cs294-ai-sys2022 lectures4 reading
1. Large Scale Distributed Deep Networks(Optional 2012, Google Jeffrey Dean)
- 动机:
-
we consider the problem of training a deep network with billions of parameters using tens of thousands of CPU cores
-
- 工作:
-
We have developed a software framework called DistBelief that enables model parallelism within a machine (via multithreading) and across machines (via message passing), with the details of parallelism, synchronization and communication managed by the framework.
-
Downpour SGD, an asynchronous stochastic gradient descent procedure which leverages adaptive learning rates and supports a large number of model replicas
-
Sandblaster L-BFGS, a distributed implementation of L-BFGS that uses both data and model parallelism.
![]()
-
-
- Downpour SGD
-
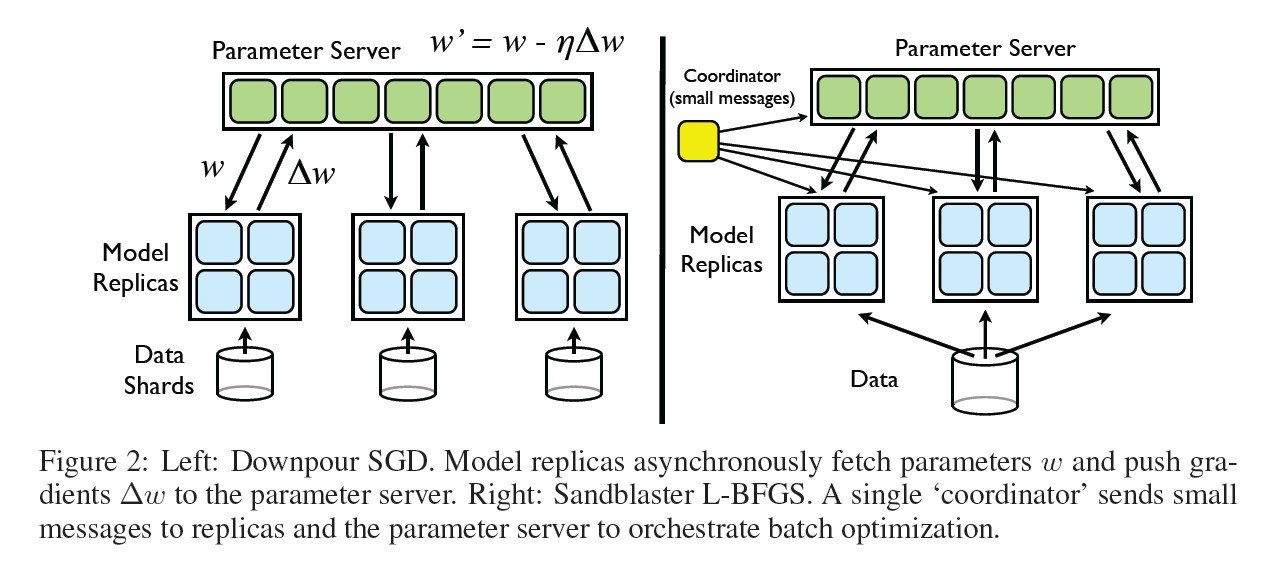
We divide the training data into a number of subsets and run a copy of the model on each of these subsets. The models communicate updates through a centralized parameter server, which keeps the current state of all parameters for the model, sharded across many machines (e.g., if we have 10 parameter server shards, each shard is responsible for storing and applying updates to 1/10th of the model parameters) (Figure 2). This approach is asynchronous in two distinct aspects: the model replicas run independently of each other, and the parameter server shards also run independently of one another.
-
- Sandblaster L-BFGS
-
A key idea in Sandblaster is distributed parameter storage and manipulation. The core of the optimization algorithm (e.g L-BFGS) resides in a coordinator process (Figure 2), which does not have direct access to the model parameters. Instead, the coordinator issues commands drawn from a small set of operations (e.g., dot product, scaling, coefficient-wise addition, multiplication) that can be performed by each parameter server shard independently, with the results being stored locally on the same shard. Additional information, e.g the history cache for L-BFGS, is also stored on the parameter server shard on which it was computed. This allows running large models (billions of parameters) without incurring the overhead of sending all the parameters and gradients to a single central server.
![]()
-
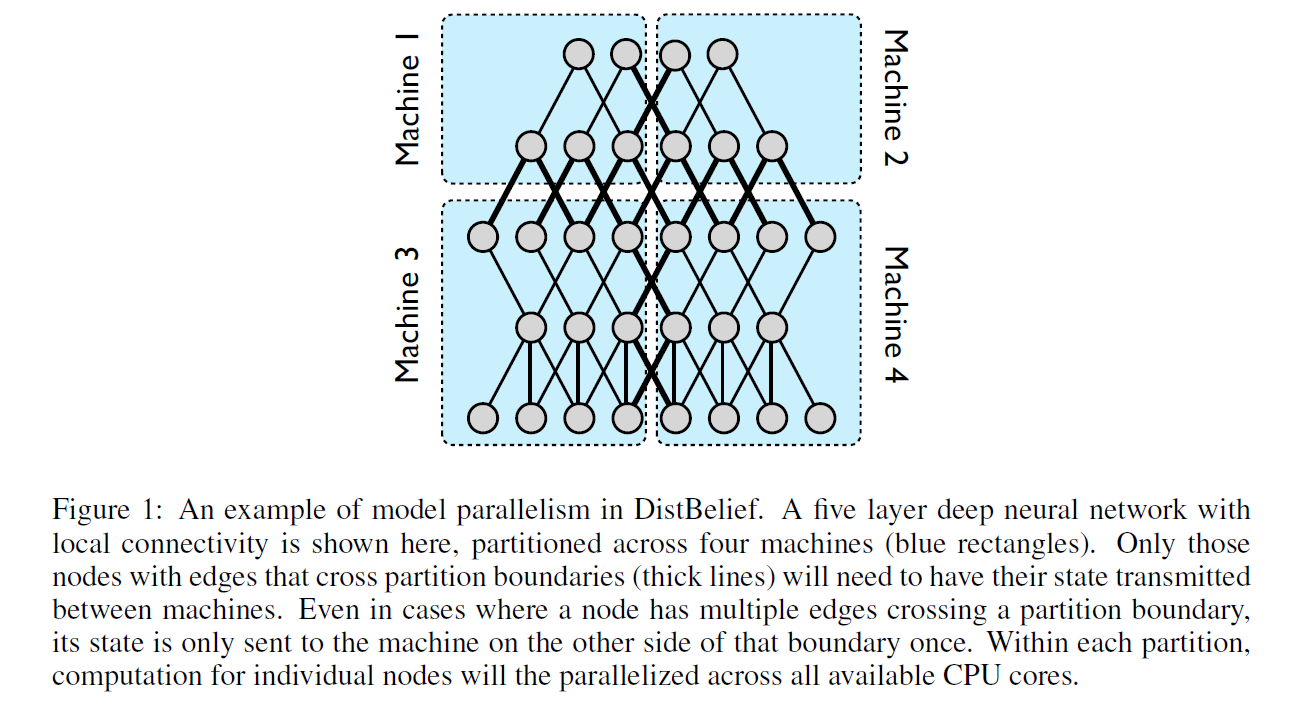
2. GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism(Optional 2019, Google)
- 动机
-
efficient model parallelism algorithms are extremely hard to design and implement, which often requires the practitioner to make difficult choices among scaling capacity, flexibility (or specificity to particular tasks and architectures) and training efficiency. As a result, most efficient model-parallel algorithms are architecture and task-specific.
