爬虫-面试鸭刷题神器
失业在家,刷题发现了一个好的网站,喜滋滋的血,需要登陆有点烦。F12也按不出来,怀疑浏览器坏了...后来发现是网站做了防盗。见猎心喜,开整
https://www.mianshiya.com/
先说结果:先是被封了IP、后被封了账号,哈哈
分析网站,随便点,发现网站接口不多,更加方便了爬取
重点说明:爬取网站,学习学些就行了,悠着点,别把别人服务器搞挂了
第一步、爬取分类

分析请求,发现请求链接为:
//1、获取题库分类banks
//https://api.mianshiya.com/api/question_bank/list/page/vo
传参为
Postdata = "{\"current\":1,\"pageSize\":1000}";
测试。通过
将结果遍历,获得bank_id
第二步、爬取分类的题目列表

根据分类页面,获取库的请求链接
https://api.mianshiya.com/api/question_bank/list_question
POST传参
{"current":1,"pageSize":200,"tagList":[],"questionBankId":"1787463103423897602"}

第三步、爬取题目的答案
打开单个问题页面,如下:

分析请求,这里作者做了反爬虫处理,

循环的debugger,不用理他,禁用断点调试就行了
查看具体请求
zhel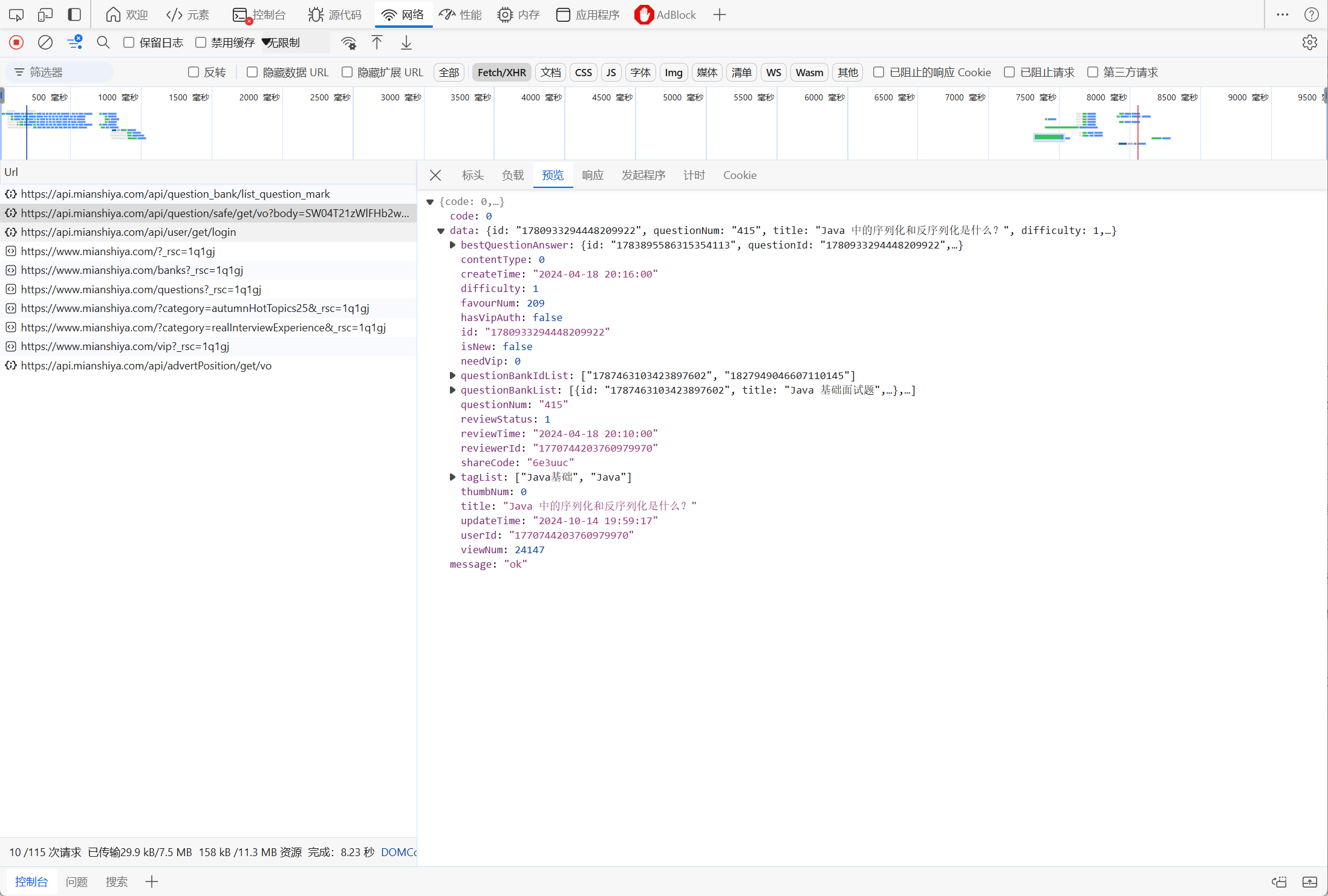
发现请求中POST传参,传递了一个加密的信息。
找找具体请求是如何发起的,搜索/api/question/safe/get/vo

