
030-一个文件:介绍一个高大上的东西
1.os模块中关于文件/目录常用的函数使用方法
| 函数名 | 使用方法 | 测试 |
| getcwd() | 返回当前工作目录 |
import os os.getcwd()
|
| chdir(path) | 改变工作目录,相当于我们的CD命令 |
os.chdir('D:\\')
|
| listdir(path='.') | 列举指定目录中的文件名('.'表示当前目录,'..'表示上一级目录) |
os.listdir('D:\\')
|
| mkdir(path) | 创建单层目录,如该目录已存在抛出异常,也可以创建复合的,但第一层目录要存在 |
os.mkdir('D:\\A')
os.mkdir('D:\\A\\B') #正常运行
-------------------------
os.mkdir('D:\\C\\B') #抛出异常,只能一层一层创建
|
| makedirs(path) | 递归创建多层目录,如该目录已存在抛出异常,注意:'E:\\a\\b'和'E:\\a\\c'并不会冲突 |
os.makedirs('D:\\C\\B')
|
| remove(path) | 删除文件 | |
| rmdir(path) | 删除单层目录,如该目录非空则抛出异常 |
os.remove('D:\\A\\B\\pjm.txt')
os.rmdir('D:\\A\\B')
注意:必须将目录中文件清空才能删除 |
| removedirs(path) | 递归删除目录,从子目录到父目录逐层尝试删除,遇到目录非空则抛出异常 | 注意:必须将目录中文件清空才能删除 |
| rename(old, new) | 将文件old重命名为new | |
| system(command) | 运行系统的shell命令,比如打开cmd,计算器calc |
os.system('cmd')
|
| walk(top) | 遍历top路径以下所有的子目录,返回一个三元组:(路径, [包含目录], [包含文件])【具体实现方案请看:第30讲课后作业^_^】 | |
| 以下是支持路径操作中常用到的一些定义,支持所有平台 | ||
| os.curdir | 指代当前目录('.') |
os.listdir(os.curdir)
|
| os.pardir | 指代上一级目录('..') | |
| os.sep | 输出操作系统特定的路径分隔符(Win下为'\\',Linux下为'/') | |
| os.linesep | 当前平台使用的行终止符(Win下为'\r\n',Linux下为'\n') | |
| os.name | 指代当前使用的操作系统(包括:'posix', 'nt', 'mac', 'os2', 'ce', 'java') | |
2.os.path模块中关于路径常用的函数使用方法
| 函数名 | 使用方法 | 测试 |
| basename(path) | 去掉目录路径,单独返回文件名 |
os.path.basename('D:\\A\\B\\C\\pjm.txt')
|
| dirname(path) | 去掉文件名,单独返回目录路径 |
os.path.dirname('D:\\A\\B\\C\\pjm.txt')
|
| join(path1[, path2[, ...]]) | 将path1, path2各部分组合成一个路径名 |
os.path.join('A','B','C')
os.path.join('D:','A','B','C')
os.path.join('D:\\','A','B','C') #要自己加上'\\'
|
| split(path) | 分割文件名与路径,返回(f_path, f_name)元组。如果完全使用目录,它也会将最后一个目录作为文件名分离,且不会判断文件或者目录是否存在 |
os.path.split('D:\\A\\pjm.txt')
os.path.split('D:\\A\\B') #也会把B分割出来,无法自动识别是否为文件名
|
| splitext(path) | 分离文件名与扩展名,返回(f_name, f_extension)元组 |
os.path.splitext('D:\\A\\pjm.txt')
|
| getsize(file) | 返回指定文件的尺寸,单位是字节 | |
| getatime(file) | 返回指定文件最近的访问时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) |
os.path.getatime('D:\\Aok\\pjm.txt')
import time
time.gmtime(os.path.getatime('D:\\Aok\\pjm.txt'))
time.localtime(os.path.getatime('D:\\Aok\\pjm.txt')) #转换成北京时间
|
| getctime(file) | 返回指定文件的创建时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) | |