-
- 工作
-
each model can be specified as a sequence of layers, and consecutive groups of layers can be partitioned into cells. Each cell is then placed on a separate accelerator.(pipeline并行)
-
We first split a mini-batch of training examples into smaller micro-batches, then pipeline the execution of each set of micro-batches over cells
-
- The GPipe Library
- Interface
-
the number of model partitions K(就是深度D)
-
the number of micro-batches M
-
the sequence and definitions of L layers that define the model.
-
- Algorithm
-
Communication primitives are automatically inserted at partition boundaries to allow data transfer between neighboring partitions.
-
The partitioning algorithmminimizes the variance in the estimated costs of all cells in order to maximize the efficiency of the pipeline by syncing the computation time across all partitions.
-
- Performance Optimization
-
In order to reduce activation memory requirements, GPipe supports re-materialization(就是recomputation). During forward computation, each accelerator only stores output activations at the partition boundaries. During the backward pass, the k-th accelerator recomputes the composite forward function Fk.
-
This bubble time is O( K-1 / M+K-1 ) amortized over the number of micro-steps M. In our experiments, we found the bubble overhead to be negligible when M >= 4 * K. This is also partly because re-computation during the backward pass can be scheduled earlier, without waiting for the gradients from earlier layers.
-
GPipe also introduces low communication overhead, given that we only need to pass activation tensors at the partition boundaries between accelerators
![]()
-
- Interface
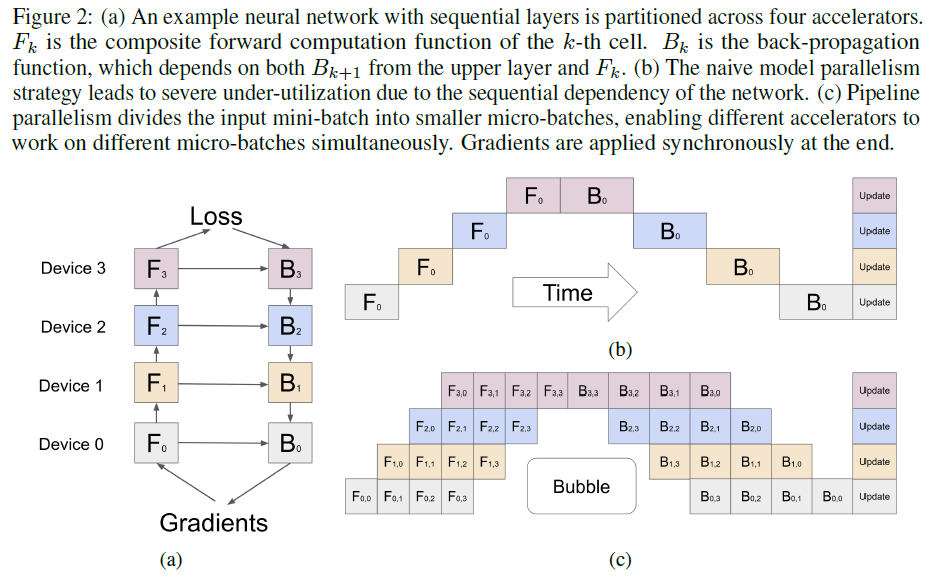
3. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM(required 2021, Nvidia)
- 动机
-
Data-parallel scale-out usually works well, but suffers from two limitations: a) beyond a point, the per-GPU batch size becomes too small(batchsize有上限,gpu无上限), reducing GPU utilization and increasing communication cost(如batchsize2000,当只有1个gpu,无通信成本,如果有2000gpu,通信很大), and b) the maximum number of devices that can be used is the batch size, limiting the number of accelerators that can be used for training.
-
tensor (intra-layer) model parallelism: Larger models need to be split across multiple multi-GPU servers(跨服务器), which leads to two problems: (a) the all-reduce communication required for tensor parallelism needs to go through inter-server links, which are slower than the highbandwidth NVLink [9] available within a multi-GPU server, and (b) a high degree of model parallelism can create small matrix multiplications (GEMMs), potentially decreasing GPU utilization.
- Pipeline model parallelism:The larger the ratio of number of microbatches(Gpipe中的M) to the pipeline size, the smaller the time spent in the pipeline flush. Therefore, to achieve high efficiency, a larger batch size(有个公式) is often necessary.
-
How should parallelism techniques be combined(data,tensor,pipeline) to maximize the training throughput of large models given a batch size while retaining strict optimizer semantics(同步?)?
-
- 工作
-
a technique we call PTD(pipeline-tensor-data)-P, to train large language models with good computational performance (52% of peak device throughput) on 1000s of GPUs. Our method leverages the combination of pipeline parallelism across multi-GPU servers, tensor
parallelism within a multi-GPU server, and data parallelism, to practically train models with a trillion parameters with graceful scaling in an optimized cluster environment with high-bandwidth links between GPUs on the same server and across servers-
efficient kernel implementations that allowed most of the computation to be compute-bound as opposed to memory-bound
-
smart partitioning of computation graphs over the devices to reduce the number of bytes sent over network links while also limiting device idle periods,
-
domain-specific communication optimization,
-
fast hardware
-
-
we studied the interaction between the various components affecting throughput, both empirically and analytically when possible
-
tensor model parallelism is effective within a multi-GPU server, but pipeline model parallelism must be used for larger models
-
The schedule used for pipeline parallelism has an impact on the amount of communication, the pipeline bubble size, and memory used to store activations.
