
对比学习入门(3):论文系列导读
🔙对比学习总结
在对比学习入门中,我们了解了对比学习的来源、基本思想和处理步骤。在对比学习时间线的发展中我们了解了近年来论文概要。对比学习不是一种模型,也不是一种新的技术,而是一种思想,这种思想与模型无关,可以应用于各种模型,比如Transformer的训练过程中就有对比学习辅助。现在对比学习的研究方向有如下三个
- Data Augmentations
- Sampling Strategy
- Loss function
这三个研究方向的难度依次生提高。本人研究生阶段主要研究图相关、序列数据相关的内容、所以研究方向也和这两个领域相关。
Data Augmentations是最常研究的一种改进,数据增强可以得到更多正样本。通过最大化原始数据和数据增强后的数据的相似度,来学习到更适合分类的特征。在对比学习入门中我们提到了个体判别任务。但是个体判别任务有一个问题, 会把同属于同一个类别的样本也在特征空间中拉远, 这个问题后续也有人进行进一步研究, 后续章节会提到。如何在图或是序列信息上使用Data Augmentation是也是需要考虑的。
Sampling Strategy已是AI中非常重要的研究方向, 像Facebook研究的EBR采样[1]提出了硬负样本的重要性, 知乎也有大佬进行了总结[2], 所谓硬负样本就是和正样本的特征十分相似但是标签不一样的样本. 由于对比学习是无监督学习, 并没有额外的标签信息能用来进行硬负样本的判断, 直觉上好像只能随机抽样, 那对Sampling Strategy的研究也有许多后续研究.
Loss Function作为对比学习中最重要的存在, 自然受到了许多的研究, 从度量学习中Triplet Loss[3]开始, 对比学习中从NCE[4]到InfoNCE[5]一系列有名的研究都是, 再到SupCon Loss[6]^]对对比学习中的Loss Function进行了分析和研究.
后续章节如下, Contrastive Method介绍对比学习的方法, Training Schema介绍如何把对比学习和主模型结合起来训练, Data Augmentation, Sampling Strategy, Loss Function, 这三章会介绍主流的一些方法和研究, 其中Loss Function章节中会有一些公式推导和分析, 最后一章进行总结.
Contrastive Method
