Risc-v之Cache设计方案
cache设计
目的
为了解决访问DDR的慢速的问题。将常用指令,数据等缓存在CPU寄存器中,加快访问速度。
- 解决操作系统内存按字节寻址与内存控制器按行寻址的矛盾
- 解决操作系统按字节操作内存与内存控制器按行操作的矛盾
设计思路/原理
Cache可以根据数据的缓存分组方式,可以分为三大类。我们在设计Risc-v的L1 cache的时候,有必要简单了解一下高云提供的DDR3内存控制器的用法与SDRAM原理图。
SDRAM寻址
在一根内存条中会包含多个SDRAM芯片,真正的内存数据会使用SDRAM芯片存储。如图黑色的部分

在内存寻址中使用rank信号线选择在哪个SDRAM芯片中寻址。每个SDRAM芯片中有着一模一样的架构。
在每个SDRAM芯片中,使用bank信号线选择具体分区。在每个bank中有着同样的行和列去选择。所以在硬件选址中是图中的寻址架构。

那我们是如何知道,每一行的数据宽度呢?可以查询DDR3芯片的datasheet,或者数DQ线。DQ的意义在于,DDR3芯片中,每一行是多少字节。根据上面这些基本知识,我们可以查看逻辑派-G1的原理图
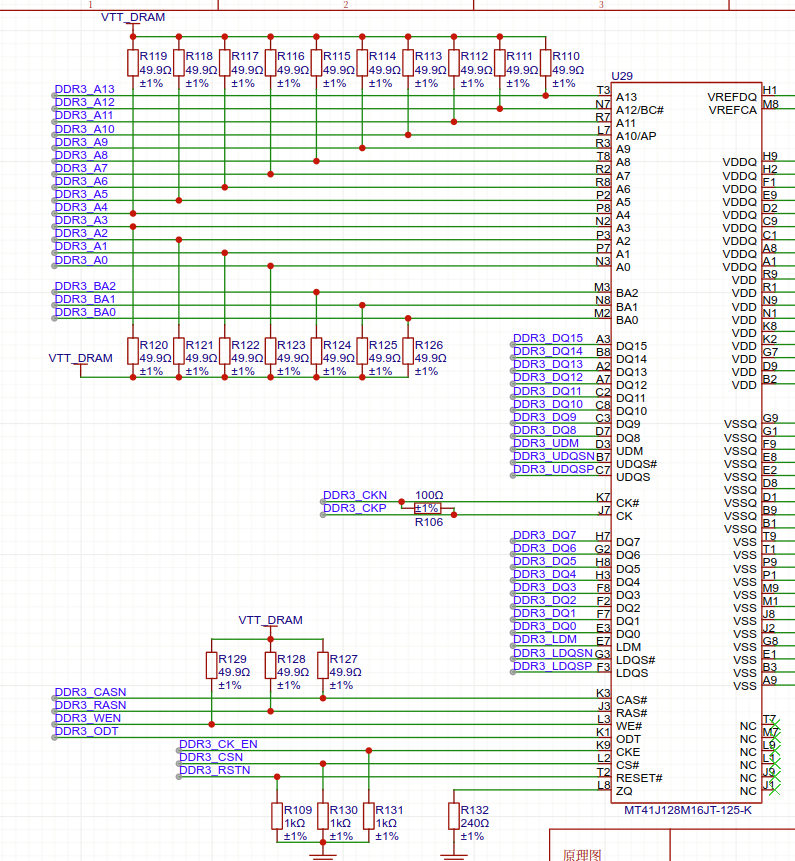
在原理图中,一共有
- 16根DQ线,说明DDR3芯片的行宽度是16位,x16
- rank是片选信号,SDRAM芯片无能力做片选,忽略
- 3根bank信号线,BAR0-BAR2
- 行和列公用A0-A13
- CAS与RAS代表是行地址选通信号和列地址选通信号
- WE代表写使能
下面我们来计算一下该SDRAM的芯片大小
2^(bank宽度 + 行宽度 + 列宽度 + DQ总线宽度),其中行宽度和列宽度请查阅SDRAM芯片手册。同理,我们也可以很容易设置高云提供的IP核
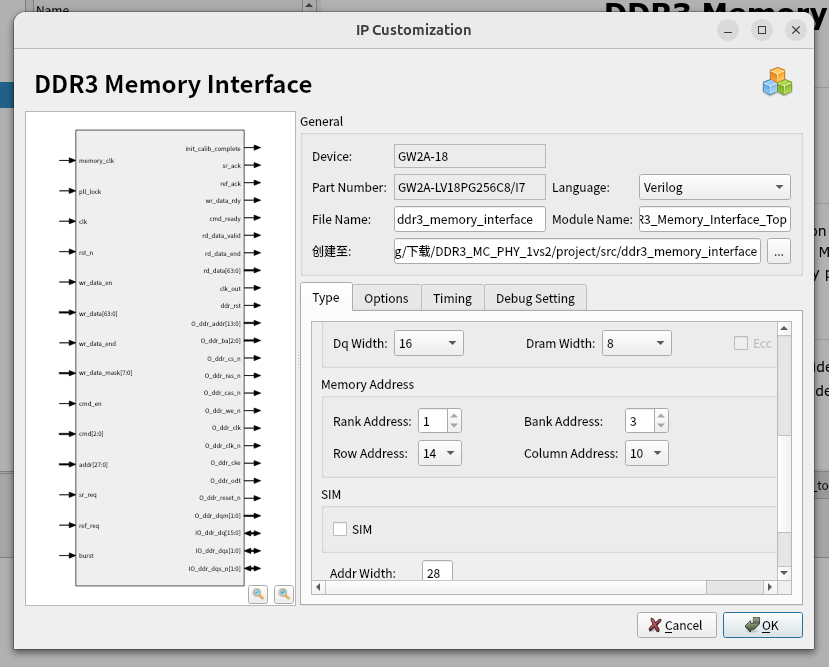
DDR3内存控制器用法
