
pandas的concat和drop函数
pandas的concat函数用于连接两个DataFrame数据,drop函数用于删除DataFrame数据中的行或者列。
首先导入需要的库 pandas和numpy:
import pandas as pd import numpy as np
1. 创建DataFrame,可以使用数组或者列表、字典来创建数据
df_1 = pd.DataFrame([['Jack','M',40],['Tony','M',20],['Mary','F',30],['Bob','M',25]], columns=['name','gender','age']) #列表创建DataFrame print('------ df_1是: ------') print(df_1) df_2 = pd.DataFrame(np.arange(16).reshape((4, 4)), index = ['aa', 'bb', 'cc', 'dd'], columns = ['c1', 'c2', 'c3', 'c4']) #数组创建DataFrame print('------ df_2是: ------') print(df_2) array_test = np.array([[1,2,3,4],[2,3,4,5],[3,4,5,6]]) df_3 = pd.DataFrame(array_test, index = ['aa', 'bb', 'ff'], columns = ['c1', 'c2', 'c3', 'c4']) #数组创建DataFrame print('------ df_3是: ------') print(df_3) dict_test = {'c1':[1,2,3,4],'c2':[2,3,4,5],'c3':[3,4,5,6]} df_20 = pd.DataFrame(dict_test) #字典创建DataFrame print('------ df_20是: ------') print(df_20)


2. 也可创建一个序列Series
s_1 = pd.Series(np.arange(4),index= ['aa','bb','cc','dd']) print('------ s_1是: ------') print(s_1)

3. concat :连接多个DataFrame,axis=0 表示按行连接,即在行的方向上进行扩充连接,axis=1表示按列连接,即在列的方向上进行扩充连接;ignore_index表示连接数据忽略之前的索引,统一使用新的索引;join默认值是'outer';axis=0时,下面的结果中没有NaN值表示两者的列名一致
df_4 = pd.concat([df_2, df_3], axis=0, ignore_index=True) print('------ df_4是: ------') print(df_4)

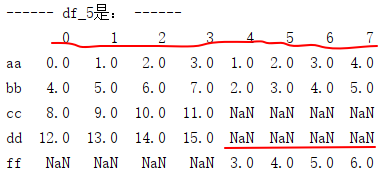
4. concat:axis=1表示列连接,即在列的维度上进行连接,join默认值是'outer',表示默认外连接,类似于sql;按列连接时,相同行名称的直接连接,不同行名称时用NaN填充:
df_5 = pd.concat([df_2, df_3], axis=1, ignore_index=True, sort=False) print('------ df_5是: ------') print(df_5)
5. concat:ignore_index=False均表示保留之前的索引
df_6 = pd.concat([df_2, df_3], axis=1, ignore_index=False, sort=False) print('------ df_6是: ------') print(df_6)

6. concat:join='inner'表示内连接,只会保留两者均有的索引行/列
df_7 = pd.concat([df_2, df_3], axis=1, join='inner', ignore_index=False, sort=False) print('------ df_7是: ------') print(df_7)

7. drop:删除其中某几行/列,labels表示要删掉的行索引或者列名,必须是已存在的;axis=0表示按行
df_8 = df_2.drop(labels=['bb'], axis=0) #直接drop时,索引会有缺失,特别是当数字作为索引时,删除中间的索引行容易造成读取错误 print('------ df_8是: ------') print(df_8)

注:直接drop时,索引会有缺失,特别是当数字作为索引时,删除中间的索引行容易造成读取错误
8. drop:删除行时,reset_index会重建新索引
df_9 = df_2.drop(labels=['bb'], axis=0).reset_index(drop=True) print('------ df_9是: ------') print(df_9)

9. drop:删除列,类似;axis=1表示按列
df_10 = df_2.drop(labels=['c3'], axis=1) print('------ df_10是: ------') print(df_10)

10. drop:method='bfill' 表示用后面的值向前面填充(否则会用NaN值填充),reindex用于重建索引
df_11 = df_2.drop(labels=['c3'], axis=1).reindex(columns=['c1','c2','c3','c4'], method='bfill') print('------ df_11是: ------') print(df_11)

11. drop:method='ffill'表示用前面的值向后面填充
df_12 = df_2.drop(labels=['c3'], axis=1).reindex(columns=['c1','c2','c3','c4'], method='ffill') print('------ df_12是: ------') print(df_12)

12. drop:fill_value=0表示用0值填充
df_13 = df_2.drop(labels=['c3'], axis=1).reindex(columns=['c1','c2','c3','c4'], fill_value=0) print('------ df_13是: ------') print(df_13)

##
参考:
https://jingyan.baidu.com/article/91f5db1b79205a1c7f05e3ae.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号