对比学习通用训练流程如下,原始数据\(D\)通过多种数据增强方式\(\Gamma(\cdot)\)得到数据增强的数据\(\tilde D\)。将\(\tilde D\) 送到Encoder中学习特征,这个Encoder可以是任何模型比如CNN,GNN,Transformer等模型。我们将特征用\(f_\theta(\tilde D)\),再将特征通过一个Head projection \(g_{\varphi_s}(\cdot)\)函数用于对比学习任务,一般是一层MLP。最后将多个数据增强数据使用对比学习loss function。
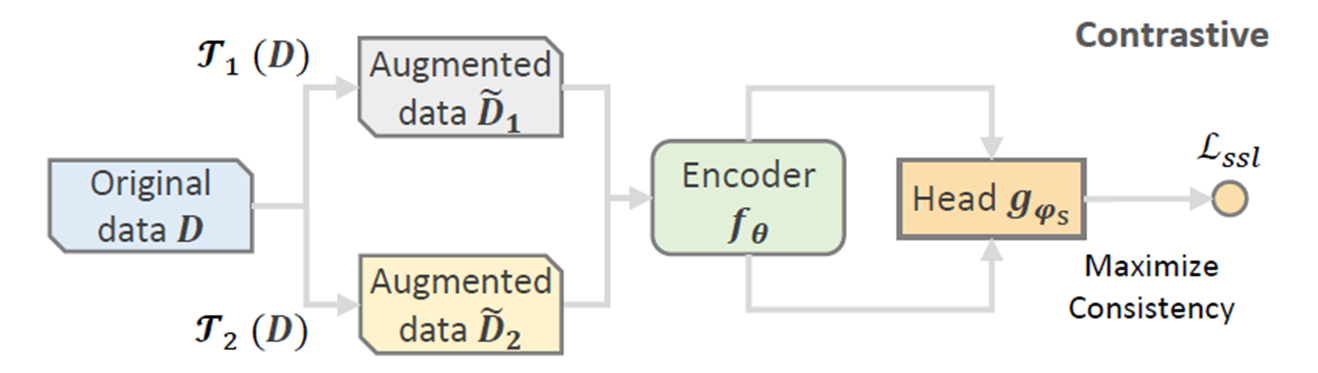
我们可以使用如下同时将上述流程使用公式表达:
Training Schema
上一章介绍了对比学习的方法, 本章就要继续介绍如何把对比学习方法与主模型一起训练. 主流的办法有三种Joint Learning(JL), Pre-training and Fine-tuning(PF), Integrated Learning(IL). 其中对比学习最常用的是第一种JL方法,BERT等预训练模型使用PF方法。
Joint Learning
Joint Learning, 最常用的对比学习模式如下图所示, 这里的图展示了只做一次数据增强的流程, 和上一章讲的对比学习方法十分相似, 区别是多了一个Head projection \(g_{\varphi_r}(\cdot)\) , 同样是一层MLP, 不过这个MLP层是用来做主模型预测任务, 而不是对比学习任务. \(\mathcal L\)是主任务的loss. Joint Learning有点类似多任务学习的方式, 把对比学习作为主模型的辅助任务
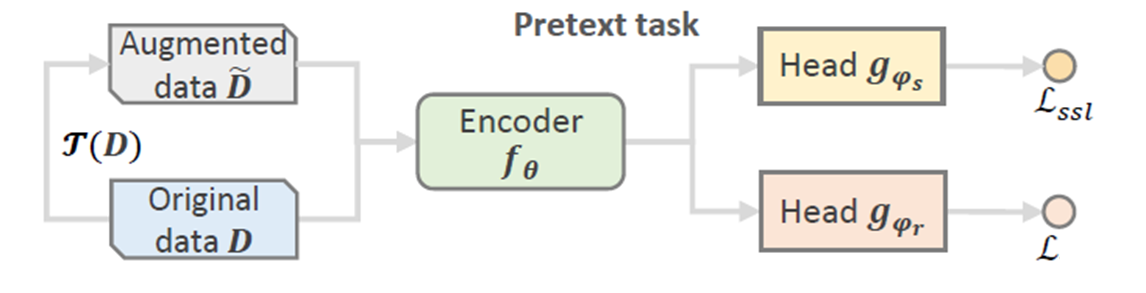
Pre-training and Fine-tuning
预训练和微调的办法, 在对比学习中用得不多, 一般是BERT使用, 如下图所示. 分为上下两部分, 上半部分, 将数据增强的数据\(\tilde D\)预训练Encoder并且使用对比学习的 \(L_{ssl}\)得到更好的特征. 下半部分, 将学习到的Encoder的模型参数作为微调模型的初始化参数, 将原始数据$ D $输入到模型中得到特征, 然后使用 \(L\) 比如softmax loss去训练主任务,.