| getmtime(file) | 返回指定文件最新的修改时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) | |
| 以下为函数返回 True 或 False | ||
| exists(path) | 判断指定路径(目录或文件)是否存在 | |
| isabs(path) | 判断指定路径是否为绝对路径 | |
| isdir(path) | 判断指定路径是否存在且是一个目录 | |
| isfile(path) | 判断指定路径是否存在且是一个文件 | |
| islink(path) | 判断指定路径是否存在且是一个符号链接(在windows上即为快捷方式) | |
| ismount(path) | 判断指定路径是否存在且是一个挂载点 | |
| samefile(path1, paht2) | 判断path1和path2两个路径是否指向同一个文件 | |
3.课后习题

0 编写一个程序,统计当前目录下每个文件类型的文件数
import os
def stat(file):
list1 = os.listdir(file)
count1 = 0
count2 = 0
count3 = 0
count4 = 0
count5 = 0
for each in list1:
(f_name,f_extension) = os.path.splitext(each)
file1 = file+'\\'+each
if f_extension=='.txt':
count1 += 1
if f_extension=='.png':
count2 += 1
if f_extension=='.py':
count3 += 1
if f_extension=='.docx'or f_extension=='.doc':
count4 += 1
if os.path.isfile(file1)==0:
count5 += 1
print('该文件夹下共有类型为【.txt】的文件夹%d个' %count1)
print('该文件夹下共有类型为【.png】的文件夹%d个' %count2)
print('该文件夹下共有类型为【.py】的文件夹%d个' %count3)
print('该文件夹下共有类型为【.docx/.doc】的文件夹%d个' %count4)
print('该文件夹下共有类型为【文件夹】的文件夹%d个' %count5)
file = 'C:\\Users\\Administrator\\Desktop\\小程序'
stat(file)
1 编写一个程序,计算当前文件夹下所有文件的大小
import os
def stat(file):
list1 = os.listdir(file)
for each in list1:
size = os.path.getsize(file)
print(each+'【%d Bytes】' %size)
file = 'C:\\Users\\Administrator\\Desktop\\猿题库'
stat(file)
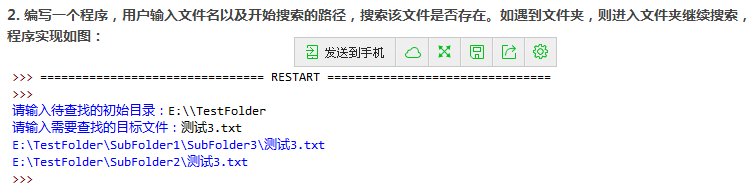
2 编写一个程序,用户输入文件名以及开始搜索的路径,搜索该文件是否存在。如果遇到文件夹,则进入文件夹继续搜索
import os
def search(catalog,target):
for (path,catalog1,target1) in os.walk(catalog):
if target in target1:
print('\n',os.path.join(path,target))
catalog = input('请输入待查找的初始目录:')
target = input('请输入要查找的目标文件:')
search(catalog,target)
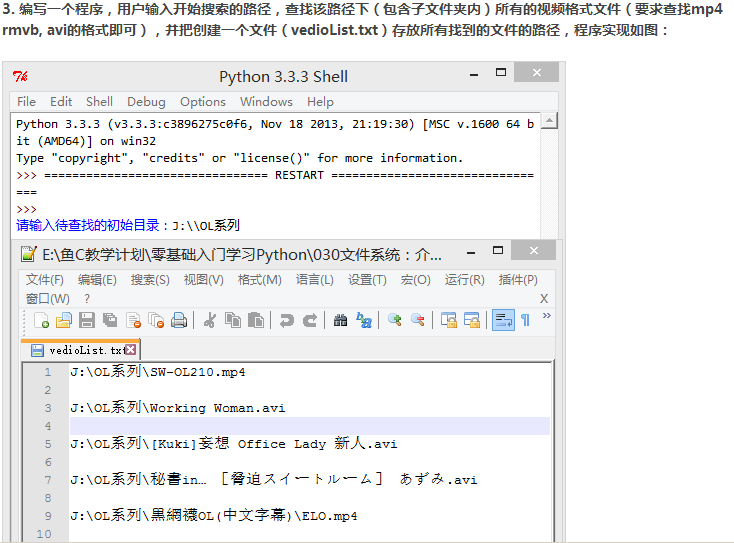
3 编写一个程序,用户输入开始搜索路径,查找该路径下(包含子文件夹)所有视频格式文件(要求查找mp4,rmvb,avi的格式即可),并把创建一个文件(vedioList.txt)存放所有找到的文件路径
import os
vediolist = []
def video_ser(path,target):
os.chdir(path) #改变工作目录
allfile = os.listdir(os.curdir) #列举当前路径下的文件名
for each in allfile:
extension = os.path.splitext(each)[1] #分离拓展名
if extension in target:
videolist.append(os.getcwd()+os.sep+each+os.linesep)
#os.sep为输出操作系统特定的路径分隔符
#os.linesep为当前平台使用的行终止符
if os.path.isdir(each): #若each路径存在且为目录
video_ser(each,target)
os.chdir(os.pardir) #改变上一级工作目录
path = input('请输入待查找的初始目录:')
while not os.path.exists(path):
print('目录不存在!')
