


全文检索技术
支持海量全文检索,索引库中查询,速度快
查询算法
顺序扫描法
- 概念:根据关键字,从头到尾扫描+匹配,直到扫描完所有文件;
- 优点:查询准确率高
- 缺点:查询速度随着查询数据量的增大,越来越慢
- 使用场景:数据库中的 like 关键字模糊查询(全表扫描,加索引也没用)、文本编辑器的 Ctrl + F 查询功能
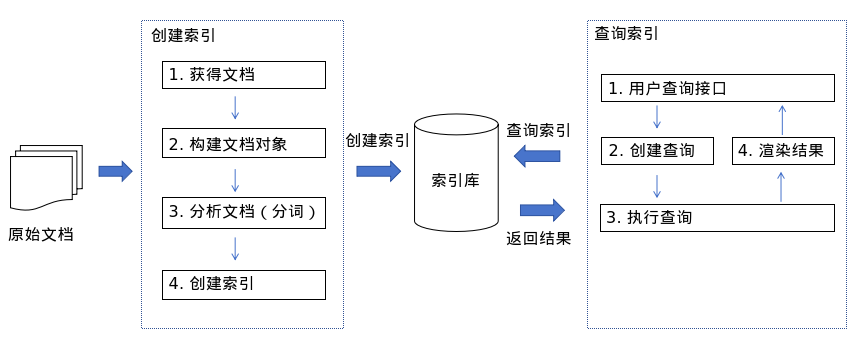
全文检索(倒排索引)
对文档进行切分词组成索引(目录),索引和文档有关联关系,查询的时候先查询索引,通过索引找文档。
切分词:将一句话切分成一个一个的词,去掉停用词、去掉重复词、去掉标点符号
Lucene
Lucene是一个开放源代码的全文检索引擎工具包(一个 jar包,不能单独部署和运行),不是完整的全文检索引擎。Lucene能够为文本类型的数据建立索引,把创建好的索引文件保存到磁盘或者内存中,并根据用户输入的查询条件在索引文件上进行查询。
Solr
Solr 是 Apache 旗下基于 Lucene 开发的全文检索的服务。用户可以通过 HTTP 请求,向 Solr 服务器提交一定格式的数据,完成索引库的索引;也可以通过 HTTP 请求查询索引库获取返回结果。
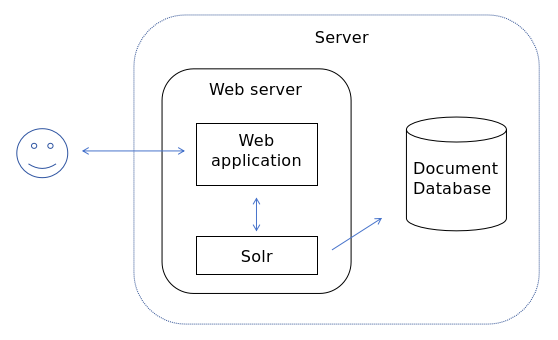
功能优势:支持各种格式文件导入索引库、分页查询和排序、Group分组查询、Solr Cloud(集群搭建,支持并发)。
Elasticsearch
和 Lucene 的关系
基于 Lucene,封装了许多 Lunece 底层功能,提供简单易用的 Restful API 接口和许多语言的客户端,如 Java 的高级客户端(Java High Level REST Client)和底层客户端(Java Low level Rest Client)。
功能
- 分布式的搜索引擎和数据分析引擎
- 全文检索,结构化检索,数据分析
- 对海量数据(上亿条)进行近实时(秒级)的处理
核心概念
- NRT(Near Realtime):近实时,秒级
- Cluster:集群
- Node:节点,每个 ES 实例
- Document:文档,ES中的最小数据单元,多个 Document 存储于一个索引中
- Index:索引,包含一堆有相似结构的文档数据,相当于表
- Field:字段
- Type:类型,ES官方将在ES9.0后删除此概念
- shard:分片
- replica:副本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号