



第二次作业:Hadoop演进与Hadoop生态
一.了解对比Hadoop不同版本的特性,可以用图表的形式呈现。
Apache Hadoop:是一套用于在由通用硬件构建的大型集群上运行应用程序的框架。它实现了Map/Reduce编程范型,计算任务会被分割成多次运行在不同的节点上。除此之外,它还提供了一款分布式文件系统,数据被存储在计算节点上以提供极高的跨数据中心聚合带宽。
优点:完全开源免费,社区活跃,且文档、资料详实。
缺点:
1.复杂的版本管理。版本管理比较混乱的,各种版本层出不穷。
2.复杂的集群部署、安装、配置。通常按照集群需要编写大量的配置文件,分发到每一台节点上,容易出错,效率低下。
3.复杂的集群运维。对集群的监控,运维,需要安装第三方的其他软件,运维难度较大。
4.复杂的生态环境。在Hadoop生态圈中,组件的选择、使用,比如Hive,Mahout,Sqoop,Flume,Spark,Oozie等等,需要大量考虑兼容性的问题,版本是否兼容,组件是否有冲突,编译是否能通过等。经常会浪费大量的时间去编译组件,解决版本冲突问题。
第三方发行版Hadoop:Hadoop遵从Apache开源协议,用户可以免费地任意使用和修改Hadoop,也正因此,市面上出现了很多Hadoop版本。其中有很多厂家在Apache Hadoop的基础上开发自己的Hadoop产品,比如Cloudera的CDH,Hortonworks的HDP,MapR的MapR产品等。
优点:
1.基于Apache协议,100%开源。
2.版本管理清晰。比如Cloudera,CDH1,CDH2,CDH3,CDH4,CDH5 等,后面加上补丁版本,如CDH4.1.0 patch level 923.142,表示在原生态Apache Hadoop 0.20.2基础上添加了1065个patch。
3.比Apache Hadoop在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运行到各种生产环境。
4.版本更新快。通常情况,比如CDH每个季度会有一个update,每一年会有一个release。
5.基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch
6.提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在几个小时内部署好集群。
7.运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效。
二.Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。
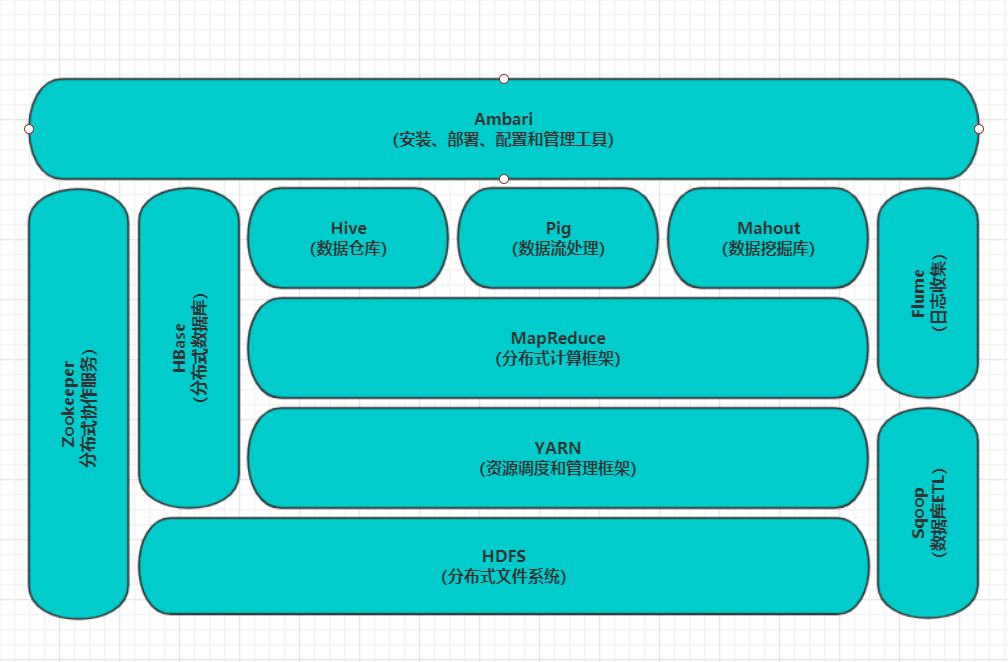
HBase:
Google Bigtable的开源实现;列式数据库;可集群化;可以使用shell、web、api等多种方式访问;适合高读写的场景。
Hive:
可以把Hadoop下的原始结构化数据变成Hive中的表;支持一种与SQL几乎完全相同的语言HiveQL,除了不支持更新、索引和事务,几乎SQL的其它特征都能支持;可以看成是从SQL到Map-Reduce的映射;提供shell、JDBC/ODBC、Thrift、Web等接口。
Zookeeper:
Google Chubby的开源实现;用于协调分布式系统上的各种服务。例如确认消息是否准确到达,防止单点失效,处理负载均衡等。
Sqoop:
用于在Hadoop和关系型数据库之间交换数据;通过JDBC接口连入关系型数据库。
Chukwa:
架构在Hadoop之上的数据采集与分析框架;主要进行日志采集和分析;通过安装在收集节点的“代理”采集最原始的日志数据;代理将数据发给收集器;收集器定时将数据写入Hadoop集群;指定定时启动的Map-Reduce作业队数据进行加工处理和分析。
Pig:
Hadoop客户端;使用类似于SQL的面向数据流的语言Pig Latin;Pig Latin可以完成排序,过滤,求和,聚组,关联等操作,可以支持自定义函数;Pig自动把Pig Latin映射为Map-Reduce作业上传到集群运行,减少用户编写Java程序的苦恼 。
Avro:
数据序列化工具,由Hadoop的创始人Doug Cutting主持开发;用于支持大批量数据交换的应用。支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理 Avro数据。
Cassandra:
NoSQL,分布式的Key-Value型数据库;与Hbase类似,也是借鉴Google Bigtable的思想体系;只有顺序写,没有随机写的设计,满足高负荷情形的性能需求。
三.官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
1.创建Hadoop用户
创建用户的命令是useradd,设置密码的命令为passwd。
2.JAVA安装
对于Ubuntu本身,系统上可能已经预装了JAVA,它的JDK版本为openjadk,路径为“/usr/lib/jvm/default-java”,需要配置的JAVA_HOME环境变量就可以设置这个值。
3.SSH登录权限设置
让名称节点生成自己的SSH密匙,命令如下:
ssh-keygen -t rsa -P ''
生成之后,需要将它的公共密匙发送给集群中的其他机器。我们可以将id_dsa.pub中的内容添加到需要匿名登录的机器的“~/ssh/authorized_keys”目录下,然后,在理论上名称节点就可以无密码登录这台机器了。对于无密码登录本机而言,可以采用以下的代码:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
这时就可以通过ssh localhost命令来检测一下是否需要输入密码。
4.安装单机Hadoop
解压玩hadoop文件夹后,在hadoop文件夹中,“etc/hadoop”目录下面放置了配置文件。我们只需要将JAVA_HOME环境变量指定到本机的JDK目录就可以了,命令如下:
$export JAVA_HOME=/user/lib/jvm/default-java
5.Hadoop伪分布式安装
我们需要修改core-site.xml、hdfs-site.xml这两个文件
修改后的core-site.xml文件如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
修改后的hdfs-site.xml文件如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成后,需要初始化文件系统,执行命令如下:
$./bin/hadoop namenode -format
当看到运行结果为“Exiting with status 0”之后,就说明初始化成功。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号