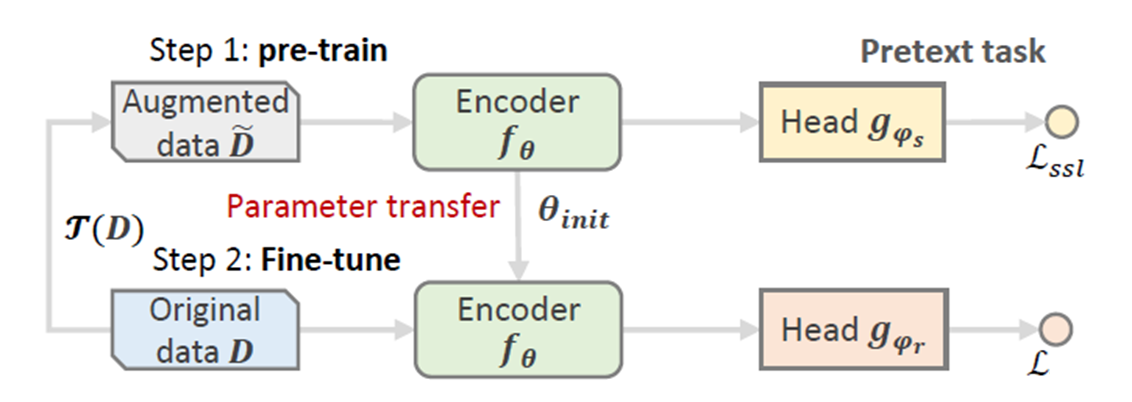
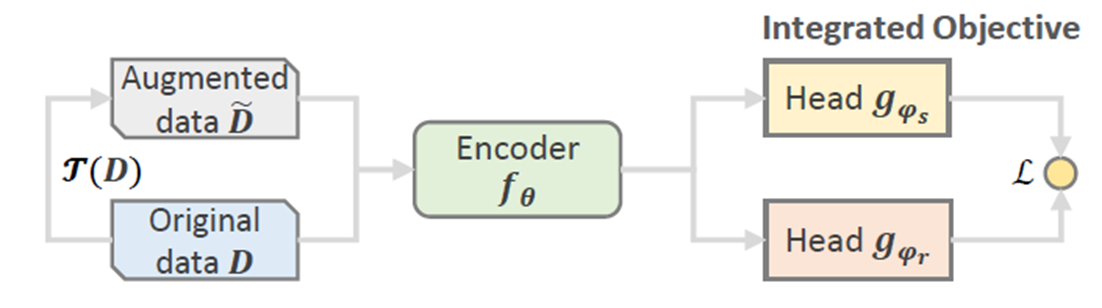
Integrated Learning(IL)
Integrated Learning相关研究较少, 一般是在自预测的模型里面使用, 前半流程和JL一模一样, 唯一的区别就是最后的loss function不再区分对比学习的loss和主模型的loss, 而是合二为一, 只用一个loss完成两者的任务
Data Augmentations(DA)
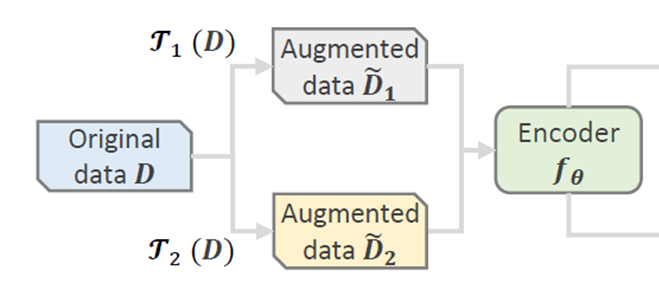
数据增强函数\(\Gamma(\cdot)\),在不同领域中有不同的方法,这些方法都不需要人工参与。比如在计算机视觉CV(Computer vision)中,可以是裁剪,旋转,增加对比度等方法。在图数据中,可以是增加边,节点等方法。在序列数据中可以通过删除,或者交换前后数据等方法。这些DA方法可以分为Data-level增强和Model-level增强。Data-level数据增强如下图所示, 和之前介绍的流程一样, 通过数据增强方式\(\Gamma(\cdot)\)得到原数据 $D \(的增强结果\)\tilde D$ , 可以看到我们是先对数据做增强再送入到Encoder。
Model-level的数据增强如下所示, 可以看出我们并不使用数据增强的办法, 而是直接把数据$ D$ 直接输入到Encoder里面, 在Encoder学习到两种特征 $h1,h2 $, 并没有先前我们讲的传统意义上的数据增强方式, 但是最后我们还是能得到 $D $的两种特征表示.