path = input('请输入待查找的初始目录:')
program = os.getcwd()
target = ['.avi','.mp4','.rmvb']
videolist = []
video_ser(path,target)
f = open(program+os.sep+'videolist.txt','w')
f.writelines(videolist)
f.close()
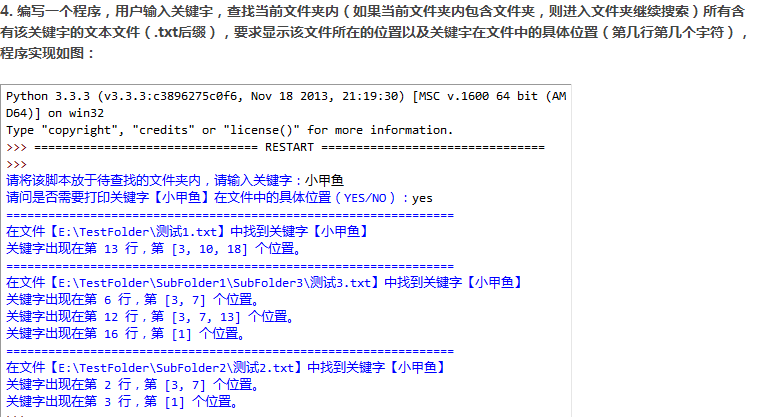
4 编写一个程序,用户输入关键字,查找当前文件夹内(如果当前文件夹内包含文件夹,则进入文件夹继续搜索)所有含有该关键字的文本文件(.txt),
要求显示该文件所在位置及关键字在文件中的具体位置(第几行第几个字符)
import os
def print_position(key_dic):
keys = key_dic.keys() #字典中每个键
keys = sorted(keys) #字典是无序的,重新进行排序
for each_key in keys:
print('关键字出现在第%s行,%s位置!' %(each_key,str(key_dic[each_key])))
def pos_in_line(line,key):
position = []
begin = line.find(key)
while begin!=-1:
position.append(begin+1)
begin = line.find(key,begin+1)
return position
def search_in_file(file_name,key):
f = open(file_name)
count = 0
key_dic = dict()
for each_line in f:
count += 1
if key in each_line:
position = pos_in_line(each_line,key) #每行中的位置
key_dic[count] = position
f.close()
return key_dic
def search_files(key,detail):
allfile = os.walk(os.getcwd())
txt_files = []
for i in allfile:
for each_file in i[2]:
if os.path.splitext(each_file)[1] == '.txt':
txt_files.append(each_file)
for each_txt_file in txt_files:
key_dic = search_in_file(each_txt_file,key)
if key_dic:
print('================================================')
print('在文件【%s】中找到关键字【%s】' %(each_txt_file,key))
if detail in ['Yes','YES','yes','Y','y']:
print_position(key_dic)
key = input('请将脚本放于待查找的文件夹内,请输入关键字:')
detail = input('请问是否需要打印关键字【%s】在文件中的具体位置(yes/no):' %key)
search_files(key,detail)
-----------------------------------------------------------------------------------
参考:https://www.cnblogs.com/mogumanman/articles/9910109.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号