

1.英文词频统
下载一首英文的歌词或文章
将所有,.?!’:等分隔符全部替换为空格
将所有大写转换为小写
生成单词列表
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
输出词频最大TOP20
将分析对象存为utf-8编码的文件,通过文件读取的方式获得词频分析内容。
f=open("text.txt","r")
song=f.read()
f.close()
sep=''',.?—!"'''
exclude={'the','and','i','in',"i'm",'a','of','an','on','to','with'}
for c in sep:
song=song.replace(c,' ')
swl=song.lower().split()
swd={}
sws=set(swl)-exclude
for w in sws:
swd[w]=swl.count(w)
fl=list(swd.items())
fl.sort(key = lambda x:x[1],reverse = True)
for i in fl:
print(i)
f=open("result.txt","w")
for i in range(20):
f.write(fl[i][0]+" "+str(fl[i][1])+"\n")
f.close()
2.中文词频统计
下载一长篇中文文章。
从文件读取待分析文本。
news = open('gzccnews.txt','r',encoding = 'utf-8')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
输出词频最大TOP20(或把结果存放到文件里)
import jieba
f = open('xiyouji.txt','r', encoding='utf-8')
text = f.read()
f.close()
p = ''',。‘’“”:;()!?、 '''
a = {
'的', '\n', '\u3000',
'曰', '之', '不', '人', '一', '大', '马', '来', '有', '于', '下', '此',
}
for i in p:
text = text.replace(i, '')
print(list(jieba.cut(text)))
t = list(jieba.lcut(text))
print(t)
count = {}
wl = list(set(t) - a)
print(wl)
for i in range(0, len(wl)):
count[wl[i]] = text.count(str(wl[i]))
cl = list(count.items())
cl.sort(key=lambda x: x[1], reverse=True)
print(cl)
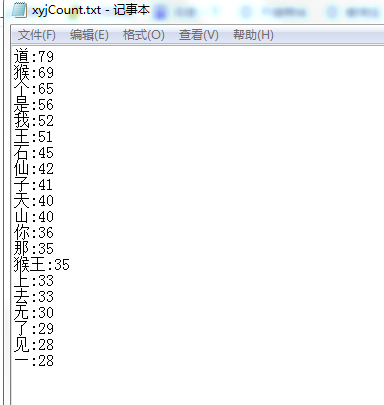
f = open('xyjCount.txt', 'a')
for i in range(20):
f.write(cl[i][0] + ':' + str(cl[i][1]) + '\n')
f.close()
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号