

sd7
1、vlogger
与video Drafter 大致思路一样,不同点在于:考虑了较长时间的单个场景的生成,先根据主体图片(通过image cross attn)+文本以inpainting的方式生成clip,然后根据上一个clip的最后几帧以inpainting的方式生成下一个clip直到完成单个场景的生成。模型方面就是在MoonShot的时间自注意力层后面新增时间较差注意力层来接受文本输入。训练也是inpainting的方式,选择k帧预测inpainting剩下的帧
2、hyperdreambooth
更快微调,更小的 db
分为两个阶段,第一阶段先固定sd在 CelebAHQ 上来训练一个通用的人脸提取器Hypernetwork(adapter),第二个阶段(Fast Fine-Tuning)为了提取更细粒度的人脸细节,采用 lora 方法微调,但是rank > 1(Rank-Relaxed Fast Finetuning)。
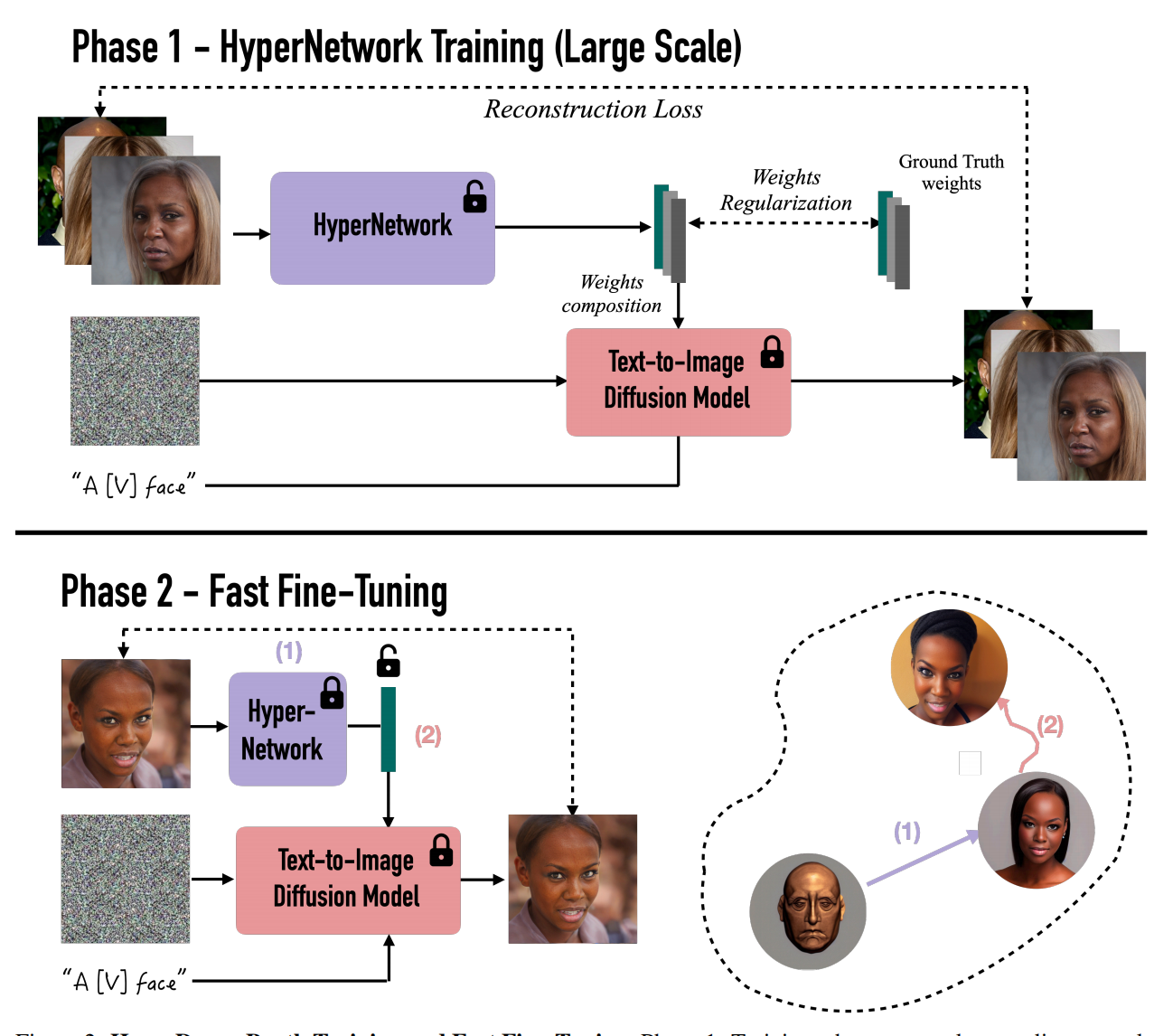
第一阶段中,Hypernetwork 输出的是要注入给 sd Unet ,text encoder 每一层的cross 和 self attn 的 delta 权重,只不过这里的delta权重(LiDB权重)是对lora的二次分解,aux固定不变,这样权重文件就更小了:
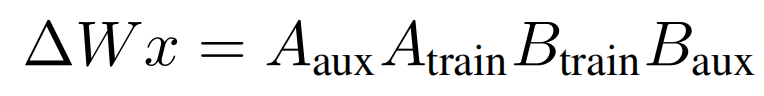
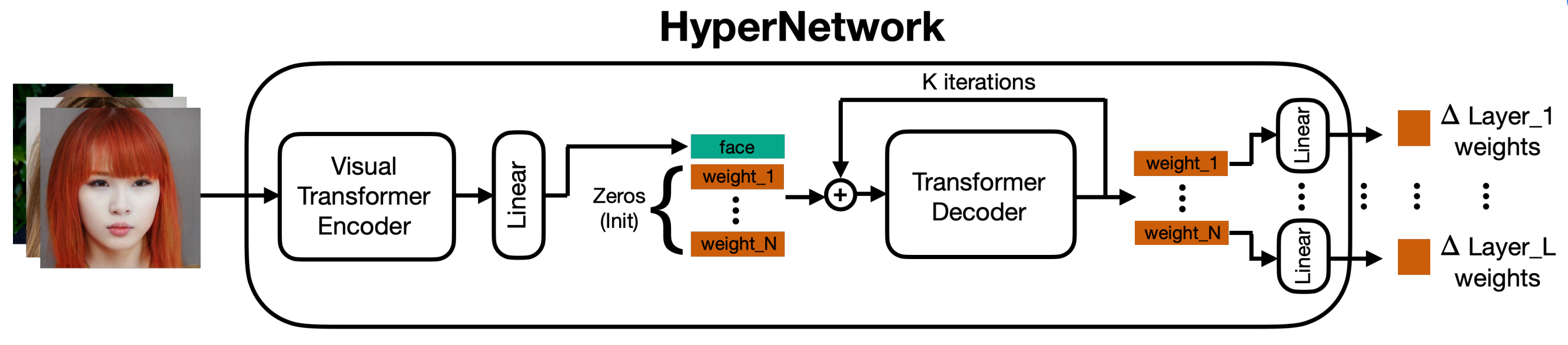
Hypernetwork 网络结构由 Encoder 和 Transformer Decoder 组成,用 Decoder 是由于多层的权重之间存在依赖关系, Decoder 多次迭代效果更好:
第一阶段的损失函数中,D是sd,x是图片,c是条件,epsilon是噪声,theta~是 Hypernetwork 的输出权重(要训练的) 结合 sd原来的权重 theta(固定的),第二项是正则化项:
![]()
3、PASD
图像高清复原,图像风格化
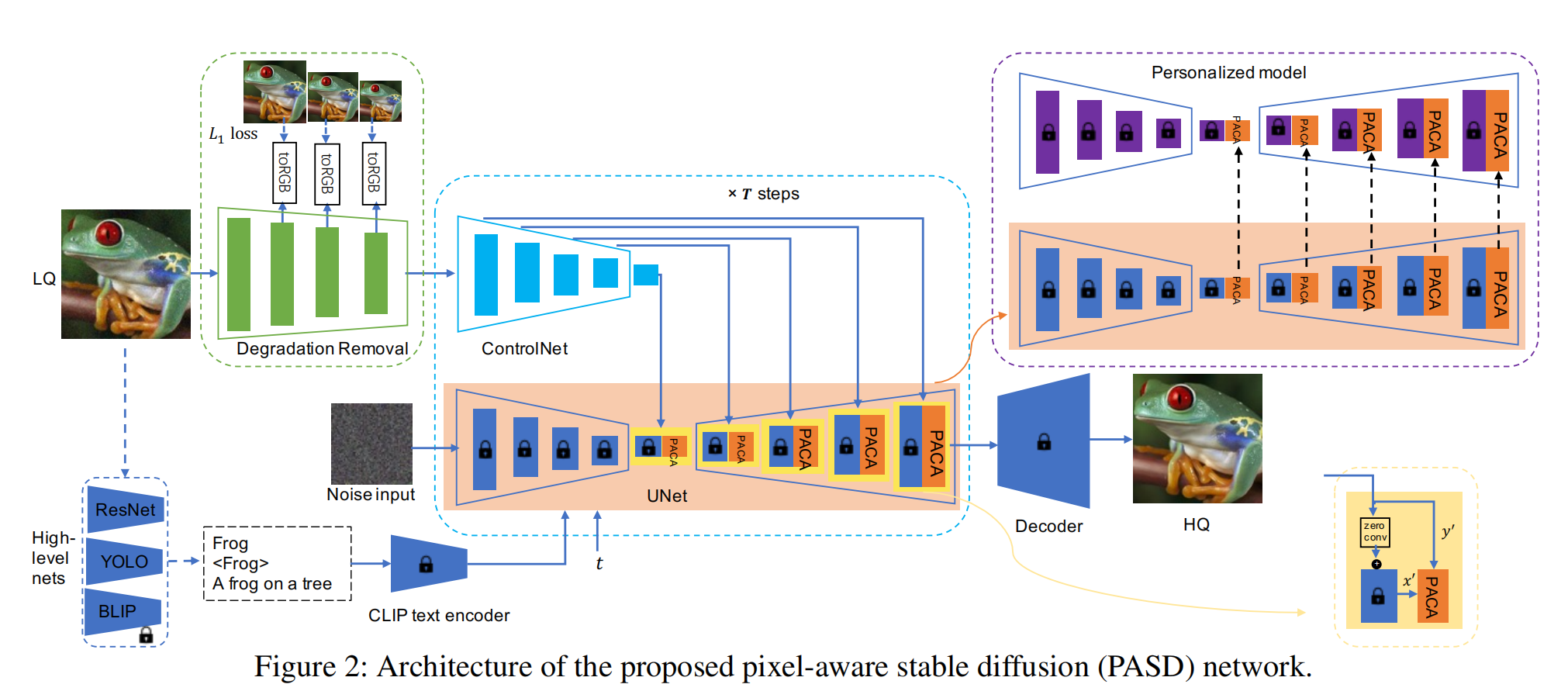
LQ图片先通过Degradation Removal 提取主要的各个分辨率下的特征,每个分辨率的特征通过 toRGB 卷积层 分别与 各个分辨率下的 LQ 图片做 L1 loss,这是为了确保主要特征是提取对的。随后注入 Controlnet (感觉此处的 Controlnet 可以代替 Degradation Removal 模块,因为controlnet 已经得到了各个分辨率下的特征了),Controlnet 注入方式不再是直接相加而是多了一个分支(右下角的PACA)做注意力,其中 y' 做K,V,只是为了更好的提取到图像的细节信息,此处的注意力替换了文本注意力。另外 LQ 通过 resnet(分类),yolo(物体检测),BLIP(提取 caption )通过原先的 text encoder 注入 Unet,训练的时候只训练 Degradation Removal 、controlnet、PACA。如果要完成 图像风格化 ,则把lora 注入到不变的 sd 权重当中。缺点是完成不了图像编辑,背景更换。