Data-level DA
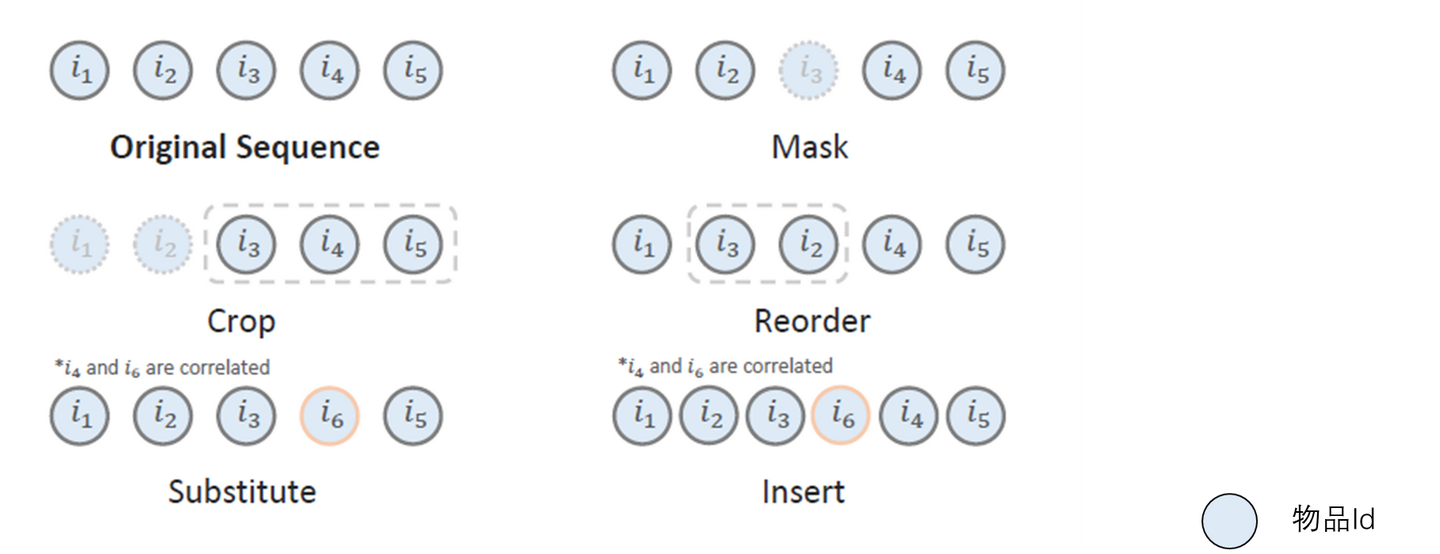
首先我们先介绍以 S3-Rec[7]CL4SRec[8]CoSeRec[9]为代表的序列预测模型的数据增强方式. 具体方法如下图所示, 可以很直观的看出不同数据增强办法, 都是希望加强后的数据比如Mask后的序列特征和原序列的特征最相似, 这些办法非常直觉. 这些不同的增强办法需要人工组合尝试.
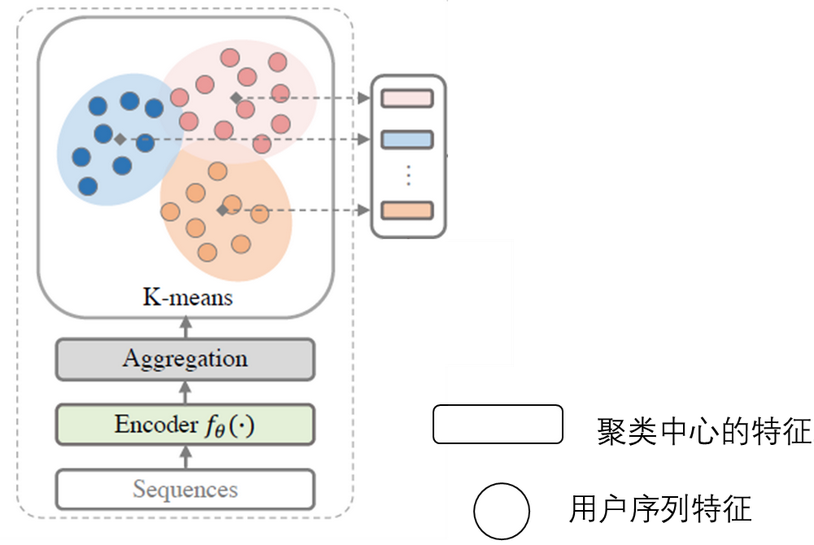
还有一种序建模ICL[10]使用的数据增强办法就是K-means聚类办法如下图所示, K-means作为一种无监督学习算法引进对比学习中,可以参考PCL[11].对于所有的序列Sequences通过Encoder\(f_\theta(\cdot)\)得到所有序列的特征, 将这些特征使用K-means算法得到聚类后的结果, 每个聚类中心代表了用户序列的意图Intention. 在训练的时候就会希望每个序列特征和它对应的聚类中心相似.

