(开集检测系列)Open Vocabulary Object Detection with Pseudo Bounding-Box Labels
利用图文大模型给caption数据打bbox伪标签扩展数据,进而训练开集检测模型
1、动机
开集检测,在大规模caption数据集上预训练的网络有很强的开放分类能力,所以需要使用caption数据,但是caption数据没有box,所有怎么自动化生成caption的box信息
2、方法
2.1、伪box生成
总体过程如下:


+1、由预训练视觉文本模型ALBEF生成相关图,进而生成相关bbox
给定输入caption数据:image和caption,计算出一个图片对caption中的object相关性的activation map激活图,然后由activation map激活图生成包含该object的box区域;图片对caption中object相关图计算见2.2
+2、由MaskRCNN with ResNet50 train on COCO2017提取proposal
+3、proposal和object相关图box交集最大的作为伪标签bbox
2.2、caption中object activation map
- 1、注意力矩阵
visual embedding和text embedding输入到multi-model encoder中,其中输入的text embedding为X = {x1, x2, ..., xNT },T ∈ R^(NT ×d),NT为word个数(包含[CLS]和[SEP]),image embedding为V ∈ R^(NV×d);
multi-model encoder为L层cross-attention层,交互过程如下2个公式,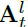 为l层的attention score,
为l层的attention score,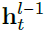 为l-1层获得表征,
为l-1层获得表征,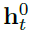
为输入的text embedding,总的来说,h为Q,image embedding为K,V;注意力得分矩阵反应对token在image不同区域上的关注度,因此可以根据这个注意力得分来定位caption中object的位置
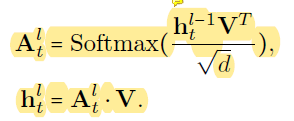
以上注意力得分矩阵是caption中所有object的注意力得分 - 2、activation map
使用Grad-CAM计算activation map,计算方式为 image和caption相似度的标量s对attention score的梯度。公式如下:
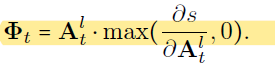
3 数据集
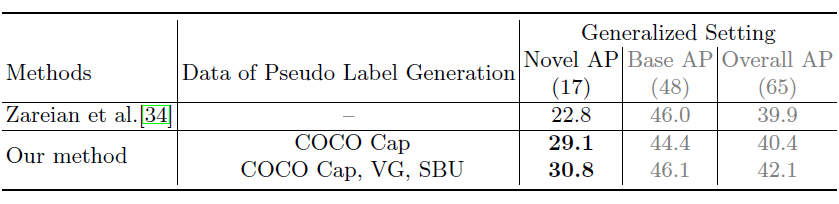
训练集:COCO Caption [3], Visual-Genome [14], and SBU Caption,
测试集:COCO,PASCAL,
Object Vocabulary:all the object names in COCO, PASCAL VOC, Objects365 and LVIS, resulting in 1,582 categories
4、效果
5、消融实验
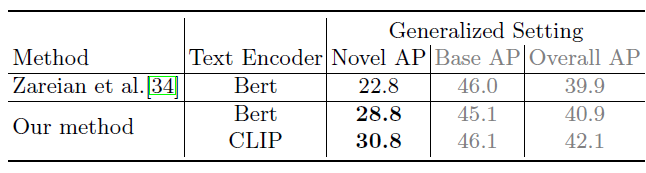
1、text encoder
CLIP比BERT效果好的原因可能是CLIP在image-caption pair数据上训练的;同伪标签生成的多模态网络结论一样
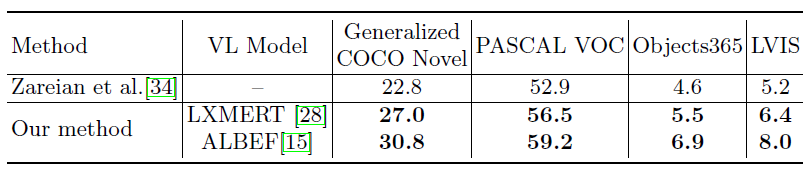
2、生成伪标签多模态网络选择
如果多模态网络ALBEF也是用image-caption训练,效果更好,同text encoder结论一样
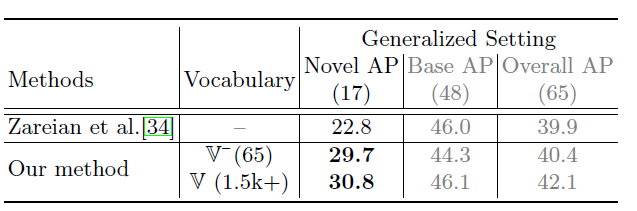
3、训练类别Object Vocabulary多少的影响
加入COCO验证集之外的类别对最终结果也有促进作用
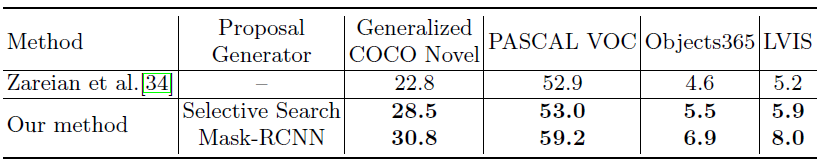
4、伪标签的影响
伪标签的加入比baseline效果好,且伪标签质量越好最后结果越好(Mask-RCNN效果比无监督Selective Search效果好)
遗留问题:
- 1、Mask r-cnn生成的所有proposal,这个在COCO训练的Mask rcnn怎么保证类无关的把所有物体proposal给取出来
- 2、ALBEF 多模态融合层生成的相关图能把关注的object给选出来吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号