容器技术
容器技术
容器和虚拟机的区别也是他的特点就是:容器是一种特殊的进程
隔离与限制
限制方案
namespace主要用来限制进程,而容器在运行时与宿主机共享内核,怎样保证容器占用资源不会影响到宿主机的稳定?
用到的技术主要是Linux cgroup

在/sys/fs/cgroup/cpu下新建文件夹后会自动生成子系统对应的资源限制文件
此时如果让系统启动一个死循环脚本并不作限制,会导致cpu占用到100
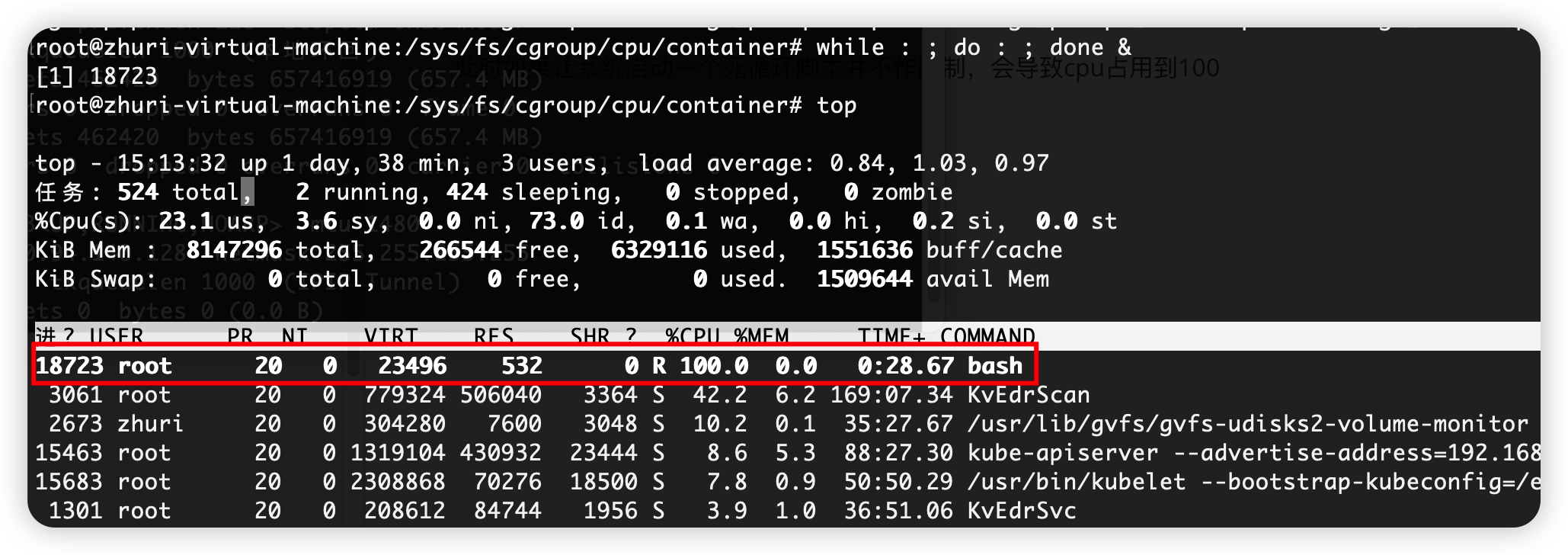
通过cpu.cfs_quota_us的值-1可知未作任何限制
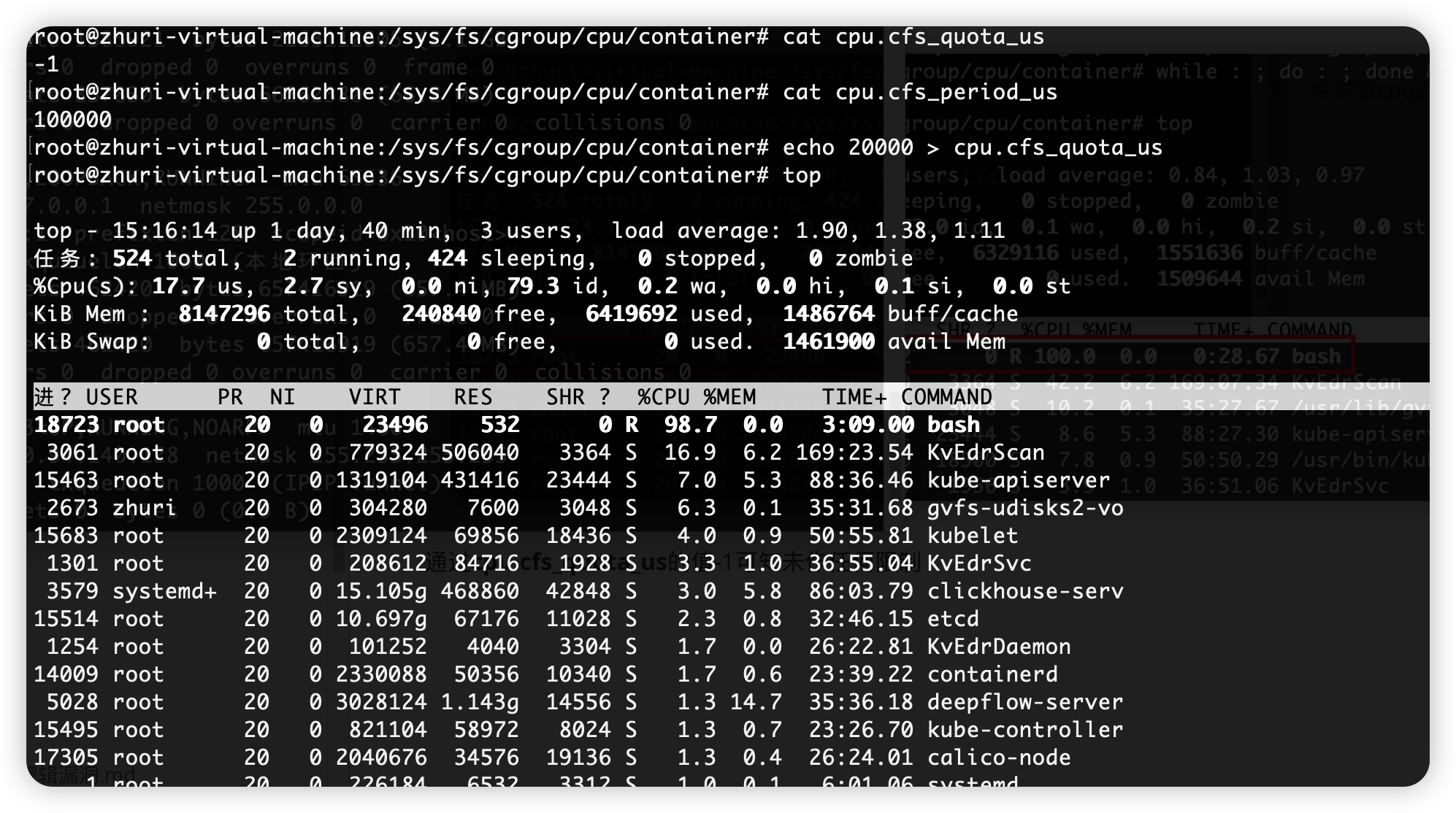
CPU period为默认的100ms
现在修改cpu.cfs_quota_us的值添加限制,比如改为20ms,这表示在每100ms的时间里,这个控制组限制的进程只能使用20ms的CPU时间,也就是只能占用20%的CPU性能
然后把进程与这个控制组绑定
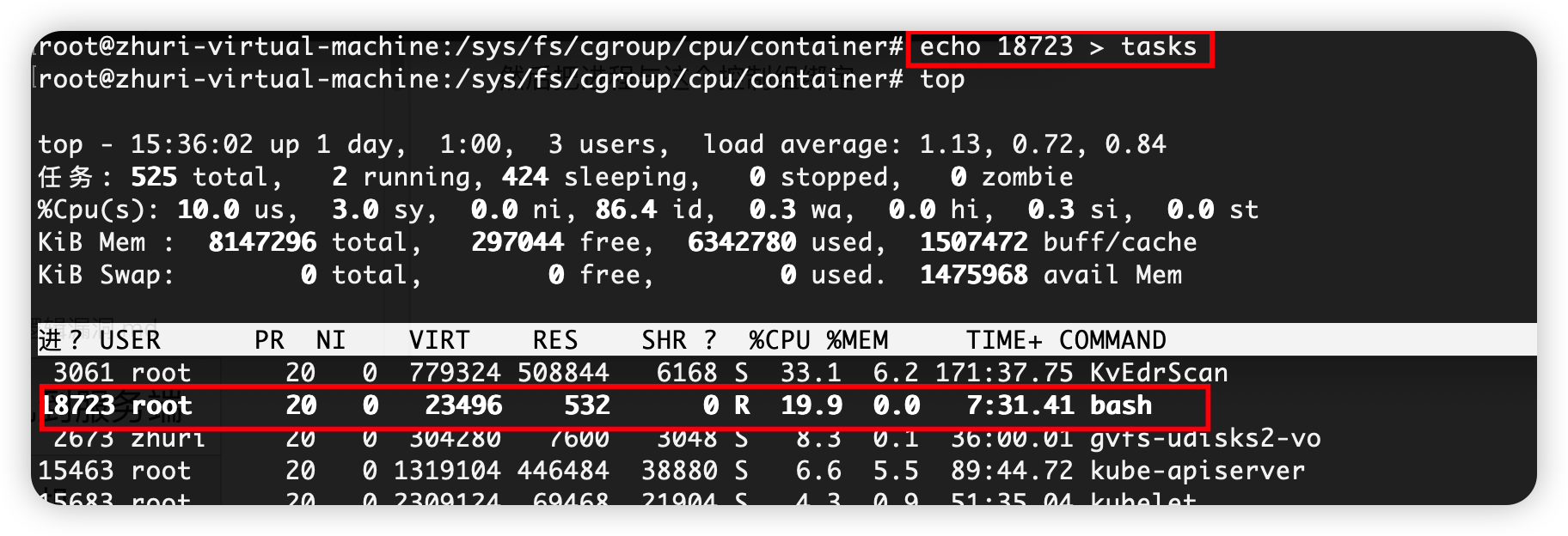
除了cpu子系统之外,Cgroup的每一项子系统都有自己的资源限制能力
- blkio,为块设备限定I/O限制,一般用于磁盘
- cpuset,为进程分配单独的CPU核和对应的内存节点
- memry,为进程设定内存使用限制
像Docker这种容器,只需要在每个子系统下为每个容器创建一个控制组(就是新建一个目录,资源限制文件会自动生成),然后启动容器进程之后再把进程与控制组绑定即可
