【backbone】RepVGG
https://zhuanlan.zhihu.com/p/344324470
VGG-16在加上BN等组件,ImageNet最好性能是 72% top-1 accuracy。
** 主要贡献是:
1、CNN现状:在VGG模型在ImageNet分类 top-1精准率大于70%之后,为了达到更好的性能,设计多支路的CNN网络设计是个趋势,比如2分支的ResNet,更复杂的DenseNet等。
2、VGG网络和多支路CNN网络各有优缺点,VGG网络优势的运行速度快,内存占用低(下有说明)
RepVGG:1、只有3x3卷积和RELU 单一类型操作,可以集成到芯片上的计算单元越多,运算快 2、给定芯片大小和功耗,因为单一类型操作,可以集成更多的计算单元 3、占用的内存更少
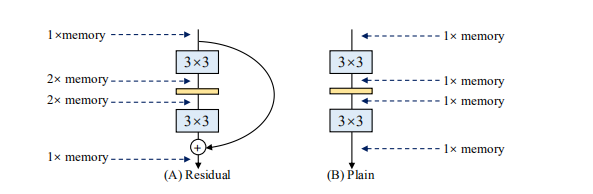
多支路网络性能好
本文结合这2中网络的优势,在训练阶段使用多支路架构,在预测阶段使用类似VGG单路窜行架构,预测阶段的RepVGG串行架构只使用3x3卷积和Relu串行搭建的网络(类似VGG),在速度和性能上达到SOTA水平,在ImageNet上超过80%正确率。**
3、要达到训练阶段使用分支架构,预测阶段使用窜行架构,需要将训练阶段的分支架构转为预测阶段的窜行架构,本文使用的方法是结构重参数化
4、结构重参数化
速度:
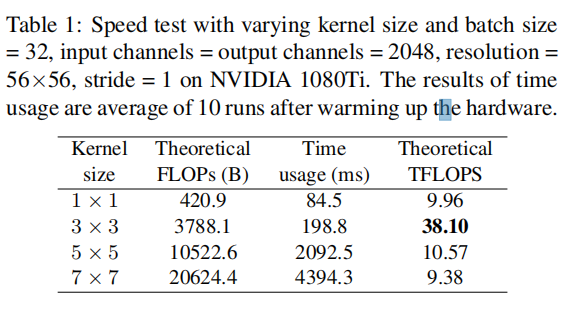
RepVGG仅使用3×3 conv,因为它被一些现代计算库(如NVIDIA)高度优化,比如Nvidia的cuDNN,计算密度(理论运算量除以所用时间)
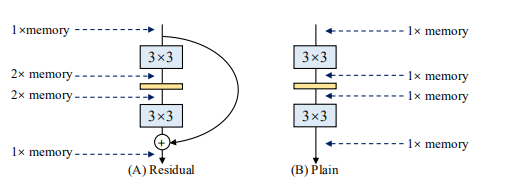
内存:
Residual峰值是2倍的输入,Plain是1倍的输入
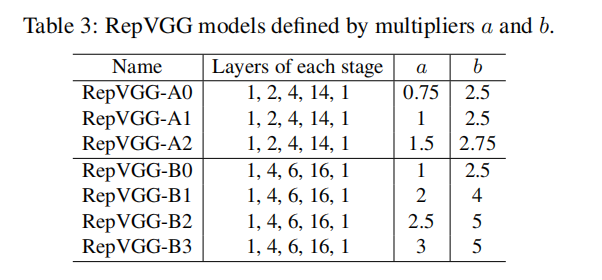
总共分5个stage,各stage层数设计的原则是:
网路深度设计:
1、第一个stage的分辨率很高,这很耗时,因此我们只使用一层来降低延迟
2、最后一个stage应具有更多通道,因此我们只使用一层来保存参数
3、最后一个stage前面层加了整个网络的大部分层,
网络宽度设计:
1、均匀缩放的经典宽度 [64, 128, 256, 512] (e.g., VGG and ResNets).
2、缩放乘以a作为前四个阶段宽度,乘以b作为最后一个stage宽度,通常设置b>a,因为最后一层具有更丰富的特征用于分类或其他下游任务;且RepVGG最后stage只有一层,不会明显增加延迟或参数的数量
设计案例:
the width of stage2, 3, 4, 5 is [64a, 128a, 256a, 512b],为了避免在高分辨率特征图上大量的卷积运算,通常stage1会缩小特征图,即a<1,或者 min(64, 64a).
和vgg不同的地方时没用使用 max pooling,因为我们希望身体只有一种类型的操作符
图像分类任务,在head里使用了全局的平均池化和全连接层global average pooling followed by a fully-connected layer as the head。
效果:
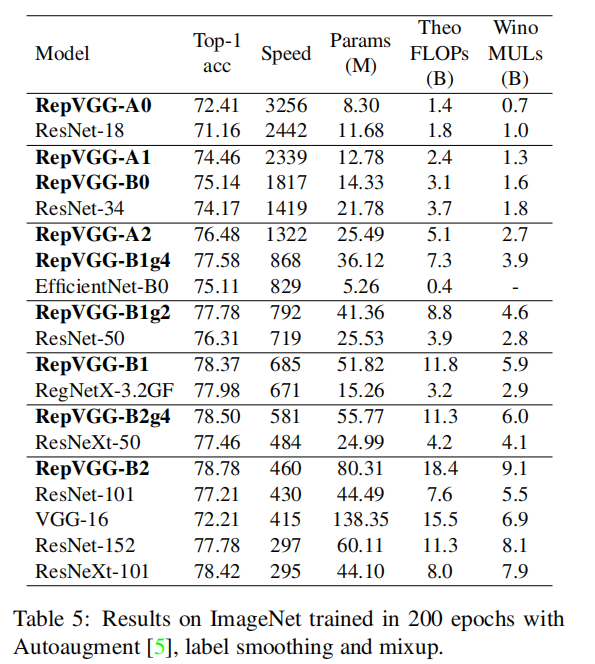
适用范围:
值得注意的是,本文不仅证明了普通模型可以很好地收敛,而且不打算像resnet那样训练极深的convnet。 相反,我们的目标是建立一个具有合理深度和良好精度-速度权衡的简单模型,该模型可以通过最常见的组件(例如,正则conv和BN)和简单代数简单实现
Notably, this paper is not merely a demonstration that plain models can converge reasonably well, and does not intend to train extremely deep ConvNets like ResNets.
Rather, we aim to build a simple model with reasonable depth and favorable accuracy-speed trade-off, which can be simply implemented with the most common components (e.g., regular conv and BN) and simple algebra

 浙公网安备 33010602011771号
浙公网安备 33010602011771号