-
Values of hyperparameters such as microbatch size have an impact on the memory footprint, the arithmetic efficiency of kernels executed on the worker, and the pipeline bubble size
- At scale, distributed training is communication-intensive
-
-
- MODES OF PARALLELISM
- Pipeline parallelism
- Gpipe
- Bubble time fraction (pipeline bubble size) = p-1/m (p:pipeline stages,Gpipe文中的K;m:number of microbatches in a batch,Gpipe文中的M,公式不一致,感觉这个对;m = B / b,假设没有数据并行)
-
For the bubble time fraction to be small, we thus need 𝑚 ≫ 𝑝. However, for such large𝑚, this approach has a high memory footprint
- PipeDream-Flush
- warm-up phase:limits the number of in-flight microbatches to the depth of the pipeline
- 1F1B
-
at the end of a batch, we complete backward passes for all remaining in-flight microbatches(不同于PipeDream,这里加了Flush,因此是同步)
-
the number of outstanding forward passes is at most the number of pipeline stages for the PipeDream-Flush schedule. As a result, this schedule requires activations to be stashed for 𝑝 or fewer microbatches
![]()
- Schedule with Interleaved Stages
-
To reduce the size of the pipeline bubble, each device can perform computation for multiple subsets of layers (called a model chunk)。 i.e., device 1 has layers 1, 2, 9, 10; device 2 has layers 3, 4, 11, 12; and so on. With this scheme, each device in the pipeline is assigned multiple pipeline stages (each pipeline stage has less computation compared to before).
- 1F1B
-
If each device has 𝑣 stages (or model chunks),Bubble time fraction (pipeline bubble size) =p-1/(m*v)
-
this schedule requires extra communication. Quantitatively, the amount of communication also increases by 𝑣.
-
- Gpipe
- Tensor model parallelism
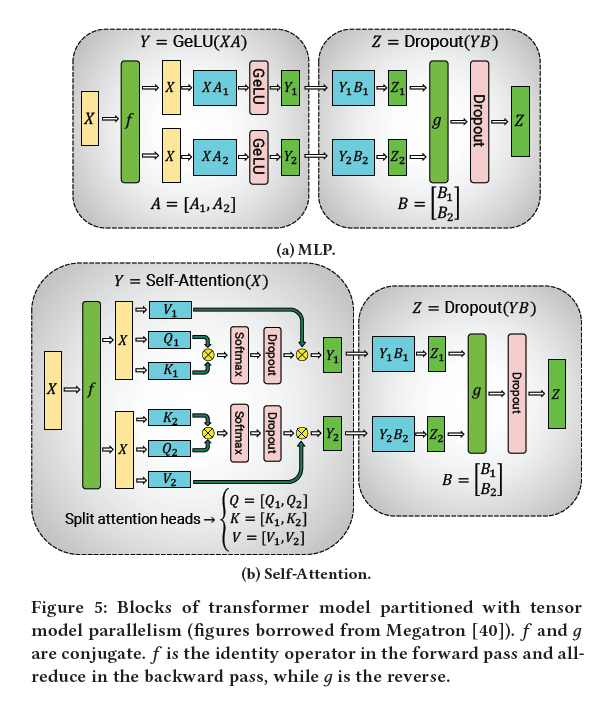
- MLP
- Y = gelu(XA) Z = dropout(YB) -> [Y1,Y2] = [gelu(XA1, XA2)] -> B = [B1, B2]T -> Z = dropout(Y1B1+Y2B2) 注意:加号这里是all-reduce
- Self-Attention
- attention(QW1, KW2, VW3) => Q = [Q1, Q2], W1 = [W11, W12]T, attention(Q1W11 + Q2W12),这里reduce吗
-
This approach splits GEMMs in the MLP and self-attention blocks across GPUs while requiring only two all-reduce operationsin the forward pass (𝑔 operator) and two all-reduces in the backward pass (𝑓 operator).
![]()
- MLP
- Pipeline parallelism
-
PERFORMANCE ANALYSIS OF PARALLELIZATION CONFIGURATIONS
- Notation
-
(𝑝, 𝑡, 𝑑): Parallelization dimensions. 𝑝 for the pipeline-modelparallel size, 𝑡 for the tensor-model-parallel size, and 𝑑 for the data-parallel size.
- 𝑛: Number of GPUs. We require 𝑝 · 𝑡 · 𝑑 = 𝑛.
- 𝐵: Global batch size (provided as input).
- 𝑏: Microbatch size
-
𝑚 = 𝐵/𝑏𝑑 : Number of microbatches in a batch per pipeline
-
𝑠 is the sequence length and ℎ is the hidden size
-
- Tensor and Pipeline Model Parallelism
- 假设d = 1,没有data并行
- bubble size = p-1/m = (n/t - 1) / m,As 𝑡 increases, the pipeline bubble thus decreases for fixed 𝐵, 𝑏,n(实际上,减少深度p就能减少bubble size,t只是提供了一种减少p的方式(有了t,pipeline每个阶段可以处理更多层,可以有更少阶段p))
- communication
-
-
Pipeline model parallelism features cheaper point-to-point communication. Tensor model parallelism, on the other hand, uses all-reduce communication(成本高)
- pipeline parallelism, the total amount of communication that needs to be performed between every pair of consecutive devices(for either the forward or backward pass) for each microbatch is 𝑏𝑠ℎ
- tensor model parallelism, tensors of total size 𝑏𝑠ℎ need to be all-reduced among 𝑡 model replicas twice each in the forward and backward pass for each layer(相当于每层总共8次all-reduce), leading to a total communication of 𝑙-stage*8𝑏𝑠ℎ*(t-1)/t(ring all reduce),
𝑙-stage is the number of layers in a pipeline stage.
-
When considering different forms of model parallelism, tensor model parallelism should generally be used up to degree 𝑔 when using 𝑔-GPU servers(tensor并行限制在服务器内), and then pipeline model parallelism can be used to scale up to larger models across servers(pipeline可以跨服务器).
-
- Data and Model Parallelism
- Pipeline Model Parallelism. Let 𝑡 = 1
- bubble size (当gpu个数n固定,d也提供了一种减少p的的方式,但会减少m,总体仍减少bubble size;d增加有限制,如增加到n,则p=1,每个gpu跑整个模型,OOM)
![]()
- communication
- data parallelism,ring based all reduce: d-1/d(这是每个设备总all-reduce通信量,独立于d,而所有设备并行执行;Each machine sends N/d data to next machine each of (d-1) rounds:(d-1) * N/d (doesn’t depend on d!))
- 增加B,会增加b',减少bubble size;
- Data and Tensor Model Parallelism
- tensor parallelism 通信成本远高于data parallelism
-
tensor model parallelism, each model-parallel rank performs a subset of the computation in each model layer(计算能力利用率不高)
-
When using data and model parallelism, a total model-parallel size of 𝑀 = 𝑡 · 𝑝 should be used so that the model’s parameters and intermediate metadata fit in GPU memory(模型并行包括pipeline和tensor,目的是要适配gpu内存); data parallelism can be used to scale up training to more GPUs.
