

使用Linux(客户端)去连接服务端的hdfs 、hive数据库 (带有Kerberos认证的)
前置条件:保证客户端和服务端的hdfs网络都能通 、同时把对应的hosts映射配置到客户端的/etc/hosts里面 、客户端有JDK (1.8版本或以上)
以下是在Ubuntu系统上,命令有的可能不太一样 根据自己的来。
1、安装Hadoop
首先下载Hadoop文件包
官方下载地址:https://archive.apache.org/dist/hadoop/common/
我这里用的是Hadoop-3.1.3版本

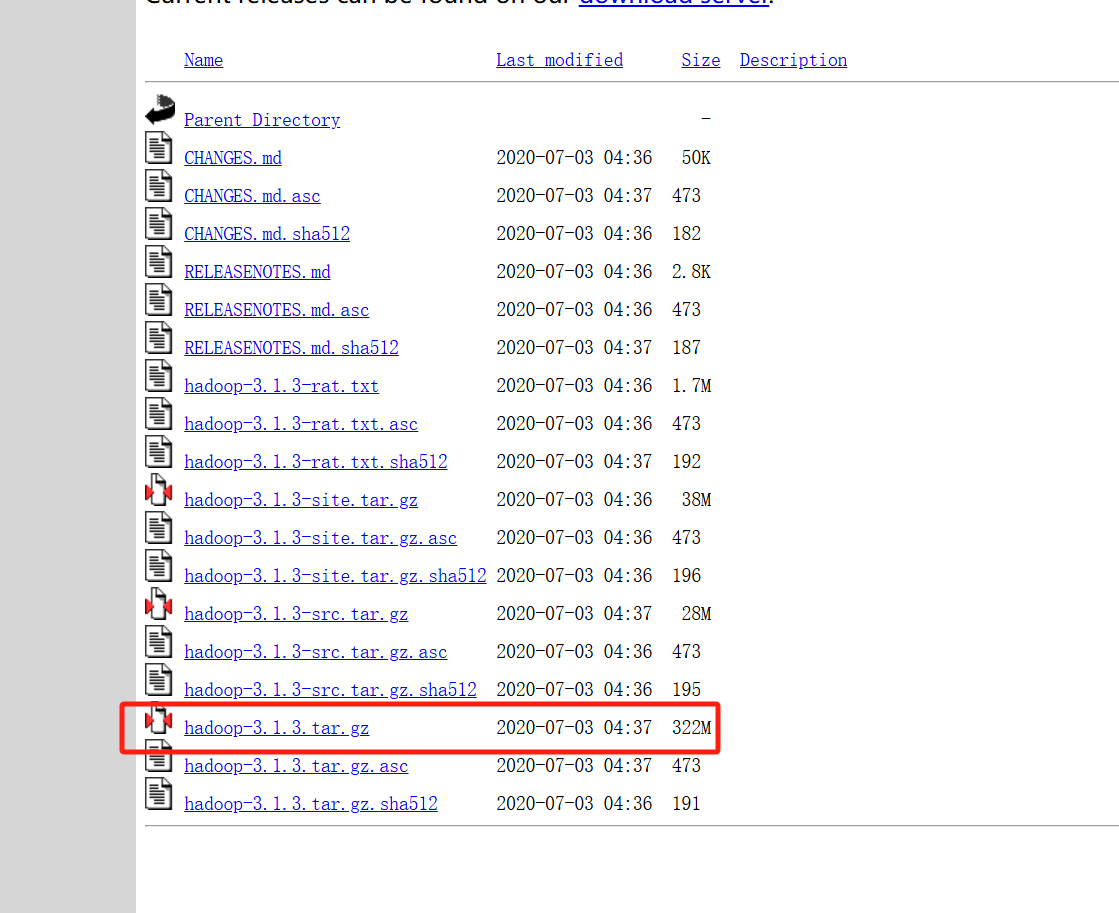
下载完成后,上传到客户端进行解压 我的目录是在/config底下 根据自己的来

为了方便使用 Hadoop,需要设置一些环境变量。
编辑 .bashrc 文件(如果你希望该设置对当前用户有效) 如果所有生效 修改 /etc/profile
修改配置文件
vim ~/.bashrc
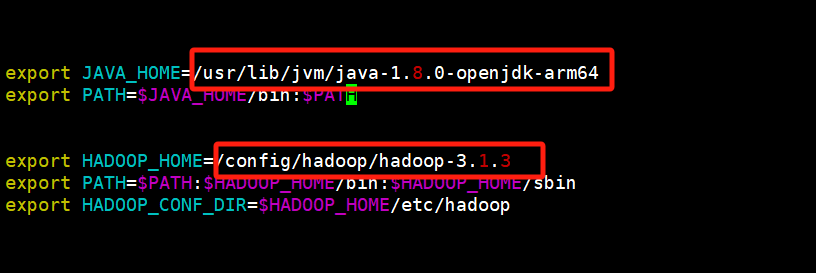
添加以下内容 路径 根据自己的来
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-arm64 export PATH=$JAVA_HOME/bin:$PATH export HADOOP_HOME=/config/hadoop/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
说明:
JAVA_HOME:这个是java的目录 因为系统是安装了两个版本的jdk 所以这里单独配置下 决定用那个 如果没有这种情况 可以不加
HADOOP_HOME: 这个就是刚才下载hadoop-3.1.3的版本的目录
然后保存 退出 执行下列命令 并让他生效
source ~/.bashrc
好了之后 执行下命令
hadoop
如果出现
abc3 ~ $ hadoop ERROR: JAVA_HOME is not set and could not be found.
这个就把上面JAVA_HOME的环境变量配置下 配置好之后 要重新执行source命令进行生效
如果好了 会显示以下内容
abc@63140424e8c3 ~/hadoop/hadoop-3.1.3 $ hadoop Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS] or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS] where CLASSNAME is a user-provided Java class OPTIONS is none or any of: --config dir Hadoop config directory --debug turn on shell script debug mode --help usage information buildpaths attempt to add class files from build tree hostnames list[,of,host,names] hosts to use in slave mode hosts filename list of hosts to use in slave mode loglevel level set the log4j level for this command workers turn on worker mode SUBCOMMAND is one of: Admin Commands: daemonlog get/set the log level for each daemon Client Commands: archive create a Hadoop archive checknative check native Hadoop and compression libraries availability classpath prints the class path needed to get the Hadoop jar and the required libraries conftest validate configuration XML files credential interact with credential providers distch distributed metadata changer distcp copy file or directories recursively dtutil operations related to delegation tokens envvars display computed Hadoop environment variables fs run a generic filesystem user client gridmix submit a mix of synthetic job, modeling a profiled from production load jar <jar> run a jar file. NOTE: please use "yarn jar" to launch YARN applications, not this command. jnipath prints the java.library.path kdiag Diagnose Kerberos Problems kerbname show auth_to_local principal conversion key manage keys via the KeyProvider rumenfolder scale a rumen input trace rumentrace convert logs into a rumen trace s3guard manage metadata on S3 trace view and modify Hadoop tracing settings version print the version Daemon Commands: kms run KMS, the Key Management Server SUBCOMMAND may print help when invoked w/o parameters or with -h.
