

摘要
引入了YOLO World,这是一种创新的方法,通过视觉语言建模和大规模数据集的预训练,增强了YOLO的开放词汇检测能力。提出了一种新的可重新参数化的视觉语言路径聚合网络(RepVL-PAN)和区域文本对比损失,以促进视觉和语言信息之间的交互。
引言
现有的方法有两个问题:
- 计算负担重
- 边缘设备的部署复杂
本文提出了YOLO World,旨在实现高效的开放词汇对象检测,并探索了大规模的预训练方案,将传统的YOLO检测器提升到一个新的开放词汇世界。具体来说,YOLO World遵循标准的YOLO架构,并利用预训练的CLIP文本编码器对输入文本进行编码。并进一步提出了可重新参数化的视觉语言路径聚合网络(RepVL-PAN),将文本特征和图像特征连接起来,以获得更好的视觉语义表示。在推理过程中,可以移除文本编码器,并将文本嵌入重新参数化为RepVL-PAN的权重,以实现高效部署。
此外还探索了prompt-then-detect范式。
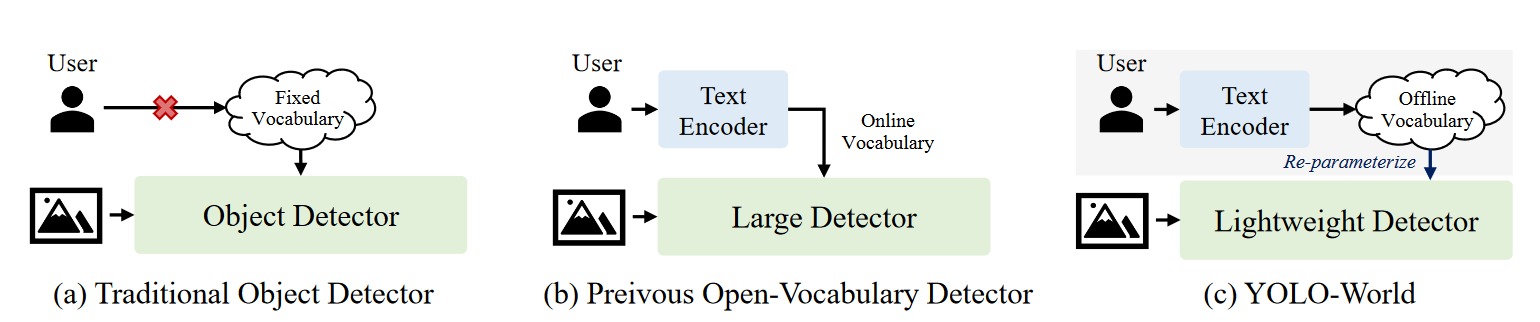
传统的物体检测器,专注于检测固定词汇检测。
先前的开放词汇检测器同时对文本和图像进行编码,十分耗时,但是检测器倾向于带有重型骨干网络的检测器。
prompt-then-detect检测范式首先对用户的提示进行编码,以构建离线词汇表,词汇表因不同需求而异。然后,高效的检测器可以在不重新编码提示的情况下动态推断离线词汇。
主要贡献总结为三方面:
- 提出了YOLO World。
- 提出了可重新参数化的视觉语言路径聚合网络(RepVL-PAN)。
- 所提出的YOLO-World在大规模数据集上进行预训练,表现出强大的零样本性能。
Method
预训练模式:区域文本对
传统的对象检测方法,包括YOLO系列,都是使用实例注释\(\Omega=\{B_i,c_i\}_{i=1}^N\),\(B_i\)为预测框,\(c_i\)为类别标签。在这篇论文中提出了region-text pairs \(\Omega=\{B_i,t_i\}_{i=1}^N\) ,\(t_i\)为区域\(B_i\)对应文本。具体来说,文本\(t_i\)可以是类别名称、名词短语或对象描述。YOLO World采用图像 \(I\) and 文本\(T\)(一组名词),然后输出预测框\(\{\hat{B_k}\}\)以及对应的对象嵌入\(\{e_k\}(e_k\in\mathbb{R}^D)\)。
模型架构
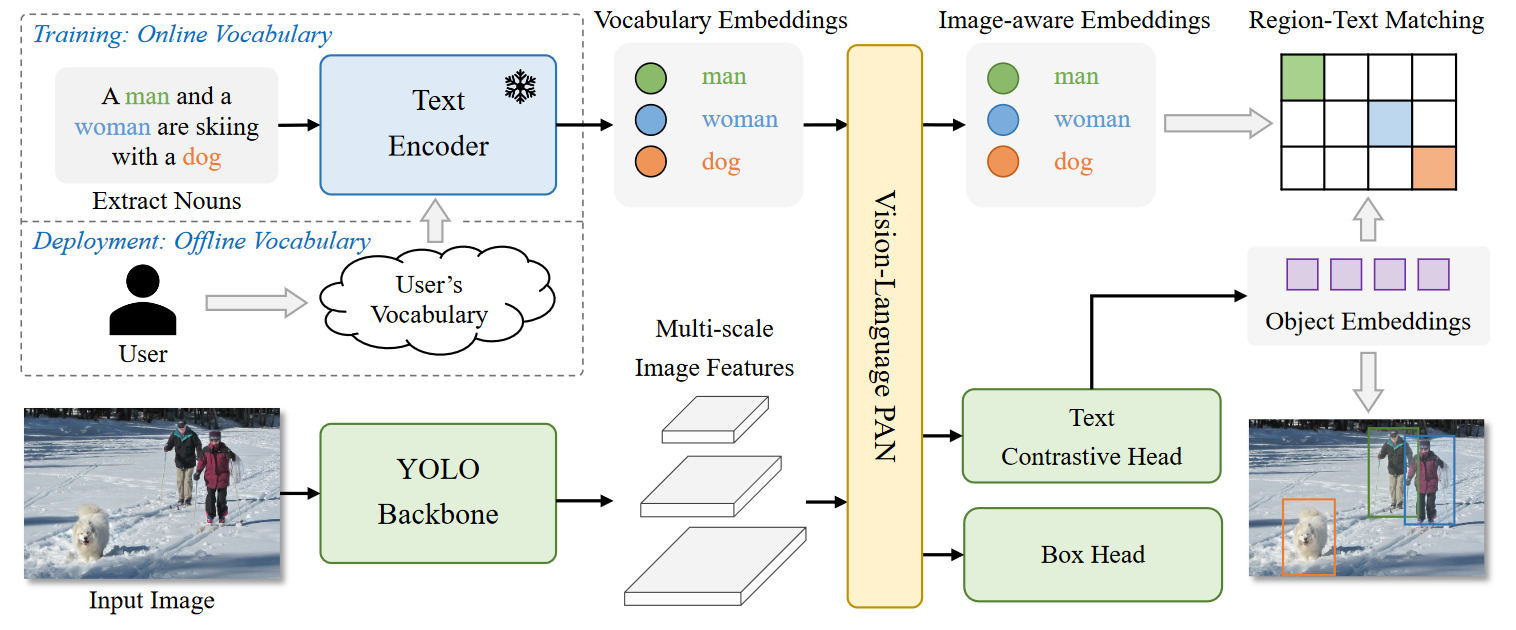
总体架构由YOLO检测器、文本编码器和可重新参数化的视觉语言路径聚合网络(RepVL-PAN)组成。
给定输入文本,YOLO World的文本编码器会把文本编码为文本嵌入。
YOLO对图像进行多尺度的特征提取。
然后使用RepVL-PAN利用图像特征和文本嵌入之间的跨模态融合来增强文本和图像表示。
YOLO Detector