- Pipeline Model Parallelism. Let 𝑡 = 1
- Microbatch Size
-
The microbatch size thus affects both the arithmetic intensity of operations as well as the pipeline bubble size (by affecting𝑚).(b增加,增加计算效率,但减少m)
-
- Activation Recomputation
-
For most cases, checkpointing every 1 or 2 transformer layers is optimal(论文中有个公式)
-
- Notation
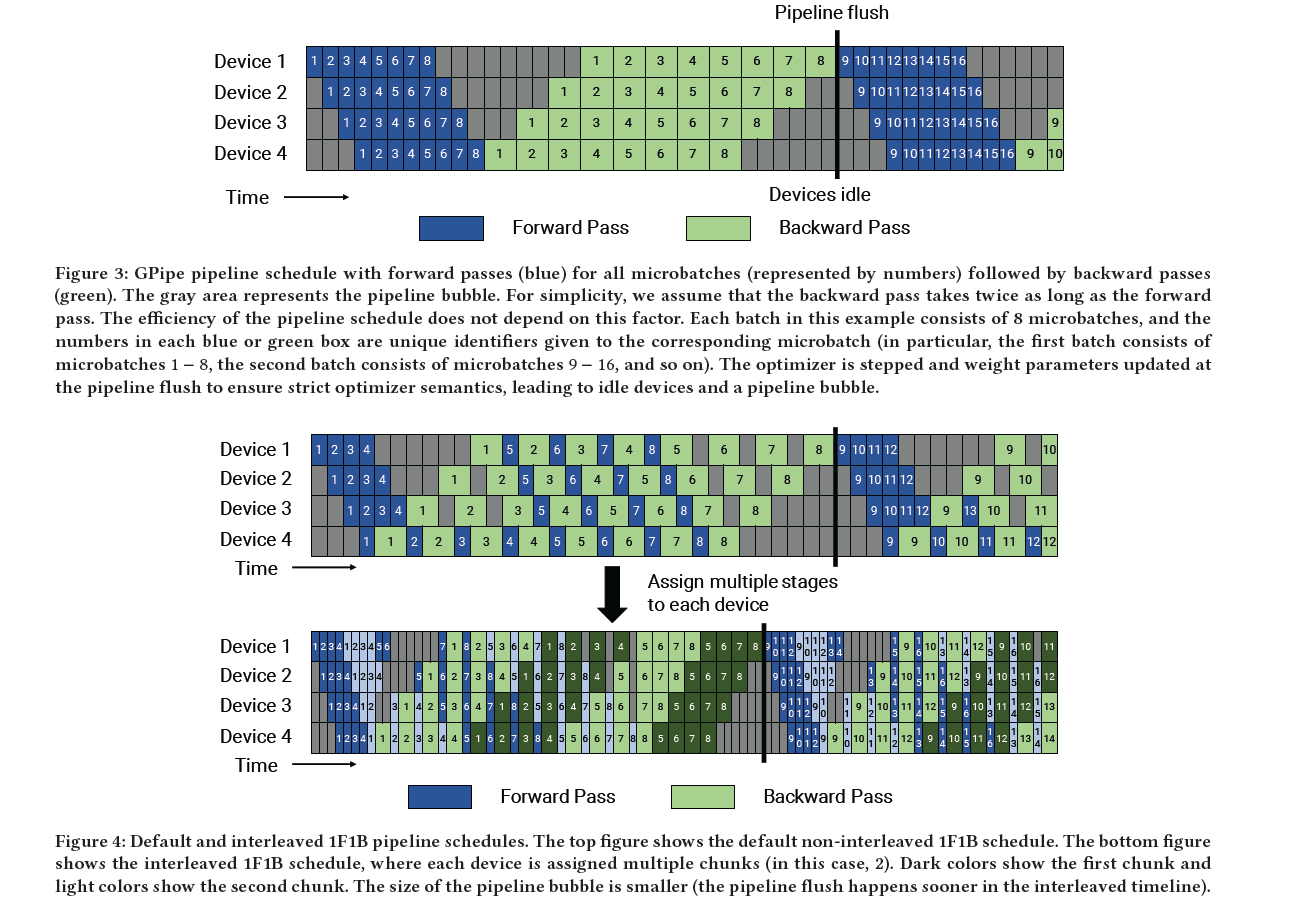

4. ZeRO-Infinity: Breaking the GPU MemoryWall for Extreme Scale Deep Learning(required2021 microsoft)
- 动机
-
Looking ahead, how do we support the next 1000x growth in model size, going from models like GPT-3 with 175 billion parameters to models with hundreds of trillions(百万亿) of parameters
-
How can we make large models of today accessible to more data scientists who don’t have access to hundreds to GPUs
-
Can we make large model training easier by eliminating the need for model refactoring and multiple forms of parallelism
- 3D parallelism问题:
-
significant model code refactoring to split the model into model and pipeline parallel components,
-
models with complex dependency graphs are difficult to be expressed into load-balanced pipeline stages
-
the model size is limited by the total available GPU memory
-
- Zero3
-
There are three stages in ZeRO corresponding to three model states: the first stage (ZeRO-1) partitions only the optimizer states, the second stage (ZeRO-2) partitions both the optimizer states and the gradients, and the final stage (ZeRO-3) partitions all three model states.
-
In ZeRO-3, the parameters in each layer of the model are owned by a unique data parallel process. During the training, ZeRO-3 ensures that the parameters required for the forward or backward pass of an operator are available right before its execution by issuing broadcast communication collectives from the owner process. After the execution of the operator, ZeRO- 3 also removes the parameters as they are no longer needed until the next forward or backward pass of the operator. Additionally, during the parameter update phase of training, ZeRO-3 ensures that each data-parallel process only updates the optimizer states corresponding to the parameters that it owns.
-
-
- 工作:
-
take a leap forward from 3D parallelism(跨过ptd并行) and present ZeRO-Infinity
- Unprecedented Model Scale: ZeRO-Infinity extends the ZeRO family of technology with new innovations in heterogeneous memory access called the infinity offload engine. This allows ZeRO-Infinity to support massive model sizes on limited GPU resources
by exploiting CPU and NVMe memory simultaneously. In addition, ZeRO-Infinity also introduces a novel GPU memory optimization technique called memory-centric tiling to support extremely large individual layers that would otherwise not fit in GPU memory even one layer at a time.
