数据采集第三次大作业
第三次大作业
作业1
1.1实验题目
-
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
-
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图。
1.2单线程编写思路
1.2.1获取天气网主页的所有链接
因为想要实现翻页,所以开始考虑从不同地区的天气页面来进行翻页,但是得到每个地区的编号进行翻页十分麻烦,同时存在许多相同图片。
所以最后考虑从主页获得其他页面链接,从中得到图片
start_url = "http://www.weather.com.cn/"
data = getHTMLText(start_url)
html=etree.HTML(data)
#找到主页下所有a中的href属性
urlli = html.xpath("//a/@href")
因为得到的urlli中存在不是其他页面的链接,比如:

所以,使用以下代码进行筛选:
urls=[]
for url in urlli:
if(url[0:7]=="http://"):
urls.append(url)
1.2.2从链接中得到图片链接
提取每个链接中的图片链接,然后除去相同的链接,每次出现一个新的图片链接就调用下载图片的方法对图片进行下载。
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.request.urljoin(start_url,src)
if url not in urls:
count += 1
if count>15:
break
urls.append(url)
print(url)
download(url,count)
except Exception as err:
print(err)
1.2.3图片下载
file_name = url.split('/')[-1]
rep = requests.get(url)
with open("images\\"+ file_name, 'wb') as f:
f.write(rep.content)
f.close()
print("downloaded " + file_name )
1.2.4结果
控制台输出图片链接以及下载成功的提醒。

本地文件夹images下的结果。

1.3多线程编写思路
1.3.1多线程与单线程区别
主要在于要存在子进程,所以使用threads = []来存储进程,以及使用部分,代码如下:
T = threading.Thread(target=download, args=(url,))
T.setDaemon(False)
T.start()
threads.append(T)
其余部分与单线程一致。
1.3.2 结果
控制台输出图片链接以及下载成功的提醒。

