数据挖掘的几种经典方法论
目录
一、CRISP-DM方法(最流行)
CRISP-DM - Data Science Project Management
https://www.datascience-pm.com/crisp-dm-2/
在老外的这个网站中,我们可以了可以看到这个信息:

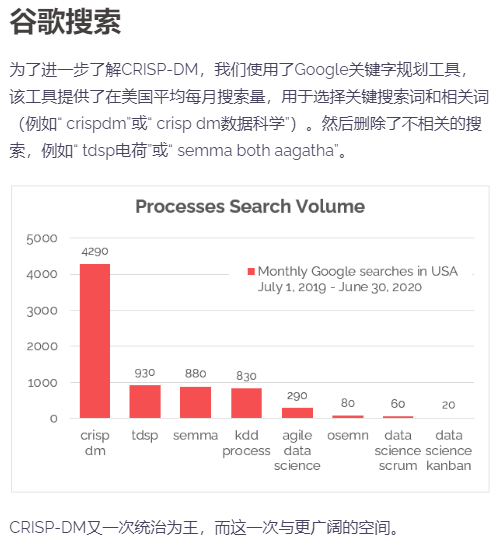
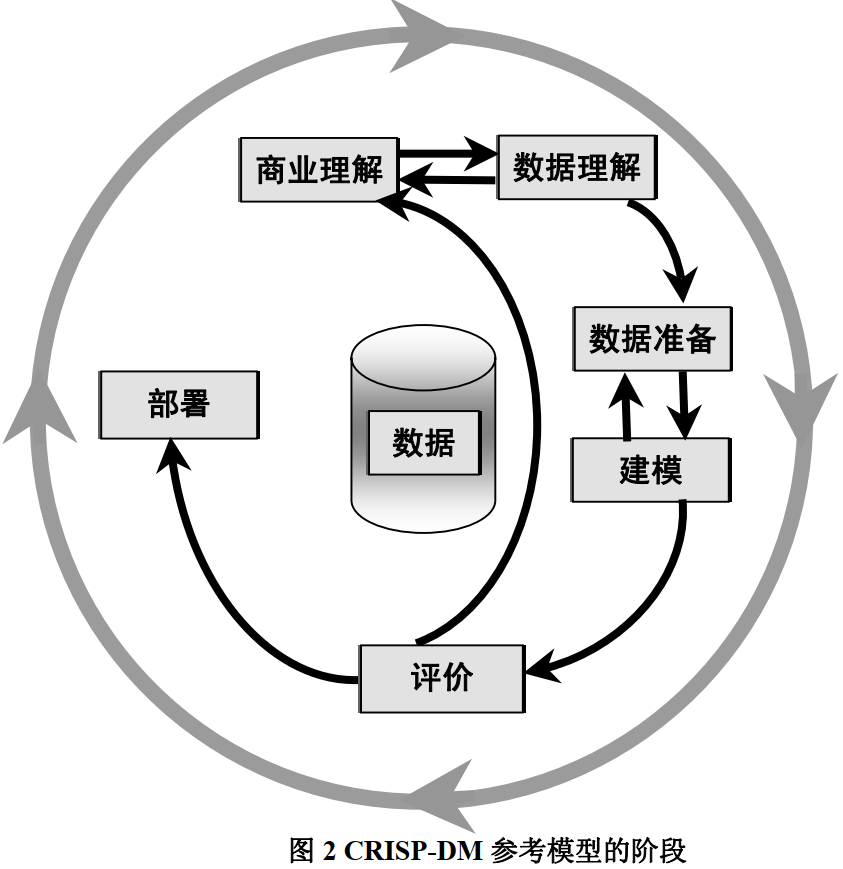
CRISP-DM (cross-industry standard process for data mining), 即为"跨行业数据挖掘标准流程"。此KDD过程模型于1999年欧盟机构联合起草。通过近几年的发展,CRISP-DM 模型在各种KDD过程模型中占据领先位置,2014年统计表明,采用量达到43%。

商业理解(business understanding)
数据理解(data understanding)
数据准备(data preparation)
建模(modeling)
评估(evaluation)
部署(deployment)
二、SEMMA方法
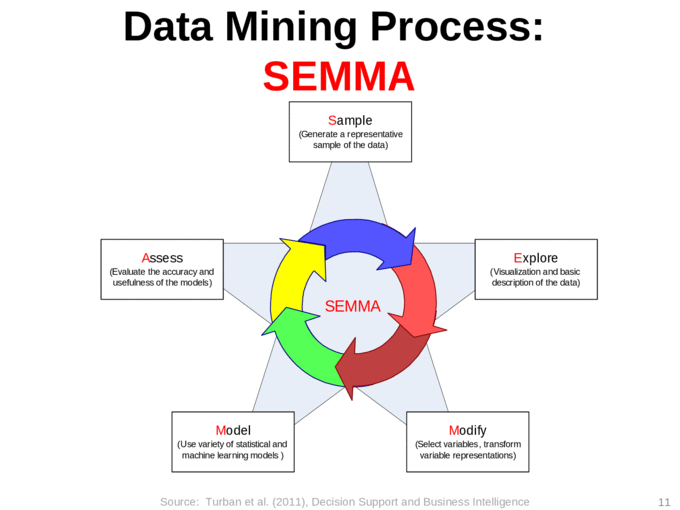
Sample——数据取样
当进行数据挖掘时,首先要从企业大量数据中取出一个与你要探索问题相关的样板数据子集,而不是动用全部企业数据。这就象在对开采出来矿石首先要进行选矿一样。通过数据样本的精选,不仅能减少数据处理量,节省系统资源,而且能通过数据的筛选,使你想要它反映的规律性更加凸现出来。
通过数据取样,要把好数据的质量关。在任何时候都不要忽视数据的质量,即使你是从一个数据仓库中进行数据取样,也不要忘记检查其质量如何。因为通过数据挖掘是要探索企业运作的规律性的,原始数据有误,还谈什么从中探索规律性。若你真的从中还探索出来了什么“规律性”,再依此去指导工作,则很可能是在进行误导。若你是从正在运行着的系统中进行数据取样,则更要注意数据的完整性和有效性。再次提醒你在任何时候都不要忽视数据的质量,慎之又慎!
从巨大的企业数据母体中取出哪些数据作为样本数据呢?这要依你所要达到的目标来区分采用不同的办法:如果你是要进行过程的观察、控制,这时你可进行随机取样,然后根据样本数据对企业或其中某个过程的状况作出估计。SAS不仅支持这一取样过程,而且可对所取出的样本数据进行各种例行的检验。若你想通过数据挖掘得出企业或其某个过程的全面规律性时,必须获得在足够广泛范围变化的数据,以使其有代表性。你还应当从实验设计的要求来考察所取样数据的代表性。唯此,才能通过此后的分析研究得出反映本质规律性的结果。利用它支持你进行决策才是真正有效的,并能使企业进一步获得技术、经济效益。
Explore——数据特征探索、分析和预处理
前面所叙述的数据取样,多少是带着人们对如何达到数据挖掘目的的先验的认识进行操作的。当我们拿到了一个样本数据集后,它是否达到我们原来设想的要求;其中有没有什么明显的规律和趋势;有没有出现你所从未设想过的数据状态;因素之间有什么相关性;它们可区分成怎样一些类别……这都是要首先探索的内容。