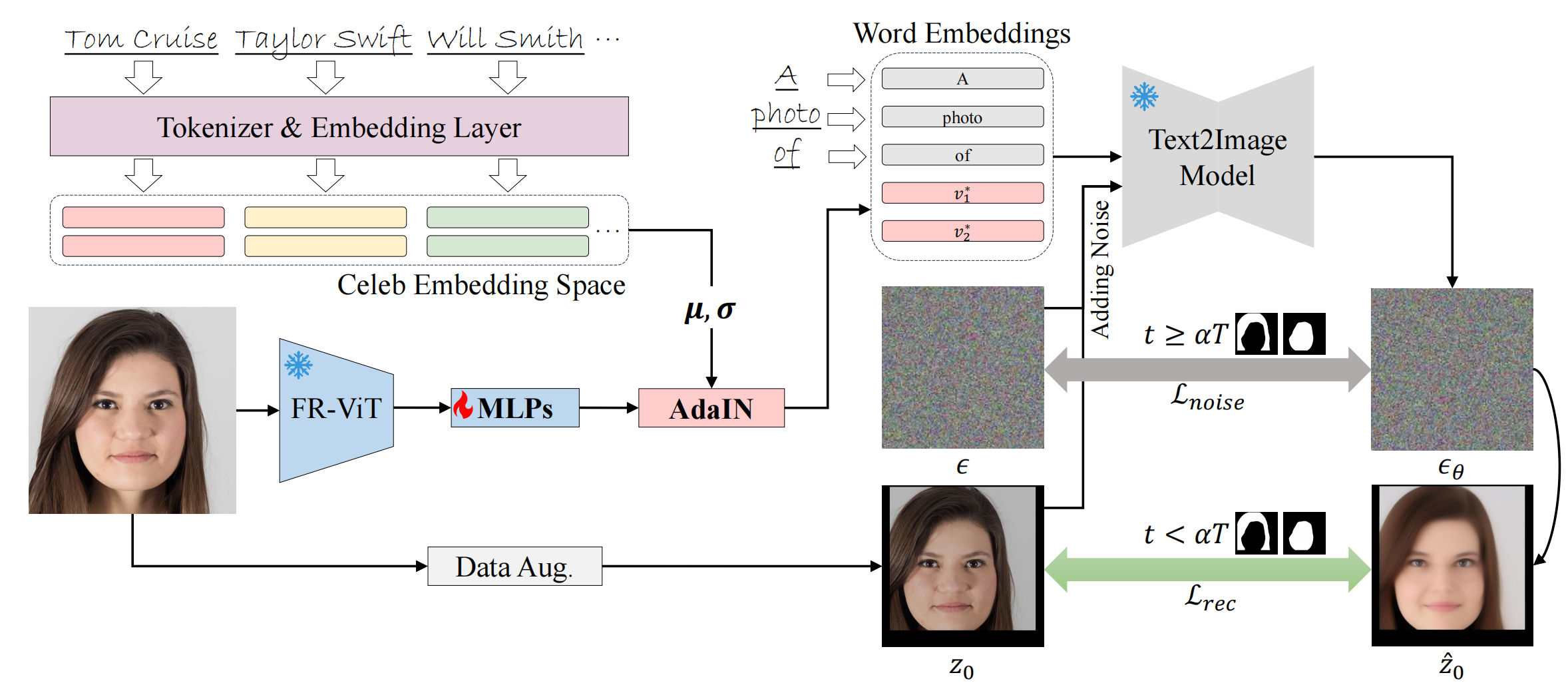
4、StableIdentity
db的作用,也需要微调:把长相视为2个名字向量,比如 a photo of taylor swift ,预训练好的sd是知道taylor的长相的,因此在微调时,需要把人类微调到2个名字的向量空间,MLP输出2个向量,再经过AdaIN 做偏移和放缩(使得初始化能离名字向量很近),得到最终的名字向量。AdaIN:
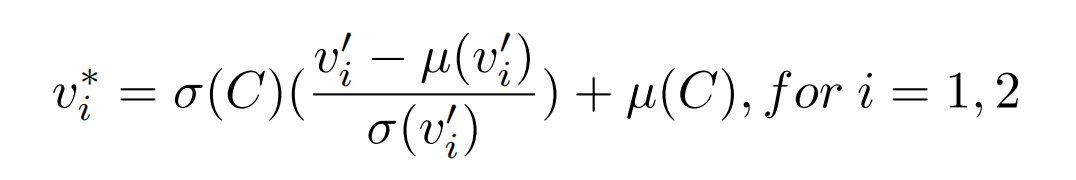
模型图:
技巧:在原始sd损失上加入重建损失以更好的学到人脸特征,t比较小的时候才用:
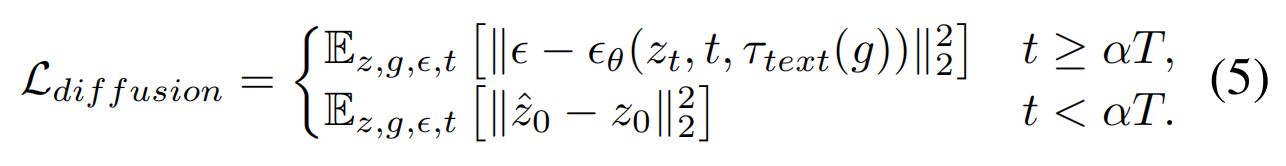
引入人脸 mf 和头发 mh 来让模型更专注于人脸损失:
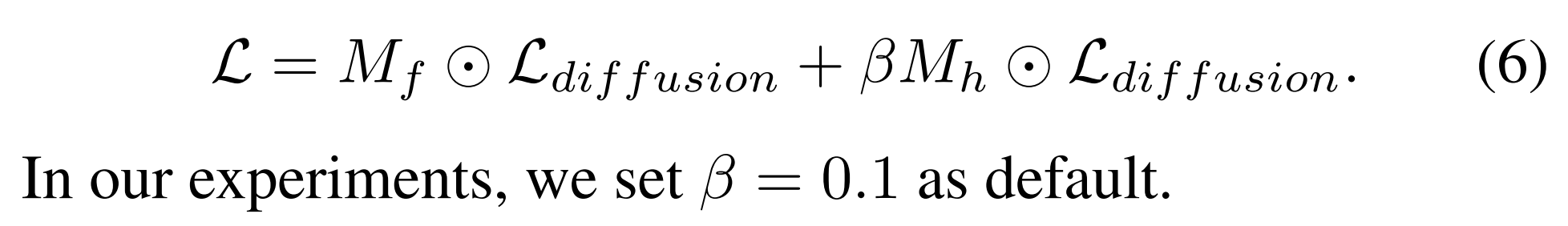
5、instantID
ipa的功能,图+文=》图
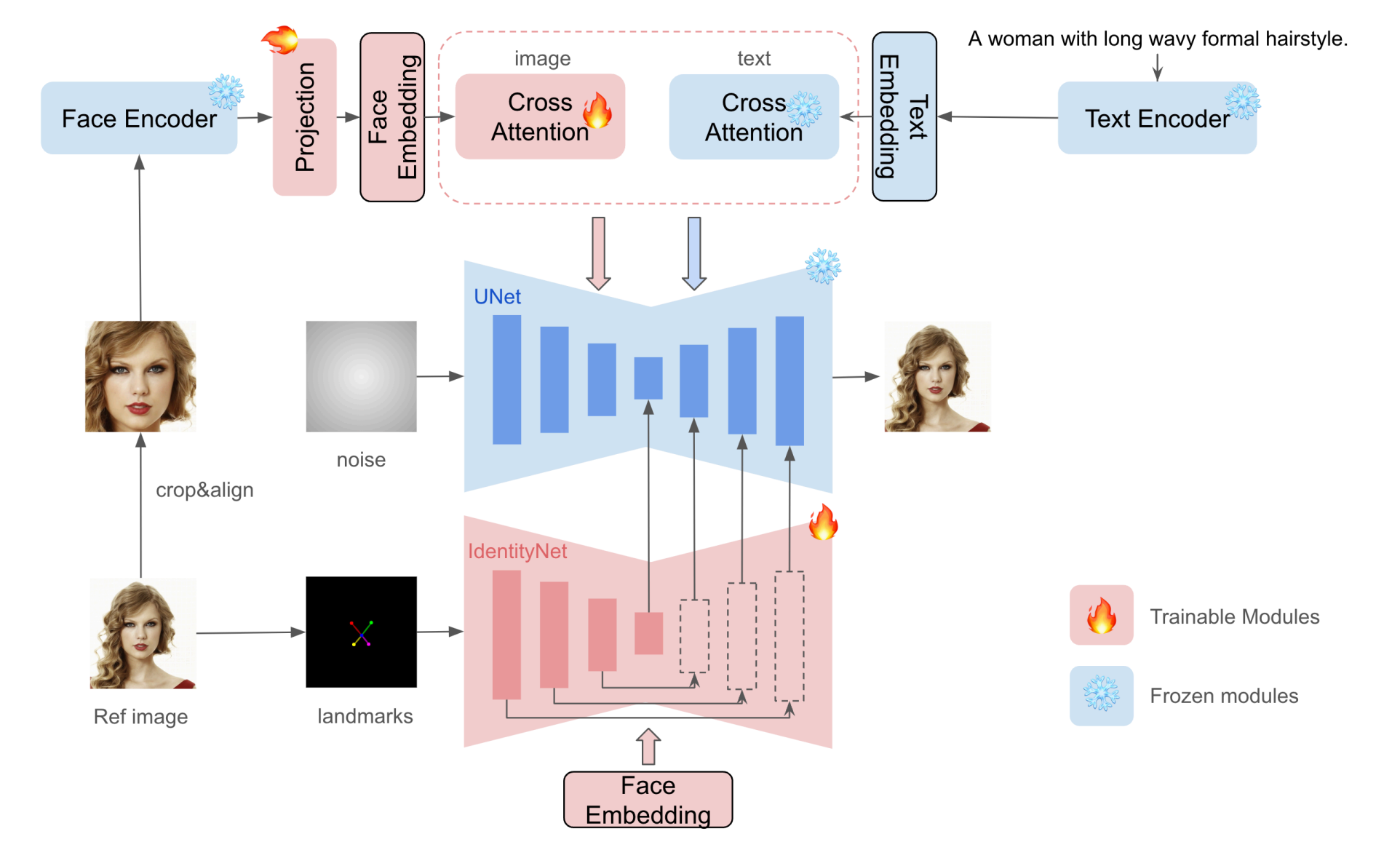
ipa由于文本和图片prompt放到一起导致文本可控性差,因此在ipa的基础上多了controlnet结构传入人脸细粒度信息,其中文本注意力替换为 face emb 注意力。
如果要和 controlnet 结合来控制身体姿态,则把姿态 controlnet 产生的中间结果加到 Identity 对应的分辨率特征图上,其中为了提高生成的脸部的相似性, Identity 各个分辨率上的特征乘以对应分辨率的 mask 只保留生成的脸部的特征,其他区域设置为0,这个mask 是参考图片的人脸区域长方形 mask,进入 Identity 的 landmark 是 参考图(下图中间)的人脸 keypoint,face emb 是用户人脸emb(下图左边),姿态 controlnet 就不用face emb 了而是还用文本emb来做注意力。见下效果:
6、MultiDiffusion
将多个扩散模型的采样做个协调,使得生成任意大小的图片,图片各处都能无缝衔接。
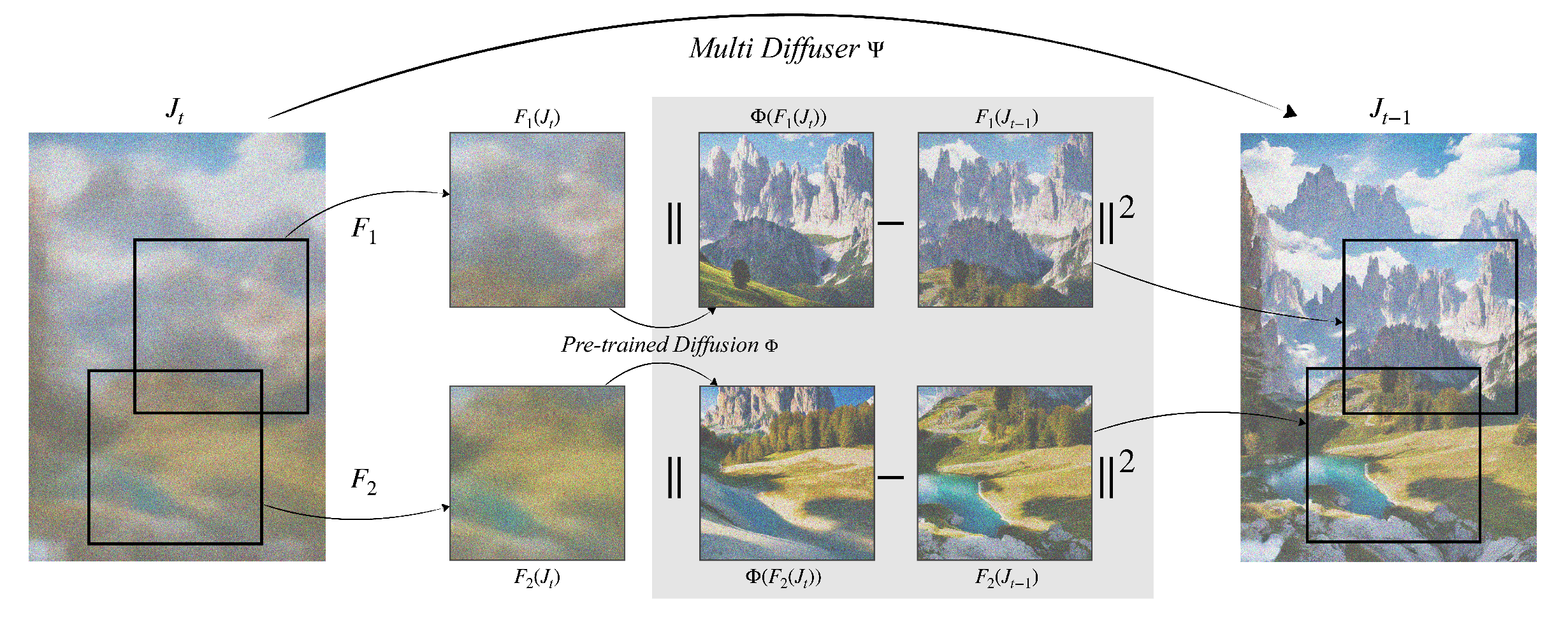
在 t 到 t-1 的采样过程中,Fi代表不同的crop,每个crop独立进行采样,然后对采样的结果分别乘以自己crop像素所占整体的比例作为权重(原理:所有crop经过预训练好的sd算最小二乘,解为:像素的比例作为权重)。这样多个crop之间的界限就模糊了。
7、caphuman
tuning-free 图+文+头部姿态 =》 图
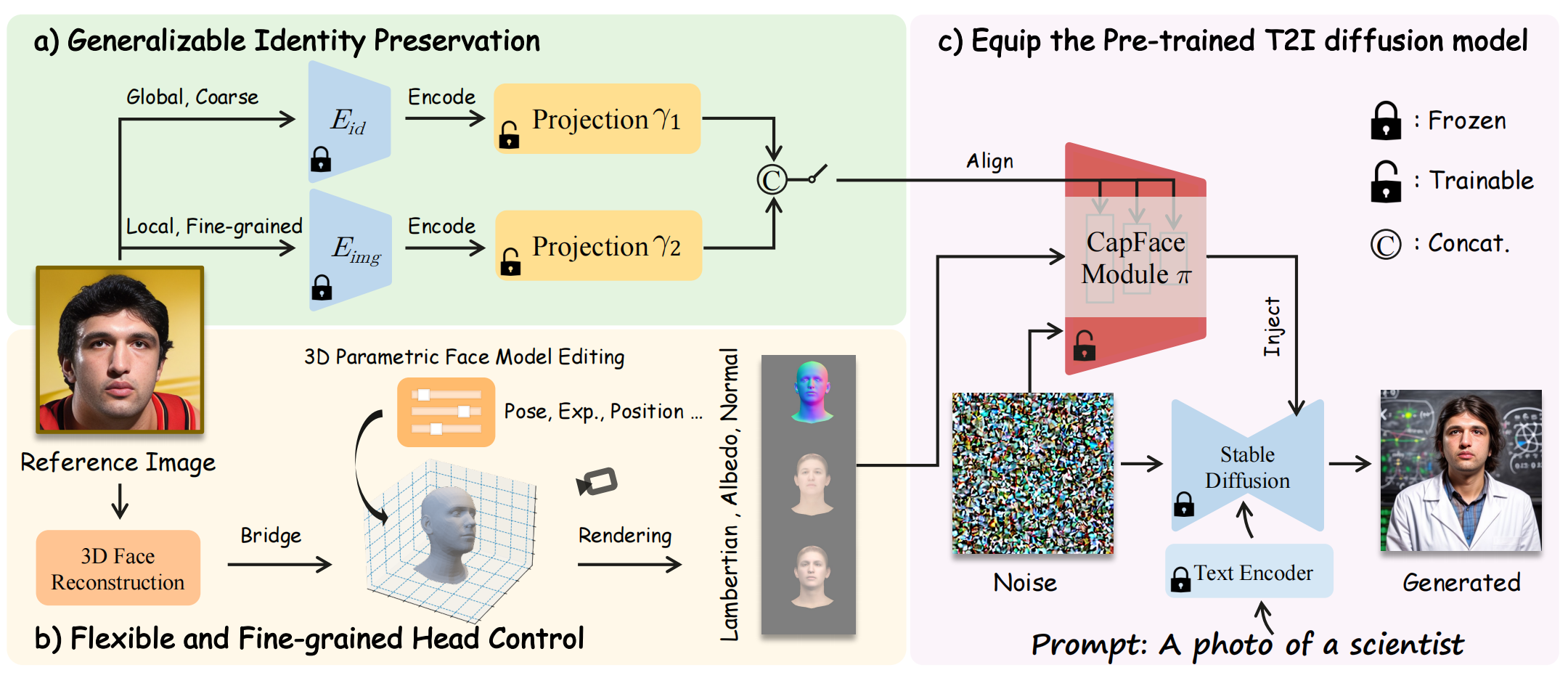