-
Excellent Training Efficiency: ZeRO-Infinity introduces a novel data partitioning strategy for leveraging aggregate memory bandwidth across all devices, which we refer to as bandwidth-centric partitioning, and combines it with powerful communication overlapcentric design, as well as optimizations for high performance NVMe access in the infinity offload engine
- Ease of Use
- Unprecedented Model Scale: ZeRO-Infinity extends the ZeRO family of technology with new innovations in heterogeneous memory access called the infinity offload engine. This allows ZeRO-Infinity to support massive model sizes on limited GPU resources
-
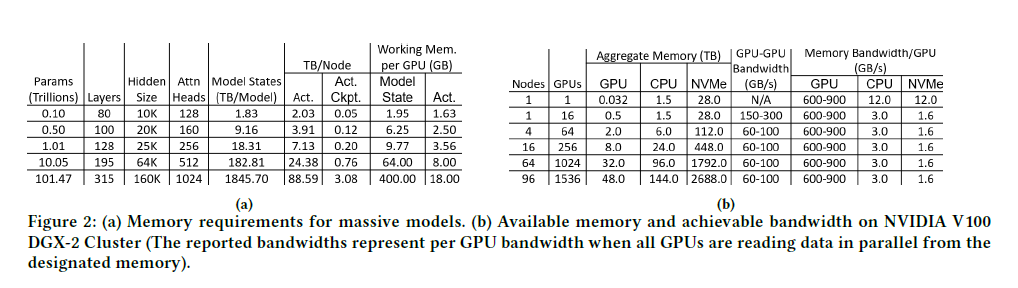
- MEMORY REQUIREMENTS
- Memory for Model States(最大,远大于其他):
-
The model states are comprised of optimizer states, gradients, and parameters
-
For mixed precision training with Adam optimizer, the parameters and gradients are stored in FP16 while the optimizer states consist of FP32 momentum, variance, parameters, and gradients. In total, each parameter requires 20 bytes of memory.
-
Thus, the total parameters in a Transformer based model and can be approximated as 12 × 𝑛𝑙 × ℎd^2( hidden dimension (ℎ𝑑), the number of Transformer layers (𝑛𝑙 ), Nearly all the parameters in a Transformer block come from four linear layers within each block with sizes: (ℎ𝑑, 3ℎ𝑑), (ℎ𝑑, ℎ𝑑)前两个是multihead-attention中, (ℎ𝑑, 4ℎ𝑑) and (4ℎ𝑑, ℎ𝑑) 后两个是FFN),requiring a total memory:240 × 𝑛𝑙 × ℎ𝑑^2
-
- Memory for Residual States:
-
The residual states primarily consist of the activation memory, which depends on the model architecture, batch size (𝑏𝑠𝑧) and sequence length (𝑠𝑒𝑞), and it can be quite large
-
The memory required to store activation checkpoints is estimated as 2 × 𝑏𝑠𝑧 × 𝑠𝑒𝑞 × ℎ𝑑 × 𝑛𝑙/𝑐𝑖,𝑐𝑖 is the number of Transformer blocks between two activation checkpoints
-
- Model State Working Memory (MSWM)
-
is the minimum amount of GPU memory required to perform forward or backward propagation
-
For a Transformer based model, the largest operator is a linear layer that transforms hidden states from ℎ𝑑 to 4ℎ𝑑, 4 × ℎ𝑑 × 4ℎ𝑑
-
lack of enough contiguous memory to satisfy these requirements(一个hidden state就很大,需要很大的连续空间)
-
- ActivationWorking Memory (AWM)
-
ActivationWorking Memory (AWM)is the memory required in the backward propagation for recomputing the activations before performing the actual backward propagation. This is the size of the activations between two consecutive activation checkpoints
![]()
-
- Memory for Model States(最大,远大于其他):
- BANDWIDTH REQUIREMENTS
-
A critical question of offloading to CPU and NVMe memory(ZERO核心) is whether their limited bandwidth will hurt training efficiency
-
The arithmetic intensity (AIT) of a workload is the ratio between the total computation and the data required by the computation.
- Quantifying AIT in DL training
- AIT w.r.t. Parameters and Gradients:𝑠𝑒𝑞 × 𝑏𝑠𝑧.
- AIT w.r.t. Optimizer States:𝑠𝑒𝑞 × 𝑏𝑠𝑧/4
- AIT w.r.t. Activation Checkpoints:24 × ℎ𝑑 × 𝑐𝑖.
- Bandwidth Requirements
- Bandwidth w.r.t. Parameter and Gradients:
-
bandwidth of over 70 GB/s for parameter and gradients, we can achieve over 50% efficiency for even the smallest batch size.
-
At this bandwidth, the data movement in theory can be completely overlapped with the computation to achieve a 100% efficiency
-
- Bandwidth w.r.t. Optimizer States
-
optimizer states require nearly 4x higher bandwidth to achieve 50% efficiency compared to parameters and gradients
-
the optimizer states are updated at the end of the forward and backward propagation and cannot be overlapped with the computation
-
For example achieving 90% efficiency with batch size of 2 per GPU requires nearly 1.5 TB/s of effective bandwidth, which is greater than even the GPU memory bandwidth
-
- Bandwidth w.r.t. activation memory
-
with activation checkpointing enabled, a meager bandwidth of 2 GB/s is able to sustain over 50% efficiency even for a hidden size of 2𝐾.
-
- Bandwidth w.r.t. Parameter and Gradients:
-
- ZERO-INFINITY DESIGN OVERVIEW
- Design for Unprecedented Scale(解决内存问题)
-
Modern GPU clusters are highly heterogeneous in terms of memory storage. In addition to the GPU memory, they have CPU memory as well as massive NVMe storage that is over 50x larger than the GPU memory and nearly 20x larger than CPU memory
- Infinity offload engine for model states
-
infinity offload engine which can offload all of the partitioned model states to CPU or NVMe memory, or keep them on the GPU based on the memory requirements
-
even the model states required by a 100 trillion parameter model can fit in the aggregate NVMe memory of a DGX-2 cluster with 96 nodes (1536 GPUs).
-
- CPU Offload for activations
-
ZeRO-Infinity can offload activation memory to CPU memory, when necessary. Note that the activation checkpoints (0.76 TB)required by a 10 trillion parameter model can easily fit in the 1.5TB of CPU memory available on a DGX-2 system
-
- Memory-centric tiling for working memory
-
exploits the data fetch and release pattern of ZeRO-3 to reduce the working memory requirements by breaking down a large operator into smaller tiles that can be executed sequentially(不同于模型并行,这是顺序执行)
-
-
- Design for Excellent Training Efficiency(解决效率问题)
-
难点:Offloading all model states and activations to CPU or NVMe is only practical if ZeRO-Infinity can achieve high efficiency despite the offload. In reality this is extremely challenging since CPU memory is an order of magnitude slower than GPU memory bandwidth, while
the NVMe bandwidth is yet another order of magnitude slower than the CPU memory bandwidth. Furthermore, reading and writing to these memory from GPU is even slower - Efficiency w.r.t Parameter and Gradients
-
bandwidthcentric partitioning: a novel data mapping and parallel data retrieval strategy for offloaded parameters and gradients that allows ZeROInfinity to achieve virtually unlimited heterogeneous memory bandwidth
-
an overlap centric design that allows ZeRO-Infinity to overlap not only GPU-GPU communication with computation but also NVMe-CPU and CPU-GPU communications over the PCIe
-
- Efficiency w.r.t Optimizer States.