主要基于YOLOv8开发,一个作为图像编码器的Darknet backbone,一个用于多尺度特征金字塔的path aggregation network (PAN),一个用于边界框回归和对象嵌入的头部。
Text Contrastive Head
根据之前工作,本文使用了带有两个3x3卷积的解耦头去回归预测框\(\{b_k\}^K_{k=1}\)和对象嵌入\(\{e_k\}_{k=1}^K\),\(K\)代表的是对象的个数。
同时提出了text contrastive head去获得object-text的相似度\(s_{k,j}\)。
\(s_{k,j}=\alpha \cdot L2—Norm(e_k) \cdot L2—Norm(w_j)^⊤+\beta\)
L2-Norm(·)表示L2归一化,\(w_j\in W\)表示第\(j\)个文本嵌入,还添加了仿射变换以及可学习的缩放因子\(\alpha\)和移位因子\(\beta\)。
Training with Online Vocabulary(使用在线词汇表训练)
在训练过程中,为每个包含4张图片的掩码样本构建了一个在线词汇表\(T\)。具体来说,对每个掩码图像涉及的 positive nouns进行采样,并从相应数据集中随机采样一些negative nouns。每个掩码图像最多有\(M\)个名词,\(M\)默认是80个。
Inference with Offline Vocabulary(使用离线词汇表推理)
在推理阶段,使用prompt-then-detect策略,编码器对用户的prompt进行编码,并且获得离线词汇表的嵌入。
Re-parameterizable Vision-Language PAN
该结构遵循自上而下和自下而上的路径,以建立具有多尺度图像特征\(\{C3,C4,C5\}\)的特征金字塔\(\{P3,P4,P5\}\)。此外还提出了Text-guided CSPLayer (T-CSPLayer) 以及Image-Pooling Attention (I-Pooling Attention) 以进一步增强图像特征和文本特征之间的交互,从而提高开放词汇能力的视觉语义表示。推理过程中,离线词汇嵌入可以重新参数化为卷积层或线性层的权重以供部署。
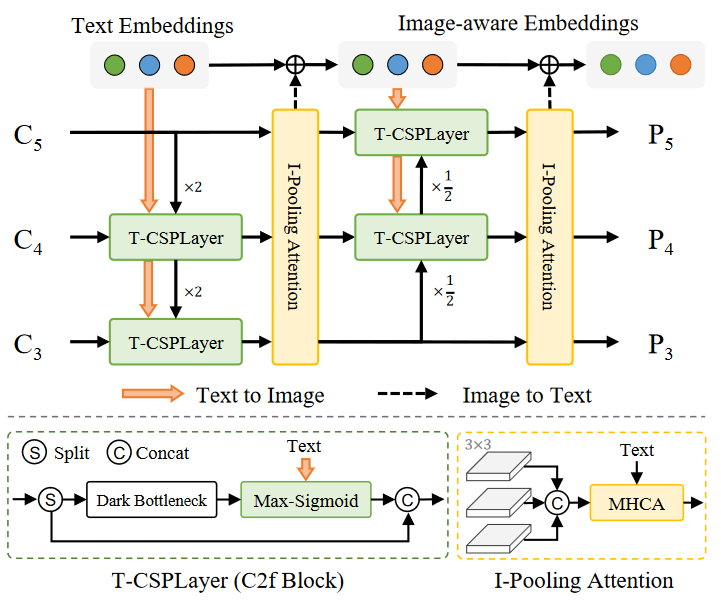
Text-guided CSPLayer
crossstage partial layers (CSPLayer),在top-down 和 bottom-up 融合后使用。同时拓展了CSPLayer,将文本引导融入多尺度图像特征中,形成Text-guided CSPLayer。具体来说给文本嵌入向量\(W\)和图像特征\(X_l\in \mathbb{R}^{H \times W \times D},(l\in\{3,4,5\})\),在 最后一个dark bottleneck block使用max-sigmoid attention把文本特征融入图像特征通过这个公式:
\(X^{'}_{l}=X_l \cdot \delta(max(X_lW^⊤_{j}))^⊤,j\in\{1...C\}\)
\(X^{'}_{l}\)作为与跨级特征连接的输出,\(\delta\)表示sigmoid函数。
Image-Pooling Attention
为了增强具有图像感知信息的文本嵌入,提出了用Image-Pooling Attention来聚合图像特征来更新文本嵌入。
没有对图像特征直接使用cross-attention,而是在多尺度特征使用最大值池化来获得3x3的regions,最后有27个patch tokens\(\tilde{X}\in \mathbb{R}^{27\times D}\),随后文本嵌入由这个公式更新:
$W^{'}=W + MultiHead-Attention(W,\tilde{X},\tilde{X}) $
预训练方案
Learning from Region-Text Contrastive Loss
给定 mosaic sample \(I\)和 texts \(T\), YOLO-World输出\(K\)个目标预测\(\{B_k,s_k\}^K_{k=1}\)以及注释\(\Omega=\{B_i,t_i\}^N_{i=1}\),这里遵循YOLOv8以及利用task-aligned label assignment去把预测和注释对齐,并且给每个正向的预测分配一个text index作为类别标签。基于这些词汇,通过between object-text (region-text) similarity 和 object-text assignments的交叉熵构建了一个region-text contrastive loss \(L_{con}\)我们采用IoU损失和分布式焦损进行边界框回归,总训练损失定义为:
\(L(I)=L_{con}+\lambda_I \cdot (L_{iou}+L_{dfl})\)
\(\lambda_I\)是一个指示因子,当输入图像\(I\)为detection或者grounding data设置为1,当image-text数据式,设置为0。考虑到图像文本数据集具有噪声框,我们只计算具有精确边界框的样本的回归损失。
Pseudo Labeling with Image-Text Data
一种自动标记方法来生成区域文本对,而不是直接使用图像文本对进行预训练。
具体由三个步骤:
- 提取名词短语:我们首先利用n-gram算法从文本中提取名词短语。
- 伪标记:们采用预训练的开放词汇检测器,例如GLIP,为每个图像的给定名词短语生成伪框,从而提供粗略的区域文本对。
- 过滤:我们使用预训练的CLIP来评估图像文本对和区域文本对的相关性,并过滤低相关性的伪注释和图像。再用NMS进一步过滤。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号