绿色框提取人脸的粗粒度和细粒度特征并融合(Eid pre-trained on the face recognition task,Eimg:CLIP image encoder),再通过注意力机制进入 capFace module(trick而已),左下角先做3D人脸重建,然后通过 FLAME 进行头部姿态\表情\位置编辑,只训练2个projection 权重 + CapFace module
8、lumiere
视频生成:先用STUNet生成低分辨率的视频,再用SSR实现超分,此处超分的范围是有交集的,这是为了应用 multidiffusion 来协调多个小clip的内容平滑。
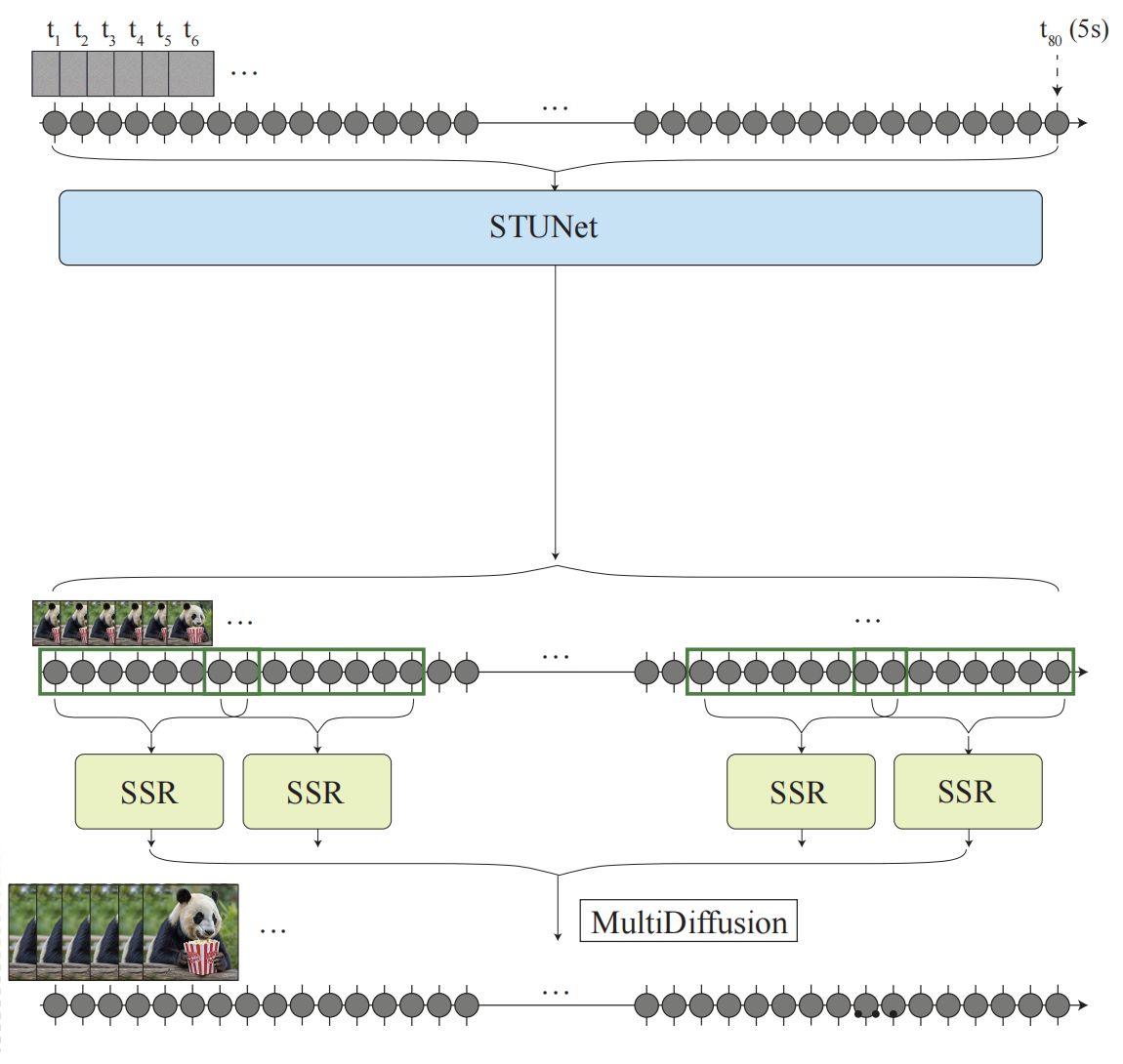
STUNET:扩展了预训练好的unet,蓝色扩展了 factorized space-time convolution:在pretrained spatial layers 后面新增了一些层。黄色扩展了 temporal attention,这种机制造成的计算成本主要由帧的个数决定,所以只在小 T 上执行,蓝色层 后面加入空间时间上下采样层,训练时只训练新增的参数。

为了完成 image+text=》video,输入新增 masked conditioning video 、 mask,它俩和 noisy latent 三者拼接,来训练 inpainting 任务。
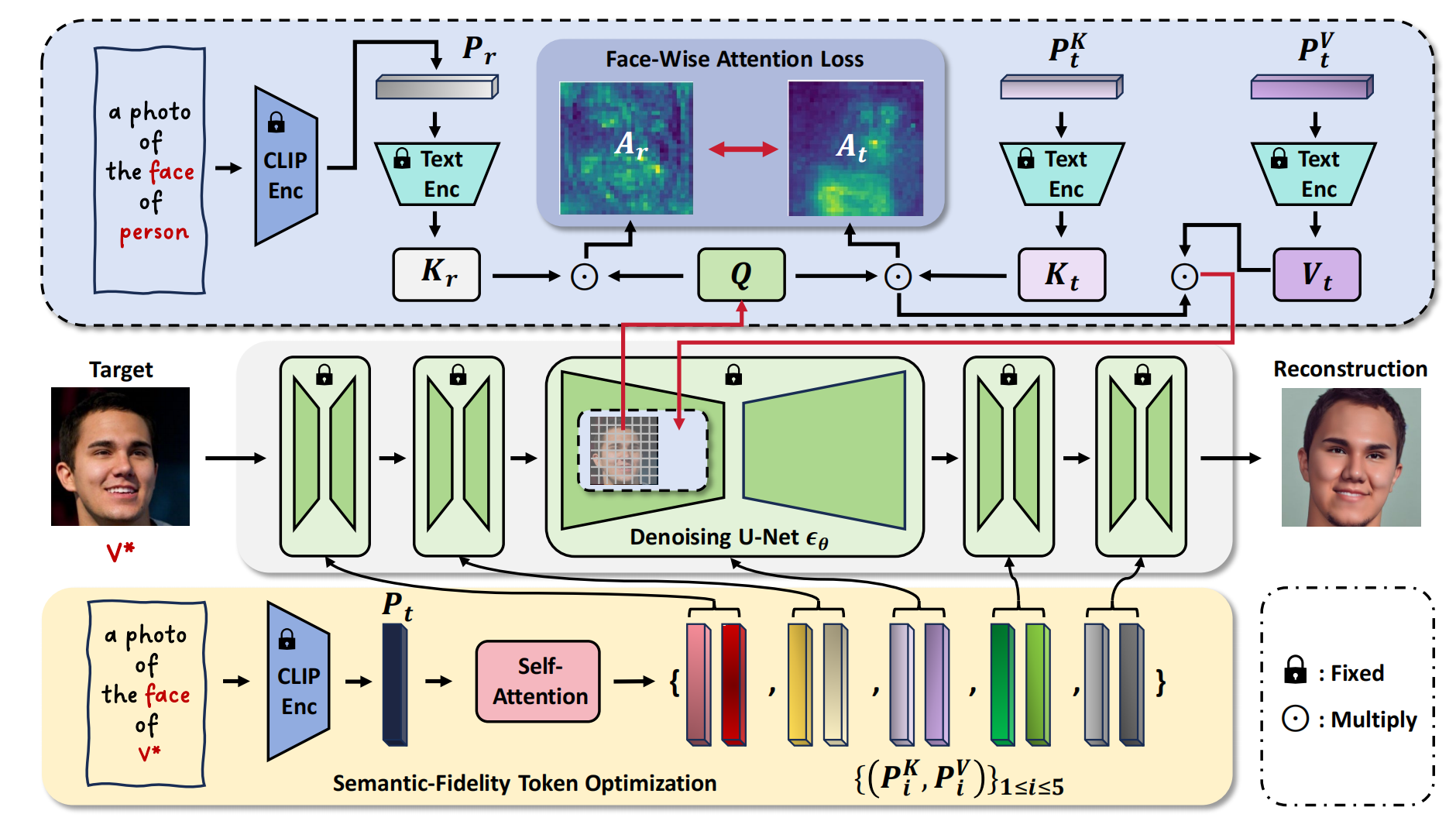
9、 SeFi-IDE
SeFi-IDE 采用 db 训练模式,我觉得主要创新点就是用 P1:a photo of the face of person 做正则化(计算 p1 和 latent feature 的cross attn map,p2:a photo of the face of V* 和 latent feature 的cross attn map,两个map算 MSE loss ),从而避免过拟合。至于把 p2 分为 5个阶段,我觉得没有什么必要。
10、wav2lip
根据音频控制嘴形
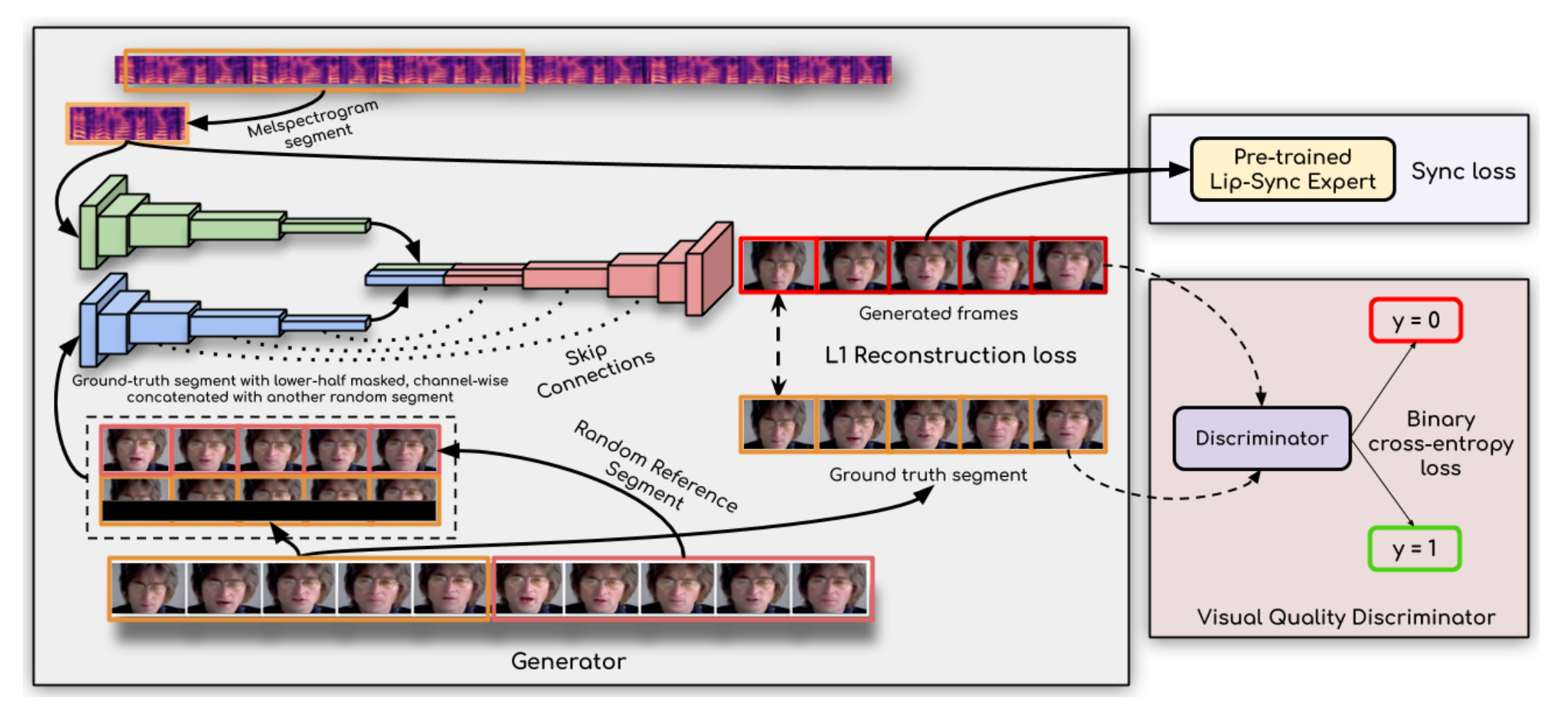
首先训练一个 expert lip-sync discriminator 用于分别当前的音频和说话是不是一直的,网络结构是 SyncNet 的改进版,利用正负样本训练,正样本是一段5帧连续的视频(下半部分,即嘴巴)和对应的音频,负样本是把音频随机移动一下,音频和视频分别通过神经网络得到对应的特征向量,然后计算类似于 Siamese networks 的损失函数,其中负样本大于m距离的就自然不考虑了(实际代码就算了个相似度损失):

然后固定 expert lip-sync discriminator ,再训练 生成器。gt取一段然后遮住下半脸,再选一段视频作为一个参考,结合对应的音频一起输入到 Generator ,生成的视频和GT视频做像素级别的重建损失以还原大致口形,还有音频同步损失,还有 visual quality Discriminator(disc) ,disc 只输入帧,用于判断当前帧是不是GT帧,以降低 atifact,二阶段gen 和 disc 一起训练。
