第一次个人编程作业
GitHub:pullself
前言
在写作业之前,考虑是把这篇写成文档那样严肃点的还是写成随笔那样随性点的,在经历了中秋一堆比赛的大起大落之后,我选择了后者,以下文字若出现某些弱智发言以及跳脱思维,请谅解。
PSP以及事前准备
PSP
先上张PSP表吧,曾经我也用过这张表,但是从来没正常实现过,当然这次也没严格遵守过这个流程
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 75 | 75 |
| Estimate | 估计这个任务需要多少时间 | 75 | 75 |
| Development | 开发 | 850 | 780 |
| Analysis | 需求分析(包括学习新技术) | 75 | 60 |
| Design Spec | 生成设计文档 | 30 | 10 |
| Design Review | 设计复审 | 35 | 40 |
| Coding Standard | 代码规范(为开发制定合适的规范) | 25 | 10 |
| Design | 具体设计 | 115 | 150 |
| Coding | 具体编码 | 290 | 230 |
| Code Review | 代码复审 | 80 | 60 |
| Test | 测试(自我测试,修改,提交修改) | 200 | 220 |
| Reporting | 报告 | 70 | 80 |
| Test Report | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结并提出过程改进计划 | 40 | 50 |
| 合计 | 995 | 935 |
这里稍作解释,由于这周时间确实紧张加上内容不算很多,所以没有设计文档,没有严格的代码规范,统统没有。时间主要集中在需求分析,设计开发和测试上面。很闹腾。
事前准备
下面这段话都是牢骚
在没说可以使用python之前,我是打算用c++来写的,别问为啥不用java,因为我的心里[^java],好吧其实是不怎么会。所以其实我c++代码是已经有个半成品的,但是说实话是我才疏学浅,c++对于中文处理以及unicode的支持真的是折腾人。想想之前c++我也就写写流量包处理,处理点小东西。用它来作字符串处理确实很麻烦。所以最后还是python来实现了,其实是没时间
当然在ymz加入python支持以及反复修改作业需求和格式的时候,我是报警的,周末建模国赛,c++写的折腾,之前写的一些还要改,还受到了时间的针对。简直像极了疯狂改需求的甲方,谴责,予以强烈谴责。
设计以及实现
前提
算是一个对题目的解读吧,在题目的规定范围()内对需求作几个定义:
输入的字符串以下简称:串串
- 串串一定是按照x!姓名,地址+手机.的格式给出。
- 串串中的手机号码一定是连续且为标准11位的。
- 对于1和2类需求,串串的省级不会缺失。
- 对于1和2类需求,串串除了省级和市级以外不会缺失级别后缀,例如(县,区,路)
- 默认门牌号采用阿拉伯数字
- 对于3类需求,尽可能补全,且不会出现模糊选择,例如(公园路)之类的模糊地名,若出现,将随机选择。
程序的设计将在以上的条件下进行,若与最终测试例有相违背,我我……我也没办法。
设计
由于技术助教的测评需求,要求python文件只能保留一个.py,所以就没有把代码写的很散碎了,原本是本着快乐造轮子的思想,结果造出来个方的。总共就一个文件,一个类,三个成员,九个方法,类图如下懒得修剪:
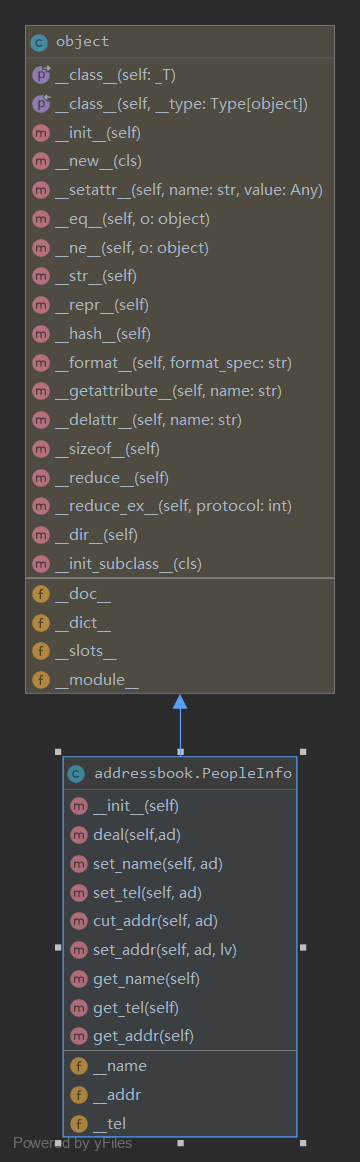
类 PeopleInfo
| 方法 | 功能 |
|---|---|
| _init_ | 初始化 |
| deal | 处理字符串 |
| set_name | 提取名字信息 |
| set_tel | 提取手机信息 |
| set_addr | 提取地址信息 |
| cut__addr | 分割地址信息 |
| get_name | 获取名字信息 |
| get_tel | 获取手机信息 |
| get_addr | 获取地址信息 |
内部调用关系如下图:
ps:这张图是pycharm的profile导出来的性能图,其实只是我懒得去画调用图了,就照着模板写了个类然后sleep了几毫秒作了一张图出来,可以无视那上面的数据,纯粹是懒。
部分实现
下列列出代码没有上下逻辑关系,仅仅是为了协助表达。
方法deal:
处理最初的串串,按照三类需求分别处理,并进行最初的异常处理。
方法set_name:
从串串中提取姓名信息,完全的字符串处理,不过既然格式这么工整,为啥不用用nice的正则表达式呢,虽然在这种情况下没比自己字符串判断减少多少代码量,不过不用白不用,嘿嘿!python是使用re模块,c++是使用regex库。
