

初了解es机制
引子
你是一位读书达人,这天旅游来到了恶州,发现了两座大图书馆,兴趣来潮想要去借本书读一读😍,于是你先进入了M馆,向前台小姐姐询问《鲁氏限流:从入门到入土》这本书的位置,小姐姐给了你一串神秘数字,并告诉你这是书的编号,从眼前开始数,数到这个编号就找到了。偶买噶,听到这个消息你直接惊掉了下巴😨,无奈你离开了它不回头看一眼,转身就进入了E馆,E馆的图书管理员就很高效了,直接告诉了你关于限流的书在第几层哪个书架,不多时你就找到了,并给了一个大大的好评❤️。
而这就是mysql与es的区别了。
说到es,我们知道它能储存数据,是个数据库,那么就回想一下已经学过的数据库吧。
| 关系型数据库 | 非关系型数据库 | |
|---|---|---|
| mysql,PostgreSQL | redis,mongodb,Elasticsearch |
什么是es
什么是elasticsearch?
- 一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能
什么是elastic stack(ELK)?
- 是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
什么是Lucene?
- 是Apache的开源搜索引擎类库,提供了搜索引擎的核心API。
从零开始的es发展史:
2010年2月8日, Shay Banon 发表了一篇博客,说他基于Lucene开发(封装 ???)了一个分布式搜索引擎,实现了一些功能。。。
就如引子中所展示的,在es之前,我们通过mysql和正则表达式来实现模糊搜索,如果搜索的字段是索引,那自然非常迅速,但如果是基于例如title做模糊查询,那么mysql会逐行扫描数据,判断是否符合条件,当数据量特别大时那将会是一场灾难。
倒排索引解决了这个困难,所谓倒排,是对于mysql的正排索引说的,这里有两个重要概念Document和Term,Document就是我们具有的数据,一行数据就是一个document,我们会根据分词器对document进行分词,分词后的一个个结果就是Term,然后按其对应的文本ID进行对应的字典序排序,排序后的整个结果就是我们所说的倒排索引。
但是数据是大量的,产生的倒排索引显然也很大,不可能将其放在内存,只能放在磁盘,但频繁通过查询磁盘显然会降低速度,这时就要引入term index了。
term index就是term前缀构成的目录树,比如term follow和forward ,我们可以把他们共同的前缀提取出来合并实现复用,指向下一部分,这些节点中储存对应倒排索引目标所在磁盘中的位置,这样就节省了很多空间,这就是term index,储存在内存中。
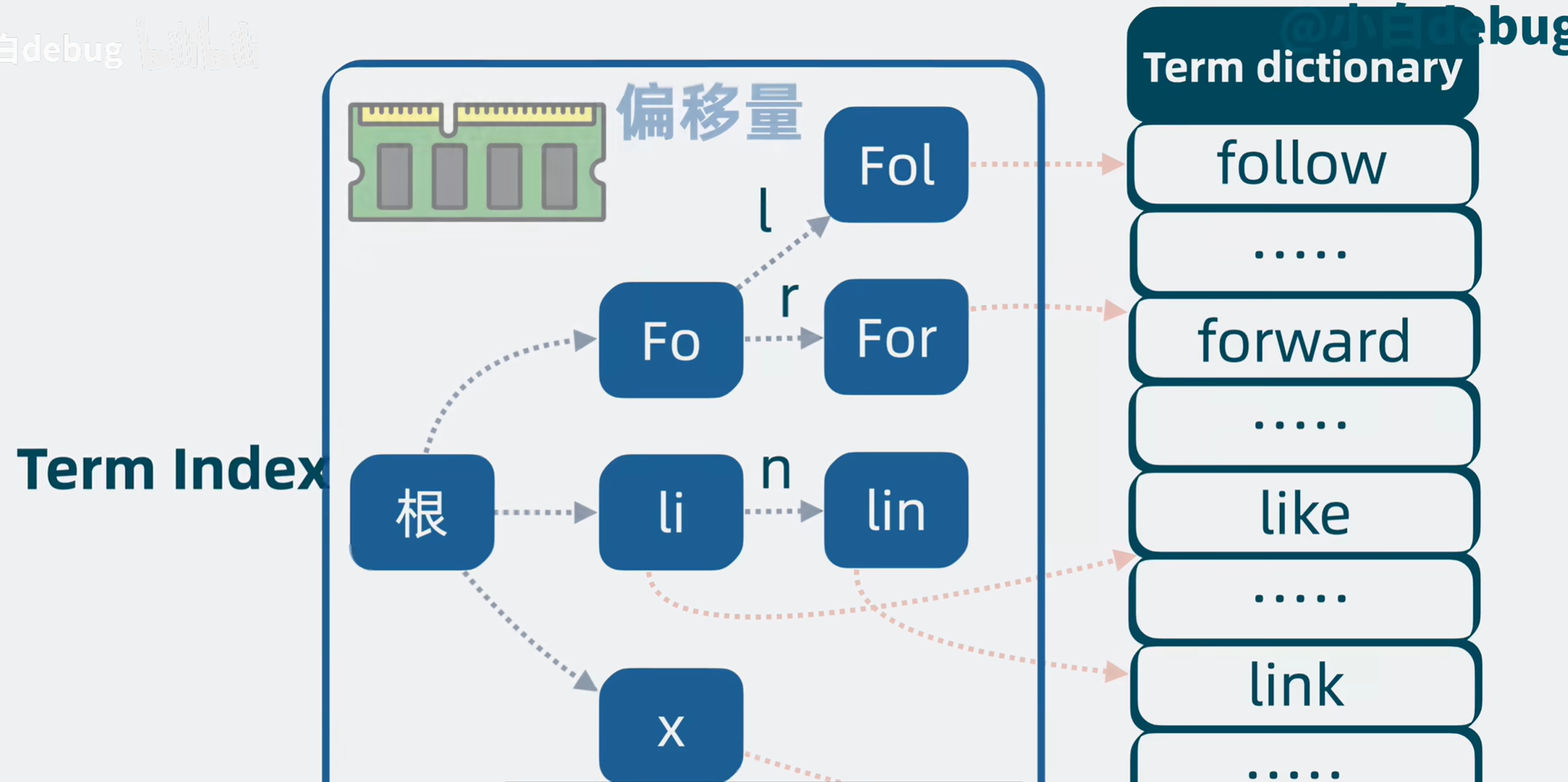
现在我们要查询比如包含手机的Title,就会通过目录树迅速查找到对应term,然后获取到文档id,进而拿到Store fields(文档内容)。
但是如果我们需要对某些字段进行排序怎么办,比如created time?这就要提到Doc Values ,我们会将某些字段如时间 集中存放,需要排序时就直接排序,这就是Doc Values。
哪些字段默认开启 doc values
默认规则如下:
| 字段类型 | 默认是否启用 doc values |
|---|---|
keyword |
✅ 是 |
date |
✅ 是 |
numeric(如 long, double) |
✅ 是 |
ip |
✅ 是 |
boolean |
✅ 是 |