11、DreamTalk
一张人图片(portrait)+ 一段音频 + 参考说话风格(表情)的视频(可选)=》该人按照该音频的说话的视频
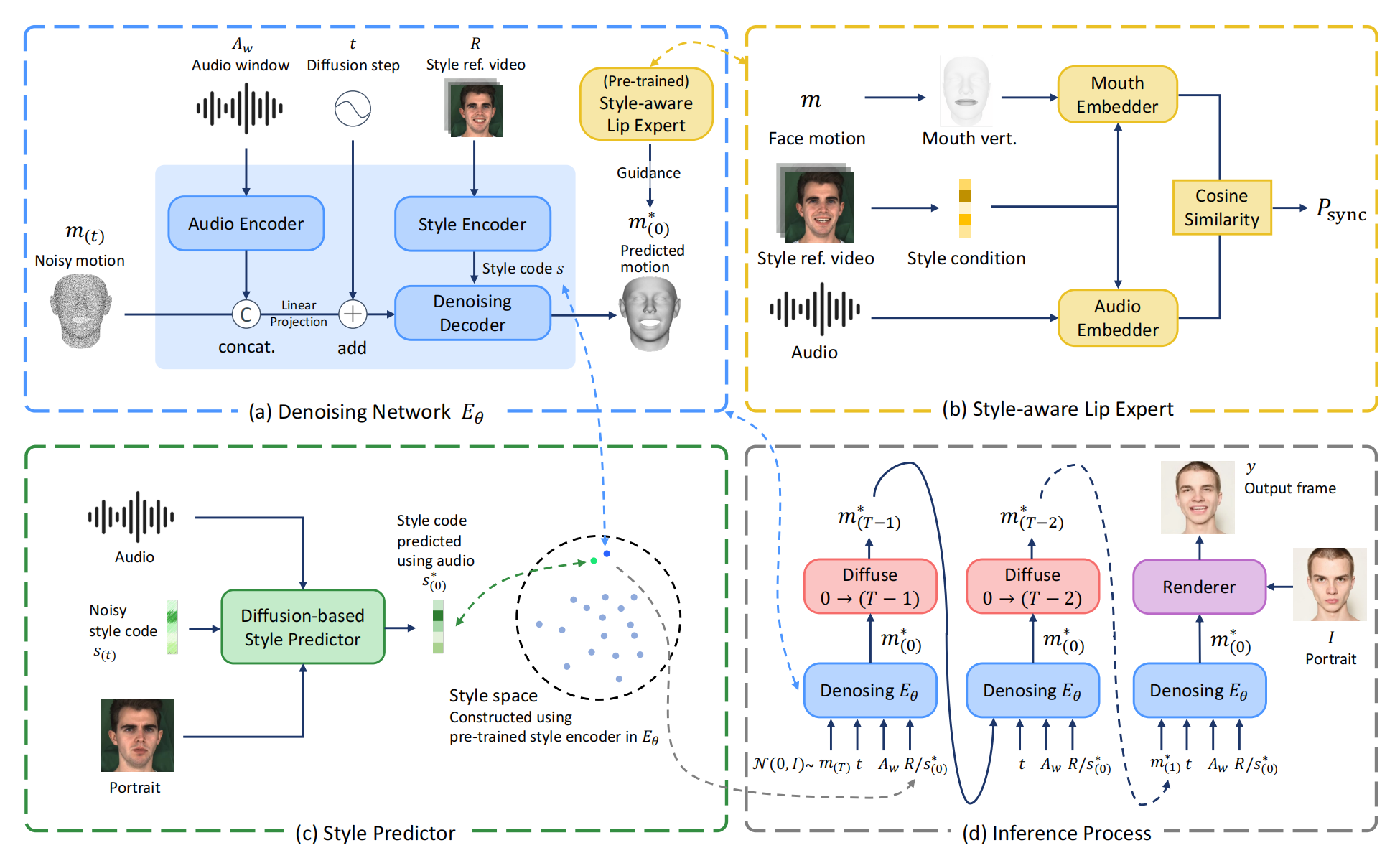
首先训练一个 Style-aware Lip Expert 实现 lip-sync 评估并在第二个阶段固定:通过 face motion -> face mesh -> 选取嘴部区域的顶点 来获取 lip motion,Embedder 结构是 mlp + 1D 卷积,参考的风格视频通过 style encoder 后分别与两边拼接,通过 lip motion 和 Audio 的相似性来做损失
第二个阶段训练扩散模型,采样建模的是多个小窗口(小音频)对应的 face motion (比如414 个 face motion),最后通过预训练好的 Render( PIRenderer) 渲染成真实说话视频。渲染的方式是:
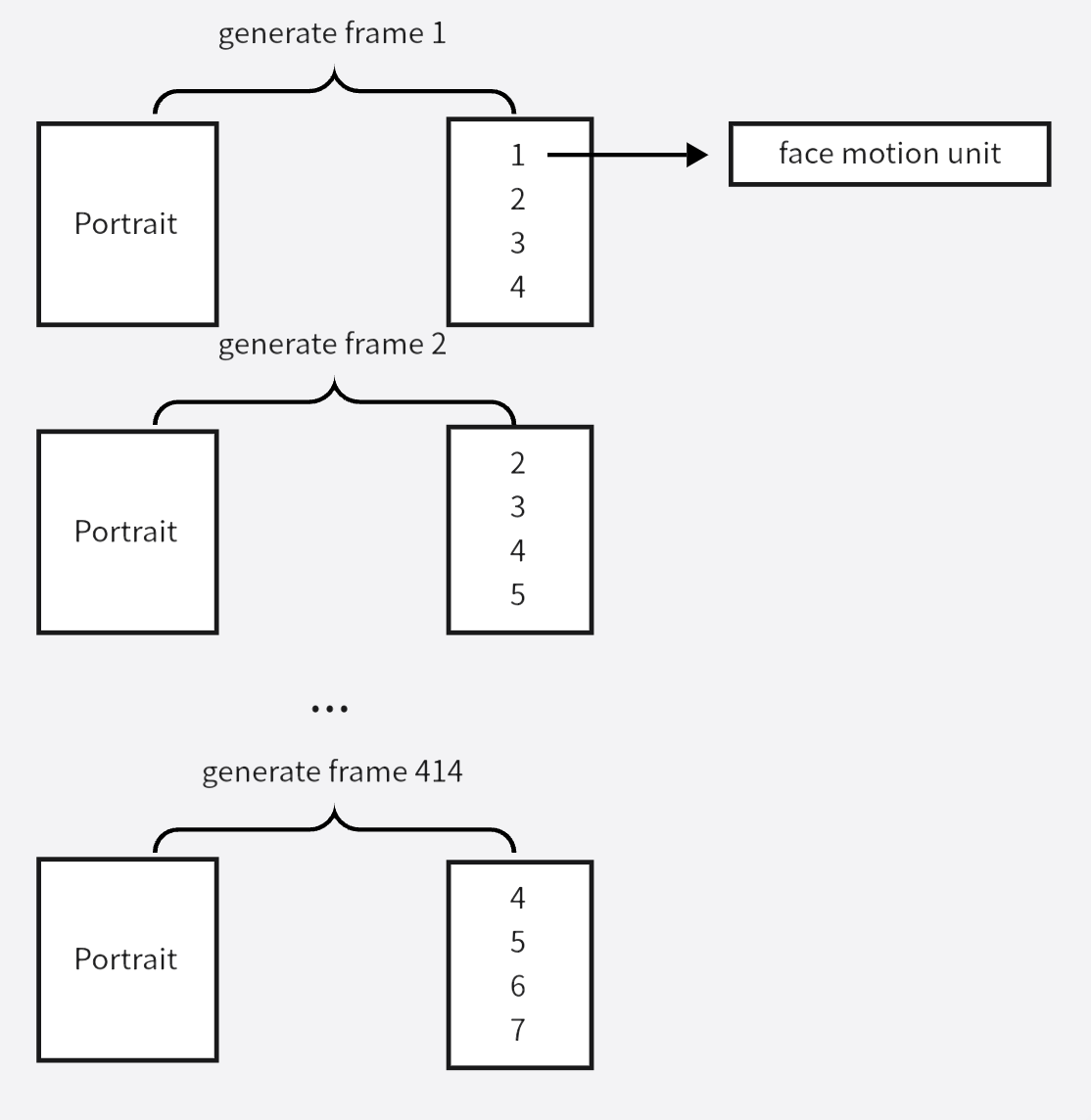
接受的条件是对音频 embedding 采用多个连续小窗口取到的小音频们(比如 414 个小音频),参考风格视频,小音频们通过 transformer-based audio encoder 后与 mt 做通道维度的拼接,经过线性映射后再和 t 相加 作为 denoising decoder 的 K,V,style encoder :从 R 中提取 3DMM expression parameters 再喂给 transformer encoder,再通过 self-attention 获得 style code s,s复制到 2w+1 长度后作为 denoising decoder 的 Q, denoising decoder 输出epislon theta,论文利用ddim算法,epislon theta,xt->predict x0->xt-1。损失函数是扩散模型损失 + 生成的 clip 的音频同步损失(由 Style-aware Lip Expert 评估)
R有时候的缺失的,所以为了估计可能的 style code s,训练一个 接受 portrai + 音频的扩散模型架构的 Style Predictor,用第二阶段的训练好的 style encoder 做监督。结构是 transformer encoder
12、simswap
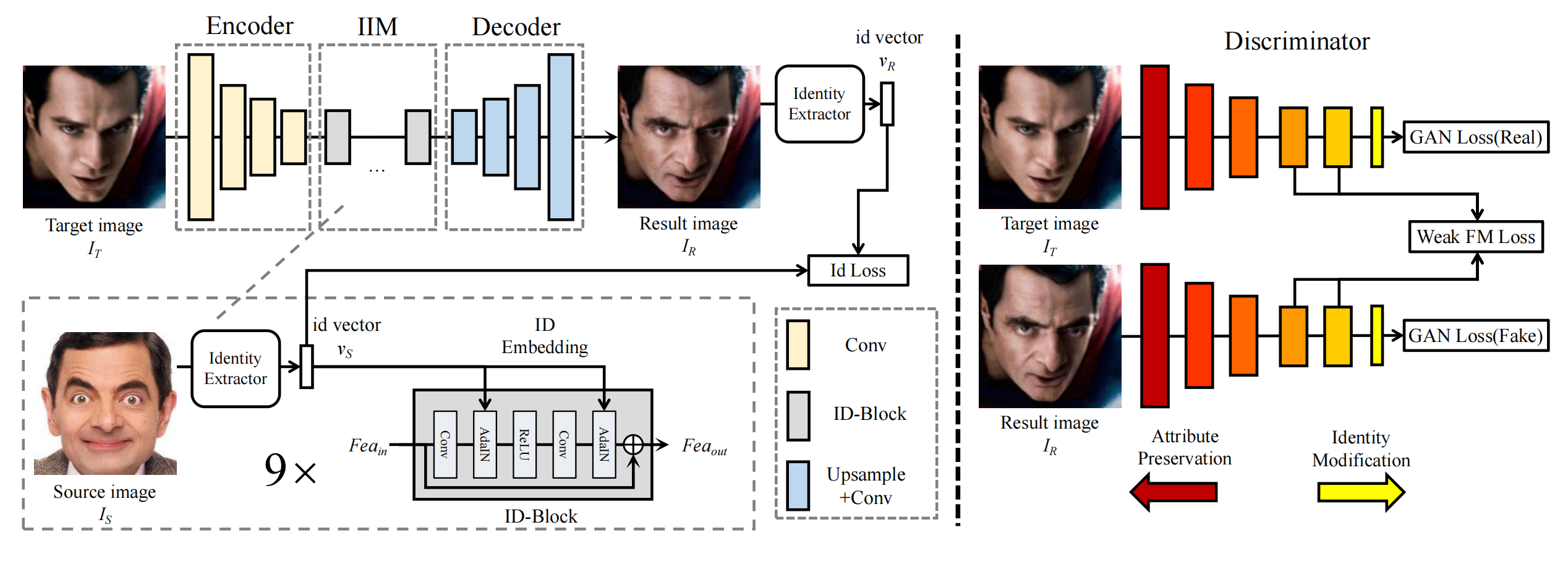
Encoder 编码 It,IIM 将 Is 注入到特征中以修改 ID,注入的核心方式是用 AdaIN,Decoder 还原为图片。loss:vr 需要和 vs 接近,为了防止过拟合同时保留部分It 的attribute,Discriminator 提取 It 和 Ir 的中间特征并希望尽可能接近(weak FM loss)。训练时用的图片对,两个人图片或者一个人的两个图,对于后者,再加个重建 loss,就是Ir 和 IT 尽可能一样。