以英文的逗号作为结尾提取姓名并切割字符串。
re.search(r"(.+),(.*)", str)
方法set_tel:
从串串中提取手机信息,这里的查询标准是按照连续11位数字作为划分标准的。当然你说出现一个连续11位数字的门牌号,我也认了,那是真滴狠。
re.search(r"\d{11}", str)
方法set_addr:
从串串中提取地址信息,并且按照1,2,3三类需求进行重组补充处理;调用方法cut_addr,其中cut_addr默认将地址划分为7级,满足2类需求,对于1类需求将后三个字段合并构成详细地址字段,而对于3类需求,则会通过调用地图sdk的RestAPI(get方法)进行补充,当然模糊匹配也不准确,因此在原本的串串上截去部分过于详细的信息,先调用了地址查询,然后再使用最精确的那个结果的经纬度进行逆地址查询。总之那个产品经理被打爆,该!原来的代码是直接用requests模块的,后面想起来这是第三方的,本着不给评测添麻烦的心态(其实我想评测也懒得弄环境),就用回了urllib模块。
ret = re.search(r"\d+?号", ad) //匹配门牌号
res = request.urlopen(url)
res = json.loads(res.read().decode('utf-8'))
方法cut_addr:
这个算是这个类的核心方法了吧,不过写的很随性,应该毛病蛮多的。其实分割地址不考虑使用深度学习之类的,最简单粗暴的方法应该就是建立一个匹配数据库了,当然我是不会有这么多时间的(哭笑)。默认地址切割为7级别,然后根据输入规则可以勉强分为三类,“福建省福州市*”这类规整的,“上海(市)*”这类直辖市的,“福建福州*****”这类搞事的,所以根据上下优先级,先判断直辖市类,然后是规整类和搞事类,当然方法还是正则匹配(还是懒,而且蠢)。
1,2类其中除了省以外都是允许缺失的,所以在正则中判定为出现0或1次,全部设定为非贪婪模式以及限定市区县路等的名字约为1~4个字来避免一些重复的名字例如:“福建省福州市福州市教育局”这类。还有一种情况是市县同名以及市区同名以及以市的名命名的路/街/道之类的,这个一般区/县和市是从属关系所以判定下级别后缀的出现情况就能绝大部分避免错判。(其实是已经错判了,然后纠正下)。你要问我搞事类的省市怎么判断的,当然是打表啊,哪有空构建什么匹配库,别问,问就是打表。
re.search(r"(北京|上海|天津|重庆)([市]?)((.{1,4}?区|.{1,4}?县|.{1,4}?市)?)((.{1,4}?街道|.{1,4}?镇|.{1,4}?乡)?)((.{1,4}?路|.{1,4}?街|.{1,4}?巷|.{1,4}?弄|.{1,4}?道)?)((\d+?号)?)(.*)",str)
re.search("([^0-9]+?省|.+?自治区)(.{1,4}?市|.{4,8}?自治州|.{2,4}?地区|.{2,4}?盟)((.{1,4}?区|[^0-9]{1,4}?县|.{1,4}?市|.{2,6}?旗)?)((.{1,4}?街道|.{1,4}?镇|.{1,4}?乡)?)((.{1,6}?弄|.{1,6}?路|.{1,6}?街|.{1,6}?巷|.{1,6}?道)?)((\d+?号)?)(.*)",str)
re.search(r"(" + province + r"?)" + r"([省]?)" + r"(" + city1 + city2 + city3 + city4 + city5 + city6 + city7 + city8 + city9 + r"?)"+ r"([市]?)((.{0,4}?区|.{0,4}?县|.{0,4}?市)?)((.{0,4}?街道|.{0,4}?镇|.{0,4}?乡)?)((.{0,4}?路|.{0,4}?街|.{0,4}?巷)?)((\d+?号)?)(.*)",str)
方法get_name:
个人习惯,对于每个类都会有一个专门的获得属性的接口,获取名字。
方法get_tel:
同上
方法get_addr:
同上
性能改进
作性能上的修改大约就花了大约70分钟?本身结构比较简单(懒得改),除了个别的小改动以外(提前跳出循环),改动比较大的就是分割字符串的处理逻辑,最早是三类匹配先进行,选择其中匹配成功的一个进行操作,这里就算是多进行了两次无用的匹配,还是蛮消耗时间,燃烧生命的。然后修改成了按照优先级匹配匹配成功就返回的逻辑。
其实整个类的所有方法中最耗时间的,不查看性能分析也能知道耗时最大的模块一定是set_addr中的urllib.request.urlopen,http请求的操作要等待网络数据的返回。网络你动啊,你倒是动啊!!