引入K-means的一种好处就是可以让相似的特征靠近. 在普通的个体判别任务里面, 是希望每个个体之间的特征是相互正交的, 远离的, 如下左图所示, 这样会导致我们即使是同一个类别比如"狗", 在特征空间中也是远离. 通过K-means可以让相似的特征靠近, 如下右图所示.
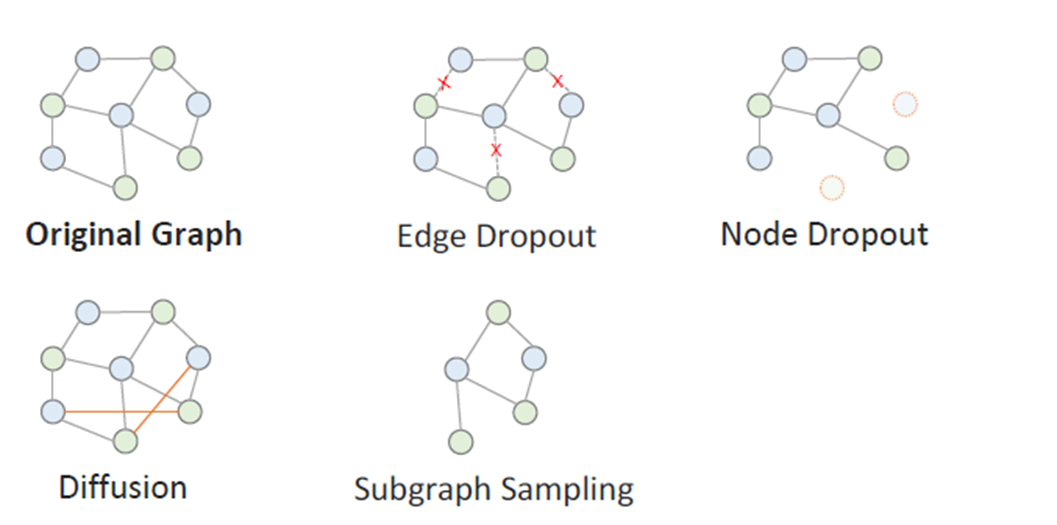
然后我们介绍以SGL[12]为代表的图数据结构模型中的数据增强办法.GNN中常用的图增强方式, 如下图所示, 也是非常直觉的方式.
协同过滤也有使用聚类的方法NCL[13],如下图所示. 一般会把物品和用户的特征使用聚类算法得到latent class, 就会希望物品和用户特征和他们聚类中心相似. 核心思想和上面的序列建模中使用聚类算法一样. 在有了latent class的情况下还有进一步的研究, 会在后续的Sampling Strategy和Loss function中再进一步说明.
- 方法繁多, 需要人工多次尝试
- 可能破坏原数据中内部关联
- 数据增强的具体步骤, 需要先验知识
对于第2点, 在序列建模中对长度为2的节点如果使用Mask这类操作, 可能会和原序列完全没关联, 或者在协同过滤的二部图中使用edge dropout可能会让原来的图变成两个分离的子图. CoSeRec[14]对于较短序列会放弃使用一些数据增强方法.
Model-level DA
对于Data-level数据增强方式的缺点, 可以使用Model-level的方式, 正如在本章开篇讲述的这两者的区别, Model-level的数据增强并不需要做传统意义上的数据增强方式, 而是直接输入到Encoder里面得到多个不同的特征.