在DDR3中我们发现,命令之间是互斥的,这里的命令包括但不限于自充电(刷新),读与写。并且寻址是按照行,而不是操作系统端的以字节。这是一个很大的区别.在我们的例子中,DDR3每行是两个字节。
在DDR3中,还有一个是时钟比例,你可以通俗理解为,在某一时钟边缘能对DDR3进行几次读写。在我们的例子中为1:2。所以,在每个时钟边沿,最少要对DDR3数据操作字节数
APP_DATA_WIDTH = 2 * nCK_PER_CLK * DQ_WIDTH 例如在我们的DDR3中,一次最少操作64位,8字节数据。
这揭示了我们为什么需要L1 cache。在内存控制器的读写中,一次最少读写8字节数据,在高端cpu中这个数字只增不减。而在操作系统端,内存寻址只操作4字节数据。这其中就会有严重不匹配,cpu也不能因为这个理由频繁向内存控制器发出请求,如果cpu向内存请求的地址处在行中末尾,内存控制器需要复杂的运算才能完成任务,这样即增加了内存请求次数,也增加了FPGA实现的复杂度。所以增加L1 cache,将一次性读取的内容缓存,以供后续使用,被称为Cache line。
从DDR3控制器用法中,我们也可以得到内存对齐的重要性。让我们的内存访问尽量在一个缓存行中,否则就要发起两次内存请求,麻烦。
内存控制器的用法如下流程。内存控制器最大的意义是,为我们屏蔽了DDR3复杂的时序操作等需求,对开发者只暴露最简单的读写操作。
示例代码如下,简化不必要的部分
if (BURST_MODE == "4") begin : app_burst_4
// 每次地址往前+4,
// DDR3内存访问说明:
// 总容量=rank数×bank数×row数×col数×数据宽度
// DDR3数据总线宽度为16位(2字节)
// 由于DDR3为双倍数据速率(DDR),每个时钟周期可传输2个数据
// 控制器突发长度通常为4或8(BL4/BL8),常用为BL8
// 若BL8,则一次突发传输16字节(16位 × 8 = 128位 = 16字节)