-
Unlike parameters and gradients that are consumed and produced sequentially during the forward and backward propagation, optimizer states can be updated in parallel, all at once. This property is leveraged by both ZeRO-3 and ZeRO-Offload, that store and update the optimizer states in GPU and CPU memory, respectively, in parallel across all available GPUs and CPUs. As a result the aggregate GPU or CPU memory bandwidth can get much higher than the required 1.5TB/s with increase in GPU or CPU count.
-
- Efficiency w.r.t Activations.
-
- Design for Unprecedented Scale(解决内存问题)
- EFFICIENCY OPTIMIZATION
- Bandwidth-Centric Partitioning
-
ZeRO-Infinity partitions individual parameters across all the data parallel process, and uses an allgather instead of a broadcast when a parameter needs to be accessed(broadcast:从NVMe或CPU到GPU时,只使用一个PCIe,因为时复制到一个设备,然后在GPU上传播;allgather将partitioned数据分别传到所有GPU设备,用所有PCIe,然后再GPU上allgather,GPU上操作快,传到GPU上慢,所以解决了瓶颈问题)
-
limited only by the max aggregate PCIe bandwidth and max NVMe bandwidth per DGX-2 node. From here, the bandwidth grows linearly with more nodes
-
For example, on 64 DGX-2 nodes, ZeRO-Infinity has access to over 3TB/s of CPU memory bandwidth and over 1.5TB/s of NVMe bandwidth
-
-
- Overlap Centric Design
-
not only overlaps GPU-GPU communication with GPU computation, but also overlaps the NVMe to CPU, and CPU to GPU communication(计算上一步的同时,把下一步要用的数传过来), all at the same time
-
A dynamic prefetcher for overlapping the data movement required to reconstruct parameters before they are consumed in the forward or backward pass,
-
For instance, before executing the 𝑖𝑡ℎ operator, the prefetcher can invoke nc, cg, and gg-transfer for parameters required by 𝑖 +3, 𝑖 +2, and 𝑖 +1 operators, respectively. Note that all of these data movement can happen in parallel with the execution of the 𝑖𝑡ℎ operator
-
-
a communication and offload overlapping mechanism for executing the data movementrequired by gradients in parallel with the backward computation
-
- Infinity Offload Engine
-
DeepNVMe, a powerful C++ NVMe read/write library in the infinity offload engine that supports bulk read/write requests for asynchronous completion, and explicit synchronization requests to flush ongoing read/writes
- Pinned memory management layer
-
To ensure high performance tensor reads (or writes) from (to) NVMe/CPU storage, the source (or destination) tensors must reside in pinned memory buffers. However, pinned memory buffers are scarce system resources, and their oversubscription by a single process can degrade overall system performance or cause system instability
-
-
- Bandwidth-Centric Partitioning
5. Chimera: Efficiently Training Large-Scale Neural Networks with Bidirectional Pipelines(2022)
- 动机:
-
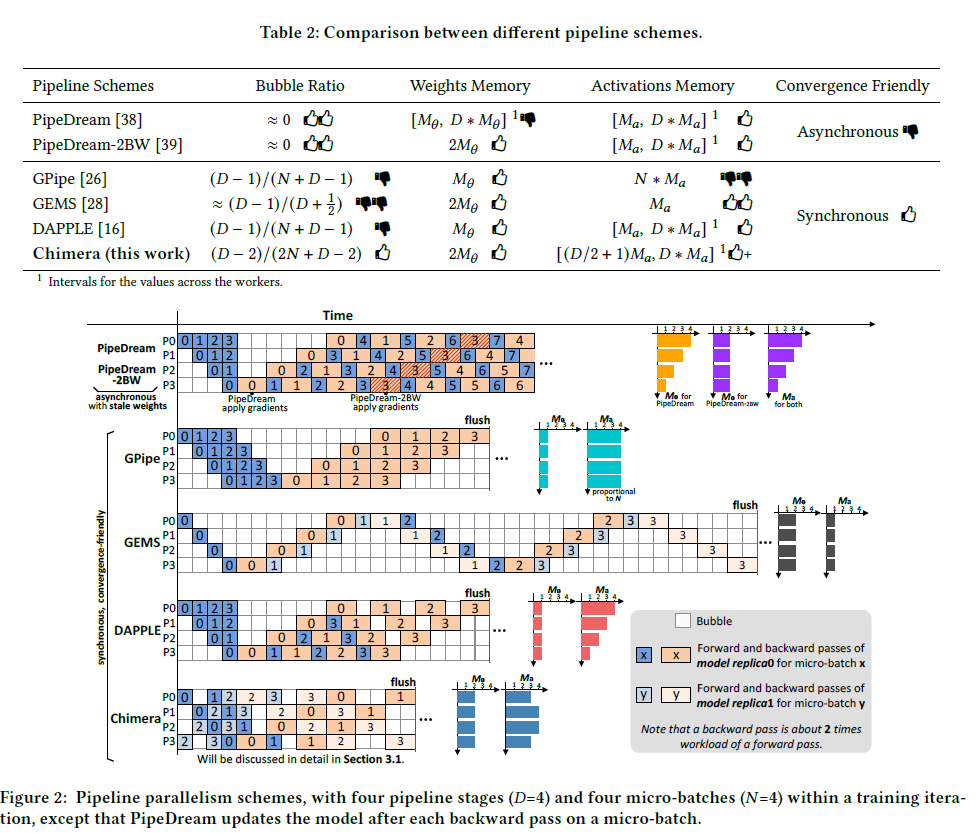
pipeline parallelism suffers from bubbles(gpipe) or weight staleness(pipedream)
-
DAPPLE, PipeDream, and PipeDream- 2BW, the first accelerator of a pipeline of depth 𝐷 has to store 𝐷 such activations while the last accelerator requires memory for one(一般都会用activation recomputation吧,但也会降低33%效率).