在序列场景下NLP下的SimCSE[15]的办法. 使用Transformer作为backbone, 在模型上使用了两个不同的dropout mask, 这样同一个物品输入进模型会得到不同的embedding输出, 但是这两种输出的原型是同一个物品, 并不需要使用Data-level的方法就能得到两个不同embedding. 这种通过改变dropout mask生成正样本的方法可以看作是数据增强的最小形式,因为原样本和生成的正样本的语义是完全一致的,只是embedding不一样.
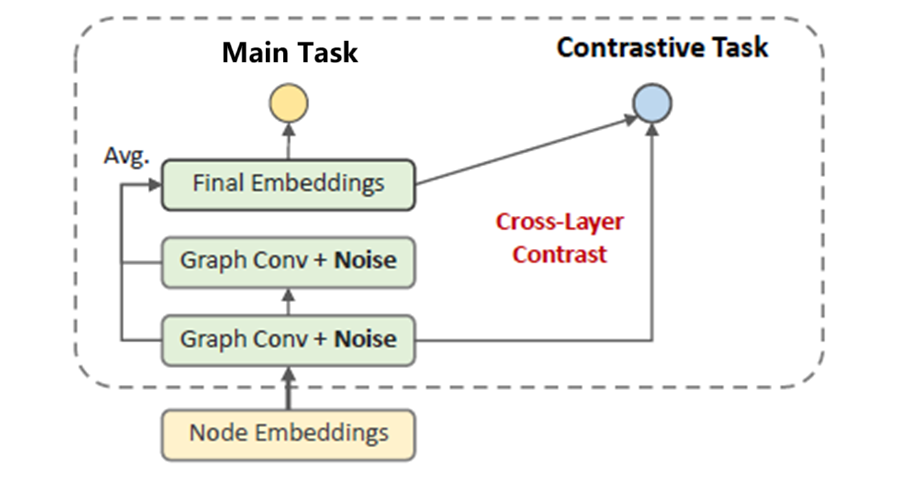
在GNN场景下, 有SimGCL[16]和XSimGCL[17]这一系列工作. 最新的XSimGCL模型设计如下, 可以看出和普通的GNN的学习过程很相似, 区别是作者借鉴了GAN中加入噪声会有利于训练的思想. 在每一层GNN Layer中会加入一些噪声Noise作为扰动, 并且让Final Embeddings和第一层GNN Layer中的Embeddings的节点做对比学习. 也就是希望最后学习到的特征和GNN早期的特征相似. 和DuoRec中的做法类似, 都是同一个物品输入模型, 模型自带一些扰动, 让同一个物品可以得到不同的embedding, 并且用这些embedding做对比学习任务.
Sampling Strategy
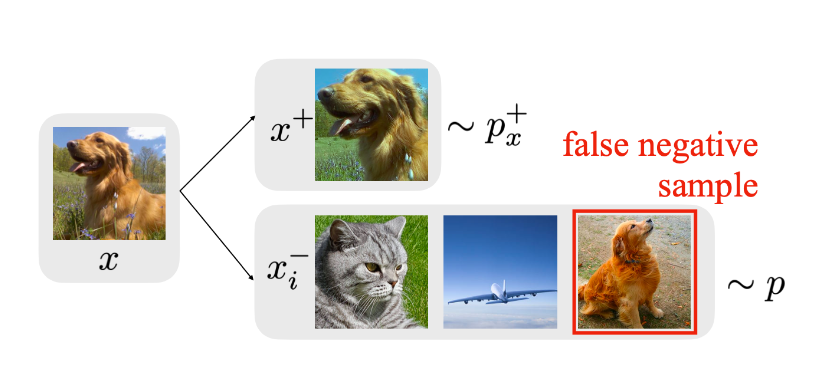
在采样策略中主要想介绍一下Debiased Contrastive Learning[18]. 这篇论文主要想解决false-negative problem, 如下图例子可以看出对比学习中作为无监督学习, 由于没有标签信息只能做个体判别任务, 这导致负样本可能会抽样到同一个类别的狗, 这并不是好. 这个狗就是作为false-negative sample, 它应该是属于positive的样本
假设latent class \(c\)的概率为\(p(c) = \eta^+\) 那么其他class的抽样概率为\(\eta^-=1-\eta^+\)。定义\(x'\),作为\(x\)的正样本被抽中的概率为\(p_x^+(x')\),作为\(x\)负样本被抽中的概率为\(p_x^-(x')\)。那么实际抽取到\(x'\)的全概率公式如下:
背后隐藏的含义就是, 当我们想去抽取一个样本作为负样本的时候, 我们其实并不能直接得到\(p_x^-\) ,因为你也可能抽到来自同一个latent class下的其他样本,有了上述公式我们就可以得到我们真正的负样本采样的概率如下, 就是一个简单的移项:
举一个例子来说的话, 假设一共有\(N\)个样本\(\{u_i\}_i^N\)来自总体的 \(p\) 分布, 其中有\(M\)个正样本 \(\{v_i\}_i^M\) 来自正样本分布\(p_x^+\), 那么我们实际的负样本抽样公式如下:
Loss function
首先需要明确的一点是对比学习是作为辅助任务用来优化主模型学习到的特征,让同一个物品不同视角下的特征相似, 让不同物品的不同视角下的特征相互远离.