进行数据特征的探索、分析,最好是能进行可视化的操作。SAS有:SAS/INSIGHT和SAS/SPECTRAVIEW两个产品给你提供了可视化数据操作的最强有力的工具、方法和图形。它们不仅能做各种不同类型统计分析显示,而且可做多维、动态、甚至旋转的显示。
这里的数据探索,就是我们通常所进行的深入调查的过程。你最终要达到的目的可能是要搞清多因素相互影响的,十分复杂的关系。但是,这种复杂的关系不可能一下子建立起来。一开始,可以先观察众多因素之间的相关性;再按其相关的程度,以了解它们之间相互作用的情况。这些探索、分析,并没有一成不变操作规律性;相反,是要有耐心的反复的试探,仔细的观察。在此过程中,你原来的专业技术知识是非常有用的,它会帮助你进行有效的观察。但是,你也要注意,不要让你的专业知识束缚了你对数据特征观察的敏锐性。可能实际存在着你的先验知识认为不存在的关系。假如你的数据是真实可靠的话,那末你绝对不要轻易地否定数据呈现给你的新关系。很可能这里就是发现的新知识!有了它,也许会导引你在此后的分析中,得出比你原有的认识更加符合实际的规律性知识。假如在你的操作中出现了这种情况,应当说,你的数据挖掘已挖到了有效的矿脉。
在这里要提醒你的是要有耐心,做几种分析,就发现重大成果是不大可能的。所幸的是SAS向你提供了强有力的工具,它可跟随你的思维,可视化、快速的作出反应。免除了数学的复杂运算过程和编制结果展现程序的烦恼和对你思维的干扰。这就使你数据分析过程集聚于你业务领域的问题,并使你的思维保持了一个集中的较高级的活动状态,从而加速了你的思维过程,提高了你的思维能力。
Modify——问题明确化、数据调整和技术选择
通过上述两个步骤的操作,你对数据的状态和趋势可能有了进一步的了解。对你原来要解决的问题可能会有了进一步的明确;这时要尽可能对问题解决的要求能进一步的量化。问题越明确,越能进一步量化,问题就向它的解决更前进了一步。这是十分重要的。因为原来的问题很可能是诸如质量不好、生产率低等模糊的问题,没有问题的进一步明确,你简直就无法进行有效的数据挖掘操作。
在问题进一步明确化的基础上,你就可以按照问题的具体要求来审视你的数据集了,看它是否适应你的问题的需要。Gartner group在评论当前一些数据挖掘产品时特别强调指出:在数据挖掘的各个阶段中,数据挖掘的产品都要使所使用的数据和所将建立模型处于十分易于调整、修改和变动的状态,这才能保证数据挖掘有效的进行。
针对问题的需要可能要对数据进行增删;也可能按照你对整个数据挖掘过程的新认识,要组合或者生成一些新的变量,以体现对状态的有效的描述。SAS对数据强有力的存取、管理和操作的能力保证了对数据的调整、修改和变动的可能性。若使用了SAS的数据仓库产品技术时就更进一步保证了有效、方便的进行这些操作。
在问题进一步明确;数据结构和内容进一步调整的基础上,下一步数据挖掘应采用的技术手段就更加清晰、明确了。