如果出现以上这个 说明Hadoop配置安装成功了
2、安装krb5-user命令
这一步主要是为了Kerberos认证执行kinit用的 如果已经有了 就可以跳过
执行
apt install krb5-user -y
这个安装过程中 虽然加了-y了 但是过程中还是会提示要输入Relam的 不过这个可以直接 Enter 键 继续往下执行
3、执行Kerberos认证
首先把服务端的 krb5.conf 移动到 /etc/ 下 。注意:/etc/下 默认会有一个krb5.conf 可以先备份下 然后在移动 移动之后 cat krb5.conf 看一下内容 是否成功
虽然认证的时候可以通过 export KRB5_CONFIG=/config/krb5.conf (krb5.conf) 这个设置临时变量 但是后续连接hdfs的时候 这个不行 还是读取的/etc/下的krb5.conf 所以我就直接替换了,如果有解决的办法 那可以不移动
这个要拥有 .keytab文件 以及认证的账号名 执行以下认证命令 根据自己的来
kinit -kt /path/to/your/keytab/file your-principal@YOUR_REALM.COM
执行之后 没有报错 使用 klist 命令 查看是否认证成功
klist
4、连接服务端的HDFS
把服务端给的 core-site.xml、hdfs-site.xml、yarn-site.xml 覆盖到 /hadoop-3.1.3/etc/hadoop 这个目录下,这目录下会有同名文件 (如果只是为了连接hdfs的话,yarn-site.xml这个文件可以不用)
然后执行以下hdfs命令 获取文件列表 后面是文件目录 根据自己的来
hdfs dfs -ls /apps/
如果出现报错
Exception in thread "main" java.lang.RuntimeException: Could not read password file: /etc/hadoop/conf/ldap_bind.file at org.apache.hadoop.security.LdapGroupsMapping.extractPassword(LdapGroupsMapping.java:823) at org.apache.hadoop.security.LdapGroupsMapping.setConf(LdapGroupsMapping.java:680) at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:77) at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:137) at org.apache.hadoop.security.CompositeGroupsMapping.addMappingProvider(CompositeGroupsMapping.java:142) at org.apache.hadoop.security.CompositeGroupsMapping.loadMappingProviders(CompositeGroupsMapping.java:134) at org.apache.hadoop.security.CompositeGroupsMapping.setConf(CompositeGroupsMapping.java:121) at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:77) at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:137) at org.apache.hadoop.security.Groups.<init>(Groups.java:106) at org.apache.hadoop.security.Groups.<init>(Groups.java:102) at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:451) at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:336) at org.apache.hadoop.security.UserGroupInformation.setConfiguration(UserGroupInformation.java:364) at org.apache.hadoop.fs.FsShell.init(FsShell.java:103) at org.apache.hadoop.fs.FsShell.run(FsShell.java:304) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:90) at org.apache.hadoop.fs.FsShell.main(FsShell.java:391) Caused by: java.io.FileNotFoundException: /etc/hadoop/conf/ldap_bind.file (No such file or directory) at java.io.FileInputStream.open0(Native Method) at java.io.FileInputStream.open(FileInputStream.java:195) at java.io.FileInputStream.