text |
❌ 否(只建倒排索引) |
object, nested |
❌ 否 |
可以在创建索引时的 字段 mapping 中指定 doc_values: false,例如:
{
"mappings": {
"properties": {
"age": {
"type": "integer",
"doc_values": false
}
}
}
}
现在我们有了倒排索引快速搜索,term index放在内存迅速查找,Store fields储存内容,doc values便于排序,这四个组合在一起就是Lucene,但是我们发现,这个系统结构简单,高可用,高并发,高性能一个不沾,所以我们需要继续改造🙌。
当有多个调用方同时读写同一个Lucene时会导致阻塞等待,于是我们对写入Lucene的数据进行分类,每一类就是一个index name,分别写入不同的Lucene中,同时为避免index name数据过多,我们将数据宅分为多个shard分片,每一个分片是一个Lucene,这样就降低了单个Lucene的压力,提高了性能和并发能力。随着shard分片增多,我们可以把shard分片放在不同的机器上(即node 节点,缓解了单机cpu过高的问题),同时为保证高可用,我们可以给shard增添副本,分为primary shard和replica shard,primary shard会将数据同步给replica shard,在primary shard挂了后,replica shard还可升级为primary shard(并不是Raft选举,而是由master node决定)。
那什么是master node?就像上面提到的,我们会增加节点来缓解数据压力,但是如果每个节点都是既存数据又处理请求还帮助管理集群,这就很浪费了,所以我们将这些能力拆开,master node 负责管理集群,data node 负责储存数据,coordinate node 负责处理请求,在配置node时可以指定这个node的身份(不唯一),实现高可用。
综合起来这一大堆就组成了我们所说的es。
Logstash:日志的收集和分析、处理。
时代的大浪
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
通常,日志被分散的储存不同的设备上。
如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。
这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
随着服务容器化,跑在一台CentOS服务器上,服务器搭建了docker环境,安装了docker-compose或者k8s,但在日志处理方面,暂时没有一个好的方法能够收集完全的日志,
只能依赖进入至服务器后,以docker logs containerID的方法来进入查看,非常不方便,所以,基础日志平台就迫在眉睫。
Logstash是一个数据收集引擎,它可以动态的从各种数据源搜集数据,并对数据进行过滤、分析和统一格式等操作,并将输出结果存储到指定位置上。Logstash支持普通的日志文件和自定义Json格式的日志解析。
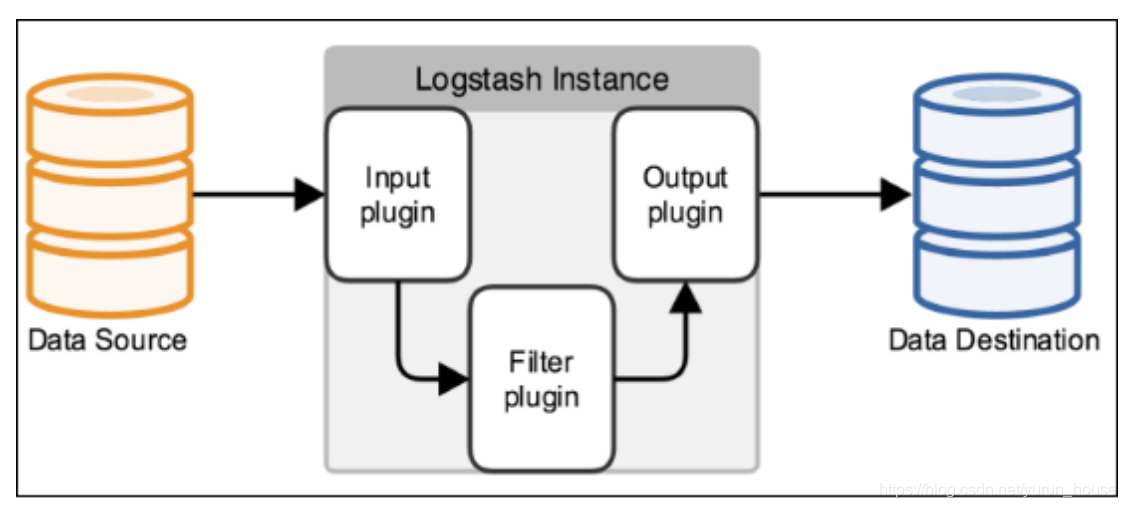
在logstash架构中,主要有三个插件:input:采集各种样式,大小和相关来源数据,从各个服务器中收集数据(进货的).
fliter:它可以对日志做清洗、格式化、结构化等操作(加工)。
output:将我们过滤出的数据保存到那些数据库和相关存储中(出口)。