-
- 工作
- fully-packed bidirectional pipelines Chimera
-
to keep the overall training synchronous without relying on stale weights
-
a higher pipeline utilization (less bubbles) than existing approaches and thus higher performance
-
the same peak activation memory consumption as the stateof- the-art methods, with an extra benefit of more balanced memory consumption
-
easy configurability to various pipelined deep neural networks as well as system architectures guided by an accurate performance model
-
- fully-packed bidirectional pipelines Chimera
- BACKGROUND AND RELATEDWORKa
![]()
![]()
- Bubbles in the pipeline
-
GEMS is mainly designed for small ˆ 𝐵 and has at most two active micro-batches
-
- Memory consumption
- weight parameters:看一个gpu计算阶段数,如Gpipe和DAPPLE,每个gpu只计算一个阶段,存一个阶段的参数;GEMS和Chimera,每个gpu计算两个阶段,需存两个阶段的参数
-
由于DAPPLE, PipeDream, and PipeDream- 2BW和Chimera中,每个时刻存在的激活值数最大为D,因此限制了 activitions memory
- Convergence friendliness
-
Although they empirically show promising convergence results, the generality is lack of proof. More recent work [4, 34, 36, 37, 52] observes that asynchronous training algorithms may result in lower convergence performance
-
THE SCHEME OF CHIMERA
- Bidirectional Pipelines
- 见fig2
- Communication Scheme
-
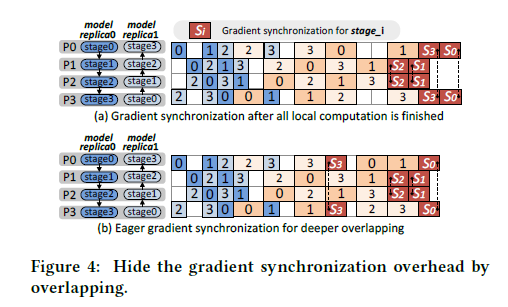
Chimera uses p2p (point-to-point) communication to transfer the intermediate activations and gradients (with respect to the inputs) between pipeline stages in the forward pass and the backward pass, respectively. Since Chimera combines bidirectional pipelines
together, collective communication (i.e., allreduce) is used to synchronize the weight gradients across stage replicas before the next training iteration. -
Taking P0 and P3in Figure 4(b) as an example, after these two workers finish the backward passes on micro-batch 3 and micro-batch 1, respectively, the calculation for the weight gradients of stage3 has been finished; therefore, P0 and P3 can launch an asynchronous allreduce using nonblocking collectives [23, 25] to synchronize the gradients of stage3 as soon as they are finished, and a wait operation is called after all the local computation to make sure the allreduce is finished. In this way, the gradient synchronization for stage3 is overlapped by the bubbles and the following computation.
![]()
-
- Hybrid of Pipeline and Data Parallelism
-
Chimera supports a hybrid of pipeline and data parallelism. When scaling to the parallel machines equipped with high performance interconnected networks (such as Infiniband [50], Cray Aries [2] or Slingshot [48], and NVLink [18]), hybrid parallelism usually achieves better performance than the pure pipeline parallelism [16, 39]. This is because pure pipeline parallelism has𝑊 · 𝐷 stages in the pipeline, while hybrid parallelism has 𝐷 stages (𝑊 times less) which helps to reduce the p2p communication overhead between stages and increase the computation workload of each stage(应该还会减少bubble size). Although hybrid parallelism leads to gradient synchronization between stage replicas, the overhead of it can be alleviated by the aforementioned high performance interconnected networks. However, as𝑊 increases (𝐷 decreases), pipeline stages become coarser, until at some point the increased gradient synchronization overhead cannot be amortized by the reduced p2p communication overhead. Therefore, it is important to find the sweet spot to achieve the best performance.
-
-
-
- Configuration Selection Based on Performance Modelling( Given the mini-batch size 𝐵^ and the number of workers 𝑃, the configuration of 𝐵,𝑊, and 𝐷 largely affects the training throughput)
-
Larger micro-batch size (𝐵) usually improves the computational efficiency of the accelerators. Since Chimera greatly alleviates the bubble problem, it greedily chooses to use the maximum microbatch size fitting in the device memory(增加micro-batch size,会减少N,增加bubble size,但Chimera优化了bubble size,所以不惧)
-
To select the best configuration of𝑊 and 𝐷, we build a performance model to predict the runtime of a single training iteration (represented by 𝑇 ) for each available configuration
-
- Scale to More Micro-Batches
-
For a large ˆ𝐵, there may be more than 𝐷 micro-batches in a training iteration for each worker (i.e., 𝑁>𝐷), especially when the compute resources are limited. To scale to a large ˆ𝐵, we first choose the maximum 𝐵 with 𝐷 micro-batches to saturate the device memory,
and schedule these 𝐷 micro-batches using bidirectional pipelines as discussed previously(B^ = N*B*W,当计算资源有限,W有限,B受限于内存,需要增加N,注意增加N并不会增加内存,因为并行的最大激活值数量为D). -
Direct concatenation,The bubbles at the end of the first basic unit can be occupied by the forward passes at the beginning of the second basic unit. If the backward pass has the same workload as the forward pass, basic units can be concatenated seamlessly. However, backward pass has about two times workload of the forward pass, which results in intermediate bubbles.
- forward doubling以及backward halving
-
equalize the workloads of forward and backward passes.
-
Forward doubling removes the intermediate bubbles, but it leads to two times activation memory consumption and therefore may exceed the device memory capacity(可以用activation recomputation).
-
Forward doubling prefers large models in which even 𝐵=1 exceeds the device memory capacity, since in such case activation recomputation must be used.
-
For smaller models which has a larger 𝐵, we propose to use backward halving, which uses the same schedule as forward doubling, except that rather than executing two micro-batches in the forward pass but to halve the micro-batch size of the backward pass. Backward halving does not increase the activation memory (thus no activation recomputation), but it may lower the computational efficiency because of using a sub-max 𝐵.
-
-
- Configuration Selection Based on Performance Modelling( Given the mini-batch size 𝐵^ and the number of workers 𝑃, the configuration of 𝐵,𝑊, and 𝐷 largely affects the training throughput)
- EXPERIMENTAL EVALUATION
- Parallel Scalability
- Performance Optimization Space for the Baselines
-
we can see the highest throughput of both DAPPLE and GPipe (with activation recomputation) is achieved by (𝑊=8, 𝐷=4, 𝐵=4), under which they hit the sweet spot for the trade-off between p2p communication overhead and allreduce communication overhead by (𝑊=8, 𝐷=4)(确定W), and the sweet spot for the trade-off between bubble ratio and computational efficiency by 𝐵=4 (and 𝑁=16)(确定B). GEMS prefers a large 𝐵 for high computational efficiency since a smaller 𝐵 does not help a lot to reduce the bubble ratio, and therefore its best performance is achieved by (𝑊=8, 𝐷=4, 𝐵=32).
