数据采集和融合实践第一次作业
第一次作业
作业①
(1)实验内容
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
①先观察每个大学的所在的标签元素
可以看到每个学校的信息都在一行中tr标签中,每个信息在td中
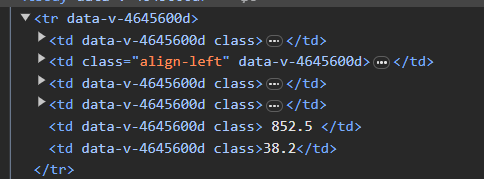
②观察需要的学校信息
需要的学校名称在第二个td单元格,学校所在省份在第三个tr单元格,学校类型在第四个tr单元格,学校评分在第五个单元格,学校办学层次在第6个单元格
③根据以上分析,编写代码的思路如下:
-
先获取单个页面的源码,
-
获取学校信息表格
-
逐步获取学校的每一项信息
代码如下
import urllib.request
import urllib.parse
from bs4 import BeautifulSoup
#发送url请求
url='http://www.shanghairanking.cn/rankings/bcur/2020 '
response = urllib.request.urlopen(url=url)
content = response.read().decode('utf-8')
#创建BeautifulSoup对象
bs = BeautifulSoup(content,'lxml')
#爬取一页的数据
table = bs.find('table',attrs={'class':'rk-table'})
#每个学校的数据都在一个行tr中
tr_list = table.select('tr')
rank=0
uni_list=[]
for tr in tr_list[1:]: #舍弃掉第一列
td_list = tr.select('td')
name = td_list[1].select('div a')[0].text #学校名称
province = td_list[2].text.strip() #学校所在省份
unitype= td_list[3].text.strip() #办学类型
score = td_list[4].text.strip() #得分
level_score = td_list[4].text.strip() #办学层次
rank+=1
uni_list.append([rank,name,province,unitype,score,level_score])
#在屏幕打印结果如下
for uni in uni_list :
print(uni)
运行结果

(2)心得体会
本次实验使用了urllib和bs4库完成对2020年中国软科排名的信息的爬取,是一个比较基础的网页源码的解析的案例,总体难度不算大,但是如果想要实现多页数据的爬取就感觉是一个难点了,想实现多页爬取目前有两个思路,一是查找每一页的数据接口,找到规律,解析出不同数据页面所需要的请求格式,第二种就是使用selenium找到解析html源码,找到下一页的按钮标签,模拟点击
作业(2)
(1)实验内容
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格
①心路历程:
本来想爬取淘宝网,但是遇到了一堆反爬,十分崩溃,退而求其次,爬取没有什么反爬的当当网
②在当当网中输入书包,按F12,查看单个商品的源码如下
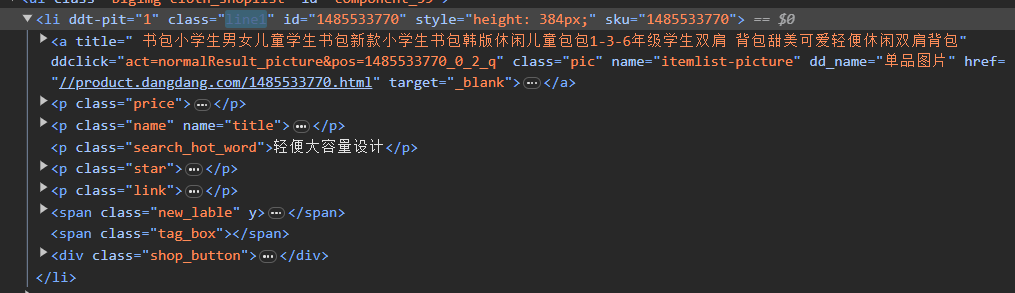
②观察单个商品的源码
需要的数据为商品名称和商品价格,找到对应的标签位置

③单个页面的商品数为60

④根据上述的分析,爬取单页商品数据的算法设计思路如下
-
发送请求,请求头携带一定信息
-
获取页面源码(html)
-
找到单个商品标签li
-
遍历所有商品,得到商品li下的名称在标签和价格所在标签,将其中的文本提取出来
-
保存在数据结构中
⑤多页爬取的设计
由于当当网的商品界面是由url 决定的,因此可以通过修改url实现翻页的功能,观察多个url后,发现翻页后只修改了一个参数page_index,于是要实现翻页只需要修改url中的page_index即可。
完整代码如下:
import requests
from bs4 import BeautifulSoup
from pprint import pprint
def get_items(page_nums):
item_list=[]
for page_num in range(1,page_nums+1): # 每一页的url 只有 page_index的参数在变化
url='http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'+'&page_index={}'.format(page_num)
headers={
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers)
response.encoding='gbk'
content = response.text
soup= BeautifulSoup(content,'lxml')
li_list = soup.select("ul[class='bigimg cloth_shoplist'] li")
for li in li_list:
name = li.a.attrs['title']
price = li.select('p[class="price"]')[0].text
item_list.append((name,price))
return item_list
if __name__ =="__main__":
page_nums= 10
itemlist=get_items(page_nums)
print(len(itemlist))
pprint(itemlist)
运行结果:

(2)心得体会
研究淘宝的反爬有点崩溃,刚进去就遇到一个非常规的滑动验证,还不是普通的滑块验证,进去之后,手动翻了几页,就会滑块验证,当然验证的问题可以使用打码平台解决,但是,又发现商品的数据是js动态加载的,崩溃,于是选择当当网进行爬取,当当网的爬取相对简单,使用urllib或者requests都可以进行爬取,然后使用Beautifulsoup进行解析即可,如果是使用re那么反而写的解析语法就更加复杂了
作业③
(1)实验内容
要求:爬取一个给定网页 https://xcb.fzu.edu.cn/info/1071/4481.htm 或者自选网页的所有JPEG和JPG格式文件
①只有一个页面,爬取单个页面的所有图片,那么问题就比较简单,只要找到页面中所有的img标签,然后获取img标签的src属性,通过src属性就可以访问到图片了
单个图片的标签如下

但是这里有一个坑点
src的链接并不是完整的图片链接,需要添加 "前缀" , https://xcb.fzu.edu.cn/ 才可以访问到图片
②获取每个图片的url后,使用urlretrieve保存图片即可,当然也可以直接获取图片的二进制内容后写入文件
代码如下:
import requests
from bs4 import BeautifulSoup
from urllib.request import urlretrieve
url ='https://xcb.fzu.edu.cn/info/1071/4481.htm'
headers={
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers)
response.encoding='utf-8'
content = response.text
soup = BeautifulSoup(content,'lxml')
#获取所有的图片标签
imgs_list = soup.find_all('img')
#遍历所有图片标签
for i,img in enumerate(imgs_list):
url='https://xcb.fzu.edu.cn/'+img.attrs['src'] #获取图片的url
urlretrieve(url,'./imgs/{}.jpg'.format(i)) #下载单张图片
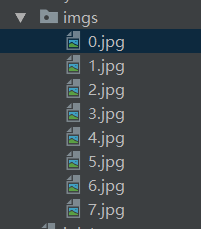
运行得到的图片目录结构如下:
(2)心得体会
第三个实验相比前面的难度比较低,简单的地方在于只需要找出所有img标签即可,不需要太多的结构解析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号