Triplet Loss[3:1]
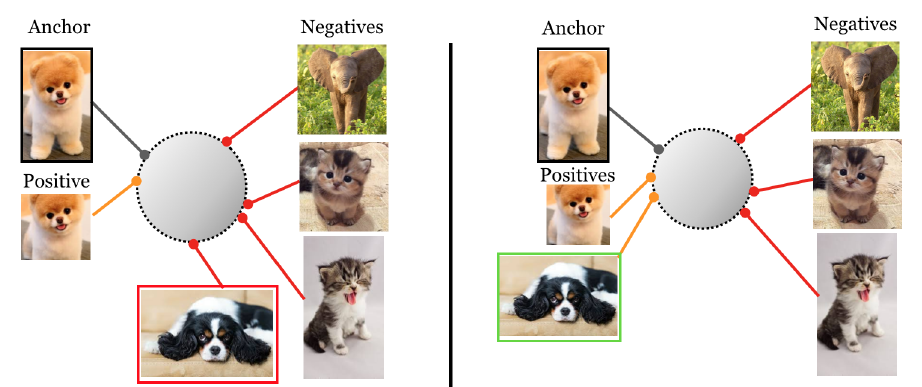
Triplet Loss 作为早期使用的损失函数,虽然现在在对比学习中已经很少使用了,但是它的思想是一脉相承的。如下图所示,我们希望anchor在特征空间中和positive更加接近,和negative远离。我们可以认为数据集中用户交互过的物品为正样本,没有交互过的物品为负样本
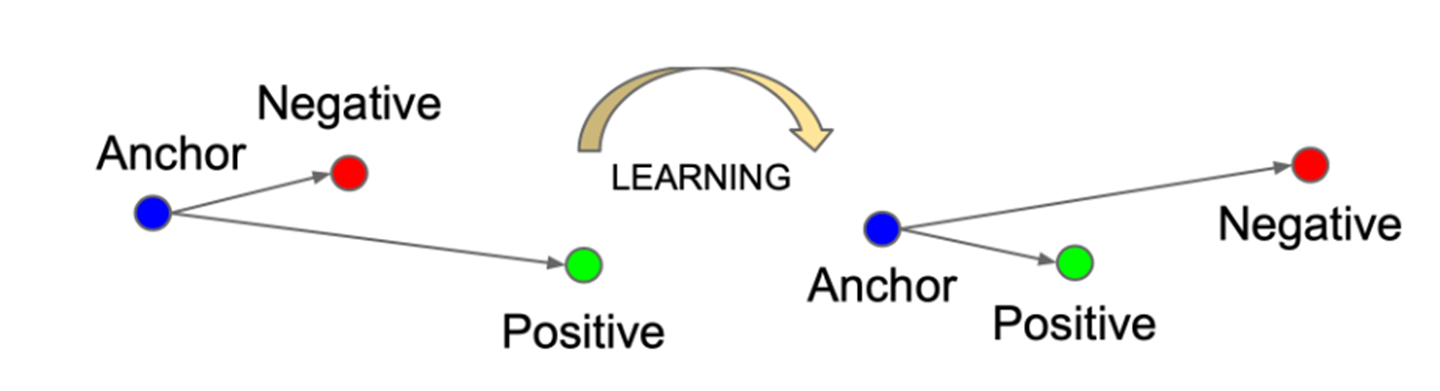
Triplet Loss的公式表示如下, \(x\) 代表anchor, \(x^+\),\(x^−\) 代表正负样本,超参数\(\epsilon\)为\(x^+\),\(x^−\) 之间最小的偏移量. 这个公式最大的问题就是训练太慢了
NCE Loss/InfoNCE Loss
对于特征相似还有一种理解视角, 就是互信息最大化, 也就是同一个物品不同视角下的特征之间的互信息应该最大化. 这一节将要推导的NCE和下一节将要推导的InfoNCE就是互信息的一种近似估计办法(也叫JSD估计), 为什么不直接计算互信息, 因为互信息的计算太过于复杂, 只能近似估计.由于推导太多,我们使用新的两篇文章对比学习最常用的两个损失函数性质进行介绍。
具体内容见
Embedding-based Retrieval in Facebook Search https://arxiv.org/abs/2006.11632 ↩︎
负样本为王:评Facebook的向量化召回算法 https://zhuanlan.zhihu.com/p/165064102 ↩︎
FaceNet: A Unified Embedding for Face Recognition and Clustering https://arxiv.org/abs/1503.03832 ↩︎ ↩︎
Noise-contrastive estimation: A new estimation principle for unnormalized statistical models https://proceedings.mlr.press/v9/gutmann10a ↩︎
Representation Learning with Contrastive Predictive Coding https://arxiv.org/abs/1807.03748 ↩︎
Supervised Contrastive Learning https://proceedings.neurips.cc/paper/2020/hash/d89a66c7c80a29b1bdbab0f2a1a94af8-Abstract.html ↩︎
S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization https://dl.acm.org/doi/abs/10.1145/3340531.3411954 ↩︎