总共执行了2段js,有加密,看看能不能根据结果分析过程
打上断点,ctrl+f5,再次请求页面
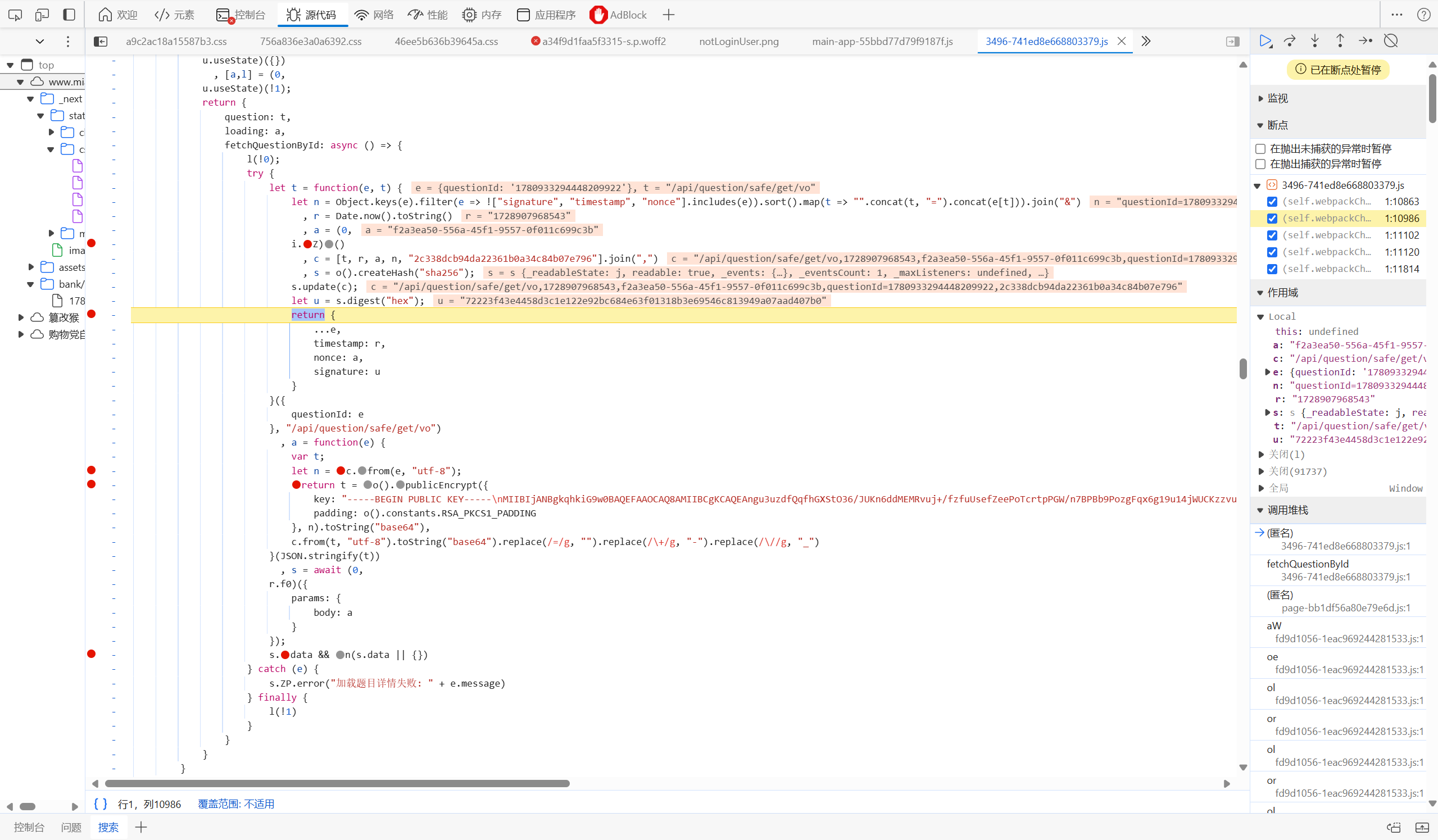
发现请求过程如上,分析总结结论
第一段方法:
n:'questionId=1780933294448209922'
r:时间戳
a:随机数,格式 'f2a3ea50-556a-45f1-9557-0f011c699c3b'
c:逗号链接字符串,结果格式'/api/question/safe/get/vo,1728907968543,f2a3ea50-556a-45f1-9557-0f011c699c3b,questionId=1780933294448209922,2c338dcb94da22361b0a34c84b07e796'
s:对c求hash,算法得到signature