本地文件夹images下的结果。

1.4完整代码
https://gitee.com/q_kj/crawl_project/tree/master/third
1.5小结
这题开始困扰我的主要在于如何进行翻页,如果对地区天气界面进行翻页太过于复杂,所以最后从主界面中提取其他页面链接进行爬取。其他部分参考课上的代码进行修改便可。
作业2
2.1实验题目
-
要求:使用scrapy框架复现作业①。
-
输出信息:
同作业1
2.2思路
2.2.1 items.py
class WeatherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
imag = scrapy.Field()
imag用于存储图片的链接。
2.2.2MySpider.py
parse函数主要用于获得主页面所有其他页面的链接。
urls=[]
#先找到主页上所有的a标签下的herf属性
urllib = response.xpath("//a/@href").extract()
for url in urllib:
#因为有些herf属性的结果不是链接,所以进行筛选,结果存入urls
if (url[0:7] == "http://"):
if url not in urls:
urls.append(url)
#对每个链接调用图片爬取的函数
for url in urls:
if self.count<135:
yield scrapy.Request(url=url,callback=self.imageSpider)
imageSpider函数主要用于获得页面所有图片的链接。
imgurl=[]
#提取每个img标签中的src属性中的图片链接
img_url = reponse.xpath("//img//@src").extract()
#if self.count>=135:
#return
for url in img_url:
#不确定每个都是否是链接,就进行了筛选
if (url[0:7] == "http://"):
#排除重复的标签
if url not in imgurl:
self.count += 1
#如果图片大于135,就不行添加
f self.count < 135:
imgurl.append(url)
for url in imgurl:
item = WeatherItem()
item["imag"] = url
yield item
2.2.3 pipelines.py
开启spideropen_spider:
def open_spider(self,spider):
print("opened")
self.opened=True
self.count=0
关闭spiderclose_spider:
def close_spider(self,spider):
if self.opened:
self.opened=False
print("closed")
print("总共爬取",self.count,"张图片")
上诉部分是对老师所给ppt中的代码进行改写后的。
process_item实现图片的下载:
self.count = self.count + 1
img=item["imag"]
print(img)
#if self.count>135:
#self.close_spider()
if self.opened:
try:
#将图片下载到本地文件夹中
rep = requests.get(img)
file_name = img.split('/')[-1]
with open("images\\" + file_name, 'wb') as f:
f.write(rep.content)
f.close()
print("downloaded " + file_name)
2.2.4结果
控制台信息:
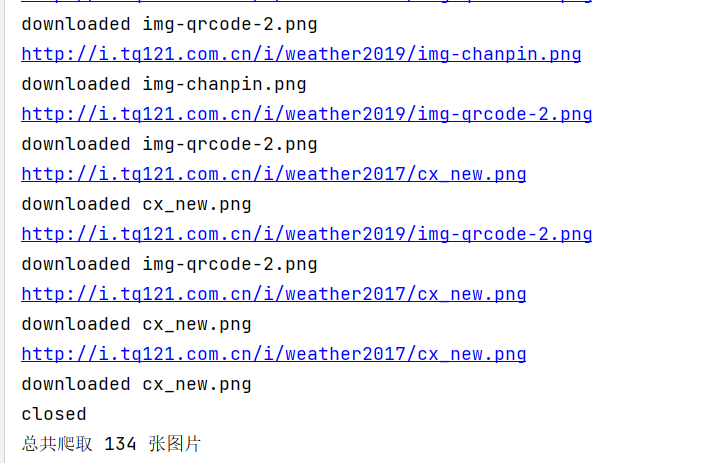
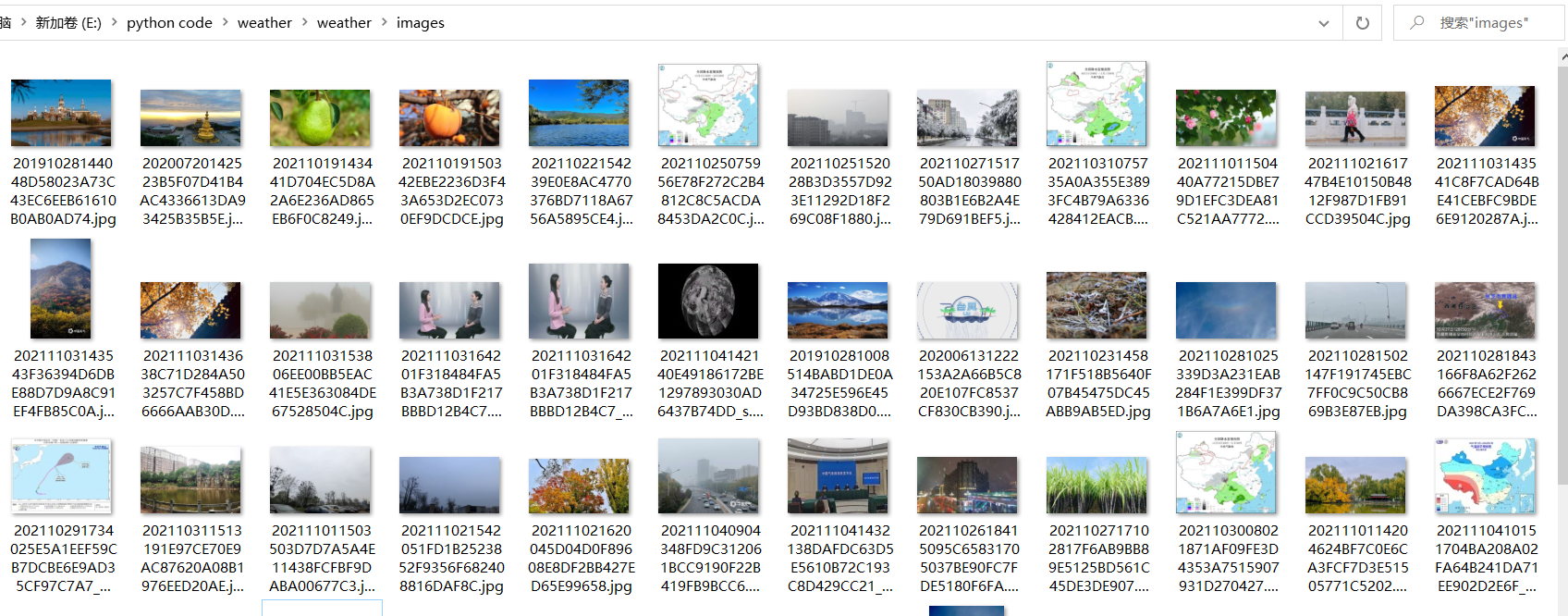
images文件夹下结果:
2.3完整代码
https://gitee.com/q_kj/crawl_project/tree/master/weather
2.4小结
第二题和第一题十分相似,第二题主要在于scrapy框架中的各个文件的编写。
作业3
3.1实验题目
-
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在
imgs路径下。
-
输出信息:
序号 电影名称 导演 演员 简介 电影评分 电影封面 1 肖申克的救赎 弗兰克·德拉邦特 蒂姆·罗宾斯 希望让人自由 9.7 ./imgs/xsk.jpg 2....
3.2思路
3.2.1 item.py
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
rank = scrapy.Field()
movie_name = scrapy.Field()
director = scrapy.Field()
actors = scrapy.Field()
brief_introduction = scrapy.Field()
grade = scrapy.Field()
imag = scrapy.Field()
3.2.2 spider.py
通过xpath提取各个部分的内容:
rank = response.xpath("//div[@class='pic']/em/text()").extract() #排名
name = response.xpath("//div[@class='hd']/a/span[1]/text()").extract() #电影名字
dir_acts = response.xpath("//div[@class='bd']/p[1]/text()").extract() #因为导演和演员信息混在一起,所以需要再次提取
brief_intro = response.xpath("//div[@class='bd']/p[2]/span/text()").extract() #简介
grade = response.xpath("//div[@class='bd']/div[@class='star']/span[@class='rating_num']/text()").extract() #评分
img = response.xpath("//div[@class='pic']/a/img/@src").extract() #电影封面图片链接
然后问题在于通过上面得到的导演和主演的信息混在一起,同时还有其他信息,如下图:

所以需要再次对其进行提取:
dname = [] #用来存导演名
aname = [] #用来存主演名
count = 0 #用于后面区分dir_acts中的奇偶
#发现每一个电影的dir_act都窜在两个部分,第一部分是导演和主演,第二部分是地区和日期等
#所以考虑提取dir_acts中的偶数部分,即导演和主演
for dir_act in dir_acts:
count += 1
if (count % 2 != 0):
#导演和主演之间存在"\xa0\xa0\xa0",所以以此分割成两部分
dir_act = dir_act.strip().split('\xa0\xa0\xa0')
#提取出的第一部分去除”导演:“,存入dname中
dname.append(dir_act[0].split('导演:')[1])
# 提取出的第二部分去除”主演:“,存入aname中
aname.append(dir_act[1].split('主演:')[1])
elif (count % 2 == 0):
continue
然后将最终结果存入item中:
item = DoubanItem()
item["rank"] = int(rank[i])
item["movie_name"] = name[i]
item["director"] = dname[i]
item["actors"] = aname[i]
item["brief_introduction"] = brief_intro[i]
item["grade"]=grade[i]
item["imag"] = img[i]
yield item
最后在于翻页:
#实现翻页,https://movie.douban.com/top250?start=(?)&filter=,?中正好是25的倍数,以此实现翻页
url_f="https://movie.douban.com/top250"
for i in range(1,10):
url=url_f+"?start="+str(i*25)+"&filter="
#得到下一页的url,回调parse,继续上面的操作
yield scrapy.Request(url=url,callback=self.parse)
3.2.3pipelines.py
open_spider:打开spider,同时创建数据库和表。
def open_spider(self,spider):
print("opened")
try:
#与数据库进行连接,创建douban数据库
self.con = sqlite3.connect("douban.db")
self.cursor = self.con.cursor()
#创建表
self.cursor.execute("create table douban(排名 int(4),电影名 varchar(25),导演 varchar(30),主演 varchar(70),简介 varchar(70),评分 varchar(8),封面 varchar(80))")
self.opened = True
except Exception as err:
print(err)
self.opened=False
close_spider:用于关闭spider。
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
process_item:用于插入数据和下载图片。
#向表中插入item中的数据
self.cursor.execute("insert into douban(排名,电影名,导演,主演,简介,评分,封面)values(?,?,?,?,?,?,?)",(item['rank'],item['movie_name'],item['director'],item['actors'],item['brief_introduction'],item['grade'],item['imag']))
#将电影封面存入本地文件夹中
rep = requests.get(img)
print(img)
#将封面名设为电影名
file_name = item['movie_name']
with open("images\\" + file_name+".jpg", 'wb') as f:
f.write(rep.content)
f.close()
print("downloaded " + file_name)
3.2.4结果
控制台信息:

数据库结果:

images本地文件夹照片结果:

3.3完整代码
https://gitee.com/q_kj/crawl_project/tree/master/douban
3.4小结
因为之前代码一直爬取不成功,所以多次爬取,最后提示检测到有异常请求从你的 IP 发出,然后登陆豆瓣,虽然没有这个提醒,但又显示了Crawled (403) <GET https://movie.douban.com/top250> (referer: None),根据https://www.cnblogs.com/guanguan-com/p/13540188.html这个链接中的方法成功解决。所以在爬虫时一定要注意:先爬取部分页面内容,正确性测试,没有问题了,联网爬取 爬取要设时间等待,限制速度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号