可以看到Logstash就是一个超级加工厂,将各种原材料加工成可口的"食物",结合es作为加工后数据的存储系统,kibana作为ui界面来可视化分析数据,这一串就构成了伟大的ELK.
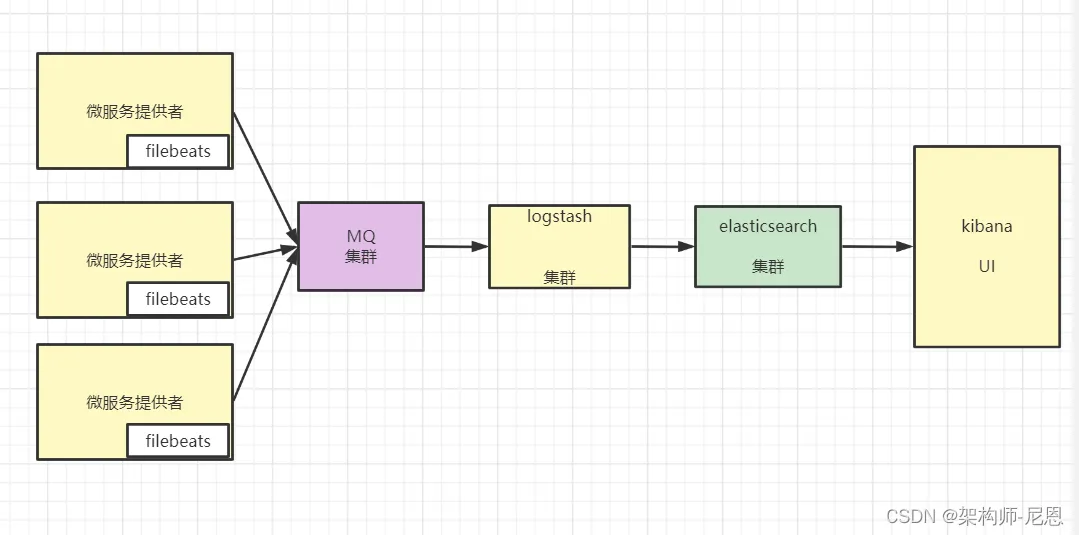
如上图所示,filebeats 安装在各个设备上,用于收集日志信息,收集到的日志信息统一汇总到Elasticsearch上,然后由Kibana负责web端的展示。
其中,如果终端设备过多,会导致logstash 过载的现象,此时,我们可以采用一台 mq 设备作为消息队列,以暂时缓存数据,避免 logstash 压力突发。
ELK架构优点如下: 1、处理方式灵活。 Elasticsearch是全文索引,具有强大的搜索能力。 2、配置相对简单。 Kibana的配置非常简单,Elasticsearch则全部使用Json接口,配置也不复杂,Logstash的配置使用模块的方式,配置也相对简单。 3、检索性能高。ELK架构通常可以达到百亿级数据的查询秒级响应。 4、集群线性扩展。 Elasticsearch本身没有单点的概念,自动默认集群模式,Elasticsearch和Logstash都可以灵活扩展。5、页面美观。 Kibana的前端设计美观,且操作简单。
现在让我们来启动一个简单的demo来感受一下🙂
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.13.4
container_name: elasticsearch
environment:
- discovery.type=single-node
- ELASTIC_PASSWORD=changeme123
- xpack.security.enabled=true
- xpack.security.http.ssl.enabled=false
- xpack.security.transport.ssl.enabled=false
ports:
- "9200:9200"
volumes:
- esdata:/usr/share/elasticsearch/data
kibana:
image: docker.elastic.co/kibana/kibana:8.13.4
container_name: kibana
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
- ELASTICSEARCH_USERNAME=kibana_user
- ELASTICSEARCH_PASSWORD=changeme123
depends_on:
- elasticsearch
ports:
- "5601:5601"
logstash:
image: docker.elastic.co/logstash/logstash:8.13.4
container_name: logstash
depends_on:
- elasticsearch
ports:
- "5000:5000"
- "9600:9600"
volumes:
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf
volumes:
esdata:
在同级目录创建logstash.conf
input {
tcp {
port => 5000
codec => line
}//由于只是简单展示,并没有用filebeat收集
}
//这里没有使用fliter,可以自己添加。