返回结果:'{"questionId":"1780933294448209922","timestamp":"1728907968543","nonce":"f2a3ea50-556a-45f1-9557-0f011c699c3b","signature":"72223f43e4458d3c1e122e92bc684e63f01318b3e69546c813949a07aad407b0"}'
接下来看第二段请求:
a = function(e) { var t; let n = c.from(e, "utf-8"); return t = o().publicEncrypt({ key: "-----BEGIN PUBLIC KEY-----\nMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAngu3uzdfQqfhGXStO36/JUKn6ddMEMRvuj+/fzfuUsefZeePoTcrtpPGW/n7BPBb9PozgFqx6g19u14jWUCKzzvuAYhu5D3nX09a/MKEB+nX37xTNYHNOV4Q3r08HmSbrQoB2Kx6qhl8DNpFYGIUBYoNIA+1sV2/RsEvo1Ccnhu/7AEFIIfmcAcXrQX6e0L0eIk25t6jjgOG3lqYD3oWokjahdSyeWY6EyivRFrddkYQP0ISmvovpx4NRqIApXLgDlV2n4M5ulZshh6xqJUObT+zguk3IqjTbJnFSBZmdkMSpe0LBoGn/AOCWckKYRy268npTVmHGOo6rhAzV6DVRwIDAQAB\n-----END PUBLIC KEY-----", padding: o().constants.RSA_PKCS1_PADDING }, n).toString("base64"), c.from(t, "utf-8").toString("base64").replace(/=/g, "").replace(/\+/g, "-").replace(/\//g, "_") }(JSON.stringify(t))
定义一个方法n,将前面的结果,转json字符串,立即执行该方法.
方法内部:
1、json字符串RSA加密,转base64字符串
2、再次base64加密,去掉特定字符
.replace(/=/g, "").replace(/\+/g, "-").replace(/\//g, "_")
至此,得到了post请求的body
爬虫研究完毕。
爬虫总结:
1、循环debugger

2、构造出来的json,加密之后,就已经满足保密需求了,顶多再做一次base64,再做2此base64,是否多余?
反爬虫思考:
1、太通用的算法,不太适合web端的加密,容易被破解
2、结果内容一次返回,很容易被利用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号