


跟我学ShardingSphere之数据分片策略
在前面一篇《跟我学ShardingSphere之SpringBoot + ShardingJDBC分库》我们介绍了如何利用ShardingJDBC进行分库,用到了inline行表达式分片策略,ShardingSphere还有其他几种分片策略,下面我们来介绍一下
分片键
用于分片的字段,是将数据库或表拆分的字段,比如,我可以使用user_id作为分片键将用户数据分到不同的表中,这里的user_id就是分片键,除了这种单字段分片,ShardingSphere还支持多个分片字段。SQL中如果没有分片字段,将执行全路由,也就是会把SQL发送到所有的数据分片上执行,性能较差。
分片算法
分片算法描述的是如何进行分片,需要结合分片键使用,比如我需要使用user_id对2取模进行分表,那么这里取模就是分片算法,ShardingShpere支持>、<、=、IN和Between分片。这些分片算法需要根据实际的业务开发,ShardingSphere没有默认的分片算法,所以你得根据自己的业务来开发自己的分片算法,不过也挺简单的,ShardingSphere已经预留好了对应的接口,你实现对应的接口就好了
目前ShardingSphere将常用的分片算法进行抽象,定义了四种分片算法
1、精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
2、范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合StandardShardingStrategy使用。
3、复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
4、Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用
分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略
1、标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND, >, <, >=, <=分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
2、复合分片策略
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
3、行表达式分片策略
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
4、Hint分片策略
对应HintShardingStrategy。通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略
5、不分片策略
对应NoneShardingStrategy。不分片的策略。
分片示例
我们还是通过一个分表的示例来演示一下,如何根据自己的需求来开发自己的分片算法
需求:业务上存在多个分支机构,需要将不同分支的客户拆分到不同的表
分析:通过需求可知,这是个单分片的需求,我们选择标准分片就可以满足需求
1、先建表
CREATE TABLE `tb_cust` (
`cust_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`cust_name` varchar(20) NOT NULL COMMENT '用户名称',
`branch_id` char(3) NOT NULL COMMENT '分公司',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`cust_id`)
) ENGINE=InnoDB AUTO_INCREMENT=202 DEFAULT CHARSET=utf8 COMMENT='客户信息表';
按不同的分支机构建不同的表