Model——莫型的研发、知识的发现
这一步是数据挖掘工作的核心环节。虽然数据挖掘模型化工作涉及了非常广阔的技术领域,但对SAS研究所来说并不是一件新鲜事。自从SAS问世以来,就一直是统计模型市场领域的领头羊,而且年年提供新产品,并以这些产品体现业界技术的最新发展。
按照SAS提出的SEMMA方法论走到这一步时,你对应采用的技术已有了较明确的方向;你的数据结构和内容也有了充分的适应性。SAS在这时也向你提供了充分的可选择的技术手段:回归分析方法等广泛的数理统计方法;关联分析方法;分类及聚类分析方法;人工神经元网络;决策树……等。
在你的数据挖掘中使用哪一种方法,用SAS软件包中什么方法来实现,这主要取决于你的数据集的特征和你要实现的目标。实际上这种选择也不一定是唯一的。好在SAS软件运行效率十分高,你不妨多试几种方法,从实践中选出最适合于你的方法。
Assess——模型和知识的综合解释和评价
从上述过程中将会得出一系列的分析结果、模式或模型。同一个数据源可以利用多种数据分析方法和模型进行分析,ASSESS 的目的之一就是从这些模型中自动找出一个最好的模型出来,另外就是要对模型进行针对业务的解释和应用。
若能从模型中得出一个直接的结论当然很好。但更多的时候会得出对目标问题多侧面的描述。这时就要能很好的综合它们的影响规律性提供合理的决策支持信息。所谓合理,实际上往往是要你在所付出的代价和达到预期目标的可靠性的平衡上作出选择。假如在你的数据挖掘过程中,就预见到最后要进行这样的选择的话,那末你最好把这些平衡的指标尽可能的量化,以利你综合抉择。
你提供的决策支持信息适用性如何,这显然是十分重要的问题。除了在数据处理过程中SAS软件提供给你的许多检验参数外,评价的办法之一是直接使用你原来建立模型的样板数据来进行检验。假如这一关就通不过的话,那末你的决策支持信息的价值就不太大了。一般来说,在这一步应得到较好的评价。这说明你确实从这批数据样本中挖掘出了符合实际的规律性。
另一种办法是另外找一批数据,已知这些数据是反映客观实际的规律性的。这次的检验效果可能会比前一种差。差多少是要注意的。若是差到你所不能容忍程度,那就要考虑第一次构建的样本数据是否具有充分的代表性;或是模型本身不够完善。这时候可能要对前面的工作进行反思了。若这一步也得到了肯定的结果时,那你的数据挖掘应得到很好的评价了。
SEMMA与CRISP-DM的区别
CRISP-DM是从一个数据挖掘项目执行的角度谈方法论,SEMMA 则是从对具体某个数据集的一次探测和挖掘的角度来谈方法论, CRISP- DM的考虑的范围比SEMMA 要大。CRISP-DM关注商业目标、数据的获取和管理, 以及模型在商业背景下的有效性。
CRISP- DM认为数据挖掘是由商业目标驱动的,同时重视数据的获取、净化和管理; SEMMA 不否认商业目标,但更强调数据挖掘是一个探索的过程, 在最终确定模式和模型前, 要经过充分的探索和比较。