// 实际内存控制器每个操作周期可访问64位(8字节)数据,地址步进为8
// 列地址(col)作为突发起始列地址,一次操作可访问连续多列(如4列)
// 因此,col寻址时,一次写入4列,带宽和
// 步进大小,DDR3 配置下,一次可以读写4行,每行2字节,一共8字节
assign addr_step = 4'd4;
always @(posedge clk or posedge rst) begin
// 初始化完成,并且当前内存控制器可以接收指令和可以写
if (app_rdy && app_wdf_rdy && init_calib_complete && cnt == 8'd10) begin
// 向内存控制器发出命令与地址信号的使能
app_en <= 1'b1;
// 命令
app_cmd <= 3'b000; //write
// 写使能
app_wdf_wren <= 1'b1;
// 写结束,我们的写入只跨越一个时钟周期,所以写完停止即可
app_wdf_end <= 1'b1;
// 写掩码,0写1不写
app_wdf_mask <= {APP_MASK_WIDTH{1'b0}};
// 固定设置0
app_burst <= 1'b0;
// 内存寻址
app_addr <= reg_addr;
// 写入内容
app_wdf_data <= mem_data[mem_index];
end else if (app_rdy && init_calib_complete && cnt == 8'd70) begin
app_en <= 1'b1;
app_cmd <= 3'b001; //read
app_wdf_wren <= 1'b0;
app_wdf_end <= 1'b0;
app_wdf_mask <= {APP_MASK_WIDTH{1'b0}};
app_burst <= 1'b0;