从表名可以看出来,我们有fc5、fdg、fdm、fdw这几个分支机构
2、分片算法
标准分片策略需要实现PreciseShardingAlgorithm接口
/**
* 精确分片算法(可用于分库、分表)
* 公众号【Java天堂】
*/
public class BranchPreciseShardingAlgorithm implements PreciseShardingAlgorithm<String> {
@Override
public String doSharding(Collection<String> shardingNameList, PreciseShardingValue<String> preciseShardingValue) {
String key = preciseShardingValue.getValue();
//遍历所有的数据分片,与分片键(key)比较,匹配就返回当前数据分片
for(String shardingName : shardingNameList){
if(shardingName.endsWith(key.toLowerCase())){
return shardingName;
}
}
throw new IllegalArgumentException();
}
}
3、分片策略配置
server:
port: 8090
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: testdb0,testdb1
testdb0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/testdb0?useUnicode=true&characterEncoding=utf-8
username: root
password: 123456
testdb1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/testdb1?useUnicode=true&characterEncoding=utf-8
username: root
password: 123456
# 分库、分表配置
sharding:
tables:
tb_cust:
actual-data-nodes: testdb0.tb_cust_$->{['fdg','fc5','fdw','fdm']}
# 分表配置
table-strategy:
standard:
sharding-column: branch_id
precise-algorithm-class-name: com.kxg.shardingRule.BranchPreciseShardingAlgorithm
props:
sql.show: true
从上面的配置可以看出来,我们分表的策略不再是inline,而是换成standard,表示标准分片策略
分片策略也换成了我们自己写的分片算法:BranchPreciseShardingAlgorithm
@Data
@TableName("tb_cust")
public class Cust {
private Long custId;
private String custName;
private String branchId;
}
public interface CustMapper extends BaseMapper<Cust> {
}
@Service
public class CustService {
@Autowired
private CustMapper custMapper;
public void insert(Cust cust){
int count = custMapper.insert(cust);
System.out.println("insert count:" + count);
}
public Cust getCust(Long custId){
return custMapper.selectById(custId);
}
}
@RestController
public class CustController {
@Autowired
private CustService custService;
@RequestMapping("/cust/add")
public String addUser(@RequestBody Cust cust){
custService.insert(cust);
return "ok";
}
@RequestMapping("/cust/get")
@ResponseBody
public Cust getUser(Long custId){
return custService.getCust(custId);
}
}
启动程序,可以看到如下打印:
tables:
tb_cust:
actualDataNodes: testdb0.tb_cust_$->{['fdg','fc5','fdw','fdm']}
logicTable: tb_cust
tableStrategy:
standard:
preciseAlgorithmClassName: com.kxg.shardingRule.BranchPreciseShardingAlgorithm
shardingColumn: branch_id
表示已经加载配置成功
我们试着添加两个Cust信息,如下
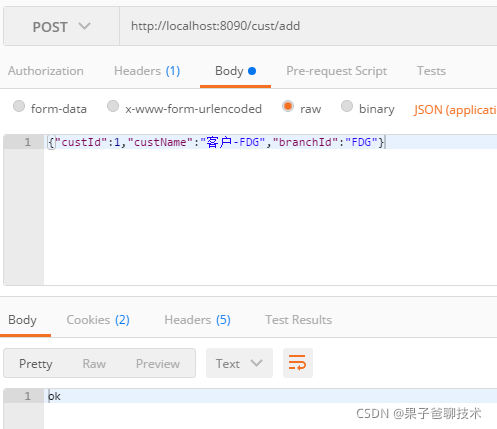
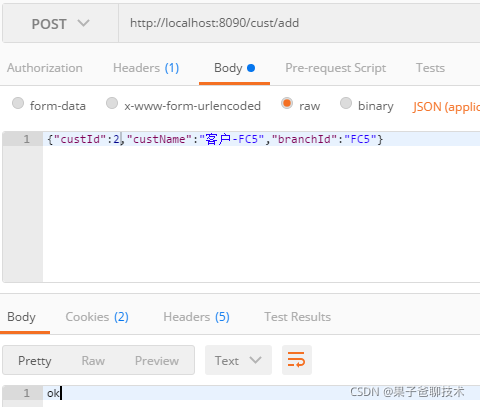
我们可以看到控制台打印的SQL语句:
Logic SQL: INSERT INTO tb_cust ( cust_id,cust_name,branch_id ) VALUES ( ?,?,? )
Actual SQL: testdb0 ::: INSERT INTO tb_cust_fdg ( cust_id,cust_name,branch_id ) VALUES (?, ?, ?) ::: [1, 客户-FDG, FDG]
Logic SQL: INSERT INTO tb_cust ( cust_id,cust_name,branch_id ) VALUES ( ?,?,? )
Actual SQL: testdb0 ::: INSERT INTO tb_cust_fc5 ( cust_id,cust_name,branch_id ) VALUES (?, ?, ?) ::: [2, 客户-FC5, FC5]
从执行的SQL可以看到,是根据我们的预期进行分表操作的,下面去数据库对应的表查看一下对应的数据是不是正确插入
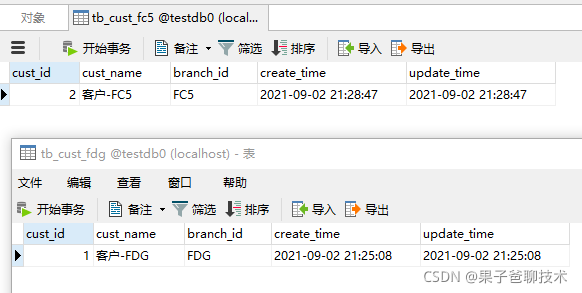
可以看到,两次的数据根据不同的branchId字段插入到不同的表中,达到了根据branchId分表的目的
如果感觉对你有些帮忙,请收藏好,你的关注和点赞是对我最大的鼓励!
如果想跟我一起学习,坚信技术改变世界,请关注【Java天堂】公众号,我会定期分享自己的学习成果,第一时间推送给您



 浙公网安备 33010602011771号
浙公网安备 33010602011771号