在数据挖掘的各个阶段中, 数据挖掘的产品都要使所使用的数据和所将建立模型处于十分易于调整、修改和变动的状态, 这才能保证数据挖掘有效的进行。SAS在同类产品中这一方面尤其强大。SEMMA 是一个特别贴近算法的视角, SAS 将不同的数据挖掘算法放到了这个挖掘过程的不同阶段( Explore, Modify,Model) , 而CRISP- DM是一个不依赖于具体算法的过程框架,CRISP-DM将所有算法放到过程的相同位置( Phase) 。SEMMA体现了不同算法在项目过程的不同阶段有不同的重要性。SAS 在技术上的另个特征是强调取样( Sampling)。
SEMMA 强调了SAS 本身产品的优势, SEMMA 没有如同CRISP-DM一样详细而规范的文本, 作为项目管理的需要来看CRISP-DM更适用一些。由于CRISP- DM在阶段间可以反馈,整个流程又是循环的, 在逻辑上CRISP- DM是可以实现SEMMA的, 它们互不矛盾。但由于强调的重点不同, 在实践上则会有明显的区别。
三、DMAIC方法
DMAIC是六西格玛管理中流程改善的重要工具。六西格玛管理不仅是理念,同时也是一套业绩突破的方法。它将理念变为行动,将目标变为现实。DMAIC是指定义Define、测量Measure、分析Analyze、改进Improve、控制Control五个阶段构成的过程改进方法,一般用于对现有流程的改进,包括制造过程、服务过程以及工作过程等等。DFSS是Design for Six Sigma的缩写,是指对新流程、新产品的设计方法。 
据DMAIC模型及其原理,人力资源管理应采取以下步骤:
(1)定义阶段(D阶段)
确定员工的知识、技能和素质等方面的关键需求,并识别需求改进的培训项目或培训管理流程,并将改进的内容界定在合理的范围内。主要方法有:胜任力模型、行为事件访谈(BEIs)、专家小组法、问卷调查法、全方位评价法、专家系统数据库和观察法等。
(2)测量阶段(M阶段)
通过对现有培训流程的测量,辨别核心流程和辅助流程;识别影响培训流程输出的输入要素,并对测量系统的有效性作出评价。 主要方法有:AFP法、模糊综合评判法、直方图、矩阵数据分析图等。
(3)分析阶段(A阶段)
通过数据分析,确定影响培训流程输出的关键因素,即确定培训过程的关键影响因素。主要方法有:鱼骨图、帕累托图、回归分析、因子分析等。
(4)改进阶段(I 阶段)
寻找优化培训流程并消除或减少关键输入因素影响的方案,使流程的缺陷或变异降低到最小程度。 主要方法有:流程再造等。
(5)控制阶段(C阶段)
使改进后的流程程序化,并通过有效的监测手段,确保流程改进的成果。 主要方法有:标准化、程序化、制度化等。
四、AOSP-SM模型
本段摘自:
SMARTBI公司的数据挖掘方法论:AOSP-SM_数据运营,运营,职能岗位_数据化运营专家-商业新知 https://www.shangyexinzhi.com/article/2590616.html