app_addr <= reg_addr;
app_wdf_data <= {APP_DATA_WIDTH{1'b0}};
end
end
时序约束文件的编写
我们都知道电子虽然传输速度很快,但是也是需要时间的,类似于MINECRAFT中的红石系统延迟。时序约束文件的主要作用是,告诉FPGA在优化布线中,一个语句块的信号传输的时间一定要小于我们规定的时间,防止出现一个信号跨越多个传输周期的情况。如果违反时序约束,就会出现亚稳态传输,造成FPGA的结果不确定。知道了原理,下面简单介绍一下时序文件的写法。
- 用
get_ports {xxx}选中的端口,以及和这个端口相关联的时序路径(比如从这个端口到内部寄存器,或者从内部寄存器到这个端口),综合和布局布线工具会根据你设定的时序约束来分析和优化布线,以满足你的时序要求(比如最大延迟、保持时间等)。
常见命令说明
-
create_clock
创建一个时钟约束,指定时钟周期、占空比、作用对象等。
create_clock -name clk -period 20 -waveform {0 10} [get_ports {clk}]上例表示在输入端口
clk上创建一个 20ns 周期、50MHZ的时钟,下降沿是0ns,上升沿在10ns处。 -
set_input_delay / set_output_delay
指定端口的输入/输出延迟(如外部设备到 FPGA 的采样延迟),通常配合时钟使用。
set_input_delay 3 -clock [get_clocks clk] [get_ports {data_in}] set_output_delay 5 -clock [get_clocks clk] [get_ports {data_out}] -
set_clock_groups
设置不同时钟域为“互斥时钟组”,工具不会分析它们之间的时序路径。
