
一个完整的大作业
1.选一个自己感兴趣的主题。
2.网络上爬取相关的数据。
3.进行文本分析,生成词云。
4.对文本分析结果解释说明。
5.写一篇完整的博客,附上源代码、数据爬取及分析结果,形成一个可展示的成果。
首先,本人本次选择要爬取的网站是http://www.gd.chinanews.com/index/gdsz.html--广东新闻网中的数据以及做本网站上标题的词频统计,形成的效果图可做初步的了解广东新闻网标题中大多数出现的用词。
第一步:我们把一条新闻的详情从新闻列表中拿出来,根据对详情新闻源代码的检查观察可以得到一条详细新闻的数据,代码如下:
def detail(url): r=requests.get(url) r.encoding='gb2312' s=BeautifulSoup(r.text,'html.parser') n={} n['t']=s.select('h2')[0].text#标题 n['u']=url#链接 return(n) #print(detail('http://www.gd.chinanews.com/2017/2017-10-30/2/389835.shtml'))#详细一条新闻主页的标题和链接
效果图如图所示:
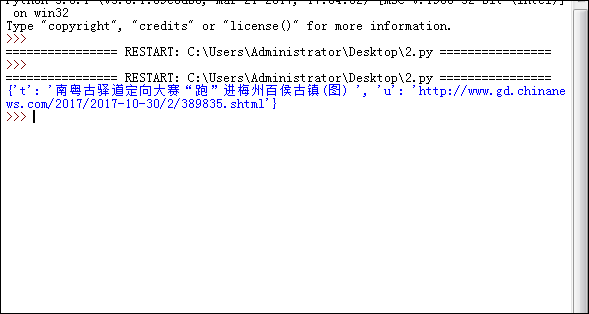
第二步,要获取广东新闻网中的所有新闻的详情内容,我们必须要获得所有新闻,由以下代码实现:
def page(p): re=requests.get(p) re.encoding='gb2312' soup=BeautifulSoup(re.text,'html.parser') newsls=[] for i in soup.select('li > .dd_bt'): if len(i.select('a')) > 0: newsls.append(detail('http://www.gd.chinanews.com'+i.select('a')[0]['href'])) return(newsls) #print(page('http://www.gd.chinanews.com/index/gdsz.html')) newstotal=[] newsurl='http://www.gd.chinanews.com/index/gdsz.html' newstotal.extend(page(newsurl))#所有新闻 #print(newstotal)
实现效果如图所示:

第三步,我们可以将所有的新闻形成表格或者数据的形式保存下来,以便我们可以更好的使用,代码如下:
df=pandas.DataFrame(newstotal) df.to_excel('new.xlsx') with sqlite3.connect('new.sqlite') as db: df.to_sql('new',con=db)
效果如图:
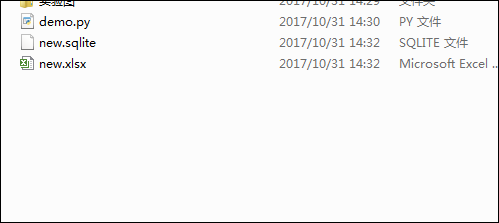
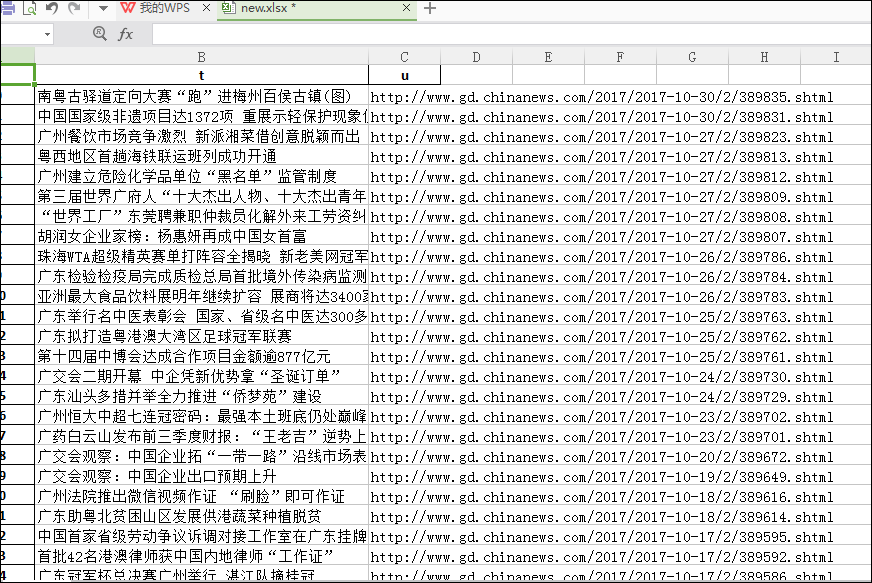
第四步,在所有新闻的详情以字典在列表中生成之后,我们要做的是提取列表中的每一个字典中的某个数据,这里提取的是标题。代码如下:
for i in range(10): if i>0: if i>0: t=t+newstotal[i].get('t') else: t=newstotal[i].get('t')#返回10条标题形成的文本 for i in ',。:?!“”() ': t=t.replace(i,'') title=list(jieba.cut(t)) #print(title)
实现的效果如图所示:
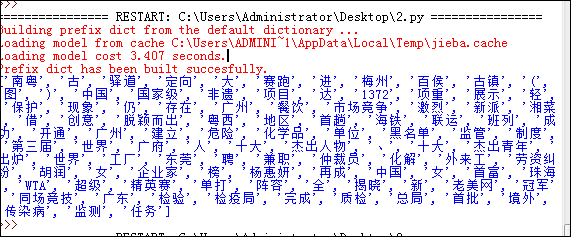
最后,我们将分词做词频统计,做成词云输出结果,代码如下:
k={} keys=set(title) for i in keys: k[i]=title.count(i) wc=list(k.items()) wc.sort(key=lambda x:x[1],reverse=True)#字典返回列表并排序 mywc=WordCloud().generate_from_frequencies(k) plt.imshow(mywc) plt.show()
效果图如图所示:
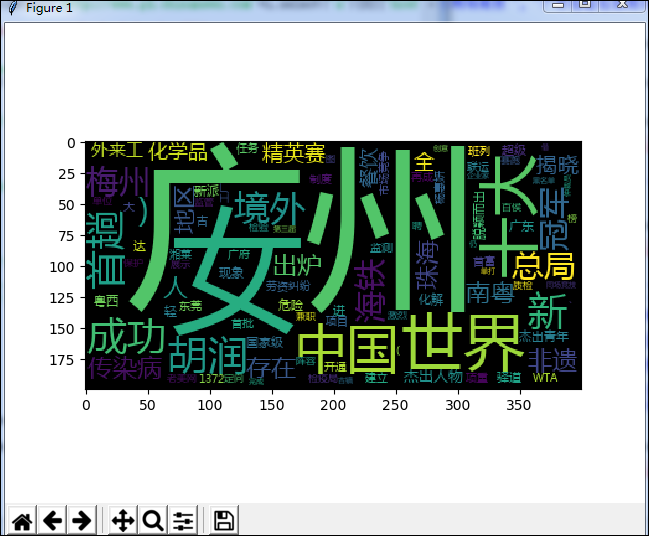
这就是整个广东新闻网中时政部分所有标题所做的词频分析,可以看出广州,中国,世界等词在时政标题中出现的频率较高,由此便可知道人们都在关注些什么。
完整的代码如下所示:
import requests from bs4 import BeautifulSoup import pandas import sqlite3 import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt def detail(url): r=requests.get(url) r.encoding='gb2312' s=BeautifulSoup(r.text,'html.parser') n={} n['t']=s.select('h2')[0].text#标题 n['u']=url#链接 return(n) #print(detail('http://www.gd.chinanews.com/2017/2017-10-30/2/389835.shtml'))#详细一条新闻主页的标题和链接 def page(p): re=requests.get(p) re.encoding='gb2312' soup=BeautifulSoup(re.text,'html.parser') newsls=[] for i in soup.select('li > .dd_bt'): if len(i.select('a')) > 0: newsls.append(detail('http://www.gd.chinanews.com'+i.select('a')[0]['href'])) return(newsls) #print(page('http://www.gd.chinanews.com/index/gdsz.html')) newstotal=[] newsurl='http://www.gd.chinanews.com/index/gdsz.html' newstotal.extend(page(newsurl))#所有新闻 #print(newstotal) ''' df=pandas.DataFrame(newstotal) #print(df.head()) #print(df['t']) df.to_excel('new.xlsx') with sqlite3.connect('new.sqlite') as db: df.to_sql('new',con=db) ''' for i in range(10): if i>0: if i>0: t=t+newstotal[i].get('t') else: t=newstotal[i].get('t')#返回10条标题形成的文本 for i in ',。:?!“”() ': t=t.replace(i,'') title=list(jieba.cut(t)) #print(title) k={} keys=set(title) for i in keys: k[i]=title.count(i) wc=list(k.items()) wc.sort(key=lambda x:x[1],reverse=True)#字典返回列表并排序 mywc=WordCloud().generate_from_frequencies(k) plt.imshow(mywc) plt.show()