13、visual-concept-translator(TCD)
风格化图片+人图片=》风格化的人

14、stytr2
风格迁移
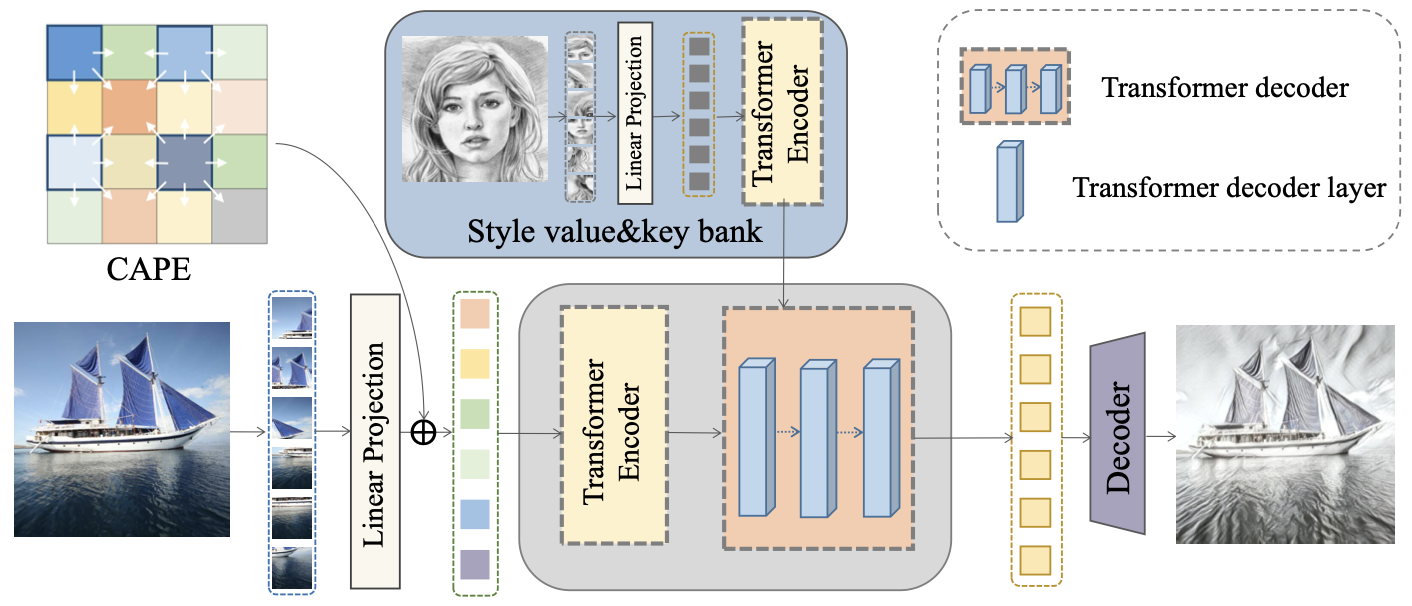
content 图片先划分成 patch,再加入位置编码 CAPE 建模图片结构,然后通过 Transformer encoder,输出一个内容序列;style image 也是同样的,只不过不用 CAPE,因为不需要结构,输出一个风格序列。随后两个序列注意力融合:内容序列做Q,风格序列做K,V。最后通过 Transformer decoder 一步解码。训练时没有GT,但是有loss:预测的图片和 content 图片结构最好一样(VGG 各个层的特征图 的 MSE),和 style image 风格最好一样,还多了个 id loss 做加强
15、styleDiffusion
Is + Ic =>Ics
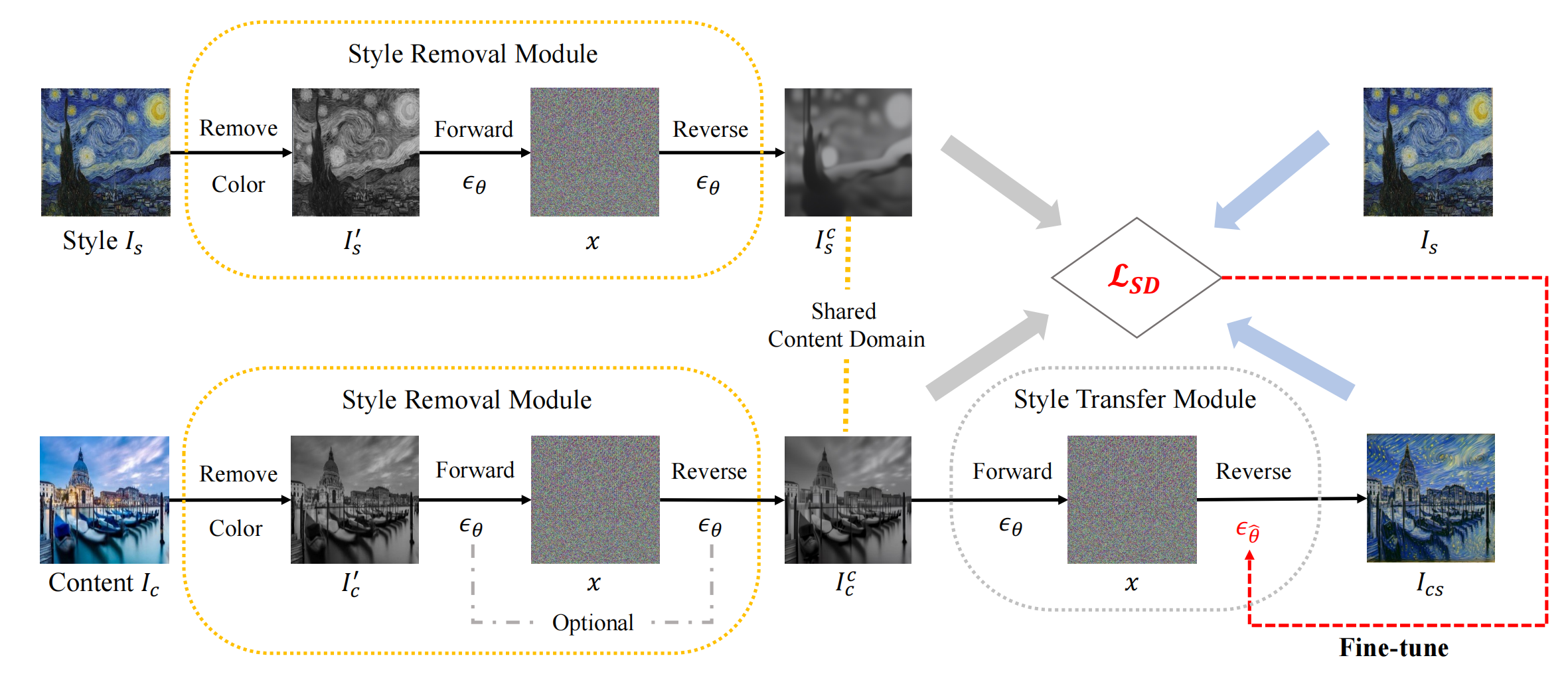
style removal module: 首先 removes its color by a commonly used ITUR 601-2 luma transform,再通过加噪和解噪去掉风格细节,通过步数可以控制去掉多少。Is 和 Ic 都做同样的操作,Ic 可以只做去颜色,因为加噪和解噪也可能会损失一些结构信息。然后就是类似 DiffsionCLip,只不过把文本引导换成了图片引导,因此一个style image就得训练一个模型。此处作者定义 图片风格=图片-图片的content,E 是 clip,通过方向损失来更新 Unet:
![]()
![]()
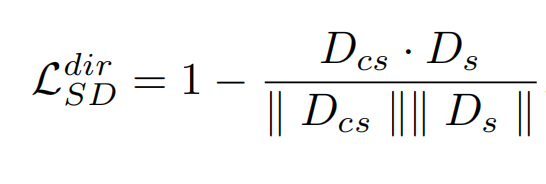
另外有加了个重建损失提高效果,这个是提前做的,作为训练所有风格化的初始权重:也就是把 Icc 换成 Ics,也就是同一张图片不仅做Ic也做Is,这样输出的结果就得还是自己。
16、styleID
不用训练就能风格迁移
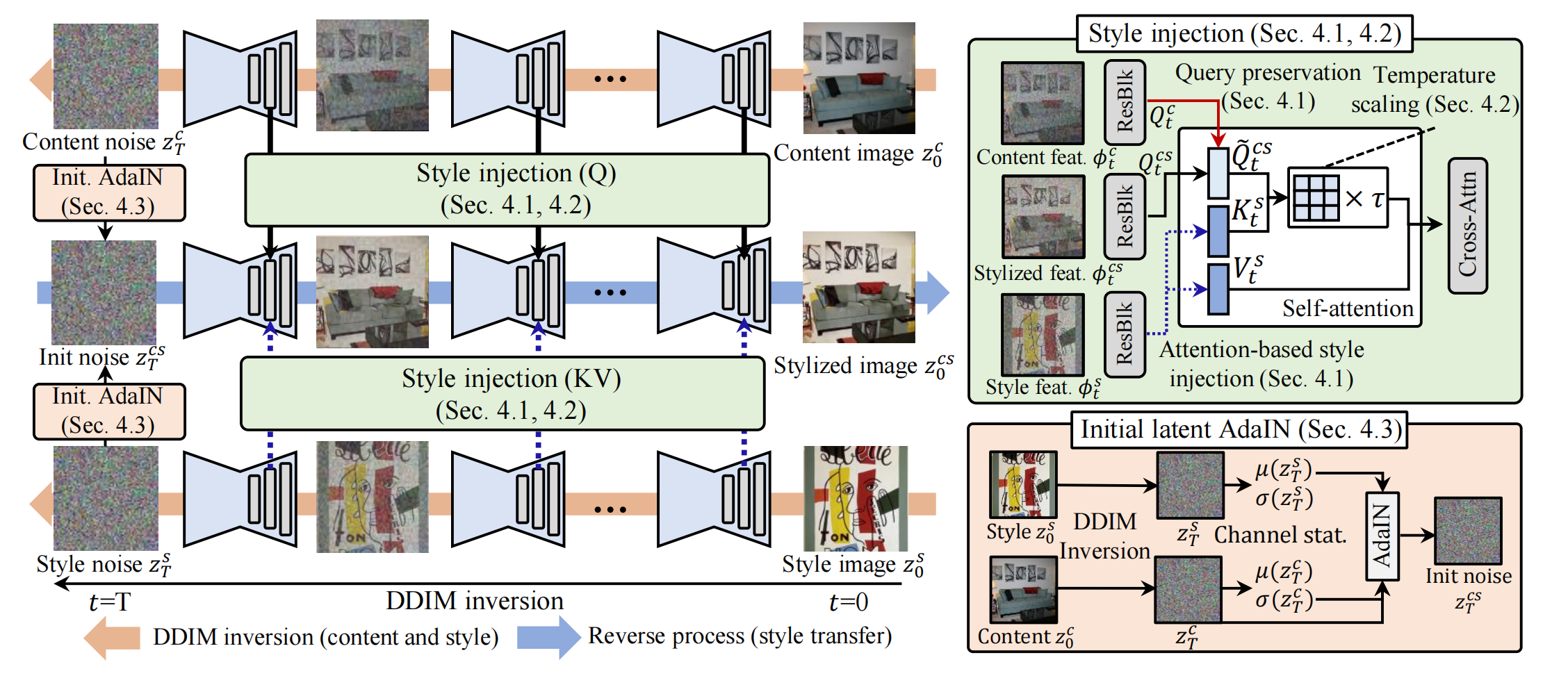
content image 和 style image 分别通过 DDIM inversion到噪声,同时记录过程当中的 content image 的Q, style image 的K,V。将两者的噪声通过 AdaIn 融合,这是为了把style image颜色传过去,因为初始噪声会影响最终颜色:
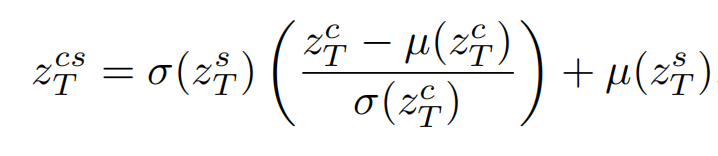
然后再从融合后的初始噪声解躁,过程中将 style image 的细节传输进去。修改自注意力机制,把 k,v 换成style image 的K,V。为了多点 content image 结构信息,Q 是 合成的Q 和 content image 的Q的融合:
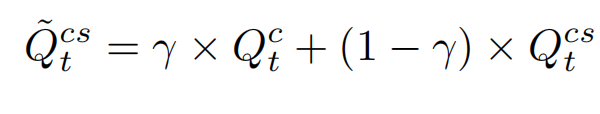
因为 K,V 和 Q 来自不同图片,所以Q 和。K相似性低,导致乘积小,导致 map 的 标准差小,导致图片模糊。为了放大乘积,引入温度系数来乘 Q K 的结果。
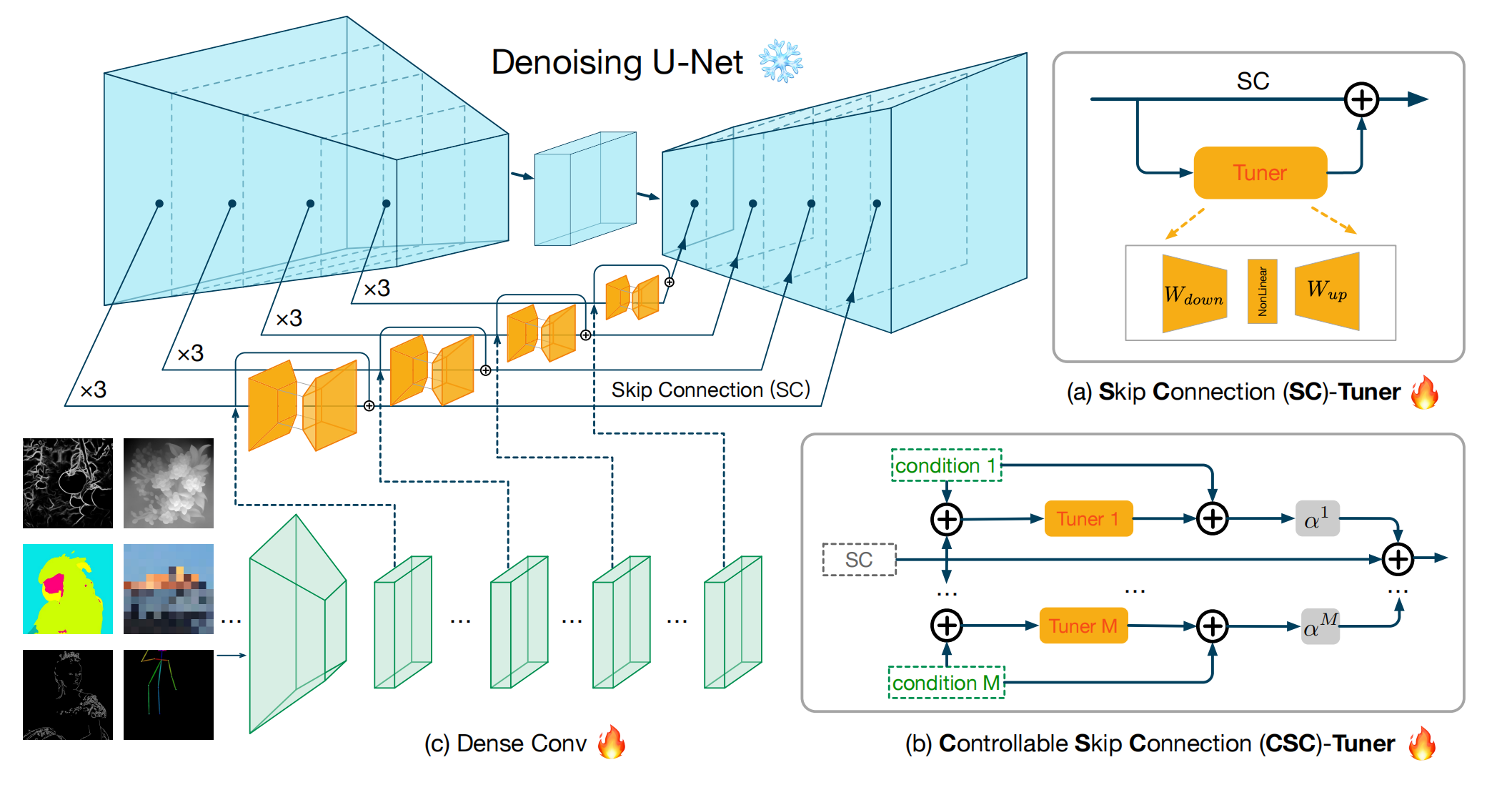
17、SCEdit
lora 的替代方法,参数量更少,更能反应细节。认为Unet中间的跳跃链接能够传递更加细节的信息,于是就在上面加了可训练模块:SC-Tuner。针对条件控制,在跳跃链接上设计了多条件的 CSC-Tuner,外加简单的Controlnet结构。
18、DisCo
参考人图像 + pose 序列 =》 按照pose运动的参考人
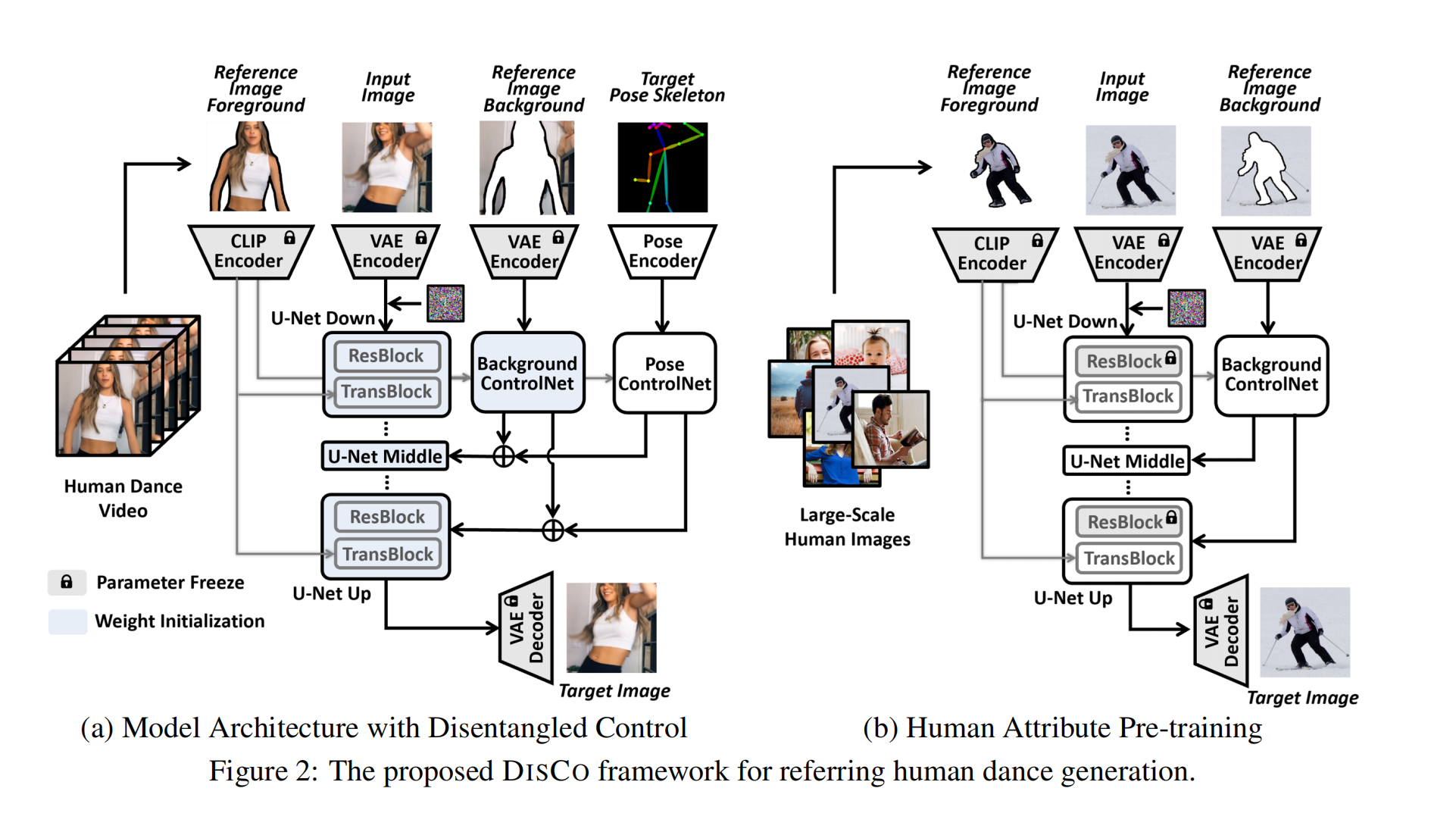
结构很简单: 2个controlnet分支加起来:背景controlnet 和 pose controlnet,背景是通过vae 编码以便保留背景细节,pose 通过简单的 pose encoder (4个卷积层)编码。前景是这个人,通过clip向量替换掉原本prompt的位置通过cross attn注入。
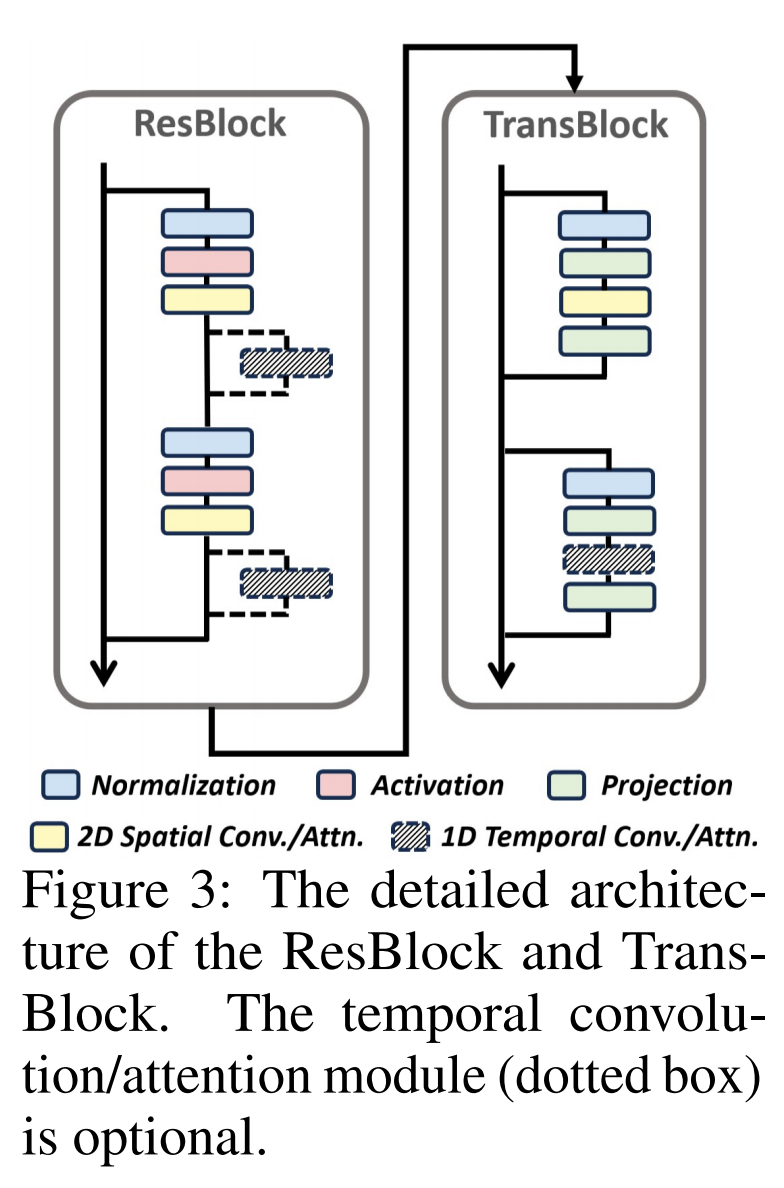
由于视频质量低,所以需要先通过一个预训练阶段(图b)(用纯图片数据集)做一个重建任务,此时去掉 pose controlnet。训练的时候冻结vae ,clip,Unet 的 ResBlock(经验证明冻结这个有利于重建脸部细节)。第二阶段(图a)微调视频(用纯视频跳舞数据集),视频第一帧做参考图片,背景复制n帧,pose 是该视频的n帧对应的pose序列,另外模型结构再做个时间维度的膨胀,ResBlock 和 TransBlock 新增 (零初始化和残差)1D temporal convolution/attention 层:
19、DEADiff
文+参考图=》有参考图风格/主题的图片

模型:参考图片+ ‘style’ =〉Qformer 输出参考图片风格向量 或者 参考图片 + ‘content’ =〉Qformer 输出参考图片主题向量。风格向量注入 Unet 的高分辨率层,主体向量注入 Unet
低分辨率层。另外模仿 IPA ,参考图片向量和文本向量拼接到 cross attn,在形式上表现为 参考图片向量 的K,V 会和 文本向量的 K,V 拼接。
训练:同一个 prompt 生成2张图放到 图a 上分之训练,让Qformer学习提取风格向量。1个主体2个 style 对应到 2个prompt ,分别生成参考图像和目标图像,放到图a 的下分支训练,让Qformer学习提取主体向量。
20、sparseCtrl
文+部分(稀疏)帧(或者深度\sketch 帧)=》视频,比如帧预测,插帧任务
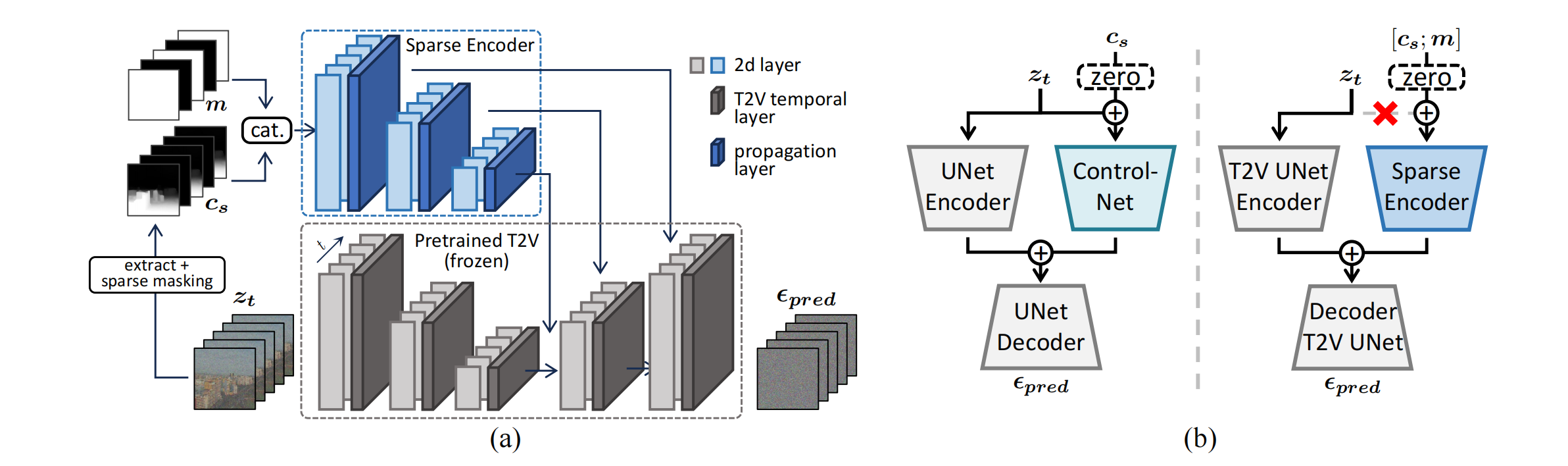