set_clock_groups -exclusive -group [get_clocks {clk}] -group [get_clocks {memory_clk}]
Cache 设计
直接相联映射
将内存地址划分为Tag、Index和Offset三部分,查找时先用Index快速定位缓存组,再用Tag在组内少量候选项中匹配,有效降低查找硬件的复杂度和延迟。
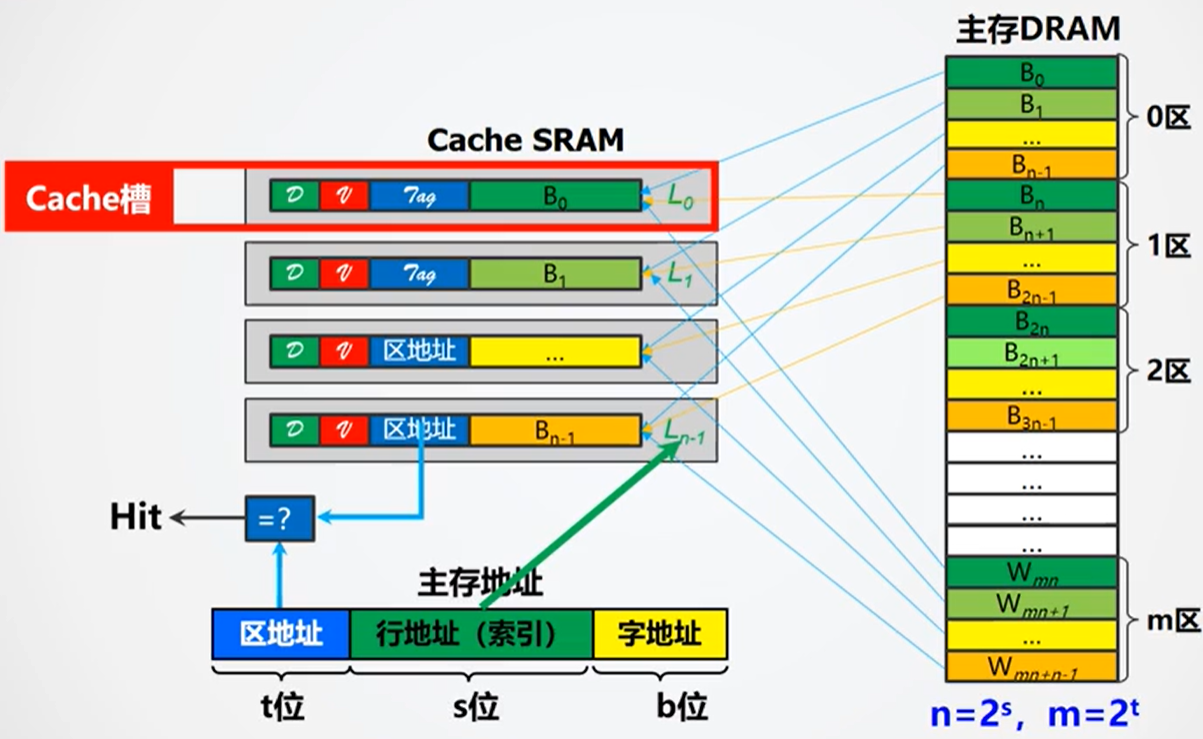
查找的流程如下:
- 根据行地址查找Cache中对应的行
- 根据区地址(标记位TAG)以及一些标志位(有效位 )来判断是否与主存中所要查找的区对应
- 如果TAG一致,则输出该行的数据内容,同时根据字地址来选择最终字的输出
- 如果TAG不一致,则从主存中载入到相应地址的内容到Cache中,再由Cache传输给CPU
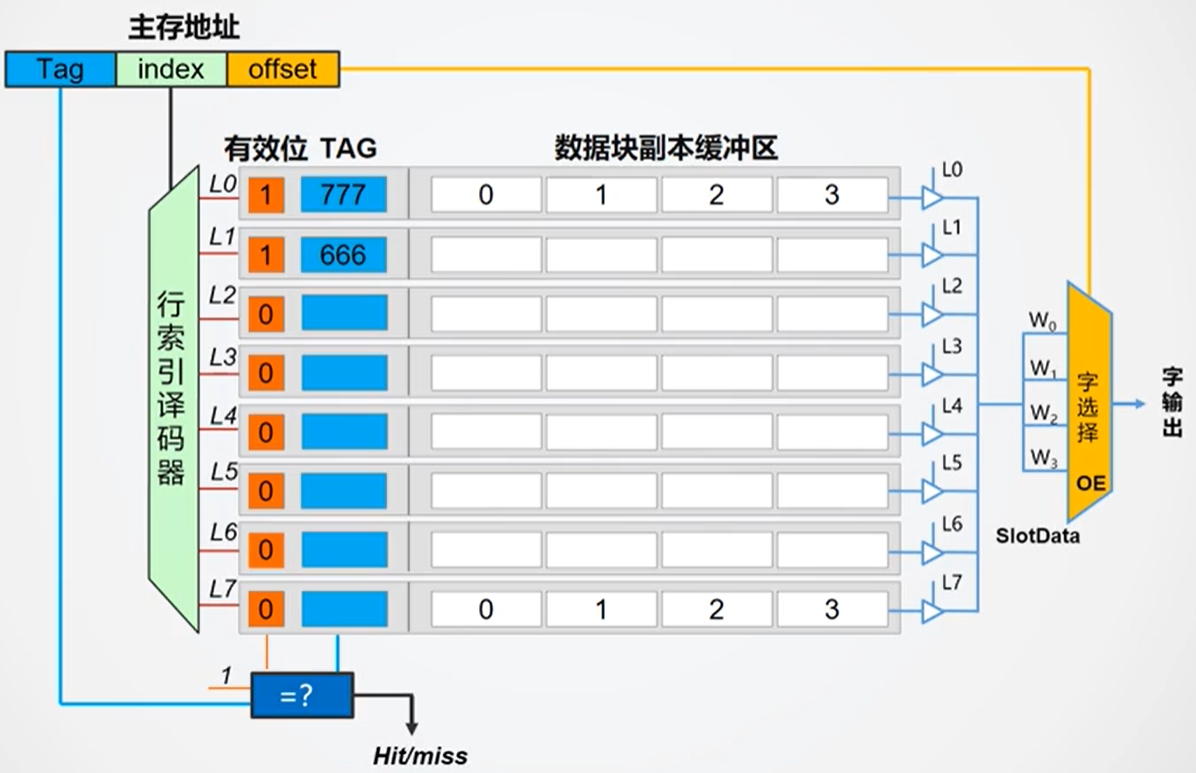
这种方法的命中率较低,因为主存中的块只能对应一个Cache块。一个块可能刚进入Cache,就被另一个块给覆盖了。
不过其优点是硬件逻辑简单,成本较低。如果硬要解决,可以增加多个TAG区即可。
全相联映射
全相联就是主存中的任意一块(行)可以放在Cache中的任意一块(行)中,没有分区的概念。于是贮存地址就只分为两部分:主存块地址(标记部分)、字地址。核心就是上一种方案提及的Hash算法,将Cache index均匀地落在set中。
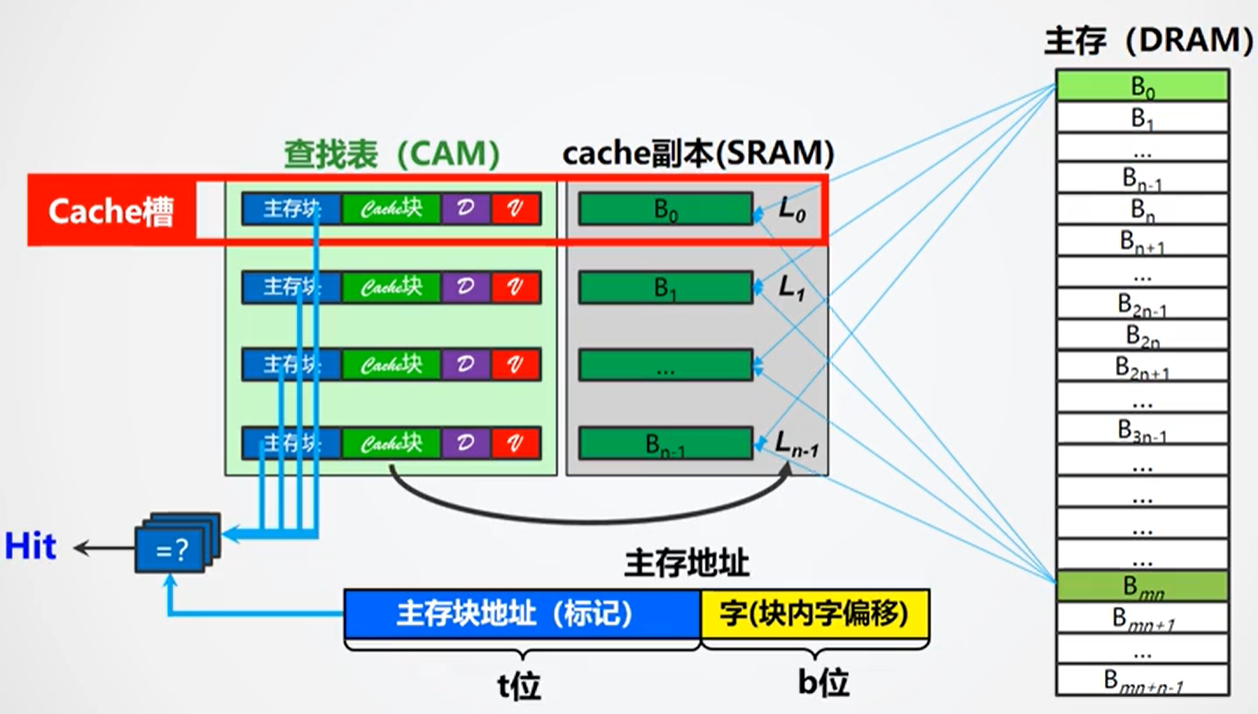
由于主存中一个块对应的Cache块地址不确定,所以需要其他的结构来辅助确定,即查找表。查找表的行数与Cache的行数相同,每一行存放着一个主存块地址,一个对应的Cache块地址,以及一些标志位。值得注意的是,查找表(CAM)与Cache是分开存放的,而直接相联中的区地址、标记位等与Cache数据则是一起存放的。
查找流程如下:
- 根据主存块地址在CAM中并行查找Cache中是否存在该块地址