docker使用run启动容器时可以指定限制的值,比如
docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
大部分资源可以通过Cgroup做限制,但还是有例外,比如/proc,/proc文件系统不了解Cgroup的存在
所以如果在容器里执行top命令,会发现他的信息是宿主机的cpu和内存数据
Docker
核心原理:为带创建的用户进程:
- 启用Linux Namespace配置
- 设置指定的Cgroup参数
- 切换进程的根目录
切换进程的根目录会优先使用pivot_root系统调用,如果系统不支持,才会使用chroot
namespace机制也是在chroot技术上延伸发展而来
一致性
容器与宿主机共用内核,而在linux中万物皆文件,所以如果在宿主机中有另一个系统的完整文件系统,理论上来说就可以依靠这些文件运行宿主机中原本没有环境的程序。
在linux中,rootfs即代表一个操作系统所包含的文件、配置和目录
共用内核,使用配置好环境的rootfs,再结合chroot切换根目录以及namespace和Cgroup限制资源,这样配合下来完成隔离与运行,也就是容器
这样做还是有一些问题,比如:程序或者系统迭代时,需要重复制作rootfs,比如配置好而且未做其他操作的java环境可能会被其他人到,如果我部署了自己的应用之后再封装制作rootfs,那么其他人拿到这个rootfs还要把我的内容清除。