复制T2V Unet encoder 作为 视频版本的controlnet,它与普通的controlnet不同之处在于:有个时间层(propagation 层),输入也不同,输入是序列,序列中的部分帧是条件,黑色帧是完全不知道,已知和未知通过 mask 拼接来表示,另外输入没有 zt 了,以防止其他信息干扰条件。训练集是WebVid-10M,条件帧数是随机抽取的,Unet 参数固定。
21、ConsistentID
改进ipa
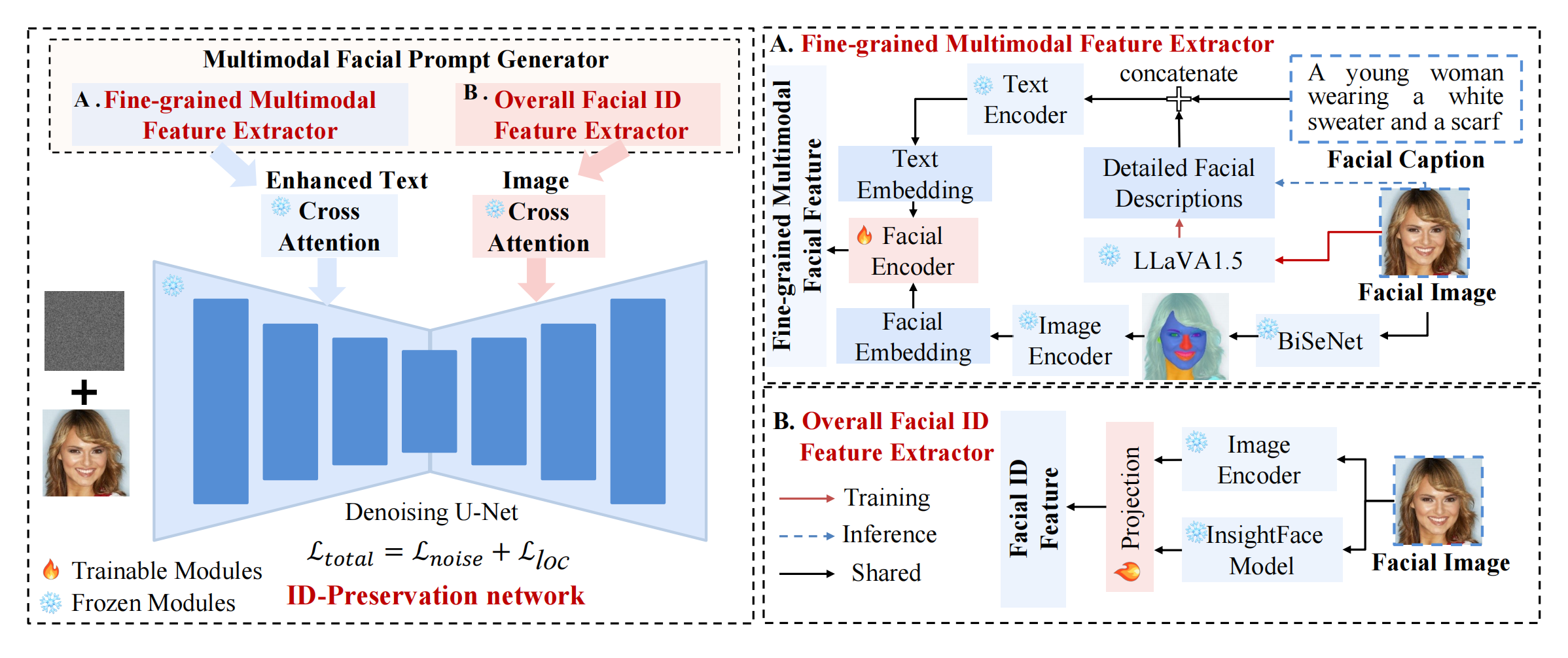
ipa的 image prompt 分支多了一个编码器; ipa的文本向量变为增强的多模态向量:用llava生成细粒度人脸描述,然后和原始标题拼接。另外 facial image 通过 bisenet 和 image encoder 生成5官向量,然后进入 facial encoder(5官向量先和 Queries 注意力+FFN,然后替换文本向量中的五官的向量):
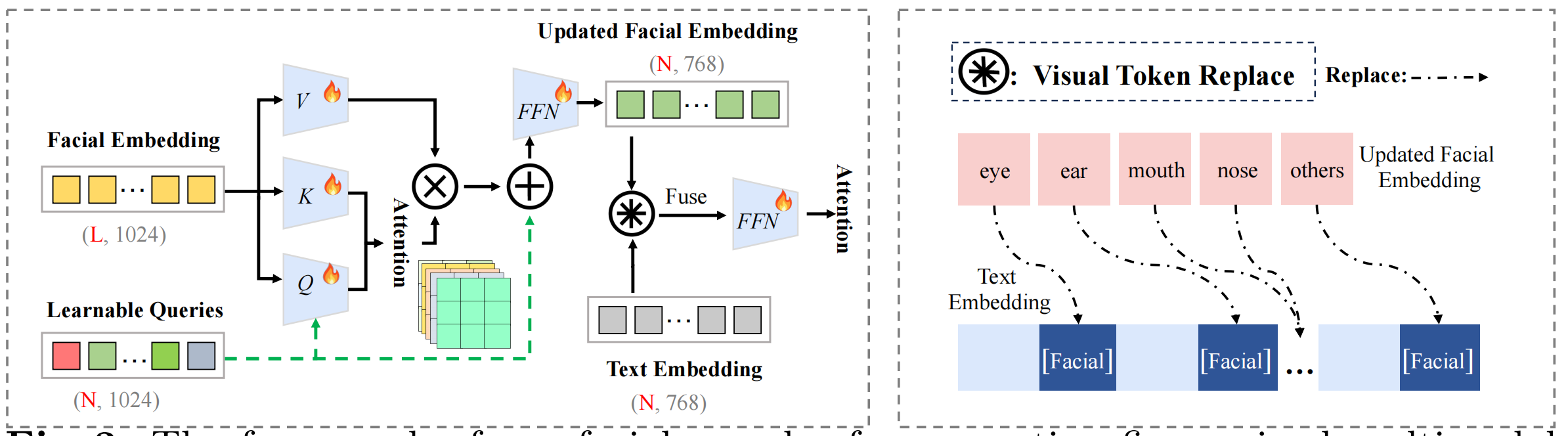
训练过程只训练 facial encoder 和 projection。损失函数多了个trick,加上了五官token 的 crossattn map 对其到五官的mask上。
22、PuLID
改进了instantID 对提示词编辑性差的问题
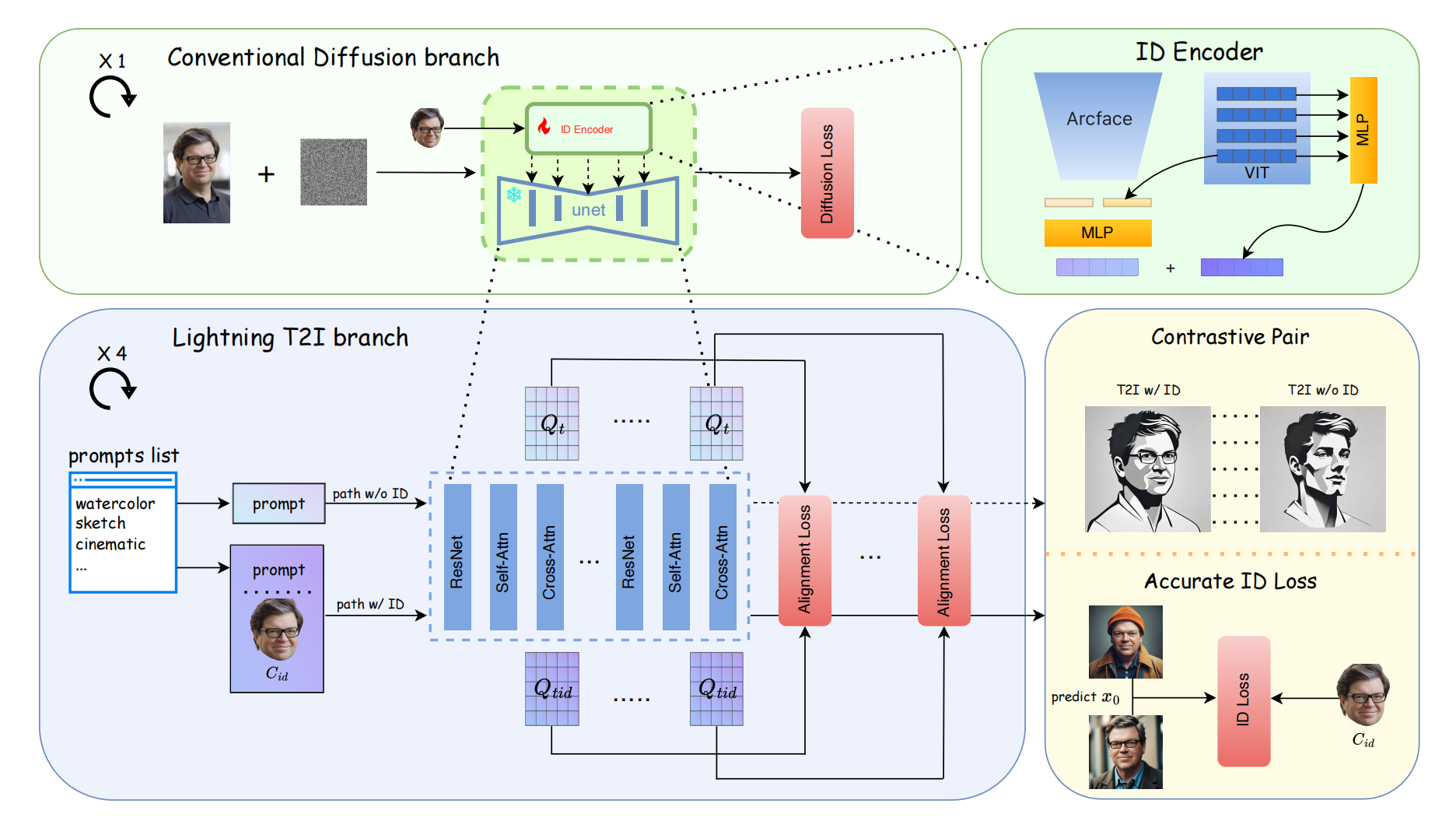
人脸:ID encoder 多了一个 VIT 输出cls 和 arcface 的结果拼接,通过MLP映射为5个token,同时 VIT 输出多层的细粒度特征( 5 个token)+ MLP,拼接后是 10 个token,每个 token 是2048维。这些人脸向量单独通过 QKV 注入到Unet 里面。
新增了损失用来分离 ID 向量对于原始sd对提示词的理解的影响:2个路径,同一个提示词,一个路径有id(代表新模型),另一个路径没有id(代表原始sd),计算两个路径的 softmax(Q,K,Q),期望相等:
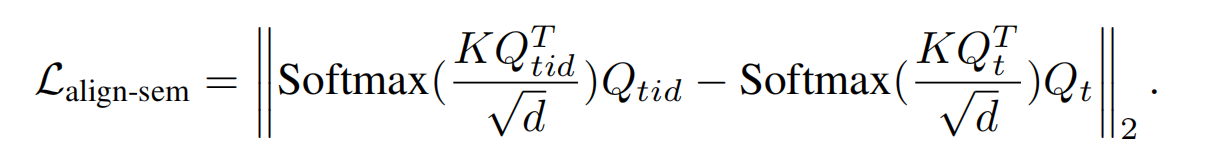
期望和原始sd的布局一样,所以期望Q一样:
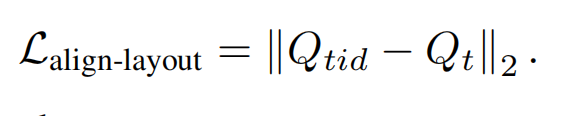
还有用 lightning 快速算出较为准确的预测 x0,计算相似度损失:

23、DiffBIR
去模糊
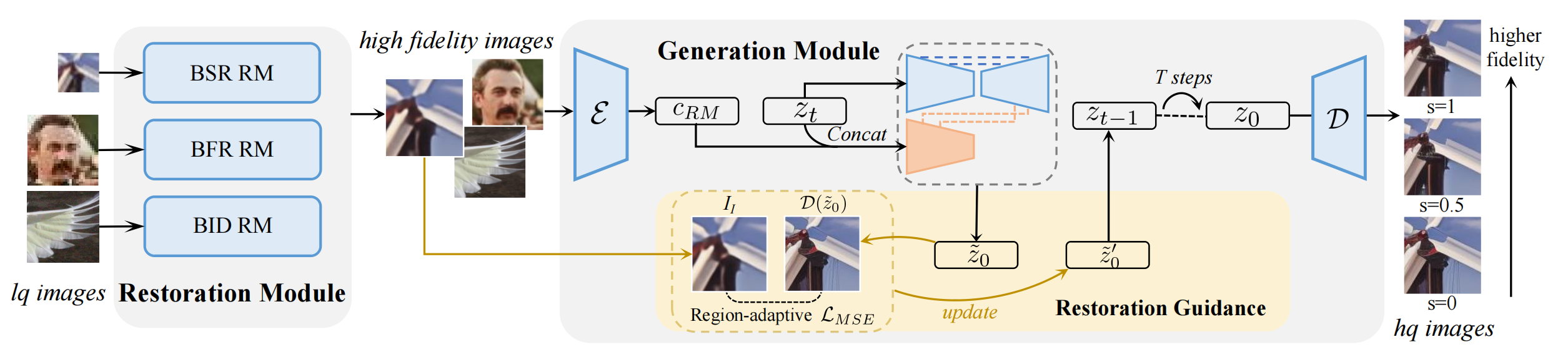
分2阶段,为了把LQ图片映射到相同的LQ水平以供第二阶段的扩散模型去学习,第一阶段就按照不同种类的LQ图片按照对应的模块做 degradation removal
第二阶段是IRControlnet,类似Controlnet结构,只不过一开始对条件图片的分支改为了VAE编码
为了使得高频区域(纹理,边缘)保持(high quality),但是flat regions (e.g., sky, wall )不要胡乱生成(high fidelity),所以需要 trade-off between quality and fidelity:
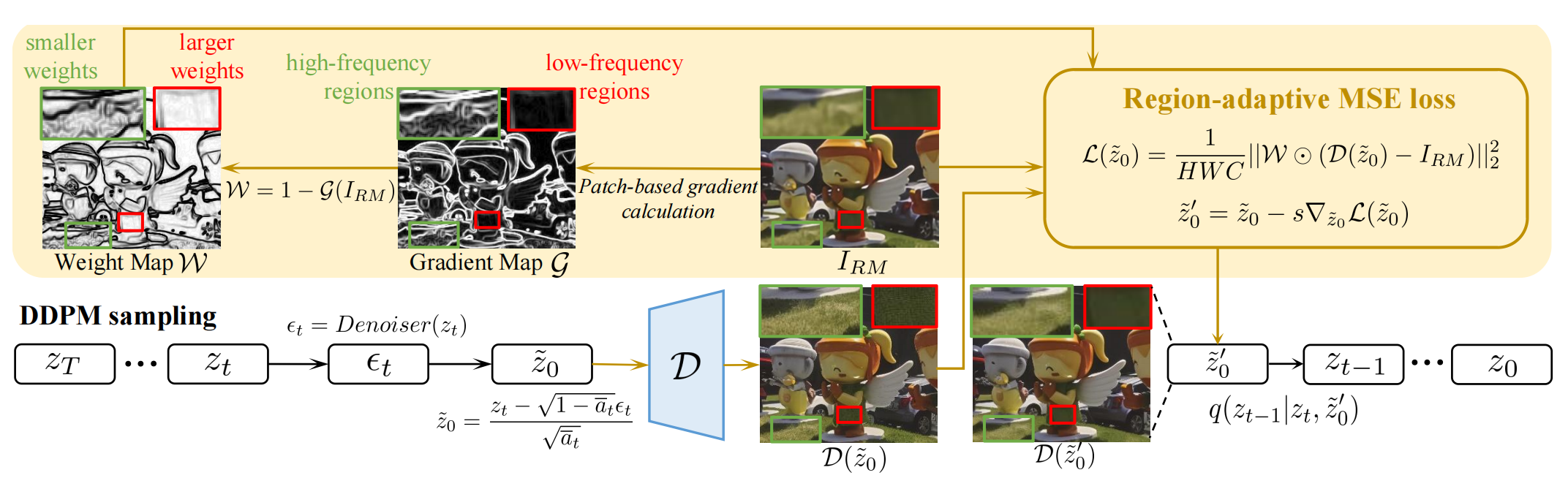
在采样的时候,对 xt 根据预测的 x0 和 IRControlnet 的条件输入(IRM)做loss,用loss做梯度来引导生成结果像 IRM。W表示不同频率的区域对应不同的权重,若某个区域的权重越大,则生成图片的那块区域更像 IRM 的那个区域。
24、ID-Animator
文+face image=》这个人的视频
在animateDiff 里面插入 ipa,ipa 的输入是这个人的多个角度的 face image 向量的平均。训练的时候只训练 ipa 部分,数据集是 (文,视频,视频里这个人的脸部 crop),文本除了属性描述,还加了视频的行为描述。
25、InstructAvatar
文T + 音频 A + portrait I =》 video
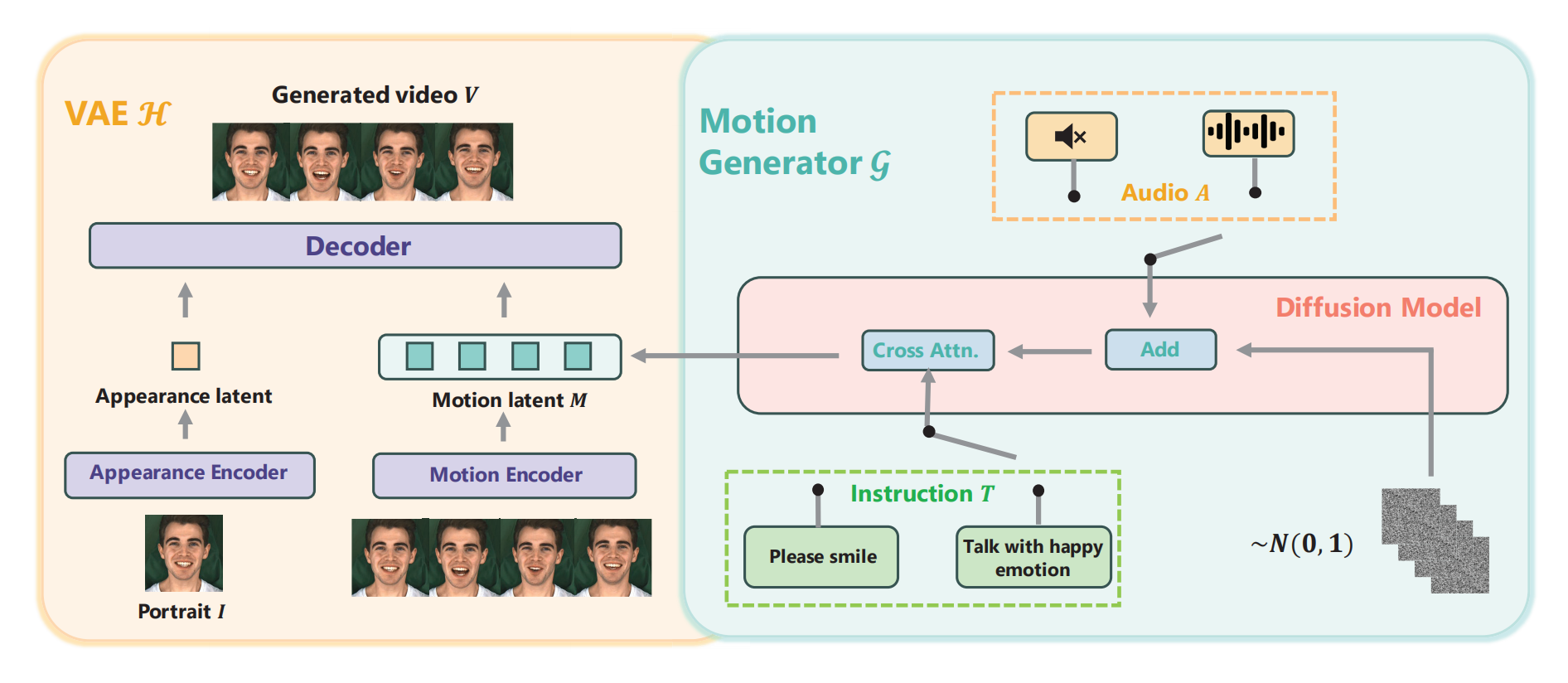
Motion generator :根据 T 和 A 生成motino M ; VAE:把 I 和 脸部 M 融合起来
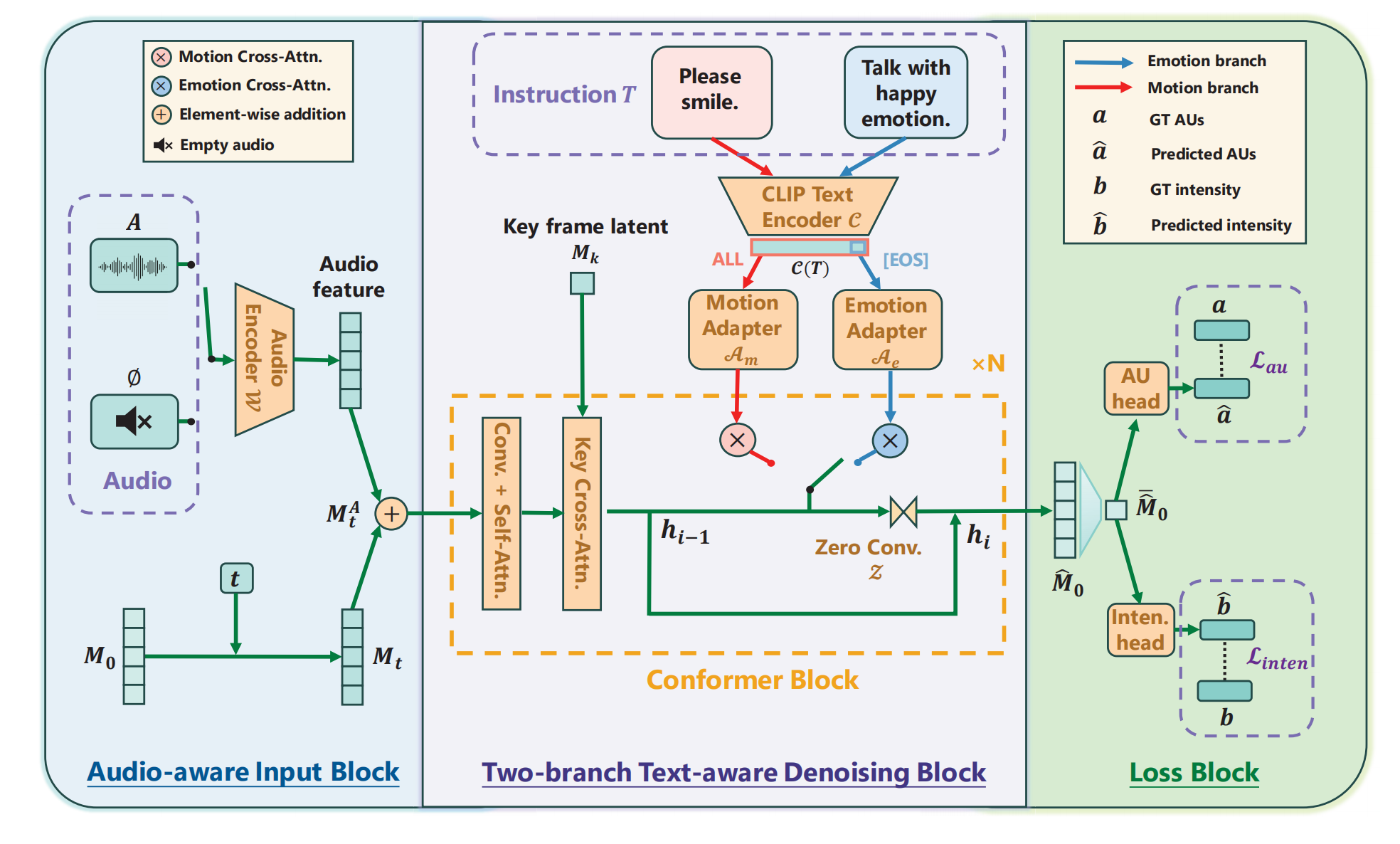
Motion generator :A 的特征作为1个dm条件与 Mt 做元素积;T 看情况,如果是 emotion talking 任务,则取T 的 EOS 向量作为全局的风格向量,如果是 motion 任务,则取文本编码器的最后一层的所有 token 特征,两个任务分别给对应的 adapter (2个MLP)做空间对齐。这个 T 单独和 hidden state 做cross attn 然后通过零卷积注入,模型权重初始化为没有文本条件的 conformer ,该权重能够产生中性的motion。loss 包括对 预测M0 的MSE loss,预测 M0 再提取的 action unit 和 emotion intensity 的分类(交叉熵)loss,后者的 au 通过 au detection 提取, emotion intensity 是标签。
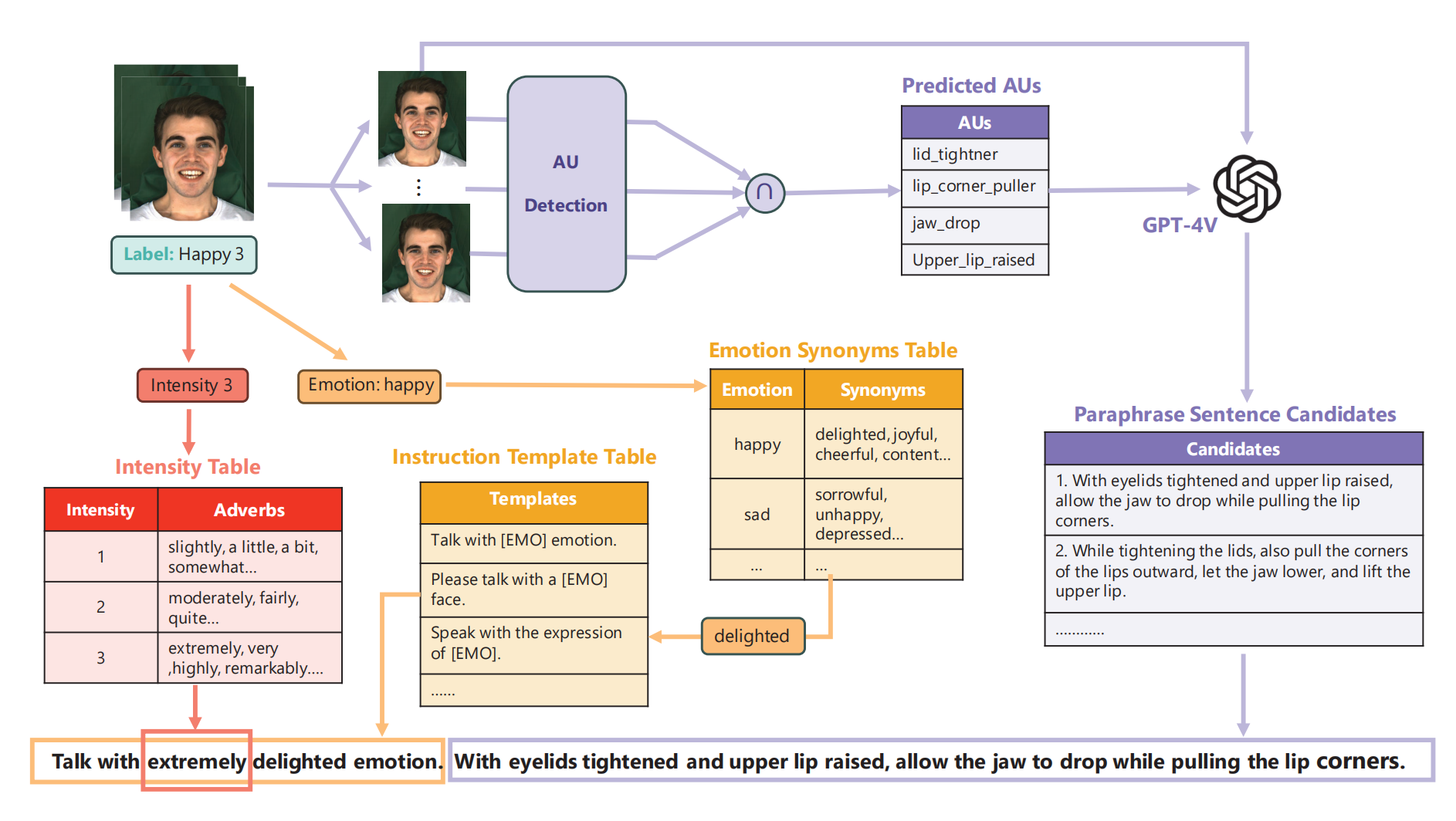
T指令的构造:
根据 label 和预定义好的模版组成黄色的title (粗力度),再根据 au detection + GPT4v (文本+图片) 补充细粒度文本
区别 :VASA-1 的 Motion generator 结构是 Diffusion Transformer;去掉了 Dreamtalk 的音频同步训练阶段,此处的 genetarar 作用不光能对嘴型还能生成嘴型,Dreamtalk 的 motion generator 也是diffusion,音频条件的注入方式也是 与mt 结合,只不过是:拼接再和t做线性映射,然后作为注意力机制的 K,V。而此处结合后就做为新的mt 了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号