- 若存在,则根据该行对应的Cache块地址直接访问Cache中的相应行,然后根据字地址选择输出的字
- 若不存在,则从RAM中载入相应地址的块到一个空的Cache行中,然后输出
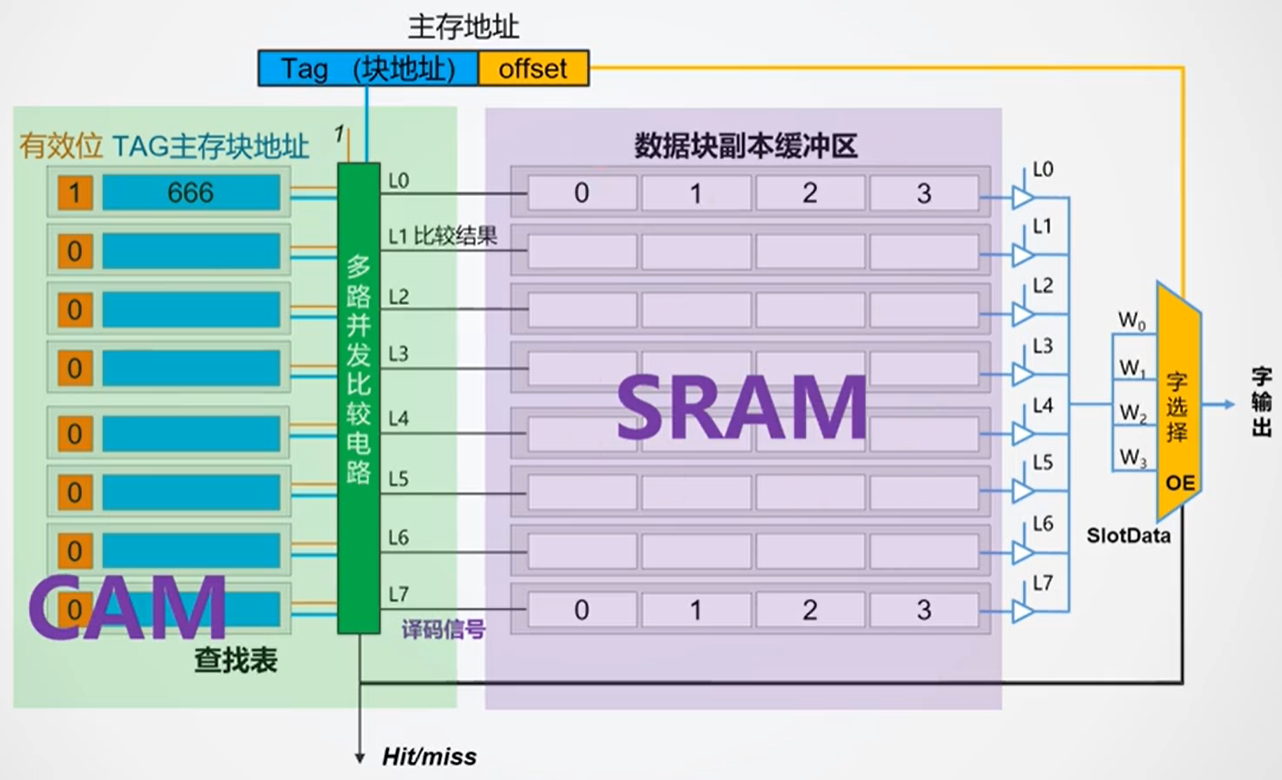
优点命中率会显著提高,缺点硬件开销大(Hash算法)
组相联映射
组相联映射结合了直接相联和全相联的特点,首先将Cache分为n组,一组中有k行。主存中也是按照每n行进行分割(类比直接相联的分区),每一行只能进入到相应的Cache组中,但是可以是组中的任意一行(类比全相联)。
每一组中的行数即路数,有k行则被称为k路组相联
于是主存的地址就被分为3个部分:标记字段(区地址)、组地址、字地址。
Cache中一行的组成与直接相联映射类似。
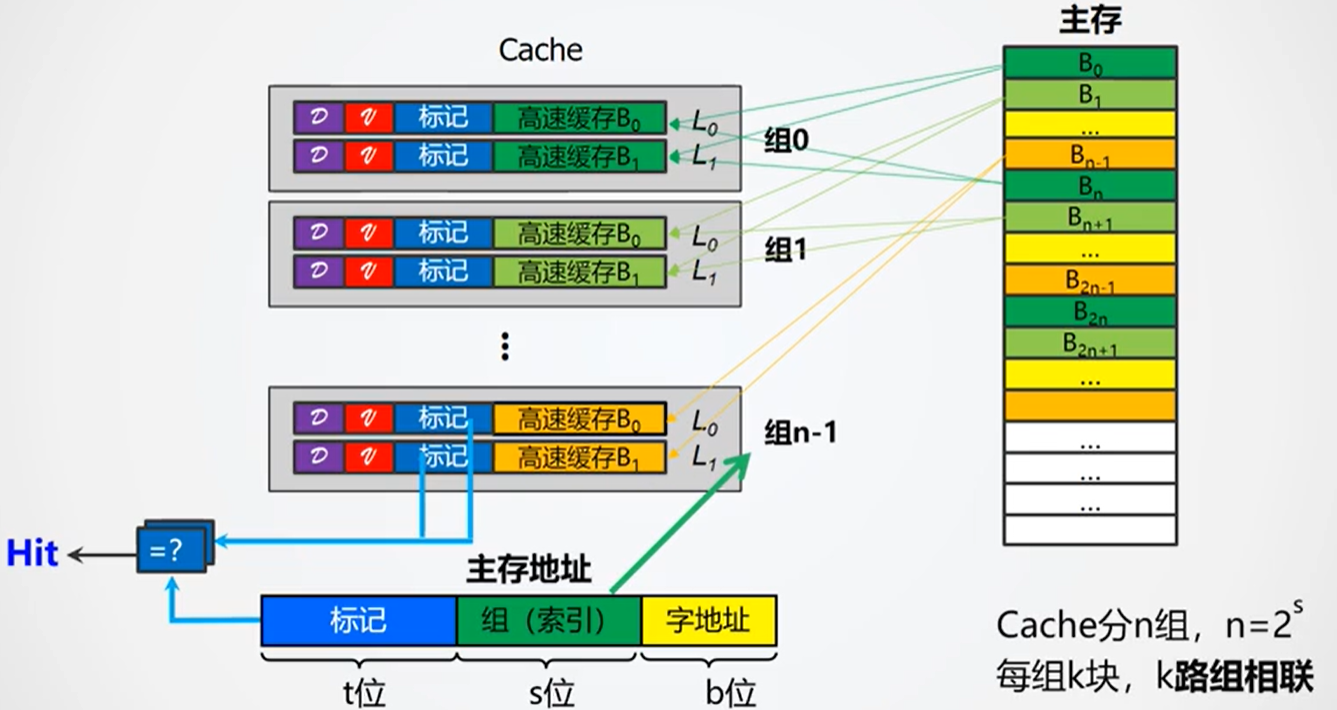
在组相联Cache中,内存地址被分为Tag、Index(组号)和Offset(块内偏移)三部分。常用的做法是直接用地址的中间若干位(Index)作为Cache组(set)的索引。这样设计的原因在于,CPU运行时具有很强的局部性,绝大多数访问集中在某一小段连续地址区间。如果直接用高位(如Tag)做set选择,会导致某些set过度拥挤、频繁替换,而有些set则长期空闲,造成cache资源利用率低下。虽然可以用更复杂的哈希算法来均衡分布,但会带来硬件复杂度的提升。因此,直接用Index作为set索引,是兼顾效率和均衡性的主流做法。
查找的流程如下:
- 首先根据组地址来确定所要查找的组,相应的组信号(S0-3)
- 根据标记字段TAG、有效位确定所要查找的行是否存在于该组中,并输出相应信号(K0、K1…)
- 根据(K0、K1…)以及组信号(S0-3)确定Cache中具体的某一行
- 根据字地址选择最终输出的字
- 若在第2步中,不存在所要查找的行,则从主存中载入,然后再进行步骤3