直观一点的解决办法是:每做一次关键操作就封装一次
而在docker中提出的解决办法是,将最初的rootfs作为一个基座,并在镜像的设计中引入了“层(layer)”的概念,也就是用户制作镜像的每一步操作都会生成一个层,也就是一个增量rootfs
我粗浅的理解为虚拟机的快照,在每一个关键节点打一个快照
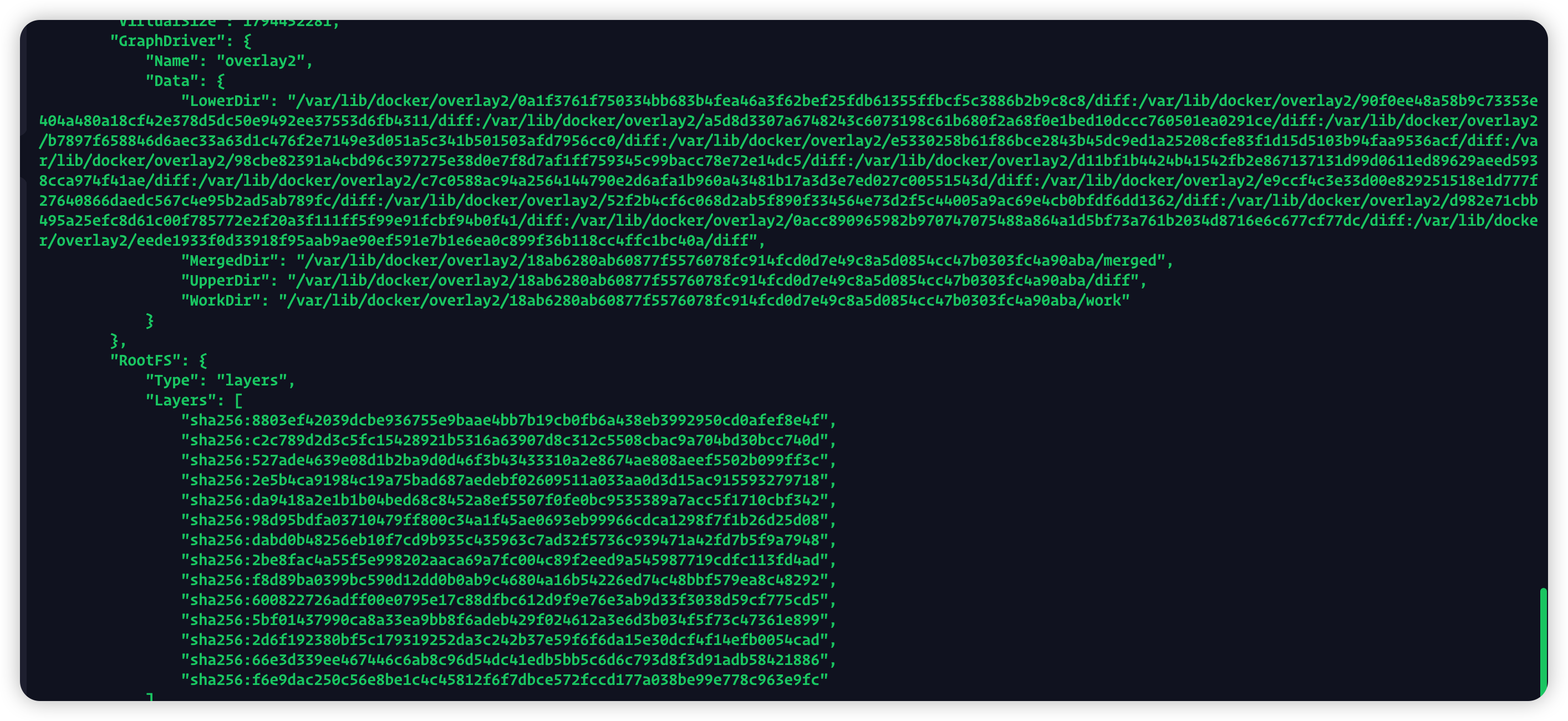
每一层都是容器系统文件与目录的一部分,而在使用镜像时,Docker会把这些增量联合挂载在一个统一的挂载点上
容器的rootfs结构
- 可读写层
- init层(ro+wh)
- 只读层(ro+wh)
以AuFS为例,如果我们需要操作可读写层的文件,比如删除
AuFS会在可读写层创建一个whiteout文件,如.wh.foo文件,当两个层被联合挂载后,foo文件就被.wh.foo文件遮挡,从而消失,一般称之为“白障”
init层在只读层和可读写层之间,是Docker单独生成的一个内部层,专门用来存储/etc/hosts、/etc/resolv.conf等信息
docker exec的执行原理
Linux namespace创建的隔离空间虽然不可见,但是实际上一个进程的namespace信息在宿主机上是以文件形式存在的
通过docker inspect --format '{{.State.Pid}}' 容器id得到进程ID