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => ["http://elasticsearch:9200"]
user => "elastic"
password => "changeme123"
index => "tcp-logs"
}
}
用这个一键启动后,创建一个用户给kibana使用。
docker exec -it elasticsearch /bin/bash
curl -X POST "http://localhost:9200/_security/user/kibana_user" -H "Content-Type: application/json" -u elastic:changeme123 -d '
{
"password" : "changeme123",
"roles" : [ "kibana_system" ],
"full_name" : "Kibana User"
}'
package main
import (
"fmt"
"net"
"time"
)
func main() {
// 连接到 Logstash
conn, err := net.Dial("tcp", "localhost:5000")
if err != nil {
panic(err)
}
defer conn.Close()
// 构造一条 JSON 日志
log := fmt.Sprintf(`{"timestamp":"%s", "level":"INFO", "msg":"用户登录成功", "user_id":123}`+"\n",
time.Now().Format("2006-01-02 15:04:05"))
// 发送给 Logstash
_, err = conn.Write([]byte(log))
if err != nil {
panic(err)
}
fmt.Println("日志已发送:", log)
}

可以看到这条数据就已经被收集到我们的es上了。
一般都是这样编写
input {
beats {
port => 5044
}
}
filter {
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:log_time} %{LOGLEVEL:log_level} User %{NUMBER:user_id} logged in from %{IP:client_ip}"
}
}
date {
match => ["log_time", "YYYY-MM-dd HH:mm:ss"]
target => "@timestamp"
remove_field => ["log_time"]
}
mutate {
add_field => { "log_source" => "tcp" }
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => ["http://elasticsearch:9200"]
user => "elastic"
password => "changeme123"
index => "tcp-logs-grok-%{+YYYY.MM.dd}"
}
}
将日志输入到文件,通过filebeat传到logstash,可以自己去玩玩,配置一下filebeat的conf文件。当然也可换成kafka,但那样程序一般就很大了😆

 浙公网安备 33010602011771号
浙公网安备 33010602011771号