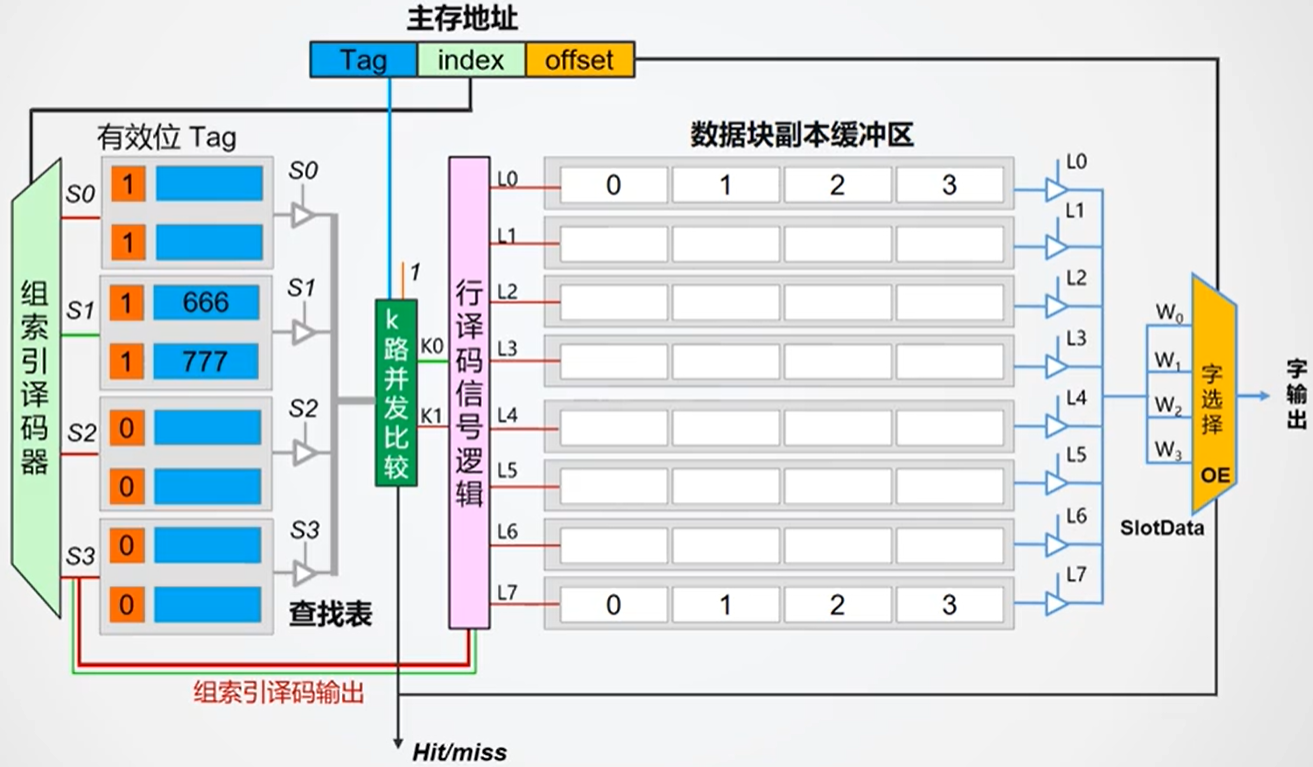
由组相联的映射机制可知,它结合了直接相联和全相联的特点,是一个比较折中的方案,命中率相比直接相联要高,但是硬件成本也要高一些,相比全相联,其硬件成本较低,但是命中率也要低一些。
他们三个关系,直接映射Cache是组相联Cache的一种特例,即每组只有1路。
全相联Cache就是组数为1,路数等于总行数的组相联Cache。
直接映射cache不需要LRU算法,因为相当于1路cache,只要命中了,有就读取,没有就只能重新cache,没有选择。
LRU设计思路
在cache的设计中,cache的容量是有限的,在cache满了以后需要决定哪些cache条目属于不太常用,删除旧的添加新的。在FPGA领域有两种主要的LRU算法,LRU与PLRU
矩阵法LRU
LRU矩阵是一个4×4的二值矩阵,M[i][j]=1表示“i比j更新”,M[i][j]=0表示“i比j更旧”。

在每行中,如果标注为1,代表着,这行的元素比对应列的元素更新。如果标注为0,代表这行元素比对应列的元素更旧。只需要找到全为0或者0的数量比较多,就可以找到最不常访问的元素。
根据上面这句话,我们可以推断,在访问到每一元素时候,把对应行置为1。该元素对应的行都设置为0即可。
在实际中,我们可以发现这是一个以对角线的对称矩阵。所以可以只存储一半的元素,同样可以完成任务。
在访问到每一个元素的时候,同样还是,在本行设置为1,在本列设置为0即可。
缺点,需要n^2/2个存储单元,可能空间不太够
PLRU
PLRU被称为伪LRU,在FPGA中很常见。节省资源但是效果不好

tree-PLRU遵循的是”访问1左0右“的原则,也就是说如果该bit位为1的话,说明最近访问的是左边的区块,反之最近访问的是右边的区块。
在找到叶子节点后,根据上面的原则调整路径上节点的值。
PLRU通过从根节点按bit指示(0左1右)一路走到叶子,找到要替换的way,并在访问后把路径上的bit都指向没被访问的那一边。