-
Asynchronous baselines (PipeDream-2BW and PipeDream) always prefer the maximum 𝐵 fitting in the device memory, since there is no bubble problem for them. Note that PipeDream conducts gradient synchronization across𝑊 pipelines after each backward
pass on a micro-batch, thus its ˆ𝐵is limited by the maximum 𝐵. Since the frequent gradient synchronization of PipeDream leads to high allreduce overhead, its best performance is achieved with a deeper pipeline than others, namely by (𝑊=4, 𝐷=8, ˆ𝐵=48). PipeDream-2BWscales to large ˆ𝐵 by accumulating the gradients for more than 𝐷 micro-batches (i.e., 𝑁>=𝐷), and its best performance is achieved by (𝑊=8, 𝐷=4, 𝐵=16) with activation recomputation.
-
- Performance Optimization Space for the Baselines
- Parallel Scalability
-

6. DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale(2022 Microsoft)
- 动机
-
MoE based models have their own set of challenges that limit their usein a wide range of real world scenarios
-
Limited Scope The scope of MoE based models in the NLP area is primarily limited to encoder-decoder models and sequence-to-sequence tasks, with limited work done in exploring its application in other domains. Application of MoE to auto-regressive natural
language generation (NLG) like GPT-3 and MT-NLG 530B, where the compute cost of training state-of-art language models can be orders of magnitude higher than for encoderdecoder models, is less explored(MOE用于NLG计算代价高). - Limited Inference Performance
-
-
- 工作
-
We expand the scope of MoE based models to auto-regressive NLG tasks, demonstrating training cost reduction of 5x to achieve same model quality for models like GPT-3 and MTNLG.
-
improve parameter efficiency of MoE based models by developing a novel MoE architecture that we call Pyramid-Residual MoE (PR-MoE).
- develop DeepSpeed-MoE inference system
-
-
DeepSpeed-MoE for NLG: Reducing the Training Cost of Language Models by 5 Times
-
We use a gating function to activate a subset of experts in the MoE layer for each token. Specically, in our experiments, only the top-1 expert is selected
-
MoE models and their dense counter part with 4-5x larger base have very si milar model quality
-
-
PR-MoE and MoS: Reducing the Model Size and Im-proving Parameter Efficiency
-
While MoE based models achieve the same quality with 5x training cost reduction in the NLG example, the resulting model has roughly 8x the parameters of the corresponding dense model (e.g., 6.7B dense model has 6.7 billion parameters and 1.3B+MoE-128 has 52 billion
parameters). -
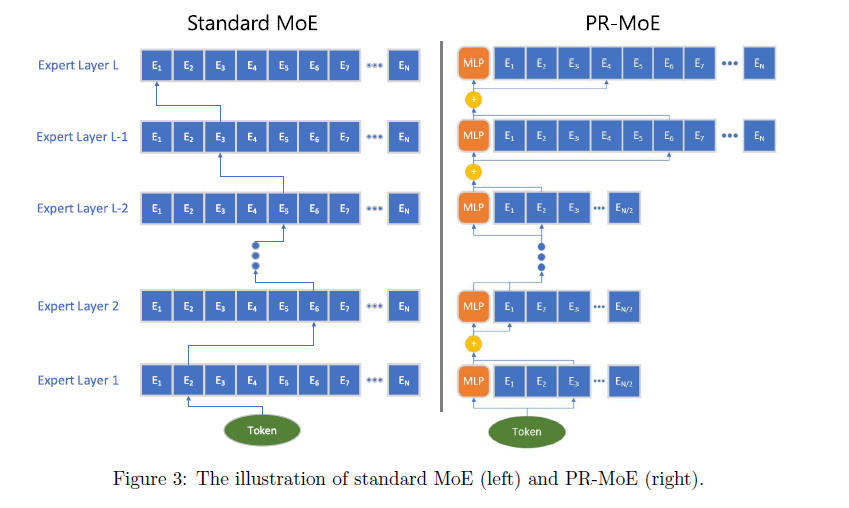
PR-MoE: Pyramid-Residual-MoE for Smaller Model Size and Fast Inference
- Two Observations and Intuitions
-
This confirrms that not all MoE layers learn the same level of representations. Deeper layers benefit more from large number of experts.
-
a token will always pass a dense MLP module and an expert from MoE module, which can be viewed as a special case of residual network. Afterward, we add the output of these two branches together to get the final output. The main intuition is to treat the expert from MoE module as an error correction term of the dense MLP module. We find out that the generalization performance of these two (aka Top2-MoE and Residual-MoE) is on-par with each other. However, the training speed of our new design, Residual-MoE, is more than 10% faster than Top2-MoE due to the communication volume reduction.
-
- Pyramid Residual MoE Architecture
![]()
- System Design
-
Training an MoE model efficiently requires having suffciently large batch size for each expert in the MoE module to achieve good compute efficiency. This is challenging since the number of input tokens to an MoE is partitioned across all the experts which reduces the number of tokens per expert proportionally to the number of experts when compared to the rest of the model where no such partition is done. The simplest way to avoid this reduction in tokens per expert is to train the model with data parallelism in combination with expert parallelism [31] equal to the number of experts
-
due to variation in the number of experts in PR-MoE, there is no single expert parallelism degree that is optimal for all MoE layers.
-
we develop and implement a exible multi-expert and multi-data parallelism design on top of DeepSpeed-MoE, that allows for training different parts of the model with different expert and data parallelism degree. For instance, a PR-MoE model running on 128 GPUs, with 32, 64, and 128 experts at different MoE layers, can be trained with 128-way data parallelism for the non-expert parallelism, and f32, 64, 128g expert parallelism plus f4, 2, 1g data parallelism for MoE parameters.
-
- Two Observations and Intuitions
-
Mixture-of-Students: Distillation for Even Smaller Model Size and Faster Inference
-
We reduce the depth of each expert branch in the teacher model to obtain a corresponding student. Since MoE structure brings signifficant benefitts by enabling sparse training and inference, our task-agnostic distilled Mixture-of-Students inherits these benefits while preserving the inference advantage over its quality equivalent dense model.
![]()
-
We find that while KD loss improves validation accuracy initially, it begins to hurt accuracy towards the end of training. the student PR-MoE may not have enough capacity to minimize both the training loss and the knowledge distillation loss, and might end up minimizing one loss (KD loss) at the expense of the other (cross entropy loss), especially towards the end of training. The aforementioned hypothesis suggests that we might want to either gradually decay the impact from KD or stop KD early in the training process and perform optimization only against the standard language modeling loss for the rest of the training
-
-
DeepSpeed-MoE Inference: Serving MoE Models at Unprecedented Scale and Speed
-

-
- Carefully partition the model and embrace di erent types of parallelism; group and route all tokens with the same critical data path together to reduce data access per device and achieve maximum aggregate bandwidth
- Optimize communication scheduling with parallelism coordination to efectively group and route tokens
- Optimize transformer and MoE related kernels to improve per-device performance


 浙公网安备 33010602011771号
浙公网安备 33010602011771号