通过查看宿主机的proc文件,可以看到该进程下的所有namespace对应的文件
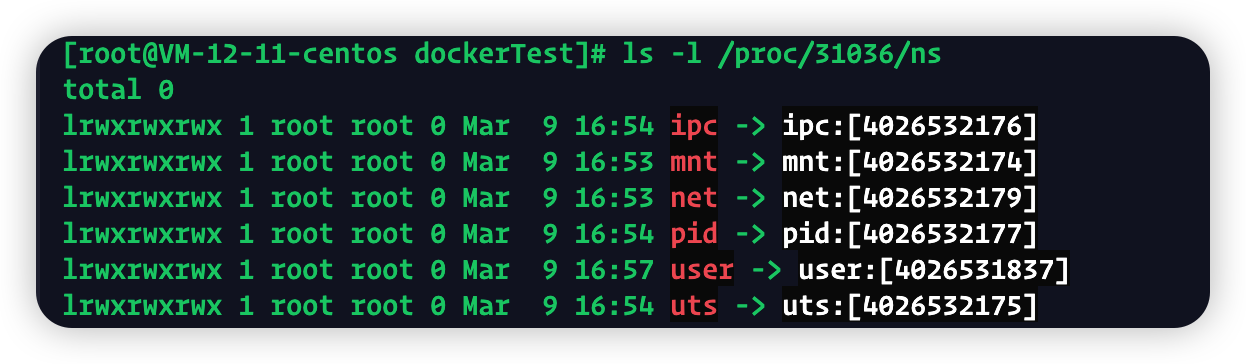
通过/ns看到一个进程的每种Linux namespace都有它对应的一个虚拟文件,并且链接到一个真实的namespace上
容器中的namespace和宿主机中的文件相绑定,那么我们就可以操作这些namespace,比如加入一个已经存在的namespace中
也就是一个进程可以选择加入进程已有的某个namespace中,从而进入这个容器
以net为例:
如果我们现在有一个ubuntu容器已经启动,容器执行后PID=25686,这个容器中默认配置了两个网卡,而宿主机有四个网卡
那么如果我们exec进入到容器内,执行ifconfig命令可以看到的就是两个网卡的信息
一个进程选择加入到另一个进程的某个namespace中的操作主要依赖于setns()的Linux系统调用
示例程序
//set_ns
....
int fd;
fd = open(argv[1], O_RDONLY);
if(setns(fd,0) == -1) {
errExit("setns");
}
execvp(argv[2], &argv[2]);
errExit("execvp");
这个程序接受两个参数,一个是要进入namespace文件的路径,一个是要在这个namespace中运行的进程,比如/bin/bash
set_ns /proc/25686/ns/net /bin/bash
这样就加入到25686的net namespace中去,那么此时我们用它执行ifconfig就是和在25686容器中进程中执行ifconfig得到一样的结果
这说明这两个进程是共享了Net Namespace
在docker中如果指定--net=host,类似桥接模式,此时和宿主机的网络没有隔离,共享宿主机的网络栈
加入其他Namespace同理,从而实现通过exec进入隔离的容器
容器探针
四种方法
| 方法 | 原理 |
|---|---|
| exec | 在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功 |
| grpc | 使用 gRPC 执行一个远程过程调用。 目标应该实现 gRPC 健康检查。 如果响应的状态是 "SERVING",则认为诊断成功 |
| httpGet | 对容器的 IP 地址上指定端口和路径执行 HTTP GET 请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的 |
| tcpSocket | 对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。 如果远程系统(容器)在打开连接后立即将其关闭,这算作是健康的 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号