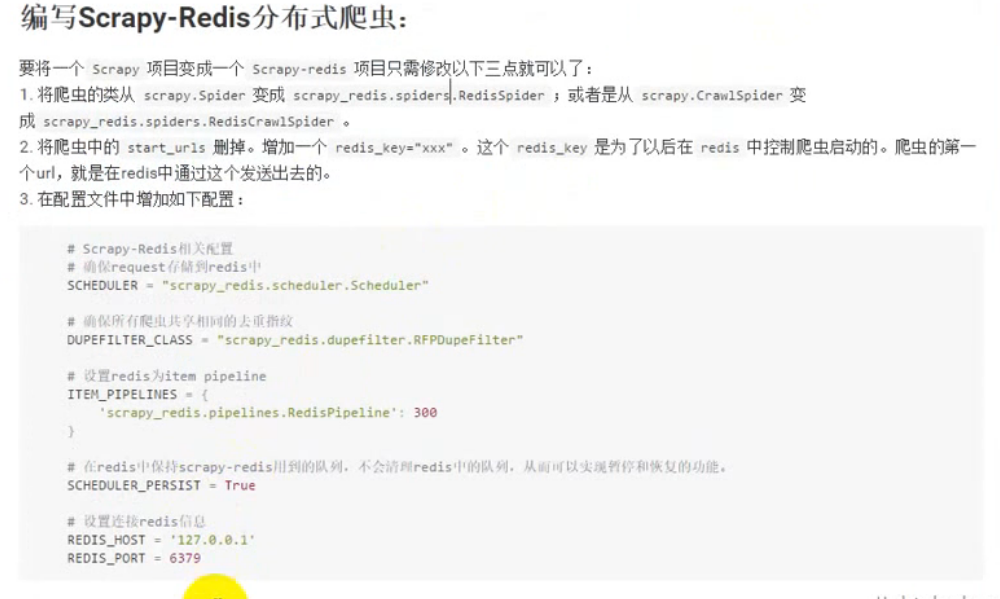
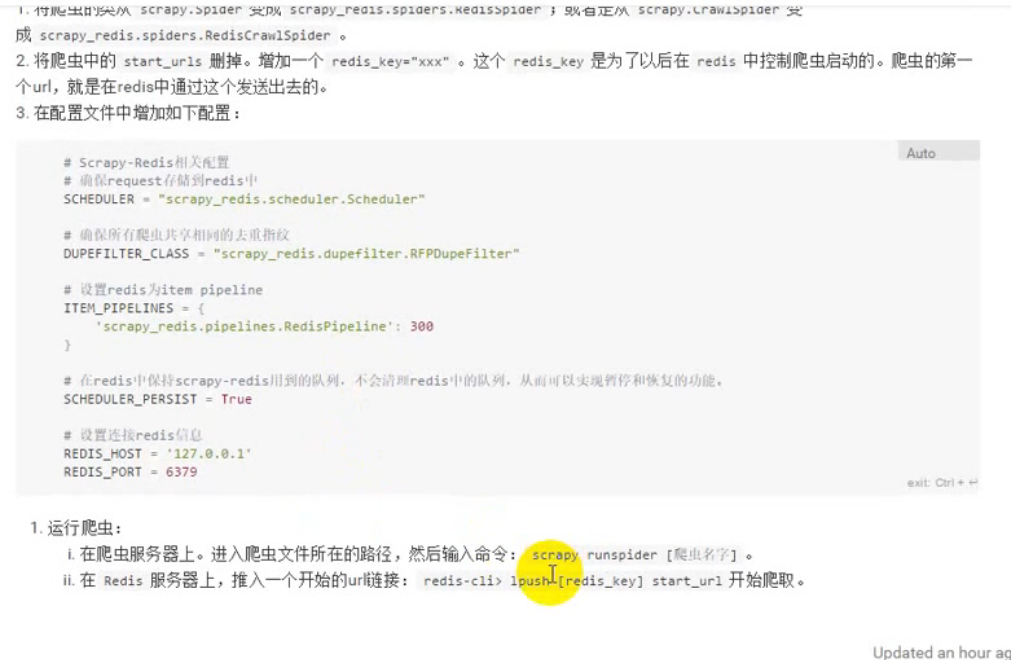
将项目变为分布式爬虫:
-
分布式爬虫服务启动:
![]()
-
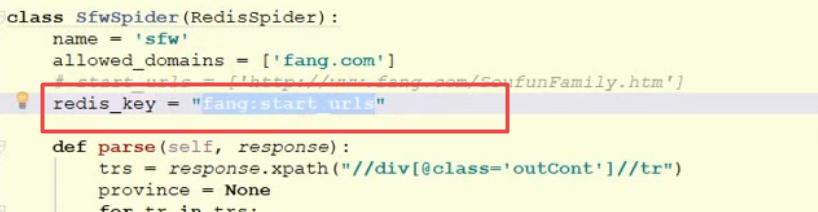
redis_key 设置:
![]()
-
向redis服务中推入开始链接:
![]()
-
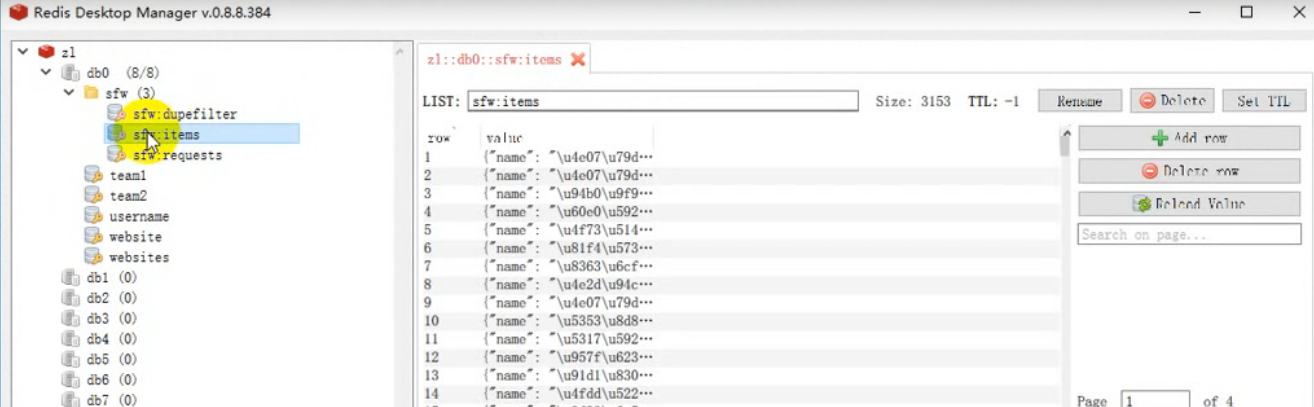
redis 服务器的数据结构:
![]()


本文来自博客园,作者:那时一个人,转载请注明原文链接:https://www.cnblogs.com/qianxunman/p/13193194.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号