PLRU有时会误把刚用过的cache行当成“最久没用”的行替换掉,因为它只能粗略区分哪一半没用,分不清具体顺序。很容易误判。
缓存刷新策略
根据内存控制器原理,一次读写的最小单位是8字节,64位。在写入内存中,我们难道要先读一行,再把待写入内容写到行中,然后再写回内存吗?这样会增加很多无畏的开销。
在L1 cache中,可以将写入内容先写到缓存行中,标记该行为dirty。那什么时候刷新L1 cache到内存中呢,在这里介绍两种最基本的缓存写回策略。
Write-back(回写)策略
- 只有在cache行被替换(evict)时, 例如该行缓存淘汰,需要更换新的内容。才会检查Dirty位,如果Dirty=1,就把数据写回内存。
- 优点:减少对内存的写入次数,提高性能。
Write-through(直写)策略
- 每次写cache时,也同步写到内存,Dirty位无意义。
- 优点:内存和cache随时保持一致,但带宽占用大。
强制刷新/定期刷新?
- 一般不会定期全部刷新,除非有“flush”指令(如某些同步场景、关机、休眠等)。
- 有些系统会在某些事件触发时(如DMA、上下文切换、I/O同步)强制flush cache,但这不是“定期”,而是“有需要时”。相关指令在Risc-v的缓存一致性,原子操作扩展中。我们的基本risc-v指令集暂时不需要。
设计结论
我们面临的问题 AMD L1 cache等也会遇到,但是我们的FPGA芯片有限,只能选择直接cache,并且不附带LRU算法,待全部设计完成后,根据LUT剩余数量,选择是否补充LRU算法。
实现细节
CPU与L1cache之间遵守严格的时序请求。不允许上一次请求未完成就发起下一次请求的情况,否则很容易出现数据丢失的情况。
完整流程图如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号