Scrapy——5 下载中间件常用函数、scrapy怎么对接selenium、常用的Setting内置设置有哪些
Scrapy——5
(Downloader Middleware)下载中间件常用函数有哪些


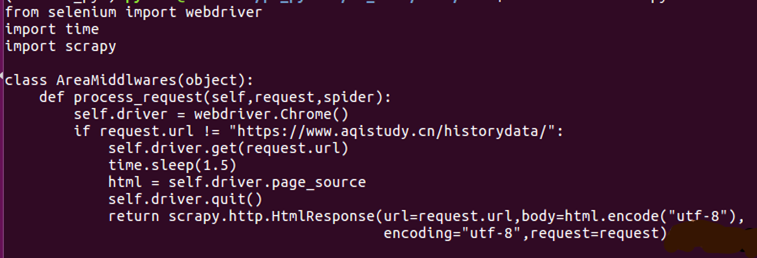
设置setting.py里的DOWNLOADER_MIDDLIEWARES,添加自己编写的下载中间件类

详情可以参考https://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/settings.html#concurrent-items
-
CONCURRENT_REQUESTS
- 默认:
16 - Scrapy downloader 并发请求(concurrent requests)的最大值。
-
CONCURRENT_ITEMS
- 默认:
100 - Item Processor(即 Item Pipeline) 同时处理(每个response的)item的最大值。
-
DOWNLOAD_TIMEOUT
- 默认:
180 - 下载器超时时间(单位: 秒)。
-
DOWNLOAD_DELAY
- 默认:
0 - 下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度, 减轻服务器压力。同时也支持小数:
DOWNLOAD_DELAY = 0.25 # 250 ms of delay
- 该设定影响(默认启用的)
RANDOMIZE_DOWNLOAD_DELAY设定。 默认情况下,Scrapy在两个请求间不等待一个固定的值, 而是使用0.5到1.5之间的一个随机值 *DOWNLOAD_DELAY的结果作为等待间隔。 - 当
CONCURRENT_REQUESTS_PER_IP非0时,延迟针对的是每个ip而不是网站。 - 另外您可以通过spider的
download_delay属性为每个spider设置该设定。
-
LOG_ENCODING
- 默认:
'utf-8' - logging使用的编码。
-
ITEM_PIPELINES
- 默认:
{} - 保存项目中启用的pipeline及其顺序的字典。该字典默认为空,值(value)任意。 不过值(value)习惯设定在0-1000范围内。
-
COOKIES_ENABLED
- 默认:
True - 是否启用cookies middleware。如果关闭,cookies将不会发送给web server。
对接selenium实战——PM2.5历史数据_空气质量指数历史数据_中国空气质量在线监测分析平...
此网站的数据都是通过加密传输的,我们可以通过对接selenium跳过数据加密过程,直接获取到网页js渲染后的代码,达到数据的提取
唯一的缺点就是速度太慢
- 首先创建项目(光标所在的文件是日志文件)
本次实战旨在selenium的对接,就不考虑保存数据的问题,所以不用配置items文件
- /area/area/settings.py 设置无视爬虫协议,设置对应下载中间件的激活,日志等级(设置日志等级后运行程序会生成相应的日志信息,主要的作用是为了屏蔽程序运行时过多的日志,方便观察运行结果)
![]()
![]()
![]()
- /area/area/spiders/aqistudy.py 直接编写代码
# -*- coding: utf-8 -*- import scrapy class AqistudySpider(scrapy.Spider): name = 'aqistudy' # allowed_domains = ['aqistudy.cn'] start_urls = ['https://www.aqistudy.cn/historydata/'] def parse(self, response): print('开始获取主要城市地址...') city_list = response.xpath("//ul[@class='unstyled']/li/a/@href").extract() for city_url in city_list[1:3]: yield scrapy.Request(url=self.start_urls[0]+city_url, callback=self.parse_month) def parse_month(self, response): print('开始获取当前城市的月份地址...') month_urls= response.xpath('//ul[@class="unstyled1"]/li/a/@href').extract() for month_url in month_urls: yield scrapy.Request(url=self.start_urls[0]+month_url, callback=self.parse_day) def parse_day(self, response): print('开始获取空气数据...') print(response.xpath('//h2[@id="title"]/text()').extract_first()+'\n') item_list = response.xpath('//tr')[1:] for item in item_list: print('day: '+item.xpath('./td[1]/text()').extract_first() + '\t' + 'API: '+item.xpath('./td[2]/text()').extract_first() + '\t' + '质量: '+item.xpath('./td[3]/span/text()').extract_first() + '\t' + 'MP2.5: '+item.xpath('./td[4]/text()').extract_first() + '\t' + 'MP10: '+item.xpath('./td[5]/text()').extract_first() + '\t' + 'SO2: '+item.xpath('./td[6]/text()').extract_first() + '\t' + 'CO: '+item.xpath('./td[7]/text()').extract_first() + '\t' + 'NO2: '+item.xpath('./td[8]/text()').extract_first() + '\t' + 'O3_8h: '+item.xpath('./td[9]/text()').extract_first() )
- /area/area/middlewares.py 设置下载中间件
- 程序代码发起requests的时候,都会经过中间件,所以用了一个 if 'month' in request.url:来区分
- 此处对接的是PhantomJS,也可以用别的驱动程序,用Chrome的话,一定也要记得设置无窗口模式,否则会不同的弹出窗口,更多关于selenium启动项的知识,可以参考此处
- middlewares.py用到的类是自定义的,所以在前面的设置中,激活的是相应的中间件
# -*- coding: utf-8 -*- # Define here the models for your spider middleware # # See documentation in: # https://doc.scrapy.org/en/latest/topics/spider-middleware.html import time from selenium import webdriver import scrapy from scrapy import signals class AreaSpiderMiddleware(object): ...... class AreaDownloaderMiddleware(object): ...... class AreaMiddleware(object): def process_request(self, request, spider): self.driver = webdriver.PhantomJS() if 'month' in request.url: self.driver.get(request.url) time.sleep(2) html = self.driver.page_source self.driver.quit() return scrapy.http.HtmlResponse(url=request.url, body=html,request=request, encoding='utf-8' )
- 因为笔者的虚拟机是服务器模式(命令行窗口,无法运行selenium),所以程序是在Windows中运行的。在项目文件中的main.py文件,就是一个运行程序的文件
- 这几行就可以将scrapy的多个程序综合在一个程序中运行了,前提是你为你的Windows安装了selenium的相应驱动和Scrapy库
# -*- coding: utf-8 -*- # @Time : 2018/11/12 16:56 # @Author : wjh # @File : main.py from scrapy.cmdline import execute execute(['scrapy','crawl','aqistudy'])



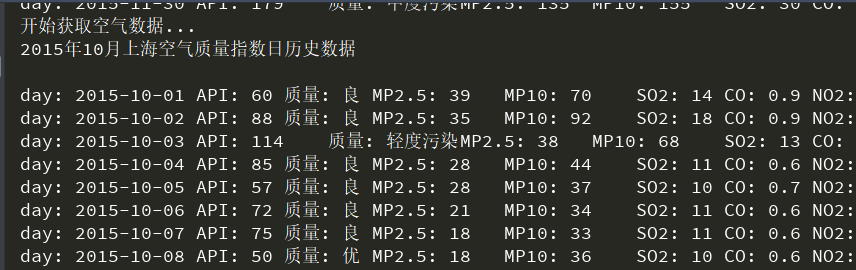
运行结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号