(开集检测系列)GLIPv2: Unifying Localization and VL Understanding
一句话概括:既GLIP统一了目标检测和phrase grounding任务,GLIP2进一步统一了VL理解任务(VQA和caption);好处是:VL learn任务给phase grounding带来的好处,是grounding性能更好了;phase grounding任务给VL learn带来的好处是有可解释性和容易debug
1、问题
当前localization和VL understand统一模型效果不好,原因是
- 1、这2个任务差异:localization只需要图像信息和细粒度的结果(bbox/mask),而VL understand任务需要视觉和文本融合和高语义的输出;
- 2、当前主流的融合模型都是一个localization是单模态,VLunderstand是双模态,具体来说是low-level 视觉backbone+2个high-level独立的处理分支分别处理localization和VL理解任务
2、介绍和实现
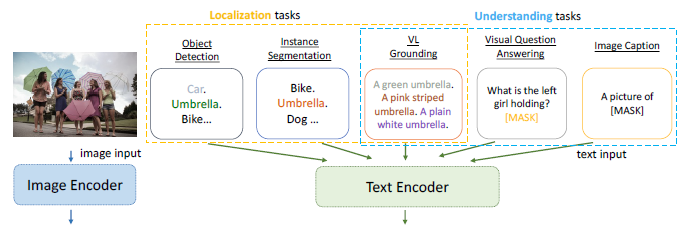

2.1 模型的统一
如上图VL grounding(语句的理解+语句中实体的定位)作为localization和VL understanding的meta 能力,基于该meta能力
1、对MLM预训练,只需要在text feature的P后面加2层的MLP作为MLM检测头;
2、对目标检测或者phrase grounding任务,和GLIP一致使用classifaction-to-matching统一检测和grounding任务,这2个任务输入差别是检测任务输入时类别的concat,grounding任务是语句
2.2 数据的统一
Localization数据(包含localizaion+语义类别),语义类别通过classification-to-matching转化为VL理解数据(各类别的cancat)。
VL理解数据(图片+语句),通过self-training生成localization(bbox+mask)数据,转为为VL理解数据
2.3 其他增强
GLIP不足:仅照片内的phase和region对比,由于负样本少,没有充分利用数据信息,因此GLIP2引入inter-image 一个batch内图片见所有的phase和region的对比学习来学习更加鲁邦的region-word特征
2.3 loss统一

2.4 应用
训练好之后在任务上的应用:
- 1、检测任务,直接使用
- 2、VL任务:
VQA,在隐藏表征前面加分类头进行finetune
caption生成任务,使用单向语言模型的loss来回归出剩下的文本
2.5 效果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号