性能分析(vs 2017的python分析工具和pycharm的profile):
测试数据是20条,共8个1类,8个2类,4个3类:
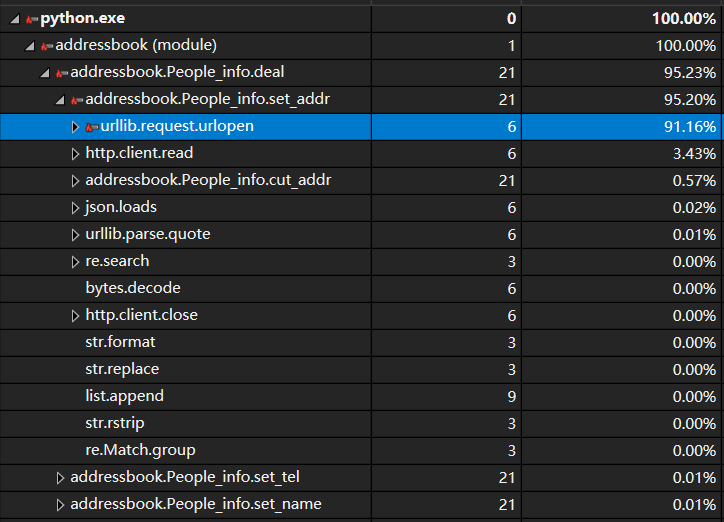
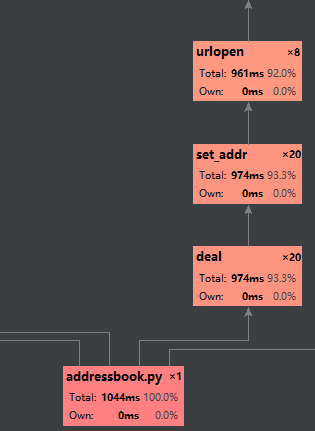
结果很显然,和猜想的一样,时间消耗基本全部集中在网络请求上,网络你动啊,你倒是动啊!!
def set_addr(self, ad, lv):
self.cut_addr(ad)
if (lv == 1):
s = self.__addr[4] + self.__addr[5] + self.__addr[6]
self.__addr = self.__addr[:4]
self.__addr.append(s)
elif (lv == 3):
data = []
url = "https://restapi.amap.com/v3/place/text?"+"keywords="+parse.quote(ad.rstrip('.'))+"&output=json&offset=1&key=ymzdsb&extensions=all"
res = request.urlopen(url)
res = json.loads(res.read().decode('utf-8'))
url = "https://restapi.amap.com/v3/geocode/regeo?output=json&location={}&key=ymzdsb&extensions=all".format(res['pois'][0]['location'])
res = request.urlopen(url)
res = json.loads(res.read().decode('utf-8'))
data.append(res['regeocode']['addressComponent']['province'])
if(data[0]=='北京市' or data[0]=='上海市' or data[0]=='天津市' or data[0]=='重庆市'):
data[0] = data[0].strip('市')
if(res['regeocode']['addressComponent']['city']==[]):
data.append('')
else:
data.append(res['regeocode']['addressComponent']['city'])
data.append(res['regeocode']['addressComponent']['district'])
data.append(res['regeocode']['addressComponent']['township'])
data.append(res['regeocode']['addressComponent']['streetNumber']['street'])
data.append(res['regeocode']['addressComponent']['streetNumber']['number'])
data.append(res['regeocode']['addressComponent']['building']['name'])
for i in range(7):
if (self.__addr[i] == ''):
if (data[i] != ''):
self.__addr[i] = data[i]
return self.__addr
虽然觉得没有必要,但是在杰哥的提醒下也稍微放一张codacy的issue分析截图吧。
单元测试
单元测试主要集中在几个主要功能上,就是除了那几个get方法以外都有涉及。在我写这部分的时候差不多建模比赛结束了,我收回我上一篇博客对大物的评价。
使用python的unittest模块,构建专门的单元测试类,对set_name,set_tel,set_addr,deal,cut_addr五个方法进行测试,测试数据放在外部的测试文件中,通过文件读写进行比对。代码如下:
import unittest
from 031702440 import PeopleInfo
class TestPeople_info(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
def test_set_name(self):
ms = open('test1.txt', 'r')
ms2 = open('output1.txt', 'r')
for line1, line2 in zip(ms.readlines(), ms2.readlines()):
testclass = People_info()
res = testclass.set_name(line1)
line2 = line2.rstrip('\n')