<init>(FileInputStream.java:138) at java.io.FileInputStream.<init>(FileInputStream.java:93) at org.apache.hadoop.security.LdapGroupsMapping.extractPassword(LdapGroupsMapping.java:814)
打开/hadoop-3.1.3/etc/hadoop/core-site.xml 文件 删除以下内容
<property> <name>hadoop.security.group.mapping.ldap.bind.password.file</name> <value>/etc/hadoop/conf/ldap_bind.file</value> <description>包含绑定用户密码的文件的路径</description> </property>
然后保存退出
然后在执行查询命令 如果出现以下内容 说明连接成功了
abc@63140424e8c3 ~/hadoop/hadoop-3.1.3 $ hdfs dfs -ls /apps/
Found 2 items
drwxrwxr-x - test test 0 2024-12-26 10:04 /apps/test1
drwxrwxr-x - test test 0 2024-12-27 09:26 /apps/test2
5、连接服务端的hive数据库
先下载hive的包
官方地址:https://archive.apache.org/dist/hive/
我是用的是hive-3.1.3版本的
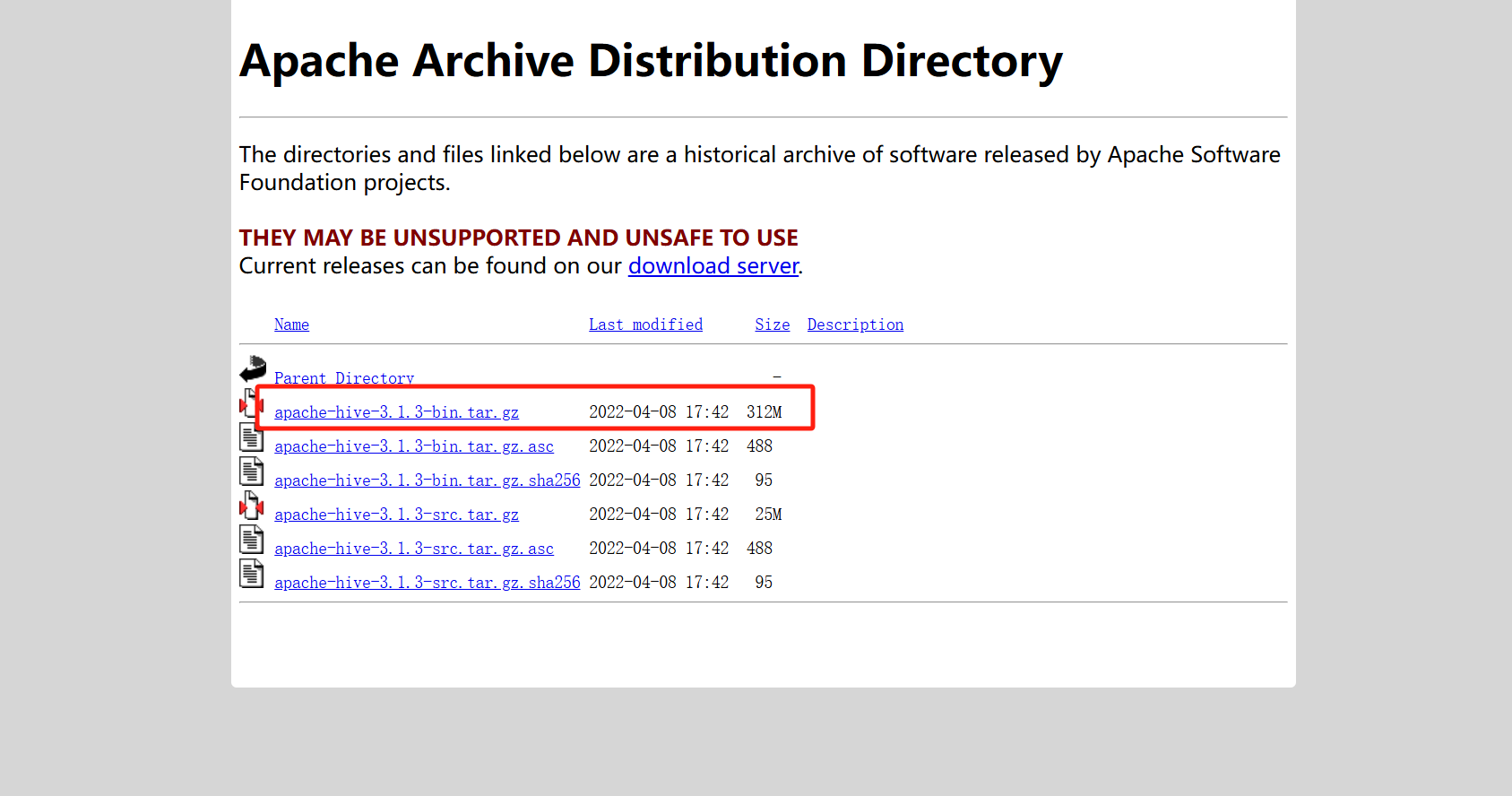
弄到服务器解压 然后把这个加目录到环境变量中 可以直接在 /etc/profile 文件修改 但是改了之后 要source 使配置文件生效
export HIVE_HOME=/config/hive/apache-hive-3.1.3-bin
export PATH=$PATH:$HIVE_HOME/bin
然后就可以通过 beeline连接服务器的hive了 因为我们上面已经执行过Kerberos认证这些其他操作了 所以hive只需要配置这个就可以连接了 后面这个是连接串 根据自己的来 可以参考:https://www.cnblogs.com/pxblog/p/18631276
beeline -u "jdbc:hive2://0hgv:2181/test;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2"
如果出现报错
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/config/hzp/hive/apache-hive-3.1.3-bin/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/config/hzp/hadoop/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Connecting to jdbc:hive2://hgv:2181/test;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2 com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V Beeline version 3.1.3 by Apache Hive Connection is already closed.
这个是因为hive-3.1.3的 guava-19.0.jar 和hadoop的版本不兼容导致
所以这里 先把hive目录的guava-19.0.jar 删掉
rm $HIVE_HOME/lib/guava-19.0.jar
然后把hadoop 的guava-27.0-jre.jar拷贝到 hive的lib中
cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
然后在重新连接就可以了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号