
对比学习入门(2):序列数据如何做对比学习
序列数据如何做对比学习
前文对比学习入门中我们介绍了图片的例子,在另一篇文章CPC中作者在音频数据上做对比学习,进一步所有序列数据都可以使用对比学习。为此我们在这篇文章中以一个简单的例子介绍序列数据如何做对比学习,方便大家理解CPC的原理,原文其实挺难理解的。
简单的例子
我们以语言序列(I like cat forever)为例子,介绍如何在序列数据上做对比学习,示意图如下
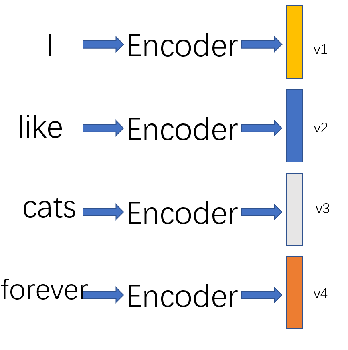
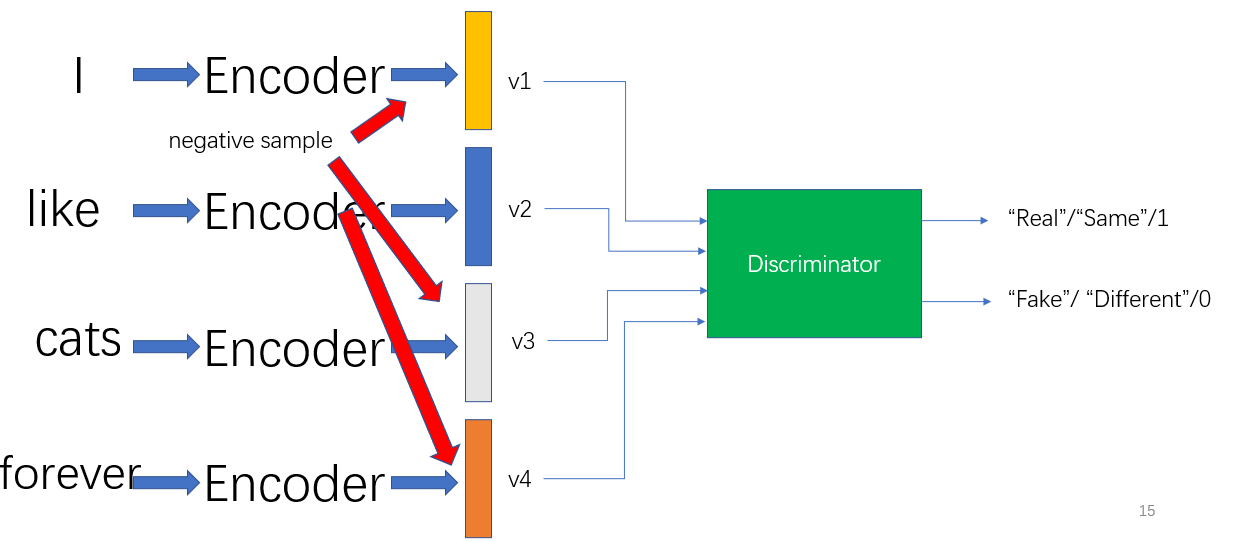
我们将每个单词送入Encoder得到对应的\(v_1,v_2,v_3,v_4\),按照前文的介绍,我们需要训练一个辨别器,示意图如下。重点就在于如何定义正样本和负样本。

对于一个序列特征,直觉告诉我们,当前位置\(t\)应该与\(t+1\)有关,比如"I"和"like"相关,"like"和"cat"相关,所以相邻位置的数据成为了正样本。负样本示意图如下,在图中以\(v_1\)作为锚点,\(v_2\)就是正样本,\(v_1,v_3,v_4\)全都是负样本。我们可以发现\(v_1\)是\(v_1\)的负样本,这和前文的例子就有区别,对比学习定义正样本的方法是非常灵活的。
CPC简单介绍
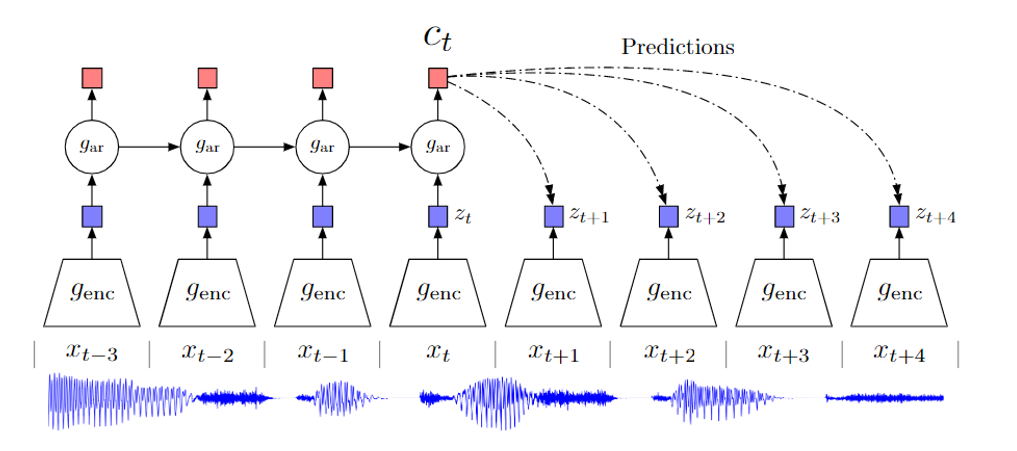
上图展示了CPC的整体框架。\(x_t\)为锚点,小于\(t\)的数据都是历史数据,大于\(t\)的数据是预测数据Predictions。
对所有数据使用\(g_{enc}\)进行编码,得到音频的特征向量。作者定义了\(c_t\)为上下文变量,通过\(g_{ar}\)自回归算法累计所有历史数据。
CPC定义的正样本和上一小节的例子有所不同,定义\(c_t\)和未来\(k\)步的特征向量\(z_{t+k}\)为正样本,所有其他数据都为负样本。至此可以比较直观地理解CPC,更详细内容可以读CPC内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号