self.assertEqual(res, line2)
def test_set_tel(self):
ms = open('test2.txt', 'r')
ms2 = open('output2.txt', 'r')
for line1, line2 in zip(ms.readlines(), ms2.readlines()):
testclass = People_info()
res = testclass.set_tel(line1)
line2 = line2.rstrip('\n')
self.assertEqual(res, line2)
def test_set_addr(self):
ms = open('test3.txt', 'r')
ms2 = open('output3.txt', 'r')
for line1, line2 in zip(ms.readlines(), ms2.readlines()):
testclass = People_info()
li = line2.split(',')
li[-1] = li[-1].rstrip('\n')
lv = line1[0]
line1 = line1[2:]
res = testclass.set_addr(line1, int(lv))
self.assertEqual(res, li)
def test_cut_addr(self):
ms = open('test4.txt', 'r')
ms2 = open('output4.txt', 'r')
for line1, line2 in zip(ms.readlines(), ms2.readlines()):
testclass = People_info()
li = line2.split(',')
li[-1] = li[-1].rstrip('\n')
res = testclass.cut_addr(line1)
self.assertEqual(res, li)
def test_deal(self):
ms = open('test5.txt', 'r')
ms2 = open('output5.txt', 'r')
for line1, line2 in zip(ms.readlines(), ms2.readlines()):
testclass = People_info()
li = line2.split(',')
li[-1] = li[-1].rstrip('\n')
res = testclass.deal(line1)
self.assertEqual(res, li)
if __name__ == "__main__":
unittest.main(verbosity=2)
测试数据根据代码中的不同分支进行测试,针对多样的地名组合方式进行构建,并加入了一些特殊的格式。在作死的边缘疯狂试探。
部分测试数据如下:
福建省福州市鼓楼区鼓西街道湖滨路110号湖滨大厦一层.
福建福州闽侯县上街镇福州大学10#111.
江西省九江市208县道征村乡熏衣村村民委员会.
北京市顺义区石园街道顺康路1号港馨家园19号楼.
北京市东城区交道口东大街1号北京市东城区人民法院.
广东省东莞市凤岗镇凤平路13号.
福建省福州晋安区新店镇古城小区.
福建福州市晋安区新店镇福飞路古城小区.
澳门大赌场.
福建福州路小家饭店.
测试覆盖率通过使用coverage模块获取,测试结果如下:

那九行大部分是无用的输出和get方法。结果勉强凑合了吧,造轮子真香。。
异常处理
我承认我做到这一部分的时候,已经莫得力气了。对于异常处理,我主要设置的都是在正则匹配出现格式错误导致的AttributeError的时候进行的处理。
try:
ad = self.set_name(ad)
except AttributeError:
print("'" + ad + "'" + ":姓名输入格式不符合规范")
try:
ad = self.set_tel(ad)
except AttributeError:
print("'" + ad + "'" + ":手机输入格式不符合规范")
try:
self.set_addr(ad, int(lv))
except AttributeError:
print("'" + ad + "'" + ":地址输入格式不符合规范")
从上到下对应的测试:
2!,福建省福州13756899511市鼓楼区鼓西街道湖滨路110号湖滨大厦一层.(缺失名字)
2!李四,福建省福州899511市鼓楼区鼓西街道湖滨路110号湖滨大厦一层.(手机号格式不对)
1!李四,13756899511湖滨大厦一层.(地址不满足需求)
总结
不知不觉,咋写了这么多啊,我哭了,一天写完这东西还是蛮痛苦的,之前用python写东西除了写复杂项目,一般很少用ide的,记事本不好吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号