AOSP-SM 是 Application Oriented Standard Process forSmart Mining 的首字母缩写,翻译成中文是 “ 应用为导向的敏捷挖掘标准流程 ” ,它是思迈特公司( SMARTBI )基于跨行业数据挖掘过程标准( CRISP-DM )和 SAS 的数据挖掘方法 (SEMMA) 两种方法论总结而来的一种面向应用的用于指导数据挖掘工作的方法。
步骤 1 :确定商业目标
-
确定业务目标: 首先要梳理业务背景与现状,明确业务问题和项目需求,确定项目期望达到的目标,将业务目标转换为数据挖掘目标;
-
制定实施方案: 基于数据挖掘项目的目标做工作任务的分解和细化,制定具体的项目实施计划。
步骤 2 :数据准备
-
数据收集: 根据项目需求与目标,提出数据需求,在相关部门的配合下收集所需要的数据。为了提高数据获取的效率,降低分析难度,应想办法降低数据量,优先获取与项目需求相关度较高的数据;
-
数据审核: 为保证获得的数据是可靠和可用的,应对收集到的数据进行必要的审核与评估,这样才能保证模型输出可靠的成果;
-
数据处理: 通过数据剔除、数据转换、数据合并等操作提高数据质量,使数据更加符合建模的要求。
步骤 3 :建立模型
-
选择建模技术: 根据项目问题选择适当的建模技术,通常会尝试多种算法;
-
构建模型: 分别训练出不同算法下的最优模型,并安排测试工程师审核整个建模过程,保证建模的合理性。
步骤 4 :评估模型
步骤 3 中已确保构建的模型在技术上是正确且有效的,还需要使用在项目开始时设立的业务成功标准来评估模型,并确保关键决策制定者参与模型结果的评审。
步骤 5 :应用部署
-
模型测试: 在模型正式商用前需要进行 1-3 个月甚至更长时间的联调测试和试运行,在此期间需要持续监控模型状态并追踪模型应用效果,及时发现模型出现的新问题并进行模型的优化;
-
模型应用: 在系统试运行结束后,可以正式将模型成果运用到实际的商业环境中,为企业创造价值。
五、5A模型
SPSS公司(后被IBM收购)曾提出过5A模型,即将数据挖掘过程分为五个A:Assess、Access、Analyze、Act、Automate,分别对应五个阶段:评估需求、存取数据、完备分析、模型演示、结果展现。
六、数据挖掘“七步法”
“七步法”分为七个步骤,分别是:业务理解、数据获取、数据探索、模型构建、模型评估、策略输出、应用部署。“七步法”更侧重从乙方的视角来完成用数据挖掘及其应用的闭环。
本文部分内容参考自:
数据挖掘与分析的六种经典方法论 – 络且网
https://www.luoqie.com/archives/16018
数据科学交流群,群号:189158789 ,欢迎各位对数据科学感兴趣的小伙伴的加入!
深信积累的力量,时间就是你最好的朋友,否则它就是你最大的敌人。
如果你想分享此文章,请注明:作者:PurStar 出处:www.cnblogs.com/purstar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号