第四次作业——结对编程
| GitHub地址 | 克隆地址 |
| 结对伙伴 | 郭忠杰 |
| 伙伴学号 | 201831061121 |
| 伙伴博客地址 | 胖狙 |
| 作业链接 | https://edu.cnblogs.com/campus/xnsy/Autumn2019SoftwareEngineeringFoundation/homework/8708 |
| 作业要求 | https://www.cnblogs.com/harry240/p/11524113.html |
软件工程第四次作业——结对编程
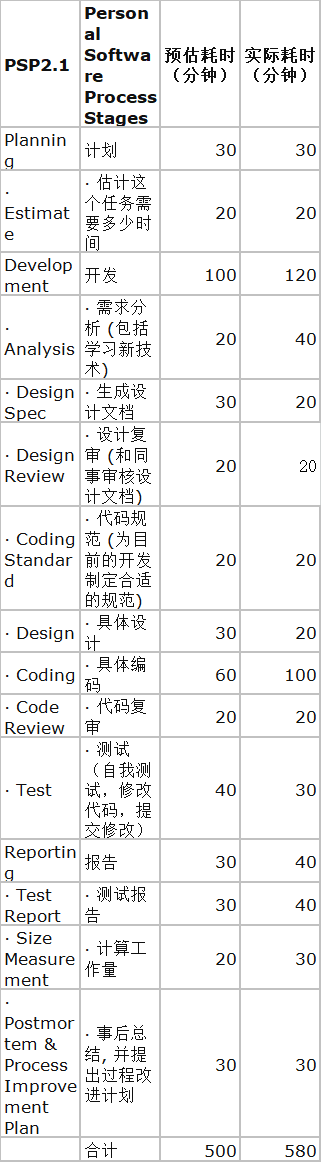
一.psp表格
二.解题思路
这次作业是我和我的室友郭忠杰一起完成的。在刚刚学习了一点点c++后,选择了用这个语言实现这次程序。
首先本次程序的功能要求
统计文件的字符数:
只需要统计Ascii码,汉字不需考虑
空格,水平制表符,换行符,均算字符
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号
例:file123是一个单词,123file不是一个单词。file,File和FILE是同一个单词
输出的单词统一为小写格式
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
统计文件的有效行数:任何包含非空白字符的行,都需要统计。
统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
按照字典序输出到文件txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows200
我们先定义了一个用于计算单词的结构体和一个单词分析的的类。
#pragma once #include <fstream> #include <iostream> #include <unordered_map> #include <algorithm> #include <string> using namespace std; struct WordInf { string word; int count; WordInf() { word = ""; count = 0; } }; class TextAnalysisUtil { public: TextAnalysisUtil(); ~TextAnalysisUtil(); int asciiCount(char * fileName); bool isAsascii(char ch); int countLines(char * filename); int wordAnalysis(char * fileName, WordInf * tempArr);
};
然后对类进行具体的实现
//#include "stdafx.h" #include"pch.h" #include "TextAnalysisUtil.h" TextAnalysisUtil::TextAnalysisUtil() { } TextAnalysisUtil::~TextAnalysisUtil() { } bool isWordGreater(string str1, int n1, string str2, int n2) { bool flag; if (n1 > n2) { flag = true; } else if (n1 < n2) { flag = false; } else { flag = strcmp(str1.c_str(), str2.c_str()) < 0 ? true : false; } return flag; } int TextAnalysisUtil::asciiCount(char * fileName) { //调试用 ifstream fin(fileName); if (!fin) { cout << "文件打开失败"; return -1; } char ch; int count = 0; while (fin.get(ch)) { if (isAsascii(ch)) count++; } fin.close(); return count; } bool TextAnalysisUtil::isAsascii(char c) { return ((unsigned char)c & 0x80) == 0x80 ? false : true; } int TextAnalysisUtil::countLines(char * fileName) { ifstream ReadFile; int n = 0; string tmp; int len; ReadFile.open(fileName, ios::in); while (getline(ReadFile, tmp, '\n')) { len = tmp.length(); for (int i = 0; i < len; i++) { if ((tmp[i] >= 0 && tmp[i] <= 32) || tmp[i] == 127) { continue; } else { n++; break; } } } ReadFile.close(); return n; } int TextAnalysisUtil::wordAnalysis(char * fileName, WordInf * tempArr) { ifstream fin(fileName); if (!fin) { cout << "文件打开失败"; return -1; } char ch; string str; int state = 0; int nflag; int wordCount = 0; unordered_map<string, int> map; while (fin.get(ch)) { if (ch < -1 || ch>255) { return -1; } switch (state) { case 0: //查找单词首的状态 if (isdigit(ch)) { //转入找到数字开头的过滤状态 state = 1; } else if (isalpha(ch)) { //找到单词,转入爬取单词状态 state = 2; str = ch; nflag = 1;//记录单词开头字母数 } break; case 1: //转入找到数字开头或不符合单词开头有4个字母的过滤状态 if (!(isdigit(ch) || isalpha(ch))) { state = 0; } break; case 2: //爬取单词状态 if (isalpha(ch)) { ++nflag; str += ch; if (nflag >= 4) //进入爬取单词尾部状态 state = 3; } else { //不满足单词开头有4个字母 state = 1; } break; case 3: //爬取单词尾部状态 if (isdigit(ch) || isalpha(ch)) { str += ch; } else { //处理和存入字符串 transform(str.begin(), str.end(), str.begin(), ::tolower); state = 0; wordCount++; map[str]++; } break; default: break; } } if (state == 3) //处理最后跳出没来的及处理的字符串 { transform(str.begin(), str.end(), str.begin(), ::tolower); wordCount++; map[str]++; } //遍历找出频率最高的top10单词 for (auto iter = map.begin(); iter != map.end(); iter++) { if (isWordGreater(iter->first, iter->second, tempArr[9].word, tempArr[9].count)) { tempArr[9].word = iter->first; tempArr[9].count = iter->second; for (int i = 9; i >= 1; i--) { if (isWordGreater(tempArr[i].word, tempArr[i].count, tempArr[i - 1].word, tempArr[i - 1].count)) { swap(tempArr[i], tempArr[i - 1]); } } } } fin.close(); return wordCount; }
在这个类的实现中有打开文本,记录单词出现的次数,计算文本的行数,遍历输出文本中出现频率最高的10个单词这几个函数。
最后是功能的实现
#include"pch.h" #include <iostream> #include <fstream> #include "TextAnalysisUtil.h" using namespace std; int main(int argc, char *argv[]) { if (argc < 2) { cout << "未输入命令行参数" << endl; system("pause"); return -1; } TextAnalysisUtil TA; ifstream infile; WordInf tempArr[10] = { }; infile.open(argv[1], ifstream::binary | ifstream::in); if (!infile) { cout << "文件打开失败" << endl; system("pause"); return 1; } infile.close(); ofstream outFile; outFile.open("result.txt"); if (!outFile) { cout << "文件打开失败" << endl; system("pause"); return 1; } outFile << "characters: " << TA.asciiCount(argv[1]) << endl; outFile << "words: " << TA.wordAnalysis(argv[1], tempArr) << endl; outFile << "lines: " << TA.countLines(argv[1]) << endl; for (int d = 0; d < 10; d++) { if (tempArr[d].count > 0) outFile << "<" << tempArr[d].word << ">: " << tempArr[d].count << endl; } system("pause"); }
在程序中会生成一个文本文件记录单词的个数和高频词。
三.代码结果
目标初始文本
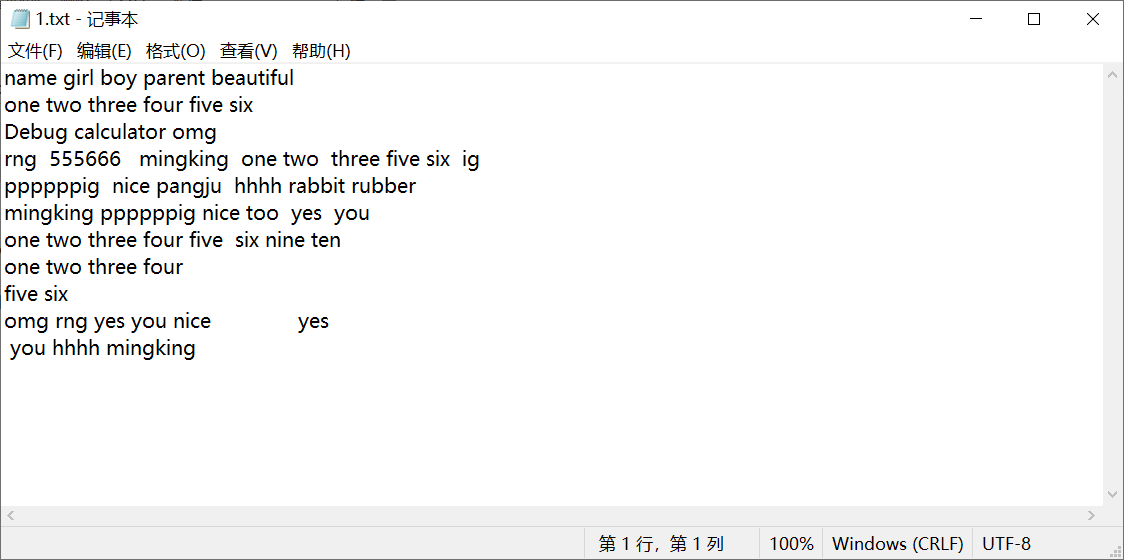
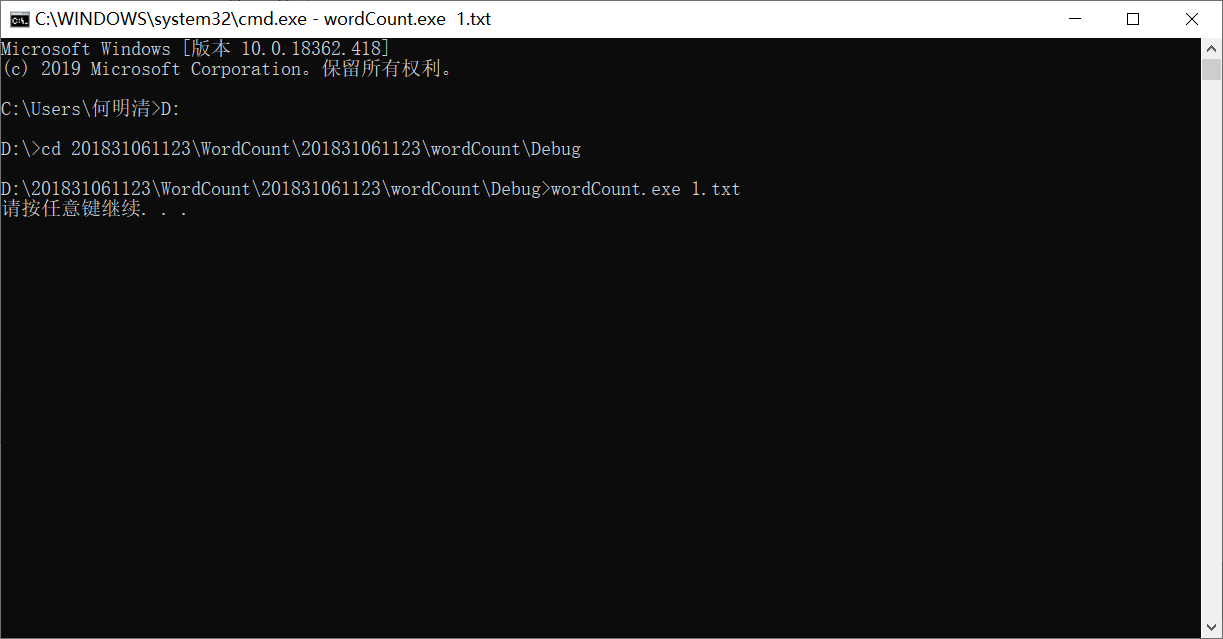
结果文本

四.代码性能分析

五.代码复审
1.我们采用的模型是写了再改模型,遇到了一个典型的麻烦就是一个地方改动,其他的地方就要跟着变,不过还好不是很麻烦。
2.由于我们C++的功底不是很牢,最开始出现了很多的语法错误,纠正后自己的语法能力也得到了提升。
3.可读性的话个人认为还是比较好,因为经过两个人的审查我觉得已经可以比较容易阅读。
4.设计的缺陷我觉得还是比较大,毕竟开发的时间也不长,而且对C++也比较不熟悉。
六.结对编程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号