Contrastive Learning for Sequential Recommendation https://ieeexplore.ieee.org/abstract/document/9835621 ↩︎
Contrastive Self-supervised Sequential Recommendation with Robust Augmentation https://arxiv.org/pdf/2108.06479.pdf ↩︎
Intent Contrastive Learning for Sequential Recommendation https://dl.acm.org/doi/abs/10.1145/3485447.3512090 ↩︎
PROTOTYPICAL CONTRASTIVE LEARNING OF UNSUPERVISED REPRESENTATIONS http://export.arxiv.org/pdf/2005.04966 ↩︎
Self-supervised Graph Learning for Recommendation https://dl.acm.org/doi/abs/10.1145/3404835.3462862 ↩︎
Improving Graph Collaborative Filtering with Neighborhood-enriched Contrastive Learning https://dl.acm.org/doi/abs/10.1145/3485447.3512104 ↩︎
Contrastive Self-supervised Sequential Recommendation with Robust Augmentation https://arxiv.org/pdf/2108.06479.pdf ↩︎
Simcse: Simple contrastive learning of sentence embeddings https://arxiv.org/abs/2104.08821 ↩︎
Are Graph Augmentations Necessary?: Simple Graph Contrastive Learning for Recommendation https://dl.acm.org/doi/abs/10.1145/3477495.3531937 ↩︎
XSimGCL: Towards Extremely Simple Graph Contrastive Learning for Recommendation https://arxiv.org/abs/2209.02544 ↩︎
Debiased Contrastive Learning https://proceedings.neurips.cc/paper/2020/hash/63c3ddcc7b23daa1e42dc41f9a44a873-Abstract.html ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号